OSI 分层模型
参考:https://int0x33.medium.com/day-51-understanding-the-osi-model-f22d5f3df756
ASCII
Control code chart
| Binary | Oct | Dec | Hex | Abbreviation | [b] | [c] | [d] | Name (1967) | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 1963 | 1965 | 1967 | ||||||||
| 000 0000 | 000 | 0 | 00 | NULL | NUL | ␀ | ^@ | \0 | Null | |
| 000 0001 | 001 | 1 | 01 | SOM | SOH | ␁ | ^A | Start of Heading | ||
| 000 0010 | 002 | 2 | 02 | EOA | STX | ␂ | ^B | Start of Text | ||
| 000 0011 | 003 | 3 | 03 | EOM | ETX | ␃ | ^C | End of Text | ||
| 000 0100 | 004 | 4 | 04 | EOT | ␄ | ^D | End of Transmission | |||
| 000 0101 | 005 | 5 | 05 | WRU | ENQ | ␅ | ^E | Enquiry | ||
| 000 0110 | 006 | 6 | 06 | RU | ACK | ␆ | ^F | Acknowledgement | ||
| 000 0111 | 007 | 7 | 07 | BELL | BEL | ␇ | ^G | \a | Bell | |
| 000 1000 | 010 | 8 | 08 | FE0 | BS | ␈ | ^H | \b | Backspace [e] [f] |
|
| 000 1001 | 011 | 9 | 09 | HT/SK | HT | ␉ | ^I | \t | Horizontal Tab [g] |
|
| 000 1010 | 012 | 10 | 0A | LF | ␊ | ^J | \n | Line Feed | ||
| 000 1011 | 013 | 11 | 0B | VTAB | VT | ␋ | ^K | \v | Vertical Tab | |
| 000 1100 | 014 | 12 | 0C | FF | ␌ | ^L | \f | Form Feed | ||
| 000 1101 | 015 | 13 | 0D | CR | ␍ | ^M | \r | Carriage Return [h] |
||
| 000 1110 | 016 | 14 | 0E | SO | ␎ | ^N | Shift Out | |||
| 000 1111 | 017 | 15 | 0F | SI | ␏ | ^O | Shift In | |||
| 001 0000 | 020 | 16 | 10 | DC0 | DLE | ␐ | ^P | Data Link Escape | ||
| 001 0001 | 021 | 17 | 11 | DC1 | ␑ | ^Q | Device Control 1 (often XON ) |
|||
| 001 0010 | 022 | 18 | 12 | DC2 | ␒ | ^R | Device Control 2 | |||
| 001 0011 | 023 | 19 | 13 | DC3 | ␓ | ^S | Device Control 3 (often XOFF ) |
|||
| 001 0100 | 024 | 20 | 14 | DC4 | ␔ | ^T | Device Control 4 | |||
| 001 0101 | 025 | 21 | 15 | ERR | NAK | ␕ | ^U | Negative Acknowledgement | ||
| 001 0110 | 026 | 22 | 16 | SYNC | SYN | ␖ | ^V | Synchronous Idle | ||
| 001 0111 | 027 | 23 | 17 | LEM | ETB | ␗ | ^W | End of Transmission Block | ||
| 001 1000 | 030 | 24 | 18 | S0 | CAN | ␘ | ^X | Cancel | ||
| 001 1001 | 031 | 25 | 19 | S1 | EM | ␙ | ^Y | End of Medium | ||
| 001 1010 | 032 | 26 | 1A | S2 | SS | SUB | ␚ | ^Z | Substitute | |
| 001 1011 | 033 | 27 | 1B | S3 | ESC | ␛ | ^[ | \e[i] | Escape [j] |
|
| 001 1100 | 034 | 28 | 1C | S4 | FS | ␜ | ^\ | File Separator | ||
| 001 1101 | 035 | 29 | 1D | S5 | GS | ␝ | ^] | Group Separator | ||
| 001 1110 | 036 | 30 | 1E | S6 | RS | ␞ | ^^[k] | Record Separator | ||
| 001 1111 | 037 | 31 | 1F | S7 | US | ␟ | ^_ | Unit Separator | ||
| 111 1111 | 177 | 127 | 7F | DEL | ␡ | ^? | Delete [l] [f] |
Other representations might be used by specialist equipment, for example ISO 2047 graphics or hexadecimal numbers.
Printable characters
Codes 20hex to 7Ehex, known as the printable characters, represent letters, digits, punctuation marks, and a few miscellaneous symbols. There are 95 printable characters in total.[m]
Code 20hex, the “space” character), denotes the space between words, as produced by the space bar of a keyboard. Since the space character is considered an invisible graphic (rather than a control character)[3]:223[46] it is listed in the table below instead of in the previous section.
Code 7Fhex corresponds to the non-printable “delete” (DEL) control character and is therefore omitted from this chart; it is covered in the previous section’s chart. Earlier versions of ASCII used the up arrow instead of the caret (5Ehex) and the left arrow instead of the underscore (5Fhex).[5][47]
| Binary | Oct | Dec | Hex | Glyph | ||
|---|---|---|---|---|---|---|
| 1963 | 1965 | 1967 | ||||
| 010 0000 | 040 | 32 | 20 | space) | ||
| 010 0001 | 041 | 33 | 21 | ! | ||
| 010 0010 | 042 | 34 | 22 | “ | ||
| 010 0011 | 043 | 35 | 23 | # | ||
| 010 0100 | 044 | 36 | 24 | $ | ||
| 010 0101 | 045 | 37 | 25 | % | ||
| 010 0110 | 046 | 38 | 26 | & | ||
| 010 0111 | 047 | 39 | 27 | ‘ | ||
| 010 1000 | 050 | 40 | 28 | ( | ||
| 010 1001 | 051 | 41 | 29 | ) | ||
| 010 1010 | 052 | 42 | 2A | * | ||
| 010 1011 | 053 | 43 | 2B | + | ||
| 010 1100 | 054 | 44 | 2C | , | ||
| 010 1101 | 055 | 45 | 2D | - | ||
| 010 1110 | 056 | 46 | 2E | . | ||
| 010 1111 | 057 | 47 | 2F | /) | ||
| 011 0000 | 060 | 48 | 30 | 0) | ||
| 011 0001 | 061 | 49 | 31 | 1) | ||
| 011 0010 | 062 | 50 | 32 | 2) | ||
| 011 0011 | 063 | 51 | 33 | 3) | ||
| 011 0100 | 064 | 52 | 34 | 4) | ||
| 011 0101 | 065 | 53 | 35 | 5) | ||
| 011 0110 | 066 | 54 | 36 | 6) | ||
| 011 0111 | 067 | 55 | 37 | 7) | ||
| 011 1000 | 070 | 56 | 38 | 8) | ||
| 011 1001 | 071 | 57 | 39 | 9) | ||
| 011 1010 | 072 | 58 | 3A | :) | ||
| 011 1011 | 073 | 59 | 3B | ; | ||
| 011 1100 | 074 | 60 | 3C | < | ||
| 011 1101 | 075 | 61 | 3D | = | ||
| 011 1110 | 076 | 62 | 3E | > | ||
| 011 1111 | 077 | 63 | 3F | ? | ||
| 100 0000 | 100 | 64 | 40 | @ | ` | @ |
| 100 0001 | 101 | 65 | 41 | A | ||
| 100 0010 | 102 | 66 | 42 | B | ||
| 100 0011 | 103 | 67 | 43 | C | ||
| 100 0100 | 104 | 68 | 44 | D | ||
| 100 0101 | 105 | 69 | 45 | E | ||
| 100 0110 | 106 | 70 | 46 | F | ||
| 100 0111 | 107 | 71 | 47 | G | ||
| 100 1000 | 110 | 72 | 48 | H | ||
| 100 1001 | 111 | 73 | 49 | I | ||
| 100 1010 | 112 | 74 | 4A | J | ||
| 100 1011 | 113 | 75 | 4B | K | ||
| 100 1100 | 114 | 76 | 4C | L | ||
| 100 1101 | 115 | 77 | 4D | M | ||
| 100 1110 | 116 | 78 | 4E | N | ||
| 100 1111 | 117 | 79 | 4F | O | ||
| 101 0000 | 120 | 80 | 50 | P | ||
| 101 0001 | 121 | 81 | 51 | Q | ||
| 101 0010 | 122 | 82 | 52 | R | ||
| 101 0011 | 123 | 83 | 53 | S | ||
| 101 0100 | 124 | 84 | 54 | T | ||
| 101 0101 | 125 | 85 | 55 | U | ||
| 101 0110 | 126 | 86 | 56 | V | ||
| 101 0111 | 127 | 87 | 57 | W | ||
| 101 1000 | 130 | 88 | 58 | X | ||
| 101 1001 | 131 | 89 | 59 | Y | ||
| 101 1010 | 132 | 90 | 5A | Z | ||
| 101 1011 | 133 | 91 | 5B | [ | ||
| 101 1100 | 134 | 92 | 5C | \ | ~ | \ |
| 101 1101 | 135 | 93 | 5D | ] | ||
| 101 1110 | 136 | 94 | 5E | ↑) | ^ | |
| 101 1111 | 137 | 95 | 5F | ←) | _ | |
| 110 0000 | 140 | 96 | 60 | @ | ` | |
| 110 0001 | 141 | 97 | 61 | a | ||
| 110 0010 | 142 | 98 | 62 | b | ||
| 110 0011 | 143 | 99 | 63 | c | ||
| 110 0100 | 144 | 100 | 64 | d | ||
| 110 0101 | 145 | 101 | 65 | e | ||
| 110 0110 | 146 | 102 | 66 | f | ||
| 110 0111 | 147 | 103 | 67 | g | ||
| 110 1000 | 150 | 104 | 68 | h | ||
| 110 1001 | 151 | 105 | 69 | i | ||
| 110 1010 | 152 | 106 | 6A | j | ||
| 110 1011 | 153 | 107 | 6B | k | ||
| 110 1100 | 154 | 108 | 6C | l | ||
| 110 1101 | 155 | 109 | 6D | m | ||
| 110 1110 | 156 | 110 | 6E | n | ||
| 110 1111 | 157 | 111 | 6F | o | ||
| 111 0000 | 160 | 112 | 70 | p | ||
| 111 0001 | 161 | 113 | 71 | q | ||
| 111 0010 | 162 | 114 | 72 | r | ||
| 111 0011 | 163 | 115 | 73 | s | ||
| 111 0100 | 164 | 116 | 74 | t | ||
| 111 0101 | 165 | 117 | 75 | u | ||
| 111 0110 | 166 | 118 | 76 | v | ||
| 111 0111 | 167 | 119 | 77 | w | ||
| 111 1000 | 170 | 120 | 78 | x | ||
| 111 1001 | 171 | 121 | 79 | y | ||
| 111 1010 | 172 | 122 | 7A | z | ||
| 111 1011 | 173 | 123 | 7B | { | ||
| 111 1100 | 174 | 124 | 7C | ACK | ¬ | | |
| 111 1101 | 175 | 125 | 7D | } | ||
| 111 1110 | 176 | 126 | 7E | ESC | | | ~ |
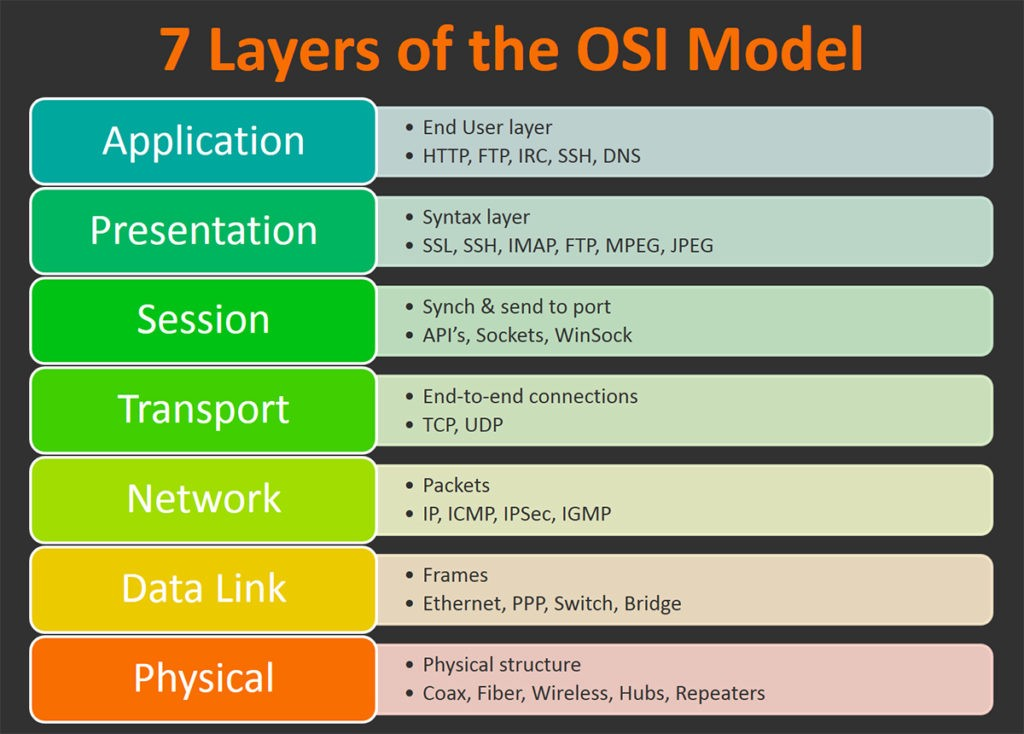
传输层:UDP
UDP 特征:
- 简单,行为表现同 IP 层更像
- 以包为单位发送数据
- 无状态服务
DHCP(Dynamic Host Configuration Protocol)就是基于 UDP 协议的。
再则,想要把 TCP 做的保证由应用层实现的时候,可以使用 UDP 协议。
示例应用场景:
- 移动网络下 Google 的 Quic 协议
- 流媒体播放场景、直播业务场景
- 游戏场景
- 物联网场景,例如 Google 旗下的 Thread 协议
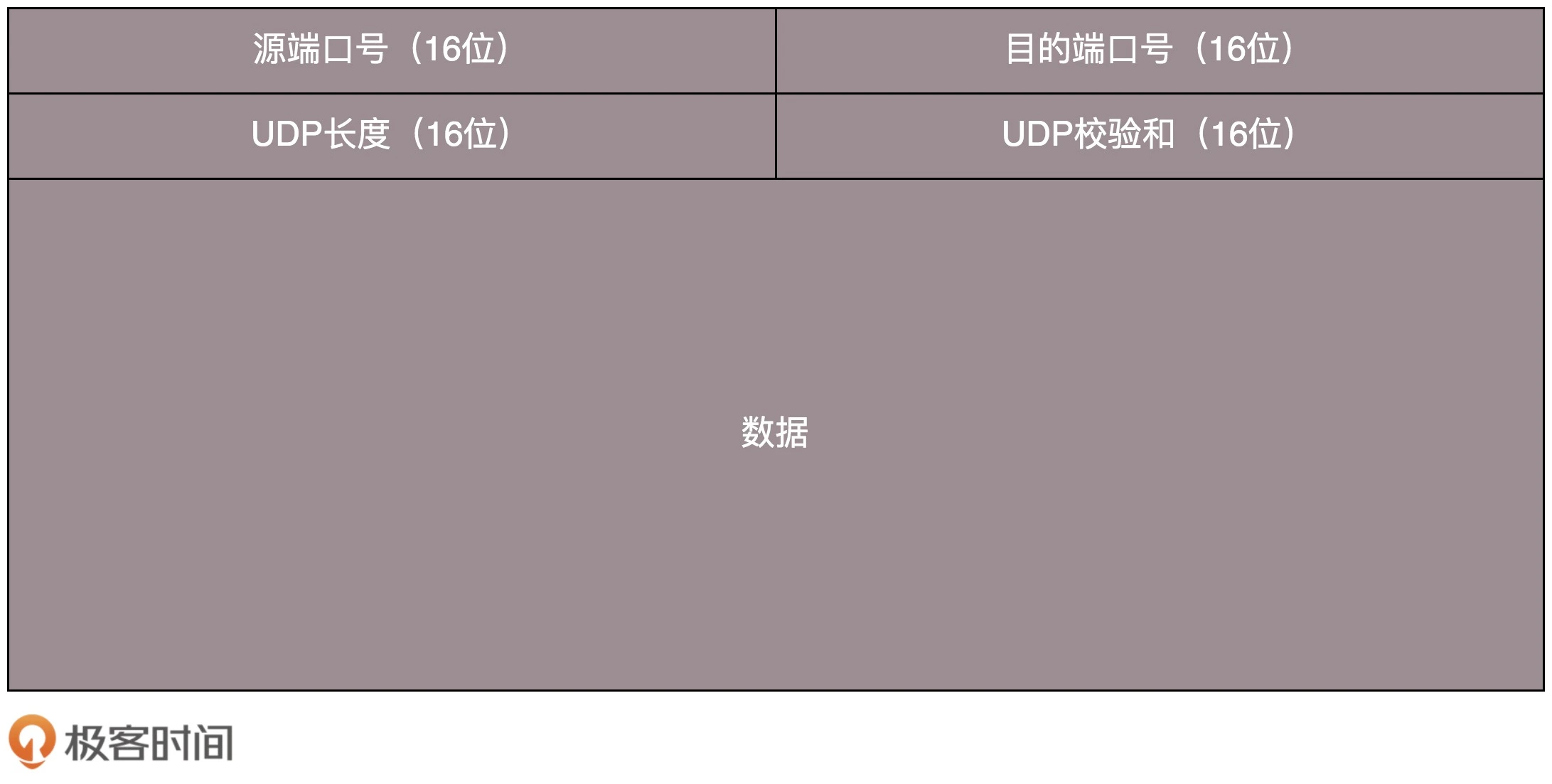
传输层:TCP
第11讲 | TCP协议(上):因性恶而复杂,先恶后善反轻松 第12讲 | TCP协议(下):西行必定多妖孽,恒心智慧消磨难
TCP 特征:
- 提供可靠交付
- 面向字节流
- 拥有阻塞控制
- 有状态服务
状态位:
- SYN:发起连接
- ACK:回复收到
- RST:重新连接
- FIN:结束连接
- PSH:推送数据
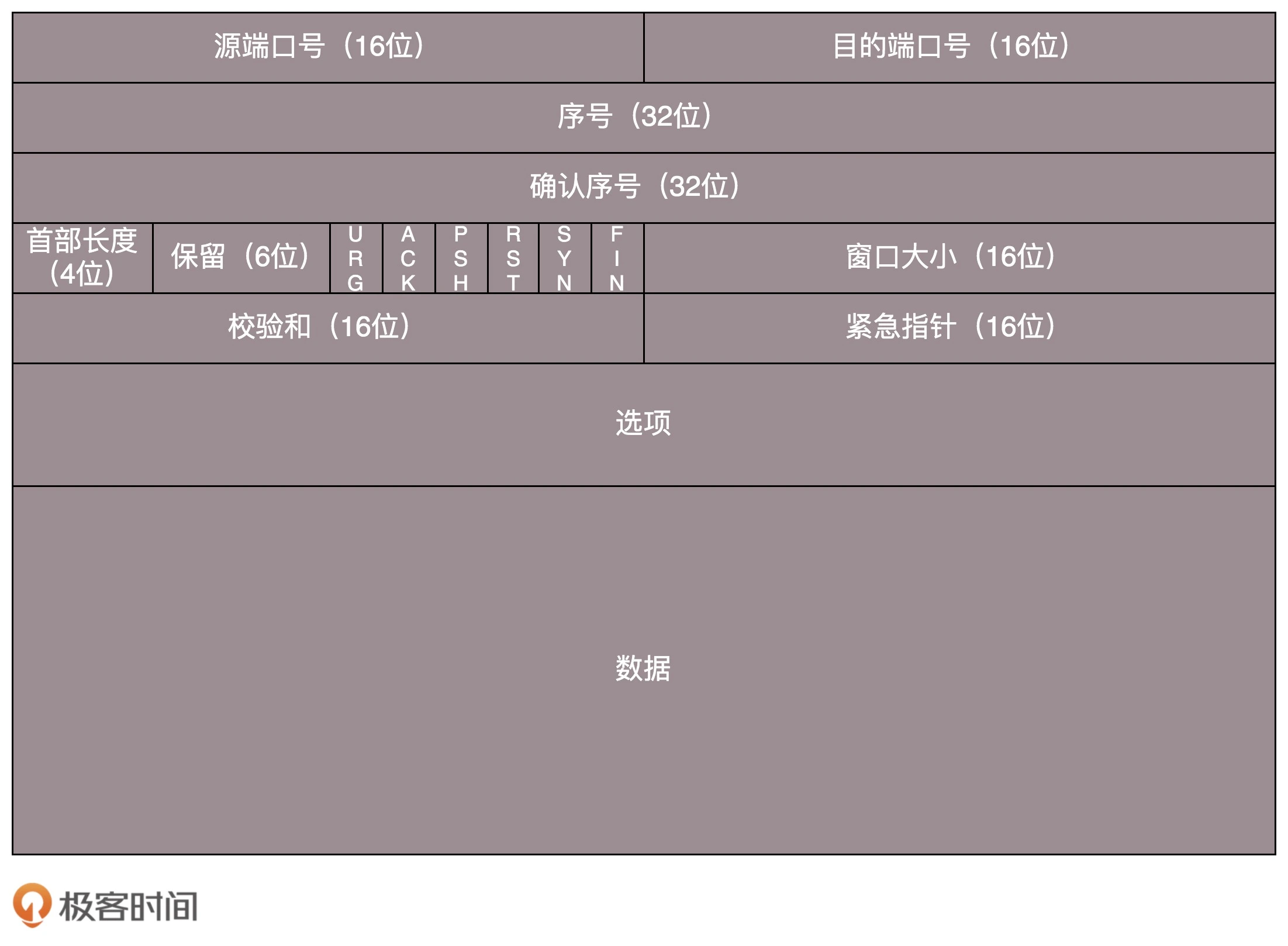
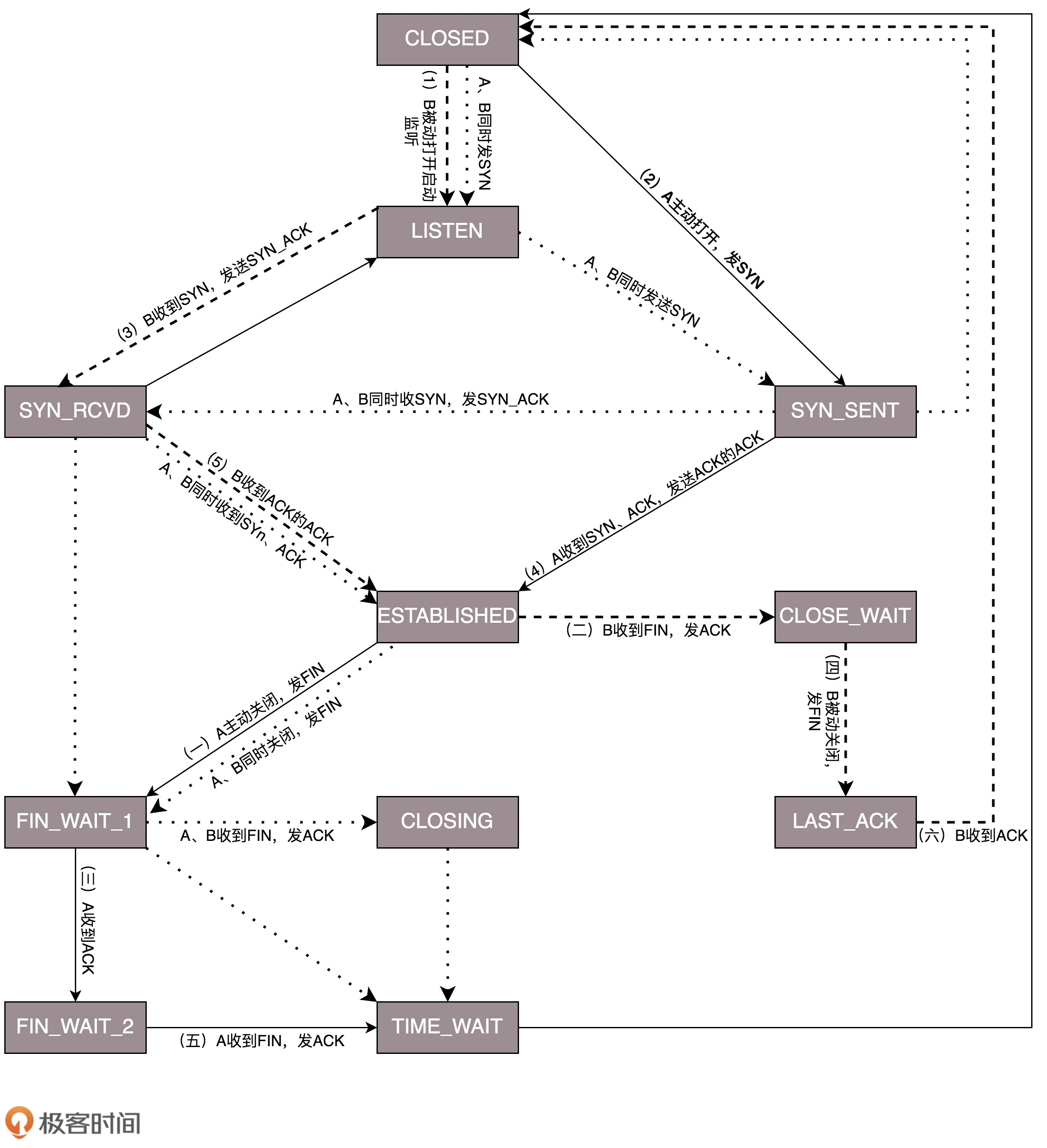
三次握手和四次挥手 🤝
Accpet 发生在三次握手之后
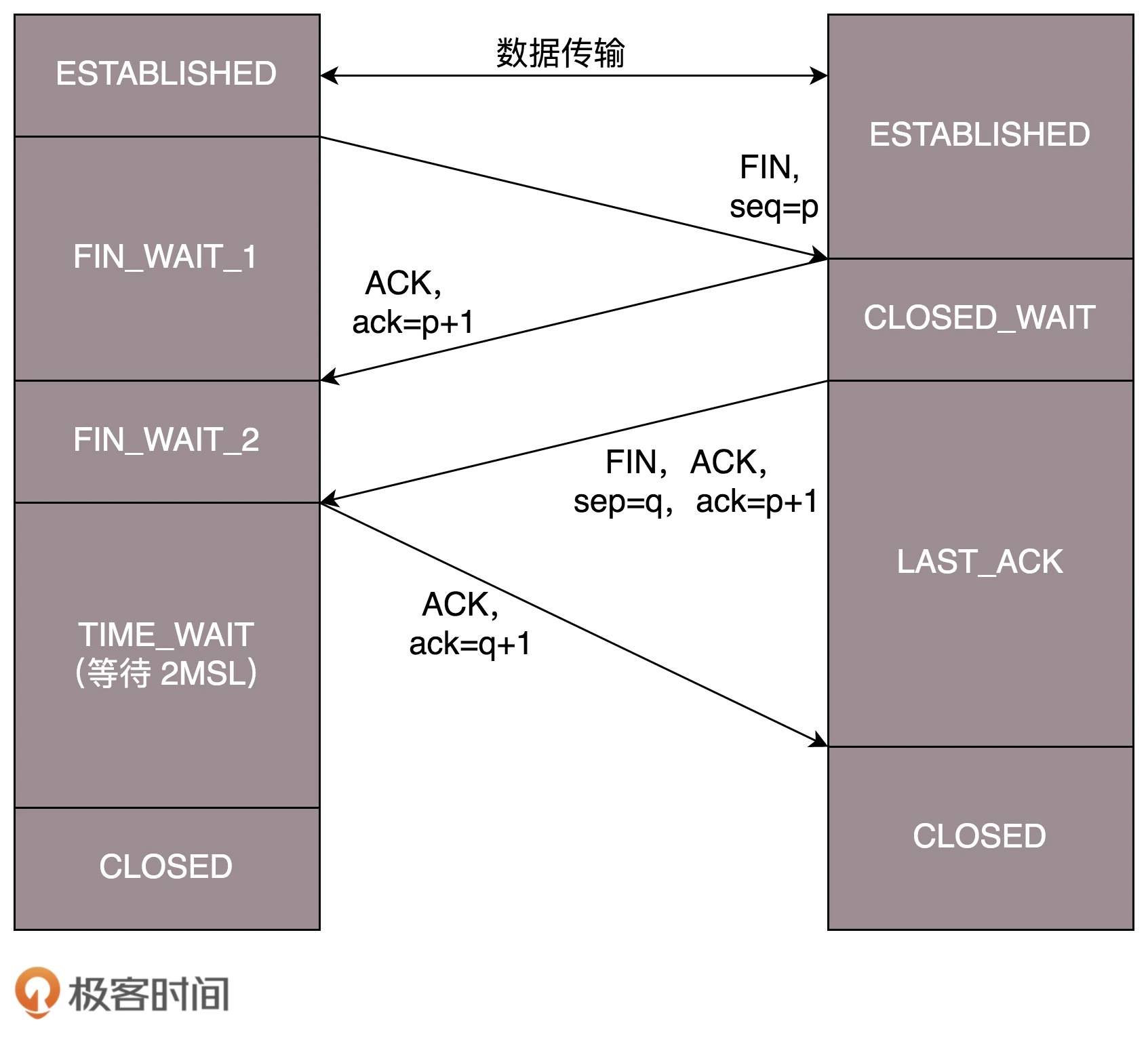
B 超过了 2MSL 的时间,依然没有收到它发的 FIN 的 ACK,怎么办呢?按照 TCP 的原理,B 当然还会重发 FIN,这个时候 A 再收到这个包之后,A 就表示,我已经在这里等了这么长时间了,已经仁至义尽了,之后的我就都不认了,于是就直接发送 RST,B 就知道 A 早就跑了。
滑动窗口
年少有为知进退
发送端数据结构: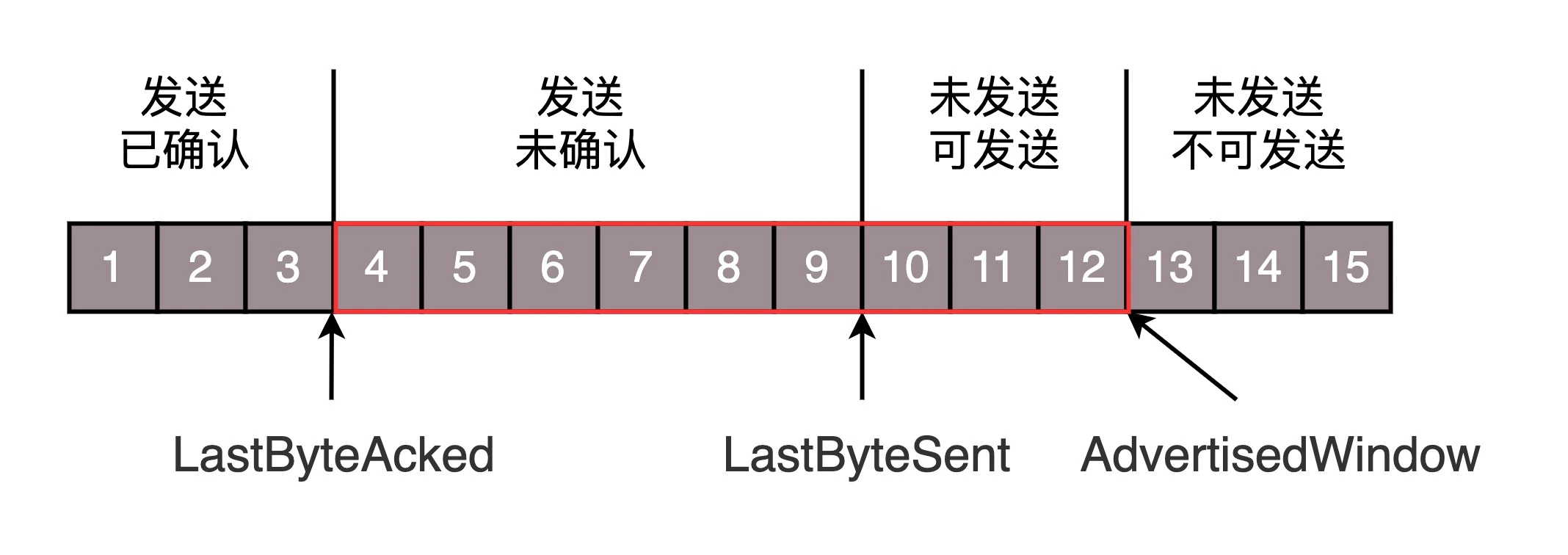
接收端数据结构: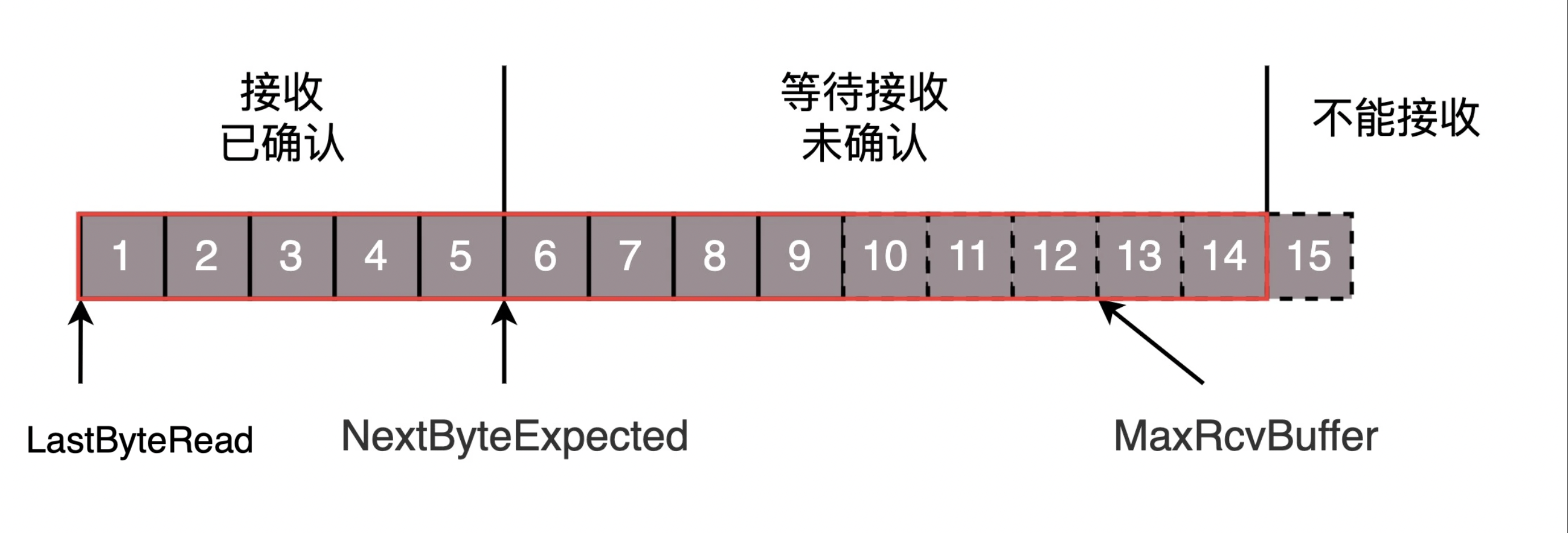
- MaxRcvBuffer:最大缓存的量;
- LastByteRead 之后是已经接收了,但是还没被应用层读取的;
- NextByteExpected 是第一部分和第二部分的分界线。
AdvertisedWindow=MaxRcvBuffer-((NextByteExpected-1)-LastByteRead)
重传和重试策略
针对发送方
- 采用 自适应重传算法 对没有 ACK 的回复的数据进行重传
- 重试间隔不能小于 RTT
- TCP 的策略是超时间隔加倍。每当遇到一次超时重传的时候,都会将下一次超时时间间隔设为先前值的两倍。两次超时,就说明网络环境差,不宜频繁反复发送
针对接受方:
- 使用 SACK(Selective Acknowledgment) 协议,将缓存地图发送给发送方,发送方可以有针对性的进行重传
流量控制 - rwnd
通过控制滑动窗口大小,防止发送方把接收方缓存塞满
拥塞控制 - cwnd
通过控制拥塞窗口的大小,防止把网络带宽塞满,通道的容量 = 带宽 × 往返延迟
这里有一个公式 LastByteSent - LastByteAcked <= min {cwnd, rwnd} ,是拥塞窗口和滑动窗口共同控制发送的速度。
TCP 的拥塞控制主要来避免两种现象:包丢失和超时重传。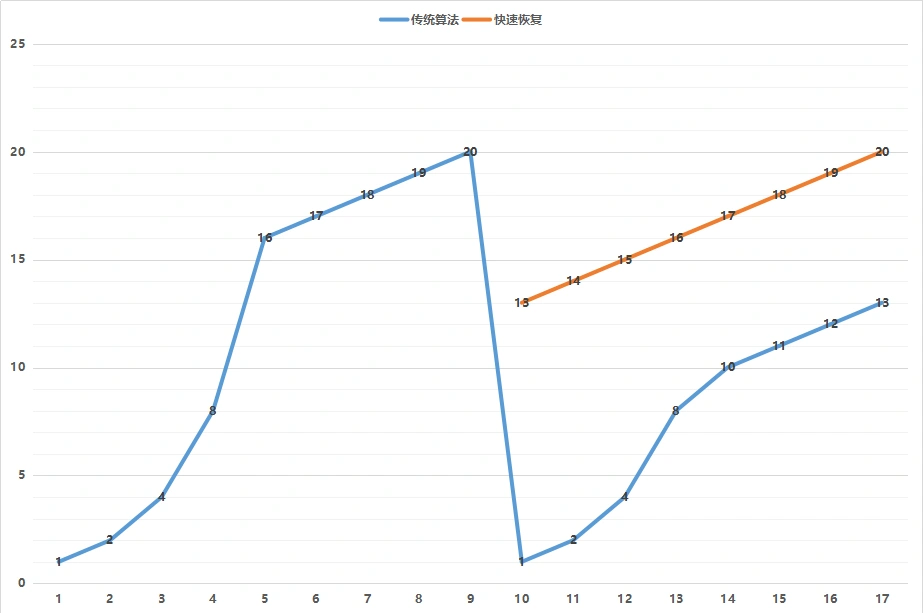
- 慢启动阈值 ssthresh(全称为 slow start threshold)
- 启动阶段是指数级增长,当达到 ssthresh(初始为 65535 字节)时,变成线性增长。
- 拥塞的一种表现形式是丢包,需要超时重传,这个时候,将 ssthresh 设为 cwnd/2,将 cwnd 设为 1,重新开始慢启动。这真是一旦超时重传,马上回到解放前。但是这种方式太激进了,将一个高速的传输速度一下子停了下来,会造成网络卡顿。
- 快速重传算法:当接收端发现丢了一个中间包的时候,发送三次前一个包的 ACK,于是发送端就会快速地重传,不必等待超时再重传。TCP 认为这种情况不严重,因为大部分没丢,只丢了一小部分,cwnd 减半为 cwnd/2,然后 sshthresh = cwnd,当三个包返回的时候,cwnd = sshthresh + 3,也就是没有一夜回到解放前,而是还在比较高的值,呈线性增长。
在评估合理窗口大小的时候,存在慢启动问题,可以通过调整初始拥塞窗口大小的方式来缓解,主流目前是 10 个 MSS(最大报文长度),而有些高速 CDN 站点,甚至把初始拥塞窗口提升到 70 个 MSS。
Cubic 算法 - 以丢包为界
TCP 默认的拥塞控制算法,每当收到一个 ACK 的时候,就需要调整拥塞窗口的大小。但是这也造成了一个后果,那就是 RTT 比较小的,窗口增长快。
然而这并不符合当前网络的真实状况,因为当前的网络带宽比较大,但是由于遍布全球,RTT 也比较长,因而基于 RTT 的窗口调整策略,不仅不公平,而且由于窗口增加慢,有时候带宽没满,数据就发送完了,因而巨大的带宽都浪费掉了。
CUBIC 进行了不同的设计,它的窗口增长函数仅仅取决于连续两次拥塞事件的时间间隔值,窗口增长完全独立于网络的时延 RTT。
CUBIC 的窗口大小以及变化过程如图所示: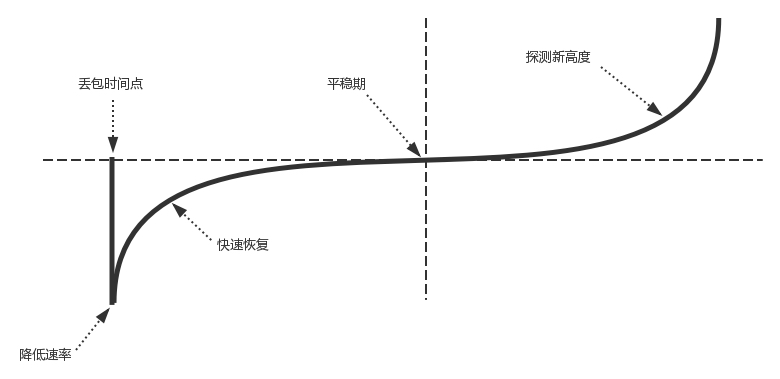
当出现丢包事件时,CUBIC 会记录这时的拥塞窗口大小,把它作为 Wmax。接着,CUBIC 会通过某个因子执行拥塞窗口的乘法减小,然后,沿着立方函数进行窗口的恢复。
从图中可以看出,一开始恢复的速度是比较快的,后来便从快速恢复阶段进入拥塞避免阶段,也即当窗口接近 Wmax 的时候,增加速度变慢;立方函数在 Wmax 处达到稳定点,增长速度为零,之后,在平稳期慢慢增长,沿着立方函数的开始探索新的最大窗口。
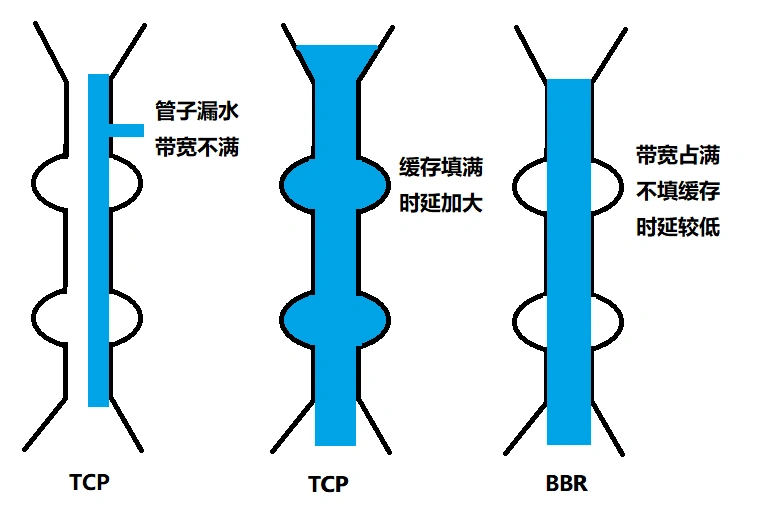
BBR 算法 - 以缓存导致速率下降为界
第一个问题是丢包并不代表着通道满了,也可能是管子本来就漏水。例如公网上带宽不满也会丢包,这个时候就认为拥塞了,退缩了,其实是不对的。
第二个问题是 TCP 的拥塞控制要等到将中间设备都填充满了,才发生丢包,从而降低速度,这时候已经晚了。其实 TCP 只要填满管道就可以了,不应该接着填,直到连缓存也填满。
为了优化这两个问题,后来有了 TCP BBR 拥塞算法。它企图找到一个平衡点,就是通过不断地加快发送速度,将管道填满,但是不要填满中间设备的缓存,因为这样时延会增加,在这个平衡点可以很好的达到高带宽和低时延的平衡。
应用层:Quic 协议
参考: 科普:QUIC协议原理分析 “三次握手,四次挥手”你真的懂吗? 为什么 TCP 协议有 TIME_WAIT 状态
特征:
- 0RTT
- 传输层 0RTT 就能建立连接
- 加密层 0RTT 就能建立加密连接
- 可插拔的拥塞控制机制
- 加密认证的报文
- QUIC 还能实现证书压缩,减少证书传输量,针对包头进行验证等
单调递增的 Packet Number
TCP 中的重传歧义性:无法确定 ACK 的是重传的包,还是原始请求的包。
如果算成原始请求的响应,但实际上是重传请求的响应(上图左),会导致采样 RTT 变大。如果算成重传请求的响应,但实际上是原始请求的响应,又很容易导致采样 RTT 过小。
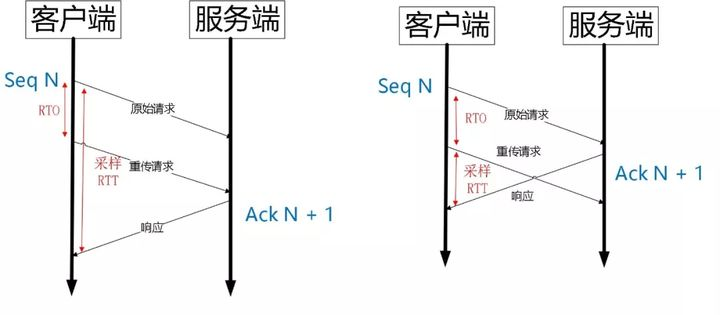
Quic 的单调递增的 Packet Number 解决了 TCP 的重传歧义性,但这同时会引发数据顺序性和可靠性的问题,所以 Quic 又引入了Stream Offset 的概念。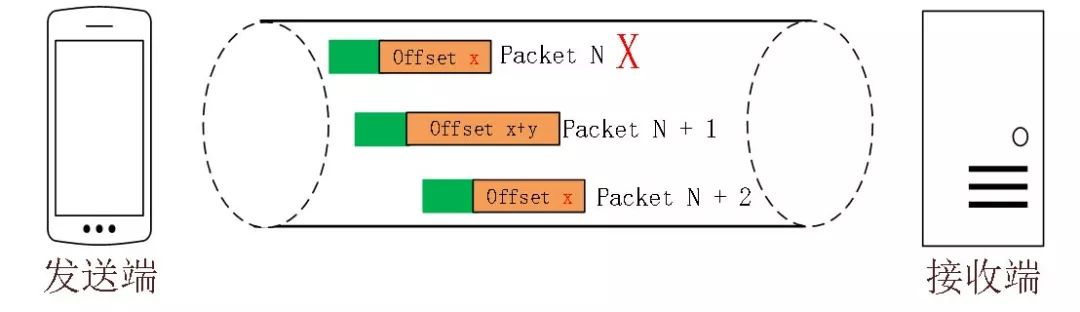
更多的 Ack 块
但是 Quic Ack Frame 可以同时提供 256 个 Ack Block,在丢包率比较高的网络下,更多的 Sack Block 可以提升网络的恢复速度,减少重传量。
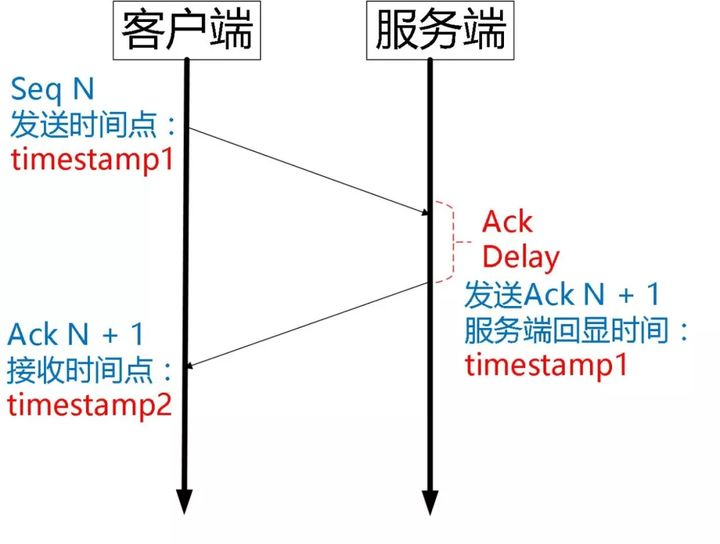
Ack Delay 时间
Tcp 的 Timestamp 选项存在一个问题,它只是回显了发送方的时间戳,但是没有计算接收端接收到 segment 到发送 Ack 该 segment 的时间。这个时间可以简称为 Ack Delay。
基于 stream 和 connecton 级别的流量控制
QUIC 的流量控制 [22] 类似 HTTP2,即在 Connection 和 Stream 级别提供了两种流量控制。为什么需要两类流量控制呢?主要是因为 QUIC 支持多路复用。
- Stream 可以认为就是一条 HTTP 请求
- Connection 可以类比一条 TCP 连接。多路复用意味着在一条 Connetion 上会同时存在多条 Stream。既需要对单个 Stream 进行控制,又需要针对所有 Stream 进行总体控制
没有队头阻塞的多路复用
什么是队头阻塞问题:后面的数据需要等待前面的数据完成传输后,才能进行读取。
HTTP/2 虽然通过 Stream 隔离 和 “数据帧”解决了应用层级的队头阻塞,但仍然受限于 TCP 层级的队头阻塞。
不仅如此,由于 HTTP2 强制使用 TLS,还存在一个 TLS 协议层面的队头阻塞: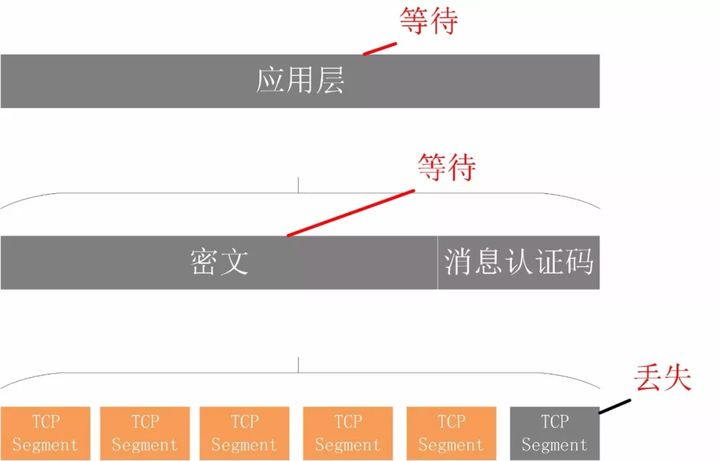
Record 是 TLS 协议处理的最小单位,最大不能超过 16K,一些服务器比如 Nginx 默认的大小就是 16K。由于一个 record 必须经过数据一致性校验才能进行加解密,所以一个 16K 的 record,就算丢了一个字节,也会导致已经接收到的 15.99K 数据无法处理,因为它不完整。
那 QUIC 多路复用为什么能避免上述问题呢?
- QUIC 最基本的传输单元是 Packet,不会超过 MTU 的大小,整个加密和认证过程都是基于 Packet 的,不会跨越多个 Packet。这样就能避免 TLS 协议存在的队头阻塞。
- Stream 之间相互独立,比如 Stream2 丢了一个 Pakcet,不会影响 Stream3 和 Stream4。不存在 TCP 队头阻塞。
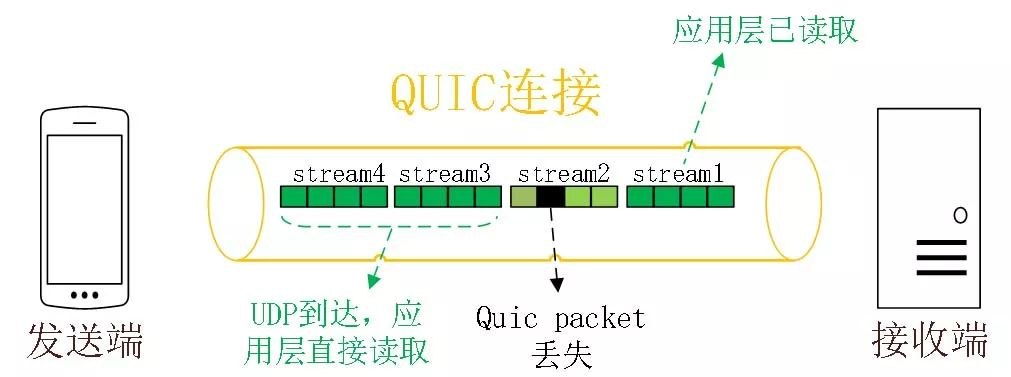
当然,并不是所有的 QUIC 数据都不会受到队头阻塞的影响,比如 QUIC 当前也是使用 Hpack 压缩算法 [10],由于算法的限制,丢失一个头部数据时,可能遇到队头阻塞。
总体来说,QUIC 在传输大量数据时,比如视频,受到队头阻塞的影响很小
连接迁移(IM 必需)
针对 TCP 的连接变化,MPTCP[5] 其实已经有了解决方案,但是由于 MPTCP 需要操作系统及网络协议栈支持,部署阻力非常大,目前并不适用。
那 QUIC 是如何做到连接迁移呢?很简单,任何一条 QUIC 连接不再以 IP 及端口四元组标识,而是以一个 64 位的随机数作为 ID 来标识,这样就算 IP 或者端口发生变化时,只要 ID 不变,这条连接依然维持着,上层业务逻辑感知不到变化,不会中断,也就不需要重连。
由于这个 ID 是客户端随机产生的,并且长度有 64 位,所以冲突概率非常低。

若有收获,就点个赞吧
0 人点赞
