1. 拉取镜像
1. 创建存放资源的文件夹
mkdir -p ~/k8smkdir ~/k8s/hadoop-helmcd ~/k8s/hadoop-helm
2. 从官方Helm库拉取镜像
# https://hub.helm.sh/charts/stable/hadoophelm search repo hadoop# Hadoop-2.9.0helm fetch azure/hadoop --version 1.1.2# Hadoop-2.7.3helm fetch aliyun/hadoop --version 1.0.4
2. 修改脚本
tar -zxvf hadoop-1.1.2.tgzcd hadoopvi templates/hadoop-configmap.yaml:set nu
默认为每次启动都格式化NameNode,所以修改34-38行为:
# 修改前34 if [[ "${HOSTNAME}" =~ "hdfs-nn" ]]; then35 mkdir -p /root/hdfs/namenode36 $HADOOP_PREFIX/bin/hdfs namenode -format -force -nonInteractive37 $HADOOP_PREFIX/sbin/hadoop-daemon.sh start namenode38 fi# 修改后if [[ "${HOSTNAME}" =~ "hdfs-nn" ]]; thenif [[ -f "/root/hdfs/namenode/exsit" ]]; thenecho "NameNode had already format!"$HADOOP_PREFIX/sbin/hadoop-daemon.sh start namenodeelsemkdir -p /root/hdfs/namenode$HADOOP_PREFIX/bin/hdfs namenode -format -force -nonInteractive$HADOOP_PREFIX/sbin/hadoop-daemon.sh start namenodetouch /root/hdfs/namenode/exsitfifi
修改后会判断是否格式化过NameNode。
vi templates/hdfs-nn-statefulset.yaml:set nu
将59-70行注释掉。
59 #readinessProbe:60 # httpGet:61 # path: /62 # port: 5007063 # initialDelaySeconds: 564 # timeoutSeconds: 265 #livenessProbe:66 # httpGet:67 # path: /68 # port: 5007069 # initialDelaySeconds: 1070 # timeoutSeconds: 2
DataNode配置修改:
vi templates/hdfs-dn-statefulset.yaml:set nu
将59-70行注释掉:
59 #readinessProbe:60 # httpGet:61 # path: /62 # port: 5007563 # initialDelaySeconds: 564 # timeoutSeconds: 265 #livenessProbe:66 # httpGet:67 # path: /68 # port: 5007569 # initialDelaySeconds: 1070 # timeoutSeconds: 2
还可以修改datanode个数等信息,在values.yaml中修改即可。
vi values.yaml
内容如下:
dataNode:replicas: 2pdbMinAvailable: 1
3. 导入Hadoop镜像
- 上传镜像(所有安装节点)。
加载镜像(所有安装节点)。
docker load -i docker-hadoop_2.9.0.tar
4. 启动Chart
helm install hadoop --namespace bigdata .kubectl get pods -n bigdata
5. 暴露端口
此时Hadoop运行无误,但是此时我们不能访问,因为Hadoop的端口是pod内部共享的,我们在外面用不了,所以此时需要将我们用到的端口暴露出来。
1. 暴露Hadoop WebUI端口
创建svc文件。
vi nnport.yaml
内容如下:
apiVersion: v1kind: Servicemetadata:name: nnportlabels:name: nnportspec:type: NodePort # 这里代表是NodePort类型的,暴露端口需要此类型ports:- port: 50070 # 这里的端口就是要暴露的,供内部访问targetPort: 50070 # 端口一定要和暴露出来的端口对应protocol: TCPnodePort: 30070 # 所有的节点都会开放此端口,此端口供外部调用,需要大于30000selector:app: hadoopcomponent: hdfs-nnrelease: hadoop
上述文件的selector要和我们此时的环境对应上,可以通过下面命令查看:
kubectl edit svc hadoop-hadoop-hdfs-nn -n bigdata
修改内容如下:
selector:app: hadoopcomponent: hdfs-nnrelease: hadoopsessionAffinity: Nonetype: ClusterIPstatus:loadBalancer: {}
开启端口。
kubectl apply -f nnport.yaml -n bigdatakubectl get svc -n bigdata
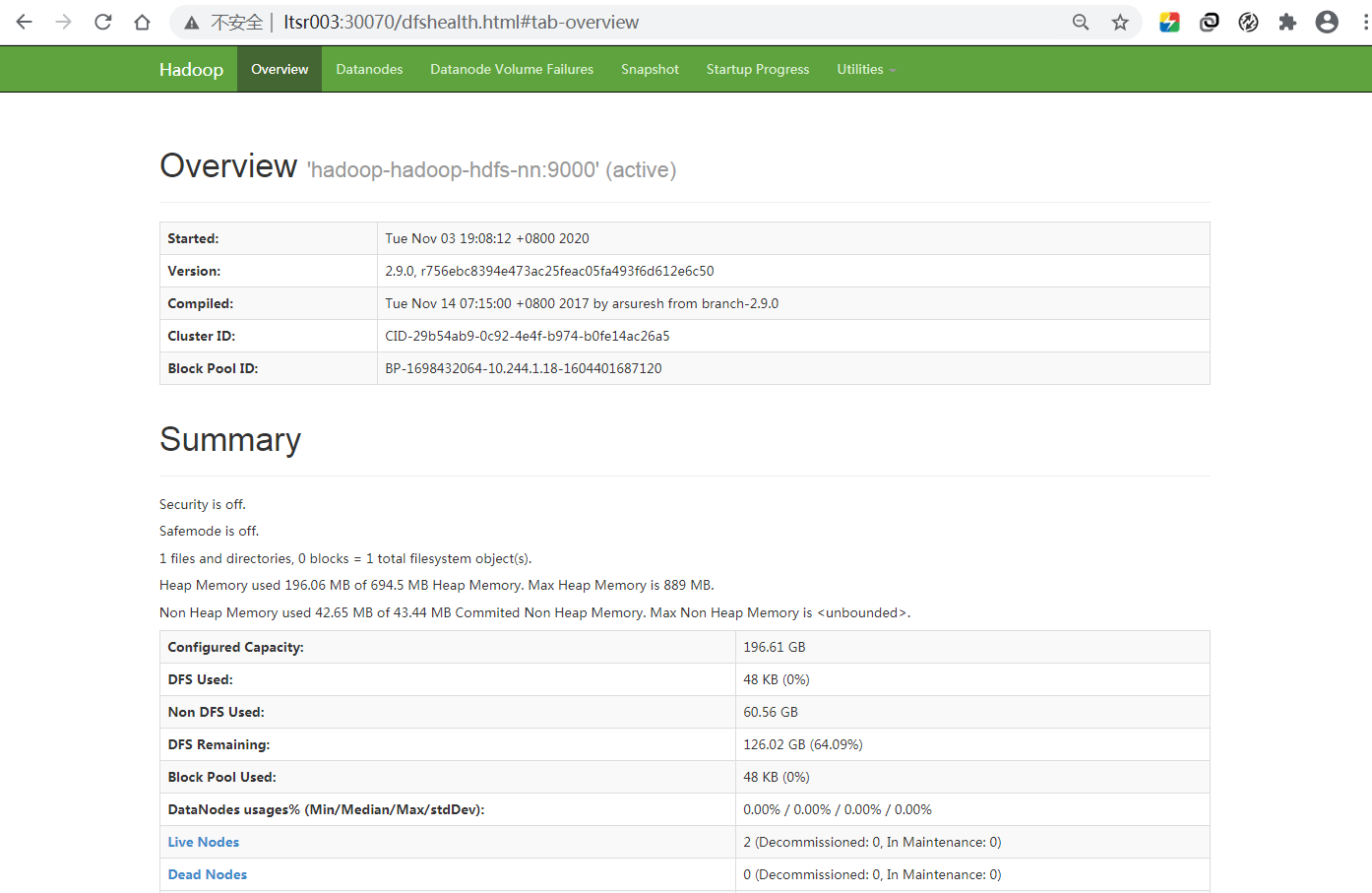
访问WebUI(http://ltsr003:30070)。
2. 暴露Yarn WebUI端口
创建svc文件。
vi rmport.yaml
apiVersion: v1kind: Servicemetadata:name: rmportlabels:name: rmportspec:type: NodePort #这里代表是NodePort类型的ports:- port: 8088targetPort: 8088protocol: TCPnodePort: 30088 # 所有的节点都会开放此端口,此端口供外部调用。selector:app: hadoopcomponent: yarn-rmrelease: hadoop
开启端口。
kubectl create -f rmport.yaml -n bigdatakubectl get svc -n bigdata
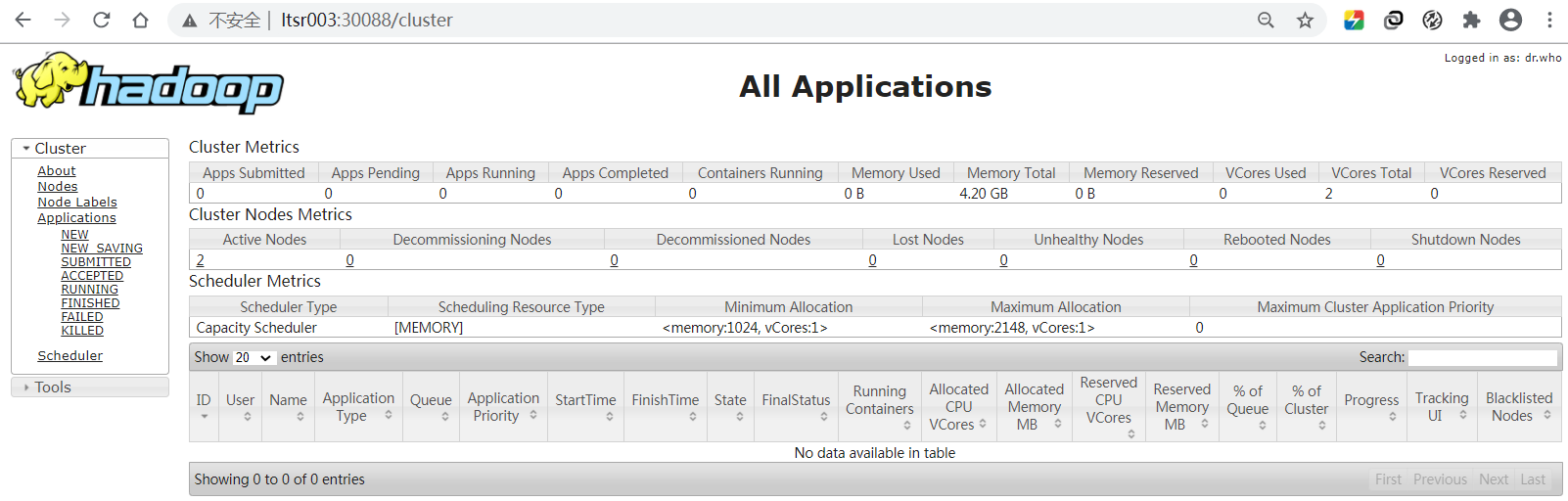
访问WebUI(http://ltsr003:30088)。
6. 验证Hadoop
1. 测试HDFS
HDFS基本信息查看。
# 查看HDFS的基本数据kubectl -n bigdata exec -it hadoop-hadoop-hdfs-nn-0 -- /usr/local/hadoop/bin/hdfs dfsadmin -report
进入NameNode(nn)容器。
kubectl -n bigdata exec -it hadoop-hadoop-hdfs-nn-0 /bin/bash
创建文件夹并上传文件。
hadoop fs -mkdir /testhadoop fs -put README.txt /test
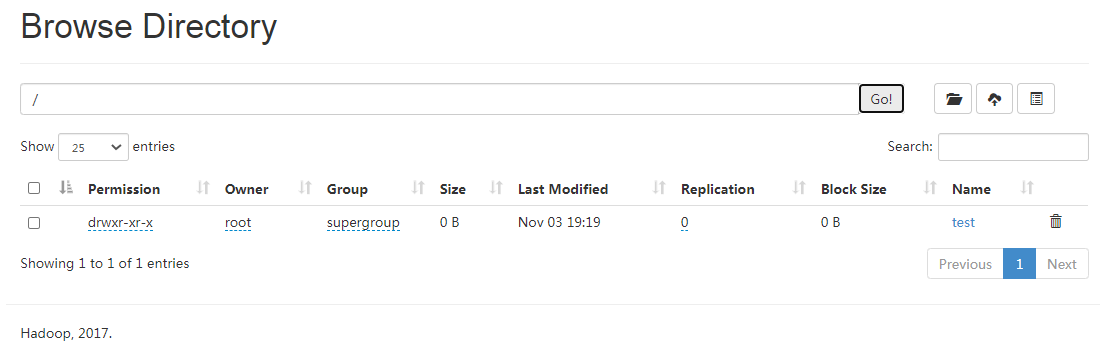
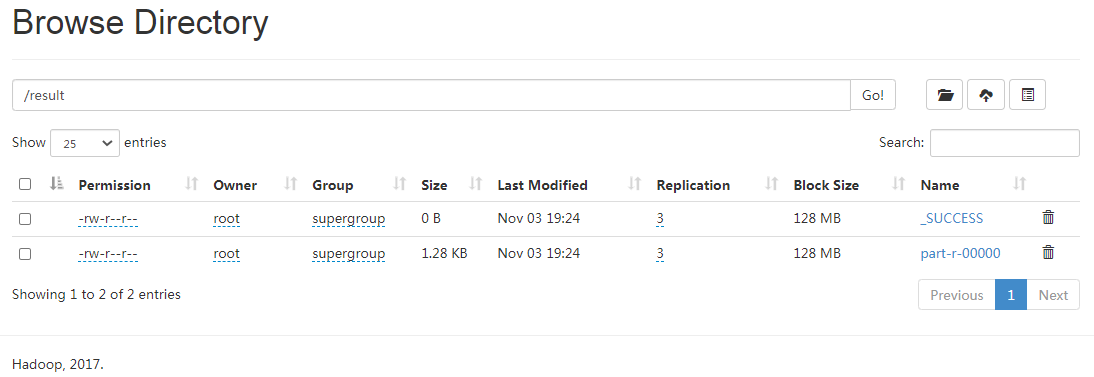
查看结果(WebUI:http://ltsr003:30070/explorer.html#/)。
2. 测试Yarn
查看Yarn的NodeManager(nm)节点。
kubectl -n bigdata exec -it hadoop-hadoop-yarn-rm-0 -- /usr/local/hadoop/bin/yarn node -list
进入ResourceManager(rm)容器。
kubectl -n bigdata exec -it hadoop-hadoop-yarn-rm-0 /bin/bash
运行官方WordCount案例。
hadoop jar /usr/local/hadoop-2.9.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.0.jar wordcount /test /result
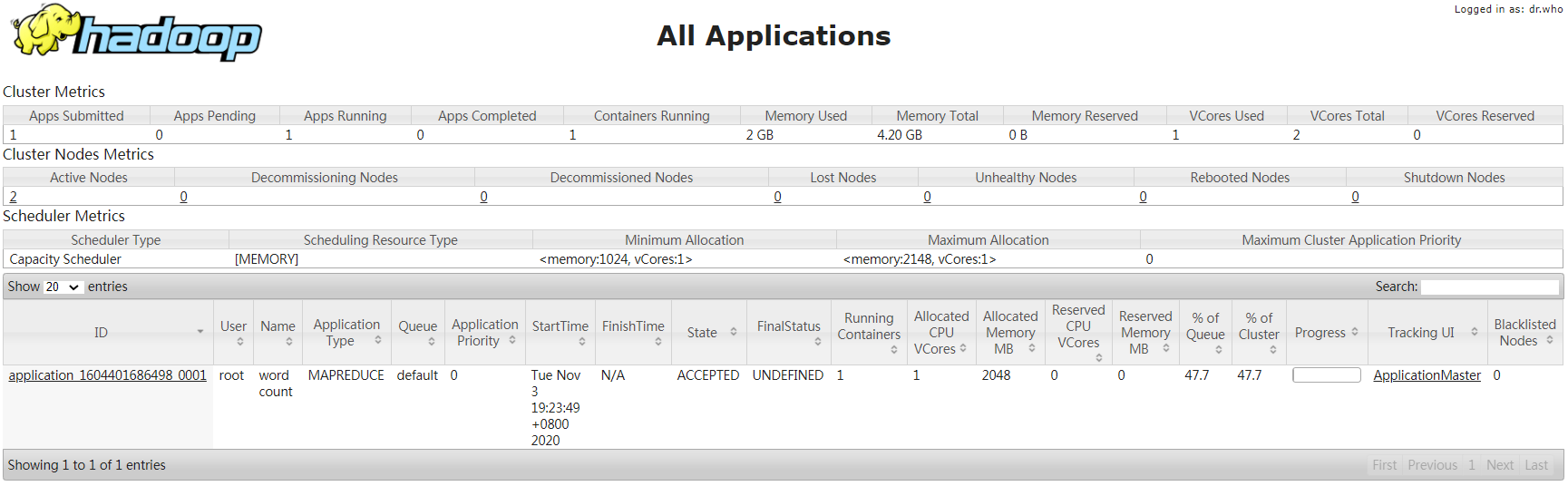
查看结果(WebUI:http://ltsr003:30088、http://ltsr003:30070/explorer.html#/result)。
7. 卸载
kubectl -n bigdata delete -f nnport.yamlkubectl -n bigdata delete -f rmport.yamlhelm uninstall hadoop -n bigdata

若有收获,就点个赞吧
0 人点赞
