SQL 语句执行流程
简图: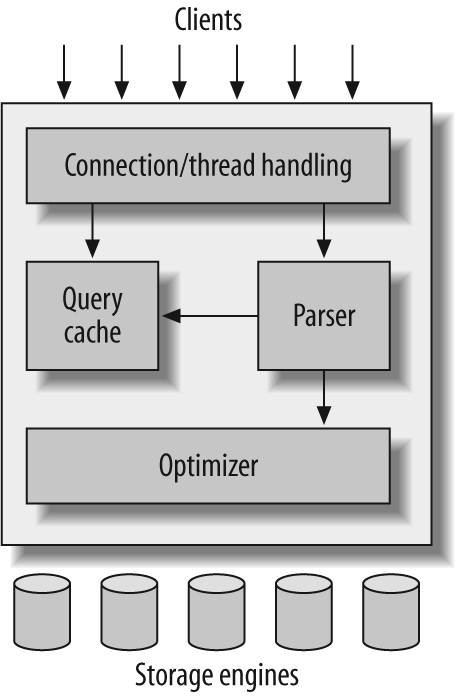
完整流程:
通信协议:
- 基于 TCP 的半双工协议 ,同一时刻要么 Client 在向 Server 发送消息,或反之。
- 客户端取数据,不是 PULL 模型,而是 PUSH 模型,像是“从消防水管喝水”
查询状态:可以通过 show full processlist 查看
- Sleep:线程正在等待客户端发送新的请求
- Query:线程正在执行查询或者正在将结果发送给客户端
- Sorting Result:线程正在对结果集进行排序
- Sending Data:这表示多种情况:现场可能在多个状态之间传送数据、或正在生成结果集、或在向客户端返回数据
查询缓存:对查询语句进行 Hash 来定位缓存数据
解析器:Mysql 语法特性的解析
预处理器:检测数据表和数据列是否存在,检查权限是否合法
查询优化器:
可以通过 show status like 'Last_query_cost'; 命令查看当前查询的成本,单位是数据页
+-----------------+----------+| Variable_name | Value |+-----------------+----------+| Last_query_cost | 8.803390 |+-----------------+----------+
不一定总能找出最优方案,有如下原因:
- 执行引擎没有给出正确的统计信息
- 没有考虑到并发执行问题
- 存储过程和用户自定义函数的成本没有考虑进去
对于用户来说:慎用 Hint 语法,这会给查询优化器后续的优化和维护带来困难。
调优思路
参考 20丨当我们思考数据库调优的时候,都有哪些维度可以选择?
第一步:定义目标
- 来源用户反馈,从表象探寻数据库底层的问题
- 日志监控
- 硬件层面:CPU、内存、IO
- 数据库内部:活跃会话、事务、锁 等指标的监控
- 响应时间:执行时间 + 等待时间
- 扫描行数和返回行数的比值
常用的查看命令:查看Mysql正在执行的事务、锁、等待
第二步:选择优化维度
- 选择适合的 DBMS
- 比如业务数据用 Mysql,在线报表分析使用 Hive + Presto 等。
- 优化表设计
- 简单表需要遵循三范式
- 如果分析查询应用比较多,尤其是需要进行多表联查的时候,可是采用反范式来利用空间换取时间。
- 字段类型尽量紧凑,提升 IO 效率
- 优化逻辑查询:改变 SQL 的语句内容让 SQL 执行效率更高
- 避免
SELECT *语句 - EXISTS 子查询和 IN 子查询:使用小表驱动大表,更好的方式是转换成 JOIN 的方式
- WHERE 子句中会尽量避免对字段进行函数运算
SUBSTRING(comment_text, 1,3)='abc'=comment_text LIKE 'abc%'
- 切分查询
- 分而治之:功能一样,每次只操作一部分数据。可用于删除场景,防止一下子锁定过多数据,同时降低复制延迟
- 分解关联查询:在业务层进行数据组装
- 提升查询缓存命中率,减少锁竞争
- 关联查询
- 确认任何的 GROUP BY 和 ORDER BY 中的表达式只涉及一个表中的列,这样 Mysql 才有可能使用索引来优化这个过程
- 优化 GROUP BY
- 通过对唯一键进行 GROUP BY 操作,来替代对唯一键关联的多个字段进行 GROUP BY 操作
- Limit 优化
- 延迟关联:先通过覆盖索引查出需要偏移的 ID 列表,再与需要取出的数据做 INNER JOIN
- 业务层面使用确定的取数范围:例如 where id > 20 limit 10
- 避免
- 优化物理查询:构建高效索引
- 高频查询可以考虑实现覆盖索引
- 如果数据重复度超过 10%,就不需要创建索引
- 索引不是越多越好,过多的索引会降低写入性能、占用过多存储空间、降低索引优化器评估效率
- 表连接:
- 嵌套循环连接
- 合并连接
- 没有数据去重需求的话,可以通过 UNION ALL 代替 UNION
- 使用 Redis 或 Memcached 作为缓存
- 常见的 3 种缓存模型
- 旁路缓存模式(可以理解为读更新)
- 需要先删除 DB,再删除 Cache
- 读写穿透(需要 Cache 提供更新 DB 的能力)
- 异步缓存写入
- 基础设施:消息队列、各种 DB 的数据持久化机制
- 业务中多用于:数据经常变化又对数据一致性要求没那么高的场景,比如浏览量、点赞量
- 旁路缓存模式(可以理解为读更新)
- 接入组件
- 简单的 CURD 可以使用 Jedis
- 需要拓展的数据结构支撑,考虑 Redison
- 常见的 3 种缓存模型
- 库级优化:但也会增加相应的维护和使用成本
- 分区表:可以应对单表 10 亿量级的数据请求
- 属于水平切分,mysql 5.7 最多拥有 8192 分区
- 唯一索引和主键必须包含所有分区键
- 针对锁表的问题,可以通过指定分区的方式来减小影响范围
- 分区字段包含 NULL 值都会落到 p0 分区,尽量避免 NULL 值
- 读写分离,主从架构
- 表结构的垂直分割,减少索引表大小
- 分库分表
- 会带来事务问题
- 分区表:可以应对单表 10 亿量级的数据请求
补充:
EXISTS 和 IN 的区别:https://cloud.tencent.com/developer/article/1144244
调优路径: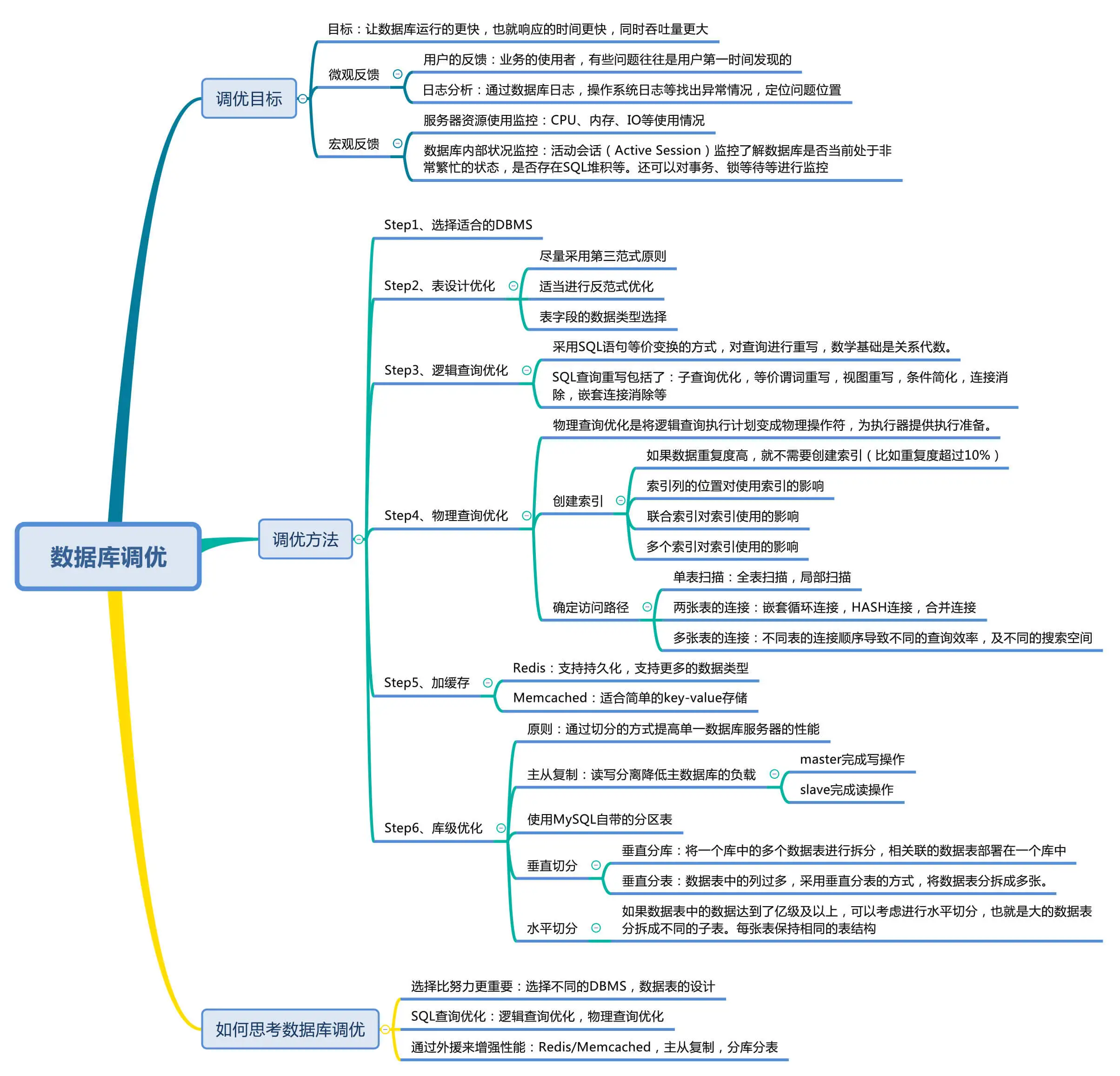
常用调优命令
show warnings
案例列表:
- 字符集问题导致的索引失效
Mysql 8.0 执行 explain ,Mysql 5.7 执行 explain extended 之后使用 show warnings 命令,可以看到 Mysql 优化的语句,错误码为 1003
mysql> explain SELECT * FROM user_info WHERE id in (10,11) and age = 20;
mysql> show warnings \G;
*************************** 1. row ***************************
Level: Note
Code: 1003
Message: /* select#1 */ select `learn-java`.`user_info`.`id` AS `id`,`learn-java`.`user_info`.`name` AS `name`,`learn-java`.`user_info`.`age` AS `age` from `learn-java`.`user_info` where ((`learn-java`.`user_info`.`age` = 20) and (`learn-java`.`user_info`.`id` in (10,11)))
1 row in set (0.01 sec)
explain
参考资料:
- MySQL 性能优化神器 Explain 使用分析
- 最官方的 mysql explain type 字段解读
| 字段 | 含义 |
| —- | —- |
| id | SELECT 查询的标识符. 每个 SELECT 都会自动分配一个唯一的标识符. |
| select_type | SELECT 查询的类型,具备如下类型
- SIMPLE, 表示此查询不包含 UNION 查询或子查询
- PRIMARY, 表示此查询是最外层的查询
- UNION, 表示此查询是 UNION 的第二或随后的查询
- DEPENDENT UNION, UNION 中的第二个或后面的查询语句, 取决于外面的查询
- UNION RESULT, UNION 的结果
- SUBQUERY, 子查询中的第一个 SELECT
- DEPENDENT SUBQUERY: 子查询中的第一个 SELECT, 取决于外面的查询. 即子查询依赖于外层查询的结果.
| | table | 表示查询涉及的表或衍生表 | | partitions | 匹配的分区 | | type | 扫描类型:
- system:表中只有一条数据. 这个类型是特殊的 const 类型.
- const:针对主键或唯一索引的等值查询扫描, 最多只返回一行数据. const 查询速度非常快, 因为它仅仅读取一次即可.
- eq_ref:此类型通常出现在多表的 join 查询, 表示对于前表的每一个结果, 都只能匹配到后表的一行结果. 并且查询的比较操作通常是 =, 查询效率较高
- ref:此类型通常出现在多表的 join 查询, 针对于非唯一或非主键索引, 或者是使用了 最左前缀 规则索引的查询.
- range:表示使用索引范围查询, 通过索引字段范围获取表中部分数据记录. 这个类型通常出现在 =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, IN() 操作中. 当 type 是 range 时, 那么 EXPLAIN 输出的 ref 字段为 NULL, 并且 key_len 字段是此次查询中使用到的索引的最长的那个
- index:表示全索引扫描(full index scan), 和 ALL 类型类似, 只不过 ALL 类型是全表扫描, 而 index 类型则仅仅扫描所有的索引, 而不扫描数据. index 类型通常出现在: 所要查询的数据直接在索引树中就可以获取到, 而不需要扫描数据. 当 是这种情况时, Extra 字段 会显示 Using index
- ALL:表示全表扫描
| | possible_keys | 此次查询中可能选用的索引 | | key | 此次查询中确切使用到的索引 | | key_len | 索引长度,单位是 byte | | ref | 哪个字段或常数与 key 一起被使用:
- const 常指用户指定的条件固定值
| | rows | 显示此查询一共扫描了多少行. 这个是一个估计值. | | filtered | 表示此查询条件所过滤的数据的百分比,见:What is the meaning of filtered in MySQL explain?
如果是 100%,所以你的索引已经完全覆盖了查询条件;如果这个值很小,那么可以考虑优化索引配置了。 | | extra | 额外的信息:
- Using filesort:当 Extra 中有 Using filesort 时, 表示 MySQL 需额外的排序操作, 不能通过索引顺序达到排序效果. 一般有 Using filesort, 都建议优化去掉, 因为这样的查询 CPU 资源消耗大
- Using index:“覆盖索引扫描”, 表示查询在索引树中就可查找所需数据, 不用扫描表数据文件, 往往说明性能不错
- Using where:A WHERE clause is used to restrict which rows to match against the next table or send to the client。简单来说:对结果集进行过滤后再继续传递
- Using temporary:查询有使用临时表, 一般出现于排序, 分组和多表 join 的情况, 查询效率不高, 建议优化。例如 UNION ALL 不对数据去重,不回用到临时表,但 UNION 会对数据去重,会用到临时表。
|
InnoDB MVCC 锁
原文见:InnoDB对MVCC的实现
读类型
MVCC 实现了一致性非锁定读:
- RC:同一个事务内,每次 SELECT 都会重新生成一个 Read View
RR:在事务开启后,第一次 SELECT 生成一个 Read View
锁定读:
select … lock in share mode
- select … for update
- insert、update、delete 操作
防止幻读是通过:MVCC + Next-Key Lock 实现的,Next-Key Lock 是 Index Record Lock 和 Gap Lock 整合体,当记录存在的时候使用 Index Record Lock,不存在则使用 Gap Lock。
如何复现幻读:在 RR 级别的事务中,明明查询不到一个数据,Insert 的时候却又爆主键冲突错误。
关键三元素
隐藏字段
- DB_TRX_ID(6字节):表示最后一次插入或更新该行的事务 id。此外,delete 操作在内部被视为更新,只不过会在记录头 Record header 中的
deleted_flag字段将其标记为已删除 - DB_ROLL_PTR(7字节):回滚指针,指向该行的
undo log。如果该行未被更新,则为空 - DB_ROW_ID(6字节):如果没有设置主键且该表没有唯一非空索引时,InnoDB 会使用该 id 来生成聚簇索引
ReadView
class ReadView {
/* ... */
private:
trx_id_t m_low_limit_id; /* 大于等于这个 ID 的事务均不可见 */
trx_id_t m_up_limit_id; /* 小于这个 ID 的事务均可见 */
trx_id_t m_creator_trx_id; /* 创建该 Read View 的事务ID */
trx_id_t m_low_limit_no; /* 事务 Number, 小于该 Number 的 Undo Logs 均可以被 Purge */
ids_t m_ids; /* 创建 Read View 时的活跃事务列表 */
m_closed; /* 标记 Read View 是否 close */
}
Read View 主要是用来做可见性判断,里面保存了 “当前对本事务不可见的其他活跃事务”
主要有以下字段:
- m_low_limit_id:目前出现过的最大的事务 ID+1,即下一个将被分配的事务 ID。大于等于这个 ID 的数据版本均不可见
- m_up_limit_id:活跃事务列表 m_ids 中最小的事务 ID,如果 m_ids 为空,则 m_up_limit_id 为 m_low_limit_id。小于这个 ID 的数据版本均可见
- m_ids:Read View 创建时其他未提交的活跃事务 ID 列表。创建 Read View时,将当前未提交事务 ID 记录下来,后续即使它们修改了记录行的值,对于当前事务也是不可见的。m_ids 不包括当前事务自己和已提交的事务(正在内存中)
- m_creator_trx_id:创建该 Read View 的事务 ID

Undo Log
Undo Log 的清理由专门的 purge 线程进行清理。
Undo log 主要有两个作用:
- 当事务回滚时用于将数据恢复到修改前的样子
- 另一个作用是 MVCC ,当读取记录时,若该记录被其他事务占用或当前版本对该事务不可见,则可以通过 undo log 读取之前的版本数据,以此实现非锁定读
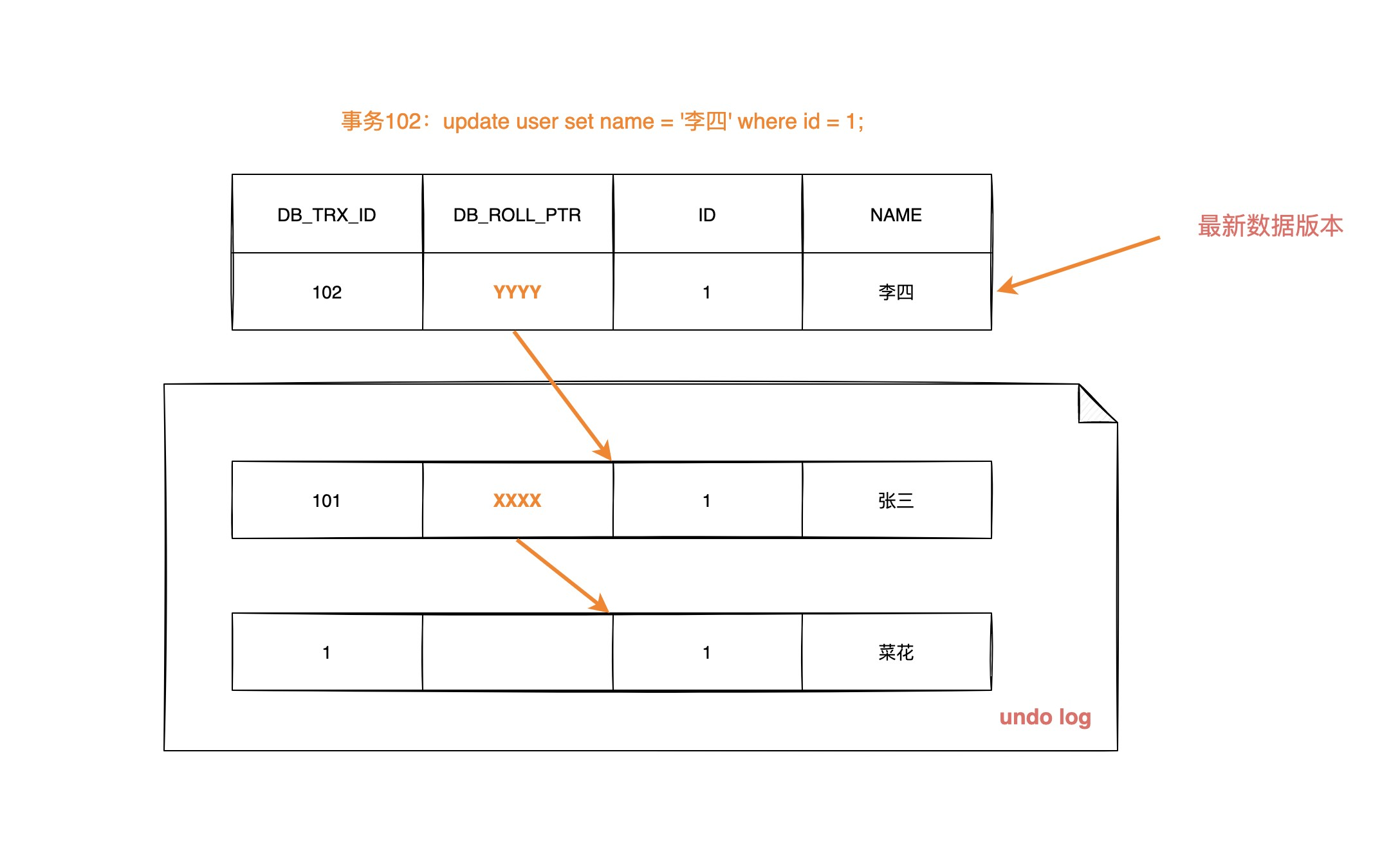
数据可见性算法

索引类型
Hash 索引
InnoDB 引擎内部有一个特殊功能叫做 “自适应哈希索引”,但他不受用户控制。
用户可以通过 hash 函数来实现伪 Hash 索引。
B+ 树
参考资料:为什么 MySQL 使用 B+ 树 参考资料:24丨索引的原理:我们为什么用B+树来做索引? 参考资料:27丨从数据页的角度理解B+树查询
无论是表中的数据(主键索引)还是辅助索引最终都会使用 B+ 树来存储数据,其中前者在表中会以
核心需求:MySQL 作为 OLTP(Online Transaction Processing) 的数据库不仅需要具备事务的处理能力,而且要保证数据的持久化并且能够有一定的实时数据查询能力
与 Hash 比较:
与 B 树和 B+ 树相比,哈希作为底层的数据结构的表能够以 O(1) 的速度处理单个数据行的增删改查,但是面对范围查询或者排序时就会导致全表扫描的结果,而 B 树和 B+ 树虽然在单数据行的增删查改上需要 O(log n) 的时间,但是它会将索引列相近的数据按顺序存储,所以能够避免全表扫描
与 B 比较:
计算机在读写文件时会以页为单位将数据加载到内存中。页的大小可能会根据操作系统的不同而发生变化,不过在大多数的操作系统中,页的大小都是 4KB,你可以通过如下的命令获取操作系统上的页大小:
$ getconf PAGE_SIZE
4096
对硬盘进行数据读取会产生随机 I/O,而随机 I/O 的性能在 ms 级别,而内存的读取速度在 ns 级别,由此我们也应该尽量减少随机 I/O 的次数,这样才能提高性能。
B 树与 B+ 树的最大区别就是,B 树可以在非叶结点中存储数据,但是 B+ 树的所有数据其实都存储在叶子节点中,当一个表底层的数据结构是 B 树时,假设我们需要访问所有『大于 4,并且小于 9 的数据』: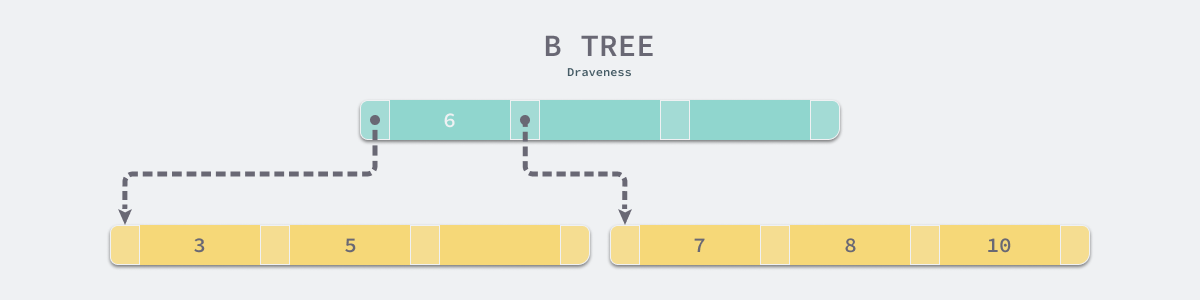
如果不考虑任何优化,在上面的简单 B 树中我们需要进行 4 次磁盘的随机 I/O 才能找到所有满足条件的数据行:
- 加载根节点所在的页,发现根节点的第一个元素是 6,大于 4;
- 通过根节点的指针加载左子节点所在的页,遍历页面中的数据,找到 5;
- 重新加载根节点所在的页,发现根节点不包含第二个元素;
- 通过根节点的指针加载右子节点所在的页,遍历页面中的数据,找到 7 和 8;
由于所有的节点都可能包含目标数据,我们总是要从根节点向下遍历子树查找满足条件的数据行,这个特点带来了大量的随机 I/O,也是 B 树最大的性能问题。
B+ 树中就不存在这个问题了,因为所有的数据行都存储在叶节点中,而这些叶节点可以 通过『指针』依次按顺序连接,当我们在如下所示的 B+ 树遍历数据时可以直接在多个子节点之间进行跳转,这样能够节省大量的磁盘 I/O 时间,也不需要在不同层级的节点之间对数据进行拼接和排序;通过一个 B+ 树最左侧的叶子节点,我们可以像链表一样遍历整个树中的全部数据,我们也可以引入双向链表保证倒序遍历时的性能。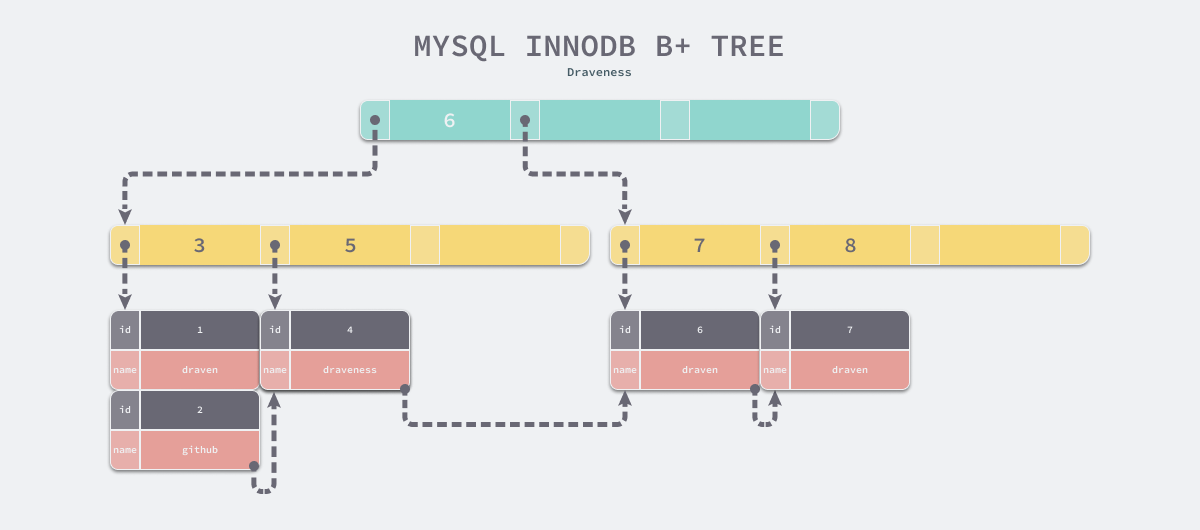
B+ 数是一个多叉平衡二叉树,高度一般控制在个位数,防止过多的层级带来过多的随机 I/O
具体结构
先看 B 树:如果一个磁盘块中包括了 x 个关键字,那么指针数就是 x+1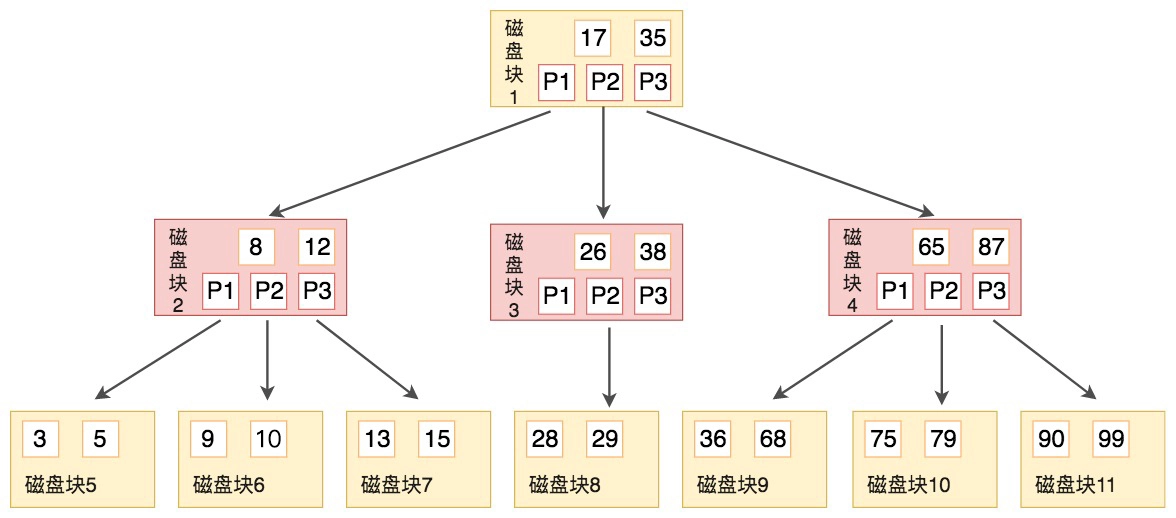
B+ 树基于 B 树做出了改进,主流的 DBMS 都支持 B+ 树的索引方式,比如 MySQL。B+ 树和 B 树的差异在于以下几点:
- 有 k 个孩子的节点就有 k 个关键字。也就是孩子数量 = 关键字数,而 B 树中,孩子数量 = 关键字数 +1
- 所有关键字都在叶子节点出现,叶子节点构成一个有序链表,而且叶子节点本身按照关键字的大小从小到大顺序链接。
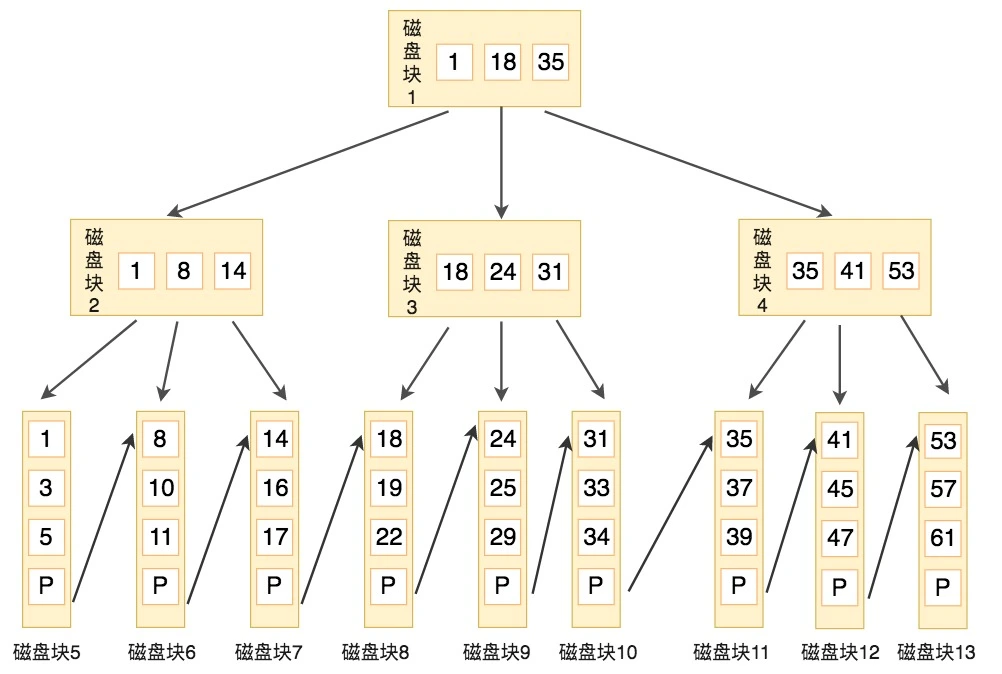
磁盘的 I/O 操作次数对索引的使用效率至关重要。虽然传统的二叉树数据结构查找数据的效率高,但很容易增加磁盘 I/O 操作的次数,影响索引使用的效率。因此在构造索引的时候,我们更倾向于采用“矮胖”的数据结构。
数据页
常见误区
COUNT 统计的列行数?
当执行 count(column) 的时候,统计的是该列中的非 NULL 行数。
如果我们想统计行数,需要使用 count(*),它会忽略所有的列而直接统计所有的行数。

若有收获,就点个赞吧
0 人点赞
