导读
这是一篇博客,更是一个 Playground,笔者在进行实际业务开发之前,习惯在简化模型上进行基础原理验证,我也一直相信,再复杂的业务和架构,也都是从一个最基础简单的原点演化起来的,而开发者一旦了解了这个原点,再去俯瞰整个系统,就有脉络可循了,理解起来事半功倍。
所以,我们需要先搭建基础的调试环境,准备如下:
- 如果你已经拥有了 Mysql 8.0 数据库,可以下载 mysql-bi.sql.zip 示例数据,但受限于 Mysql 不支持 FULL JOIN 等特性,你的实验只能止于 With 章节。
- 笔者更建议直接准备一个 ClickHouse 数据库,相比于其他大数据引擎,ClickHouse 的测试环境搭建相对简单,以及对资源要求较低。本文实验是在一台 2C4G 的 Ubuntu 服务器上进行的,简明的搭建注意事项可见 附录:ClickHouse 安装和使用指南
PS:下文的所有示例都是可执行观察的 👀,读者可边看边实验,Have Fun.
宽表是什么?
先了解下关系型数据下的 3 范式定义,三者之间是递进关系,即第二范式建立在第一范式已经满足的情况下,以此类推:
- 第一范式:要求确保表中每列的原子性,也就是不可拆分,不能出现表中表
- 第二范式:约束非主键和主键之间的关系,要求确保表中每列与主键完全相关,多见于联合主键场景
- 第三范式:约束非主键之间的关系,非主键只能直接完全依赖主键,不能通过传递关系依赖主键
而宽表是反三范式的,它会将业务主题相关的事实、维度、属性关联在一起组成一张大表,造成的直接结果是字段多、数据量冗余,是典型的空间换时间的做法;而带来的好处也显而易见,规避了查询时多表关联带来的性能损耗,方便了数据流转和管理。
在一个 OLAP 系统中,几乎 100% 的流量是读请求,所以习惯性的做法也是提前生成宽表落入数仓的 DWS(Data ware service)层,而且常用的数仓存储如 HIVE 等通常也不是关系型数据库,所以反三范式也就变得合乎情理了。
以样例数据为例:我们以 order 表为行为事实,user、goods 表为维度表,生成 dws_order 宽表。
这个过程可抽象概括为:以事实表为基础,通过关联字段从维度表中抽取需要的字段,最终填入宽表之中。
使用 Mysql 模拟演示 SQL 如下:
-- 清空旧数据,批处理一般都是 T + 1 的逻辑,会全量重新生成数据TRUNCATE TABLE dws_order;-- 以事实表为基础,通过关联字段从维度表中抽取需要的字段,最终填入宽表 dws_order 之中INSERT INTO dws_order (`order_id`, `buyer_id`, `user_name`, `province`, `purchase_goods_id`, `goods_name`, `purchase_quantity`, `created_at`) SELECTt1.order_id,t1.buyer_id,d1.`name` AS user_name,d1.province,t1.`purchase_goods_id`,d2.`name` AS goods_name,t1.purchase_quantity,t1.created_atFROM`order` t1LEFT JOIN `user` d1 ON t1.buyer_id = d1.user_idLEFT JOIN `goods` d2 ON t1.purchase_goods_id = d2.goods_id;
指标是什么?
基于宽表,这里引申出 OLAP 中常见的另外一个概念:指标,定义为对宽表内相关事实数据字段进行聚合计算后得出的数值。
在 OLAP 系统中,由于用户使用时维度筛选条件的不确定性,指标一般不会提前计算,而是存储相关计算公式。
例如我们需要一个“人均购买商品数” 的指标,会存储如下公式:
-- 指标:人均购买商品数
ROUND(
-- 由于 SUM 可能会出现 NULL 值,所以要用 COALESCE 取第一个出现的非 NULL 值
COALESCE ( SUM( purchase_quantity ), 0 ) / COUNT( DISTINCT buyer_id ),
2
)
用户在具体分析时候,假如限制条件为“省份维度为浙江省”,那么代入指标公式后最终生成的示例 SQL 如下:
SELECT
ROUND( COALESCE ( SUM( purchase_quantity ), 0 ) / COUNT( DISTINCT buyer_id ), 2 )
FROM
dws_order
WHERE
province = '浙江省';
维度聚合
常用语句为 GROUP BY,从开发角度可大致分为两类:日期维度、普通维度,其中日期维度的处理逻辑相对复杂。
日期维度
常见的日期粒度有:天、周、月、季、年,处理思路是对日期字段进行格式化操作
Mysql
在 Mysql 中对应公式如下,详细语法见 mysql5.7 date_format:
| 粒度 | 格式化 | 输出效果 | 备注 |
|---|---|---|---|
| 天 | %Y-%m-%d | 2021-09-22 | |
| 周 | %x-%v | 2021-01 | - 周一为新一周的开始, - 周的范围为 00..53 - 小 v 需要配 小 x 第一周的定义: - Mysql 遵循 ISO 8601 定义,即第一周至少包含 4 天 - 在 Java 中可以通过配置 GregorianCalendar.html#week_and_year 来定义第一周,示例见:DateTimeTest |
| 月 | %Y-%m | 02 | |
| 季 | %Y + Q+ Quarter | 2021Q3 | 无直接参数,通过拼接实现 |
| 年 | %Y | 2021 |
例如我们按年进行聚合:
SELECT
DATE_FORMAT( created_at, '%Y') AS `period`,
ROUND( COALESCE ( SUM( purchase_quantity ), 0 ) / COUNT( DISTINCT buyer_id ), 2 ) AS quota_mean
FROM
dws_order
GROUP BY
peroid;
按季示例:
SELECT
CONCAT( DATE_FORMAT( created_at, '%Y' ), 'Q', QUARTER ( created_at ) ) AS `period`,
ROUND( COALESCE ( SUM( purchase_quantity ), 0 ) / COUNT( DISTINCT buyer_id ), 2 ) AS quota_mean
FROM
dws_order
GROUP BY
period;
在其他大数据查询引擎如 presto 中,可以使用 date_trunc 等函数完成等价功能。
ClickHouse
Click House 的日期公式,可参考:ClickHouse#date-time-functions,此处不作细节展开,直接举一个按季度聚合的小例子:
SELECT
formatDateTime(created_at, '%Y-%Q') AS `period`,
ROUND( COALESCE ( SUM( purchase_quantity ), 0 ) / COUNT( DISTINCT buyer_id ), 2 ) AS quota_mean
FROM
dws_order
GROUP BY
period;
普通维度
普通维度指代枚举值、数值类型等,处理逻辑相对简单,也同样可以使用函数对行值进行规整。
但在实际的大数据加工过程中,普通维度的规整工作会在数据清洗阶段,进入 DWM(Data Ware Middle)的时候就会完成掉,以提升宽表的查询性能。
MYSQL以省份为维度举个例子,下述语句的呈现的是:每年各省的“人均购买商品数”,以此类推。
SELECT
DATE_FORMAT( created_at, '%Y') AS `period`,
province,
ROUND( COALESCE ( SUM( purchase_quantity ), 0 ) / COUNT( DISTINCT buyer_id ), 2 ) AS quota_mean
FROM
dws_order
GROUP BY
period, province;
ClickHouse 再举一个 ClickHouse 的例子:
SELECT
formatDateTime( created_at, '%Y') AS `period`,
province,
ROUND( COALESCE ( SUM( purchase_quantity ), 0 ) / COUNT( DISTINCT buyer_id ), 2 ) AS quota_mean
FROM
dws_order
GROUP BY
period, province;
条件过滤
Having 与 Where
在 SQL 定义中,Having 可以与聚合函数处理过的字段一起使用,而 Where 只能用于原始字段。在 BI 模型中,往往将 Having 用于结果筛选,Where 用于条件筛选。注意在 Mysql 中 Having 字段是会忽略索引的存在的,所以日常业务中,如非必要,请优先使用 Where 进行限定。
Mysql在下面的示例中,Where 部分是针对原始字段的筛选,Having 部分是对聚合字段的筛选,两者不可互换。
SELECT
DATE_FORMAT( created_at, '%Y') as `peroid`,
ROUND( COALESCE ( SUM( purchase_quantity ), 0 ) / COUNT( DISTINCT buyer_id ), 2 ) AS quota_mean
FROM
dws_order
-- 这里的 where 可以用到 Mysql 的索引特性,快速减少后续数据集的大小
WHERE province = '浙江省'
GROUP BY peroid
HAVING quota_mean > 4;
当前你可以使用嵌套的 SELECT 语句实现等价效果:
SELECT
*
FROM
(
SELECT
DATE_FORMAT( created_at, '%Y' ) AS `peroid`,
ROUND( COALESCE ( SUM( purchase_quantity ), 0 ) / COUNT( DISTINCT buyer_id ), 2 ) AS quota_mean
FROM
dws_order
WHERE
province = '浙江省'
GROUP BY peroid
) t1
WHERE
t1.quota_mean > 4;
ClickHouse 再举一个 ClickHouse 的例子,除了时间格式化函数外无其他改动:
SELECT
formatDateTime( created_at, '%Y') as `peroid`,
ROUND( COALESCE ( SUM( purchase_quantity ), 0 ) / COUNT( DISTINCT buyer_id ), 2 ) AS quota_mean
FROM
dws_order
-- 这里的 where 可以用到 Mysql 的索引特性,快速减少后续数据集的大小
WHERE province = '浙江省'
GROUP BY peroid
HAVING quota_mean > 4;
索引与大数据查询引擎
大数据查询引擎如 Doris、Presto、Hive 等,究竟有没有索引?
这是初次接触大数据查询引擎的业务童鞋,最常碰到的困惑。笔者对这块未有深入研究,但查阅相关技术文档发现几个查询引擎,都会有类似索引的概念。
但在项目实施中,很少听到大家谈起索引,这是为什么?Doris 文档内有这么一句话,引发了一些思考:
不同于传统的数据库设计,Doris 不支持在任意列上创建索引。Doris 这类 MPP 架构的 OLAP 数据库,通常都是通过提高并发,来处理大量数据的。
类比到 OLAP 系统中,虽然指标涉及的字段是确定的,但通常会对该类字段使用聚合函数,这时候索引大概率是失效的;相对的,虽然部分维度字段上不会使用聚合函数,但你无法确定用户会选择使用哪些维度,这会导致索引命中率低下,贸然加索引的性价比也很低。这时候听到更多的是,我们上了 xCxG 机器多少台,并发处理能力如何之类的讨论。
我们讨论索引是为了查询性能,性能提升有一个通用的点是:如何快速缩小目标数据集?
所以我们通常对数据进行分区,进行数据查询的时候,通过 where 语句指定分区查询范围是常见的优化手段之一。
With 语句
在 OLAP 系统中经常用到的语句,如果想要在 Mysql 中使用,需要升级到 8.0 才支持,详细文档可见 Mysql 8 with clause。
简单来说,通过 With 语句我们可以提前生成临时结果集,该临时结果集在后续 CURD 过程中可以实现复用。如果语句设计合理,这将大幅减少数据传输和重复计算,提升 SQL 语句性能。
with_clause:
WITH [RECURSIVE]
cte_name [(col_name [, col_name] ...)] AS (subquery)
[, cte_name [(col_name [, col_name] ...)] AS (subquery)] ...
我们同样举个小例子,随着企业数据分析能力的增强,运营同学开始把数字化营销、精准营销挂在嘴边,这些通常依赖对用户特征的标记,也可称之为用户画像。假如我们的报表中,需要按照用户画像进行聚合,我们可以提前把画像分组存入临时表,下述 SQL 的功能是:不同用户分群下的人均购买商品数,MysqlClickHouse 均可运行。
WITH portrait_user AS (
SELECT
user_id,
CASE group_id
WHEN 1 THEN
'NormalUser'
WHEN 2 THEN
'GoldUser'
ELSE
'PlatinumUser'
END AS `group_name`
FROM portrait
)
SELECT
t2.group_name,
ROUND( COALESCE ( SUM( purchase_quantity ), 0 ) / COUNT( DISTINCT buyer_id ), 2 ) AS quota_mean
FROM dws_order t1
LEFT JOIN portrait_user t2 ON t1.buyer_id = t2.user_id
GROUP BY t2.group_name;
-- result
┌─group_name───┬─quota_mean─┐
│ PlatinumUser │ 5 │
│ NormalUser │ 5 │
│ ᴺᵁᴸᴸ │ 30 │
│ GoldUser │ 20 │
└──────────────┴────────────┘
上述语句在 gruop_name 部分,可能会出现空值的情况,下节我们将做讨论。
:::danger
从此示例开始,由于需要用到 FULL JOIN 等特性,Mysql 已经无法完整运行
我们需要切换到 ClickHouse 进行实验
:::
Join 方式
-- Join 语法格式定义
<join_type> ::=
[ { INNER | { { LEFT | RIGHT | FULL } [ OUTER ] } } [ <join_hint> ] ]
JOIN
依据 sql 查询对 join 的定义,OUTER 是可选的,事实上 join 查询可分为两大类:
- INNER
INNER JOIN:数据左右表同时存在才返回,同时也是默认 JOIN 的默认类型,所以A INNER JOIN B = A JOIN B
- OUTER
LEFT OUTER JOIN:数据只要左表内存在就返回,OUTER 可以省略,所以A LEFT OUTER JOIN B = A LEFT JOIN BRIGHT OUTER JOIN:数据只要右表内存在就返回,OUTER 可以省略,所以A RIGHT OUTER JOIN B = A RIGHT JOIN BFULL OUTER JOIN:数据只要左右任一表内存在就返回,OUTER 可以省略,所以A FULL OUTER JOIN B = A FULL JOIN B
ClickHouse在开始正式实验之前,我们新增指标:“应用访问 PV”,生成 dws_visit_history 宽表的 SQL 如下:
-- 清空旧数据,批处理一般都是 T + 1 的逻辑,会全量重新生成数据
TRUNCATE TABLE dws_visit_history;
-- 以事实表为基础,通过关联字段从维度表中抽取需要的字段,最终填入宽表 dws_order 之中
INSERT INTO dws_visit_history (
`trace_id`, `user_id`, `user_name`, `province`, `created_at`
) SELECT
t1.trace_id,
t1.user_id,
d1.`name` AS user_name,
d1.province,
t1.created_at
FROM
`visit_history` t1
LEFT JOIN `user` d1 ON t1.user_id = d1.user_id;
指标的聚合公式定义如下:
COUNT(user_id)
ClickHouse 注意:为了使不存在的记录,填充 NULL 值而非空值,以便使用 coalesce,需要配置 Processing of Empty or NULL Cells,接下来的示例中使用的是在会话中使用命令配置的方式。
Inner Join 示例
延续之前用户画像的例子,当画像数据出现在分析语句中的时候,除了对用户进行特征标记外,还有过滤数据的作用。在之前的示例中,我们可以加上 where in 画像分组 的限定条件来进行数据过滤,但实际业务中会利用如下等式进行转换:
A LEFT JOIN B WHERE A IN B = A INNER JOIN B
ClickHouse 转换后的 SQL 如下:
WITH portrait_user AS (
SELECT
user_id,
CASE group_id
WHEN 1 THEN
'NormalUser'
WHEN 2 THEN
'GoldUser'
ELSE
''
END AS `group_name`
-- 在 with 子查询内,可以选定需要比对的用户分组
FROM portrait WHERE group_id in (1,2)
)
SELECT
t2.group_name,
ROUND( COALESCE ( SUM( purchase_quantity ), 0 ) / COUNT( DISTINCT buyer_id ), 2 ) AS quota_mean
FROM dws_order t1
-- 改动点,在过滤数据的同时,可以防止 group_name 列存在空值。
INNER JOIN portrait_user t2 ON t1.buyer_id = t2.user_id
GROUP BY t2.group_name;
-- result
┌─group_name─┬─quota_mean─┐
│ GoldUser │ 20 │
│ NormalUser │ 5 │
└────────────┴────────────┘
Full Join 示例
ClickHouse 这次的需求是,将 “应用访问 PV” 和 “人均购买商品数” 在省份维度 + 用户类型维度进行比对:
-- Empty cells are filled with NULL
SET join_use_nulls=1;
WITH portrait_user AS (
SELECT
user_id,
CASE group_id
WHEN 1 THEN 'NormalUser'
WHEN 2 THEN 'GoldUser'
WHEN 3 THEN 'PlatinumUser'
ELSE ''
END AS `group_name`
-- 在 with 子查询内,可以选定需要比对的用户分组
FROM portrait WHERE group_id in (1,2,3)
)
SELECT
coalesce(qa.group_name, qb.group_name) as group_name,
coalesce(qa.province, qb.province) as province,
quota_pv,
quota_mean
FROM
-- 指标 A
(
SELECT
t2.group_name,
t1.province,
COUNT(user_id) AS quota_pv
FROM dws_visit_history t1
-- 改动点,在过滤数据的同时,可以防止 group_name 列存在空值。
INNER JOIN portrait_user t2 ON t1.user_id = t2.user_id
GROUP BY t2.group_name, t1.province
) qa
-- 连接方式为 FULL JOIN
FULL JOIN
-- 指标 B
(
SELECT
t2.group_name,
t1.province,
ROUND( COALESCE ( SUM( purchase_quantity ), 0 ) / COUNT( DISTINCT buyer_id ), 2 ) AS quota_mean
FROM dws_order t1
-- 改动点,在过滤数据的同时,可以防止 group_name 列存在空值。
INNER JOIN portrait_user t2 ON t1.buyer_id = t2.user_id
GROUP BY t2.group_name, t1.province
) qb ON qa.group_name = qb.group_name AND qa.province = qb.province;
-- result
┌─group_name───┬─province─┬─quota_pv─┬─quota_mean─┐
│ GoldUser │ 浙江省 │ 2 │ 20 │
│ PlatinumUser │ 江苏省 │ 3 │ 5 │
│ NormalUser │ 江苏省 │ 1 │ 6 │
│ NormalUser │ 浙江省 │ 1 │ 4 │
└──────────────┴──────────┴──────────┴────────────┘
性能优化点 这里举一个性能优化的实践案例,在现实业务中经过优化之后,性能耗时降低在 50% 以上。
同样是指标比对的需求,在第一版实现中,数据处理的逻辑为:提取维度列 -> 提取指标数据
这里的提取维度列成了耗时的前置依赖,后续的 Left Join 合并都需要等待其完成后才能进行,下面的执行计划图直观的展示了这个等待过程。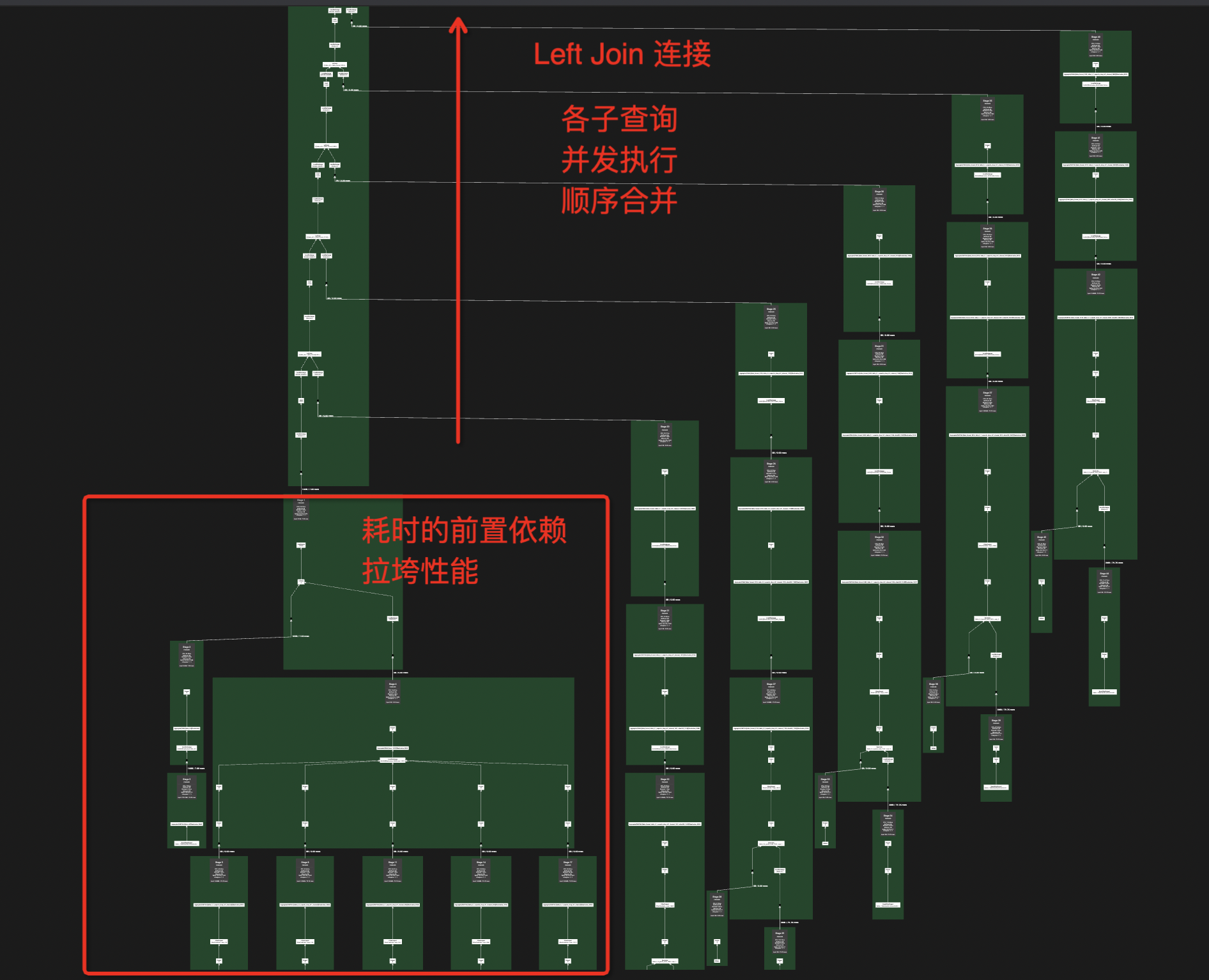
我们知道,对于大数据查询引擎的性能优化,最有效的手段是:充分利用其并行处理能力。
我们将 维度提取 + 指标提取 合并为一个子任务,再通过 FULL JOIN 对结果进行连接,通过下面的执行计划图,我们清楚地看到前置依赖消失了,各个任务 worker 可以并发地完成数据处理,相比于第一版方案,性能将近提升 50%,本文中的 FULL JOIN 就是该方案的简化版。
再开一个脑洞:FULL JOIN 是取并集,那么我们依据结合律,我们可以得出如下等式:
如果我们 FULL JOIN 子查询的结果,按照右侧方式进行合并,是不是可以把合并的时间复杂度从 O(N) 降低到 O(LogN),笔者未做此方面实验,读者可自行验证可行性。
分析模型
行文至此,日常开发的 SQL 模型都已经涵盖,下面补充几个特例。
下钻模型
下钻模型是在 “条件过滤” 阶段,添加 where 限制条件(很少见到 Having),相当于对数据源材料进行过滤。
其他并无特殊。
漏斗模型
现实世界中漏斗模型作用是:输入一定数量的实体,经过一系列过滤条件后,输出过滤结果。
在本案例中,过滤条件被实例化了成 “时间 + 判断条件” 的组合体。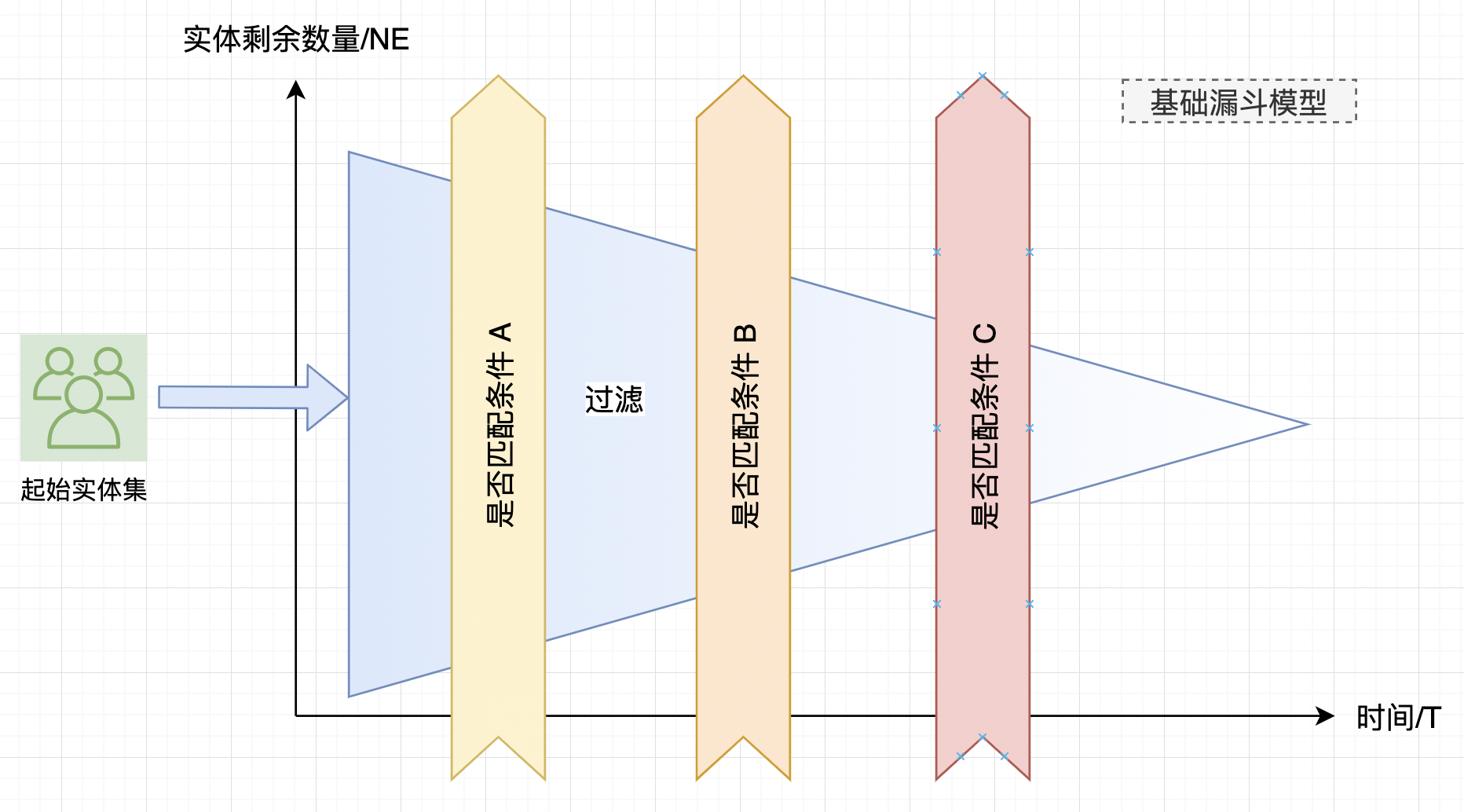
同样以现有数据举例:我们需要知道“用户浏览网站 -> 用户发生交易” 之间的漏斗转换率,
-- Empty cells are filled with NULL
SET join_use_nulls=1;
SELECT
-- 此处必须是 COUNT DISTINCT,因为多表交叉后,中间表会有重复数据
COUNT(DISTINCT trace_id) AS quota_pv,
COUNT(DISTINCT order_id) as quota_buy
FROM
-- 指标 A
(
SELECT
trace_id,
user_id
FROM dws_visit_history t1
-- 假如要看某省的转换率,只需要在第一个指标内添加字段筛选
-- WHERE conditon = ?
) qa
-- 连接方式为 LEFT JOIN,在漏斗模型中,前值存在的情况下,后值才有意义。
LEFT JOIN
-- 指标 B
(
SELECT
order_id,
buyer_id as user_id
FROM dws_order t1
) qb ON qa.user_id = qb.user_id;
-- result
┌─quota_pv─┬─quota_buy─┐
│ 9 │ 6 │
└──────────┴───────────┘
-- 中间表,对比源表会发现有重复数据
┌─trace_id─┬─user_id─┬─order_id─┬─qb.user_id─┐
│ 1 │ 1 │ 1 │ 1 │
│ 2 │ 2 │ 2 │ 2 │
│ 2 │ 2 │ 6 │ 2 │
│ 3 │ 3 │ 3 │ 3 │
│ 4 │ 4 │ 5 │ 4 │
│ 5 │ 5 │ 7 │ 5 │
│ 6 │ 4 │ 5 │ 4 │
│ 7 │ 3 │ 3 │ 3 │
│ 8 │ 4 │ 5 │ 4 │
│ 9 │ 6 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │
└──────────┴─────────┴──────────┴────────────┘
实际业务过程中,漏斗模型可能会和指标结合,这个时候在垂直角度,输出图形可能看起来忽胖忽瘦,不再是个标准的倒三角了,不作展开。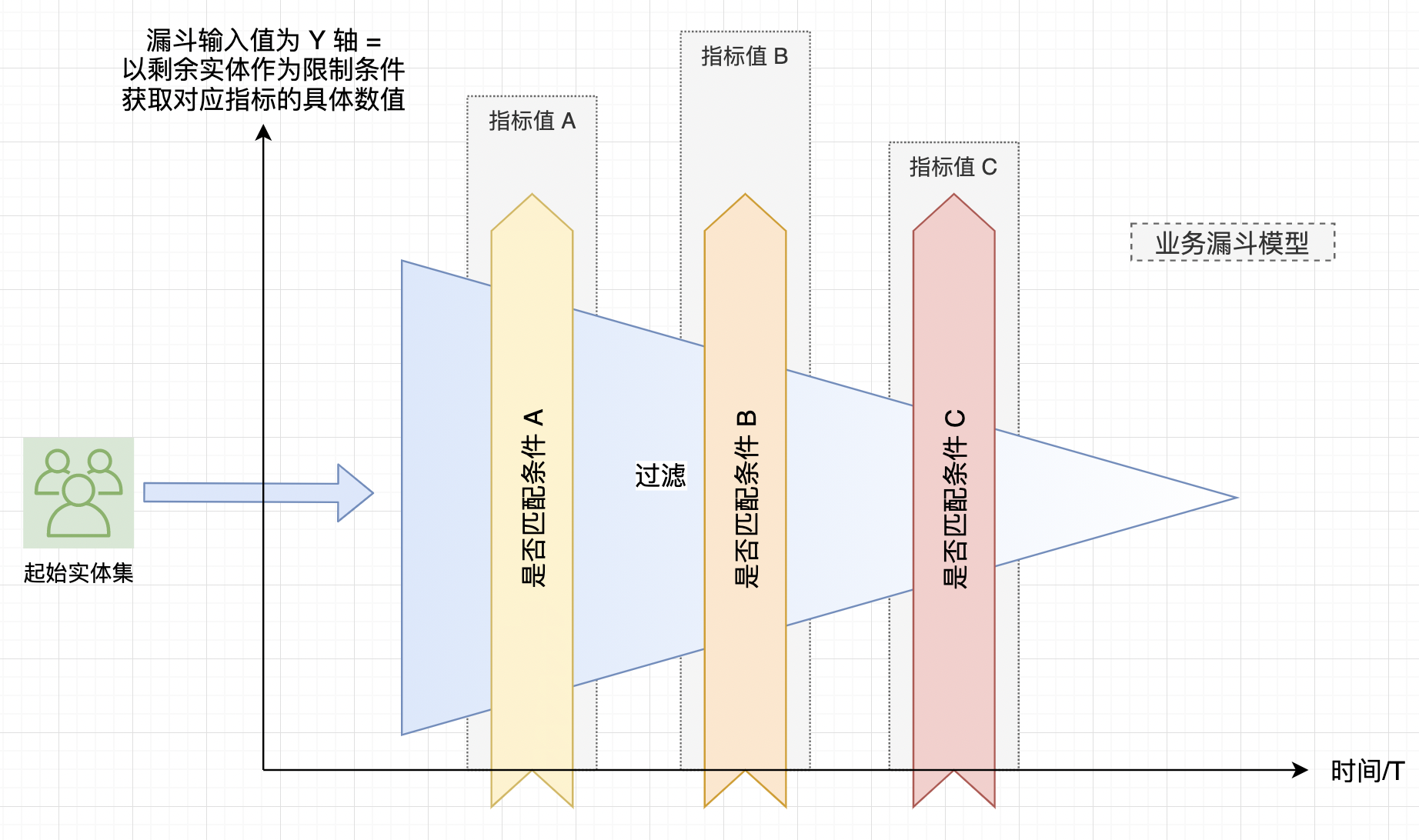
附录
ClickHouse 安装和使用指南
安装
安装可以直接参考官方文档的 QuickStart,无明显卡点,安装过程中的密码一定需要记住。
访问
对于 JAVA 开发来说,执行 SQL 建议直接使用 clickhouse-client 命令,查看数据可以使用 IDEA DataGrip
⚠️:有些语法在 DataGrip 里面显示错误,但在 clickhouse-client 的 CLI 上是可以执行的
clickhouse-client 建议开启多行模式,笔者客户端的 /etc/clickhouse-client/config.xml 配置文件有如下配置,可做参考:
<config>
<user>default</user>
<password>xxxxxxx</password>
<database>bi</database>
<multiline>1</multiline>
<multiquery>1</multiquery>
</config>
数据初始化
直接执行文件:ClickHouseTable.sql.zip
两个宽表的数据,需要后期生成,生成方式见正文。
关于性能优化的方向
- 选择合适的大数据引擎,比如单纯从 Hive(磁盘 IO)迁移到 Presto(基于内存),就可提升 3 倍以上的性能。
- 修改 SQL 模型适配特定大数据引擎,利用其并发处理能力提升性能,对于 OLAP 系统来说,并发优化的收益大于索引优化。
- 关于成本可以参考阿里云:大数据集群机器一般 8C64G 起步
参考资料
- 宽表和窄表的区别 - 知乎云水禅心(https://zhuanlan.zhihu.com/p/140420911)
- Mysql 5.7 - 12.7 Date and Time Functions(https://dev.mysql.com/doc/refman/5.7/en/date-and-time-functions.html#function_date-format)
- Doris Doc(https://doris.apache.org/master/zh-CN/getting-started/data-model-rollup.html#rollup)
- 使用Presto SQL一些常见问题总结 - segmentfault(https://segmentfault.com/a/1190000013615017)
- Mysql 8.0 13.2.15 WITH (Common Table Expressions)(https://dev.mysql.com/doc/refman/8.0/en/with.html)
- LEFT JOIN vs. LEFT OUTER JOIN in SQL Server - StackOverflow(https://stackoverflow.com/questions/406294/left-join-vs-left-outer-join-in-sql-server)

若有收获,就点个赞吧
0 人点赞
