学习文档
Docker2022.docx
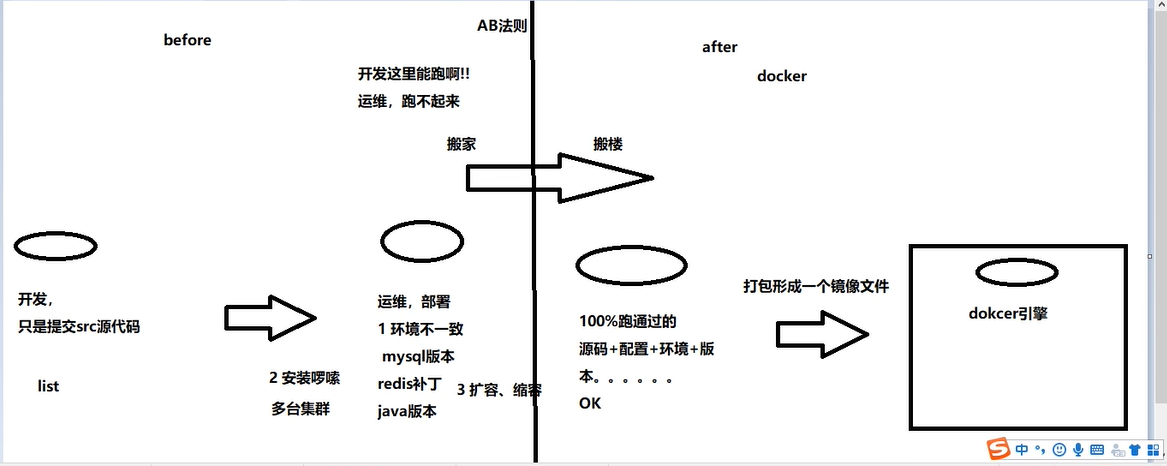
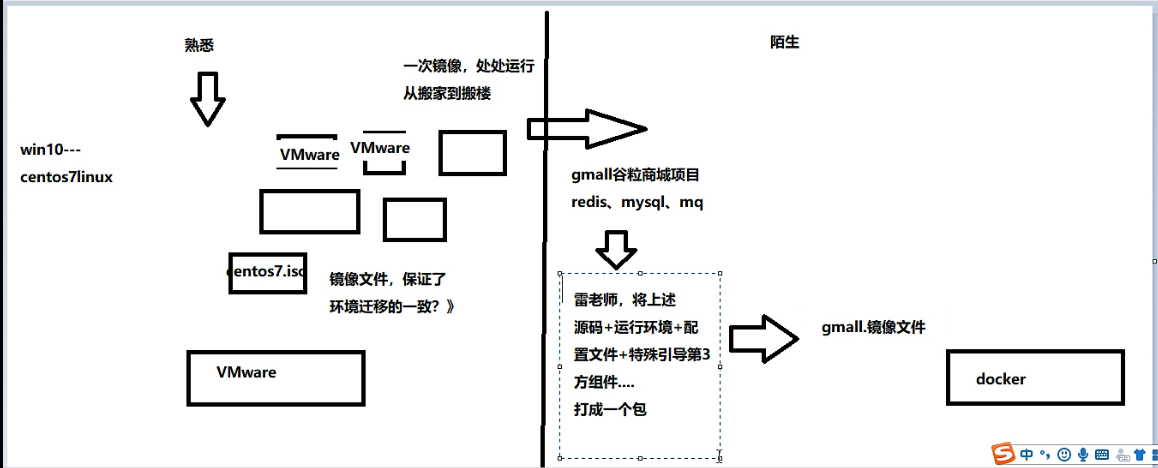
什么是docker?docker的用处~~~~

注意
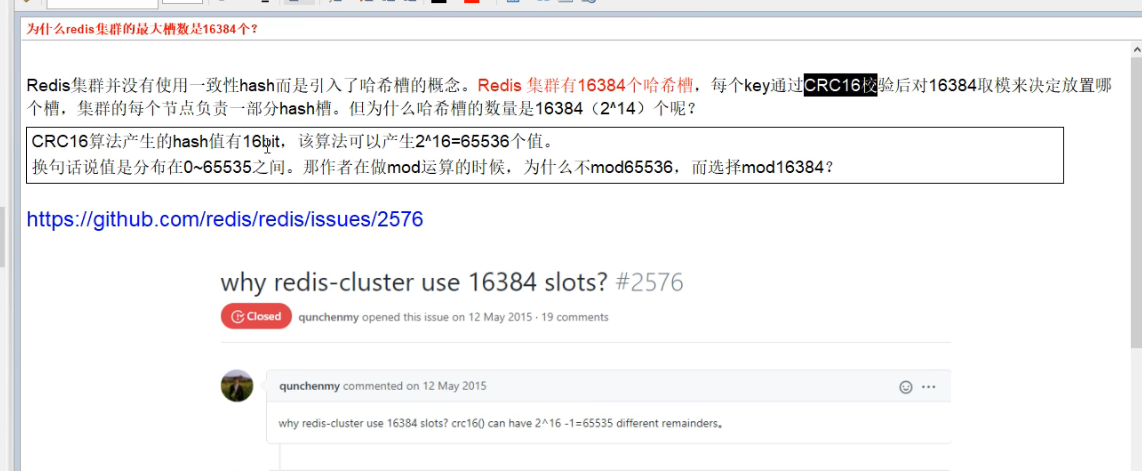
哈希槽算法和一致性哈希:https://blog.csdn.net/weichi7549/article/details/107657938这个解释很好
普通的哈希算法:缺点是由于分布式系统中的节点充满了不确定性,可能会缩容或者扩容或者节点宕机,如果在这些情况下,意味着哈希的映射将会发生变化,同时之前的那些映射的数据需要进行迁移,以便之后能够正确的访问。而这种方式的哈希在这种情况下产生的数据迁移量将会是非常巨大的。(数据可能全部都要重新洗牌,因为一个服务器宕机之后,哈希函数发生了变化(由之前的key%3变成了key%2),所以影响到了所有的key;也就导致几乎所有key的缓存都失效了,造成缓存雪崩)
哈希槽算法:某一个槽的master宕机之后,首先会由其slave节点顶替成为master,当这些槽的所有节点都宕机之后,槽会被分配给其他节点。
扩容时,重新分配槽位,是其他节点槽位每个分一点自己的槽位出去给新节点
缩容时,把删除节点之前的所拥有的槽位可以自己指定分配给其他节点,数量自己随意指定
数据都是放槽里的,跟着槽动
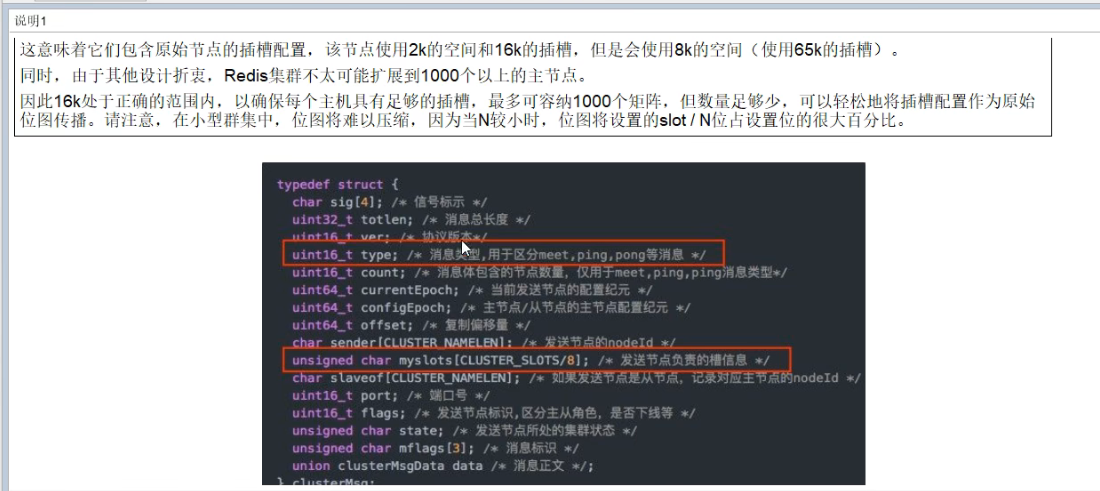
master节点的slave节点不分配槽,只拥有读权限。但是注意在代码中redis cluster执行读写操作的都是master节点,并不是你想 的读是从节点,写是主节点。第一次新建redis cluster时,16384个槽是被master节点均匀分布的。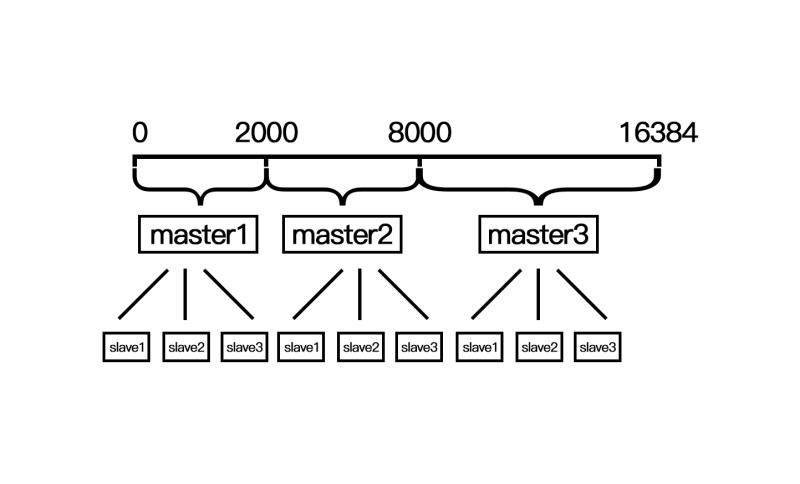
采用master节点有多个slave节点机制来保证数据的完整性的,master节点写入数据,slave节点同步数据。当master节点挂机后,slave节点会通过选举机制选举出一个节点变成master节点,实现高可用。但是这里有一点需要考虑,如果master节点存在热点缓存,某一个时刻某个key的访问急剧增高,这时该mater节点可能操劳过度而死,随后从节点选举为主节点后,同样宕机,依次类推,造成缓存雪崩。解决这个问题请看我的另一篇文章如何应对热点缓存问题
容器之间是独立的,如果都链接同一个网桥就是互通的
多个容器之间通信,使用自定义网络,这样可以ping通服务名
docker-compose等于一次性运行了多个docker run
dockerfile是对一个容器服务进行修改,比如在ubuntu中加VIM,docker建议的是一个容器只运行一个服务,也即是docker-compose范围涉及很多服务,dockerfile涉及一个服务
dockerfile:
docker-compose
不使用docker-compose也可以,比如,项目用到了MySQL和redis,我们就要首先把项目dockerfile成镜像,然后把这三个服务都运行起来。不过要运行三次docker run。可以如果涉及到的服务有100个呢,就要运行100次docker run。而且服务的先后启动顺序也要固定,当我先启动项目的时候,没有提前启动MySQL,那么项目连接不到数据库就会报错
容器之间在同一个网段,就可以ping通也就是可以互相访问
docker-compose 一键部署一键启停
3主3从 redis集群搭建
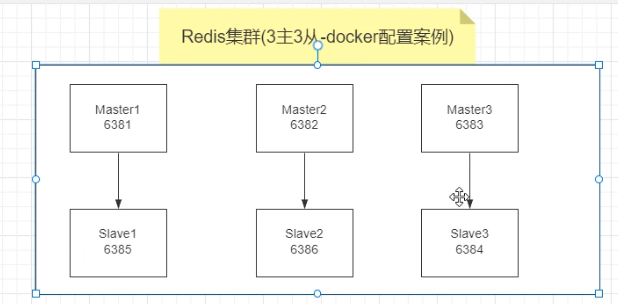
三主三从配置
1、关闭防火墙并且启动Docker后台服务systemctl start docker
2、新建6个docker容器redis实例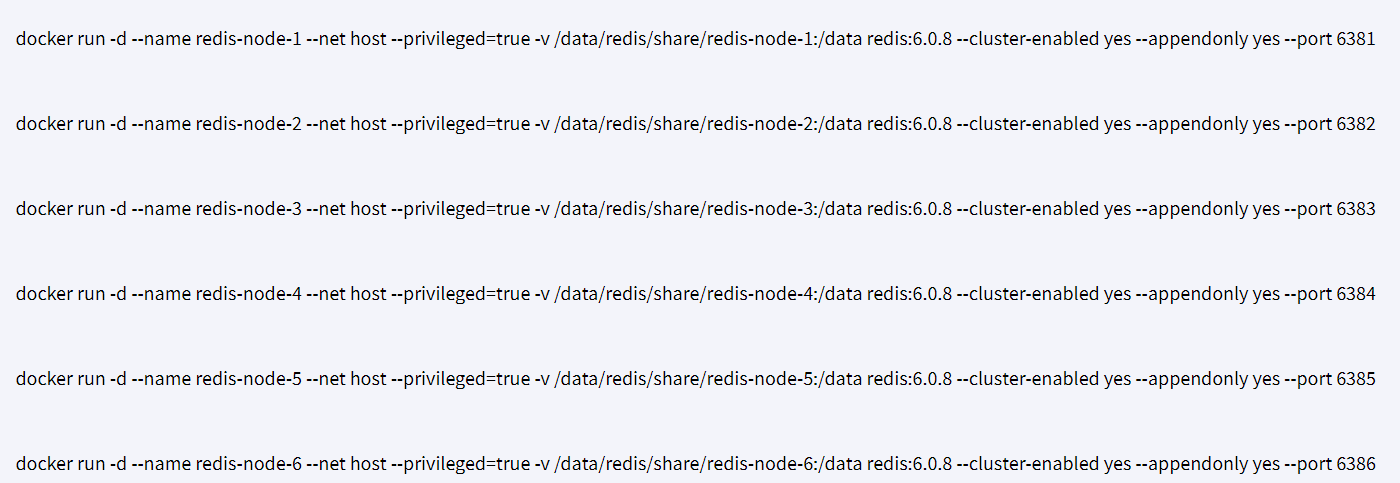
参数说明
3、进入容器redis-node-1并为6台机器构建集群关系
进入容器docker exec -it redis-node-1 /bin/bash
构建主从关系//注意,进入docker容器后才能执行以下命令,且注意自己的真实IP地址。redis-cli --cluster create 192.168.111.147:6381 192.168.111.147:6382 192.168.111.147:6383 192.168.111.147:6384 192.168.111.147:6385 192.168.111.147:6386 --cluster-replicas 1
—cluster-replicas 1 表示为每个master创建一个slave节点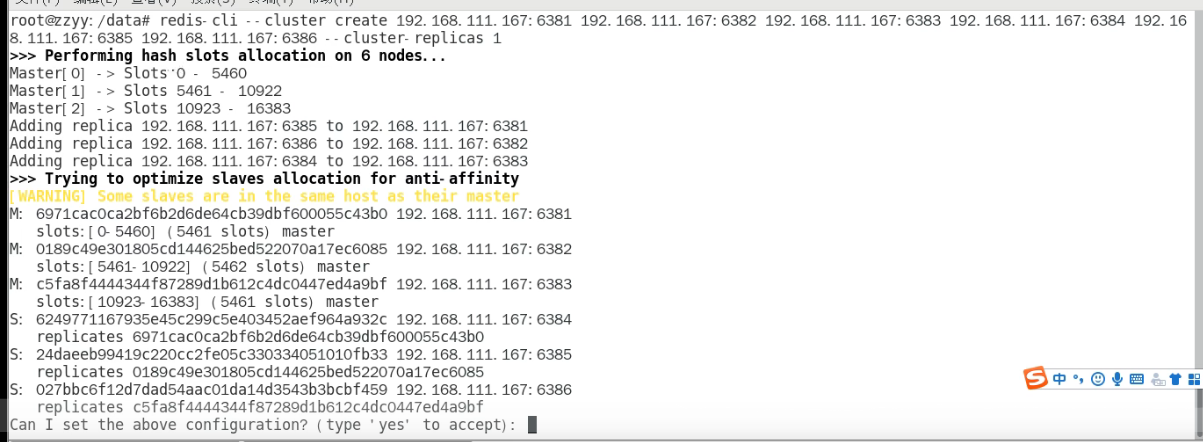
执行完上述代码以后,上图第一行下面显示,为每一个Master分配哈希槽。(0-5460。。。。)也就是下图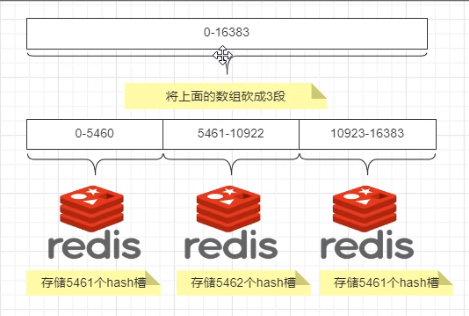
第二行黑体下面,显示了Master和Slave分别是谁。
至此,都分配ok了,链接进入6381作为切入点,查看集群状态,查看节点状态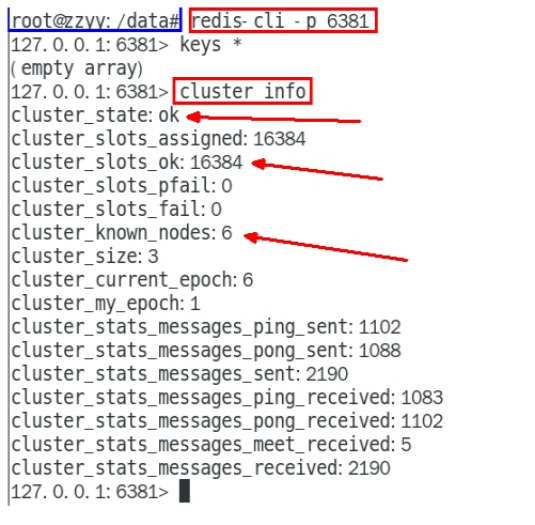
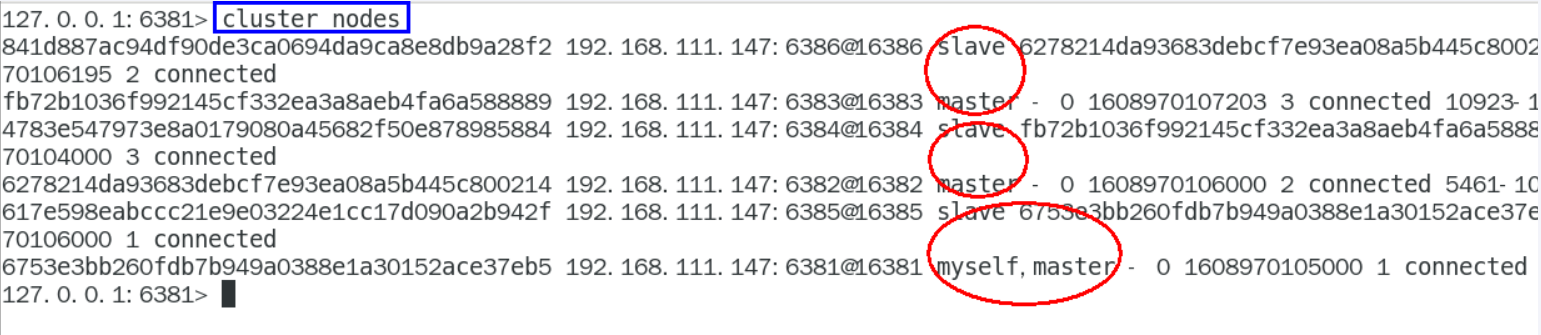
谁是master谁是slave系统自主分配,每次分配结果可能不一样。
主从容错切换迁移
数据读写存储

这种情况,是进入单机版的redis,有些key值经过哈希以后存不进6381节点(0—5460)。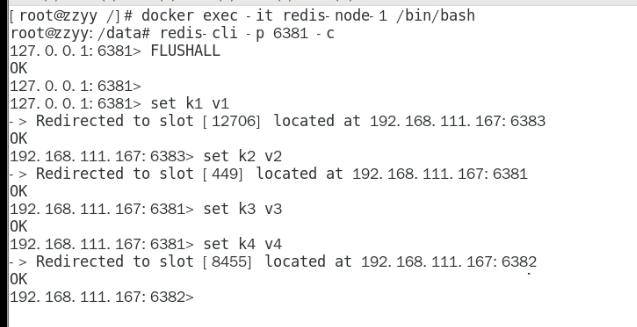
这种情况,则是存到集群里,不会出现error
查看集群存储数据信息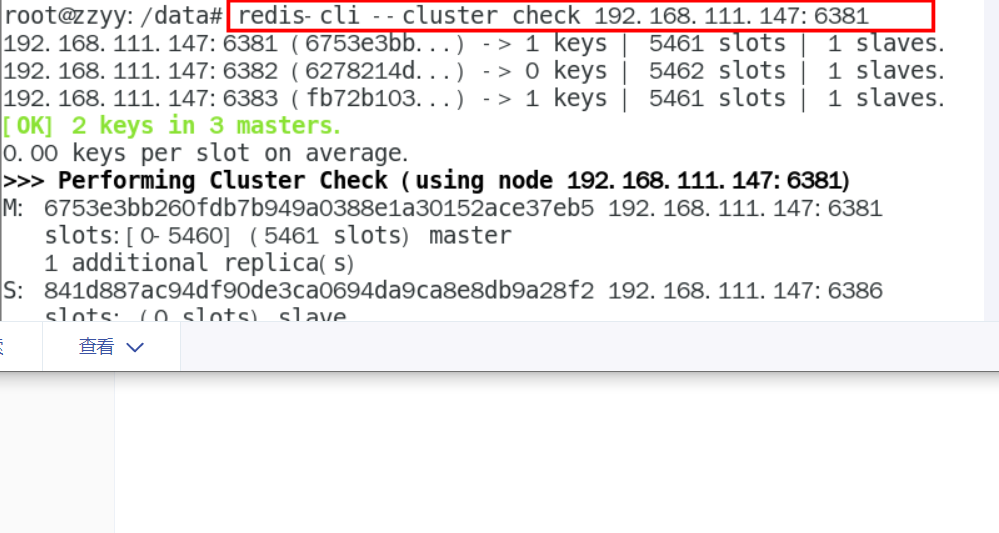
容错切换迁移
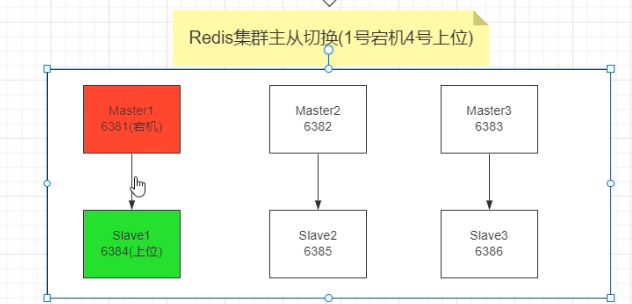

停止主机1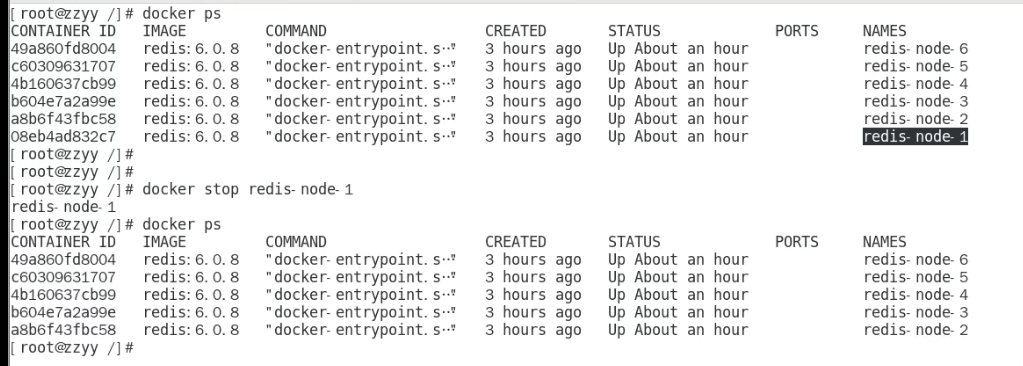

上图6381fail了,6384变成了master。
如果6381活回来了,6384继续是master,6381是slave。
如果想还原,参考下图。
主从扩容
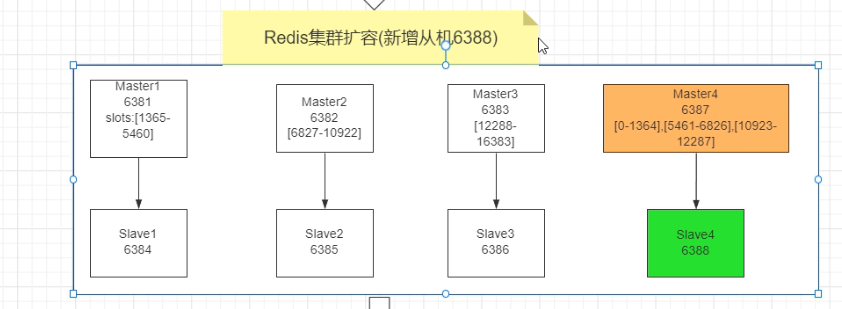
新增机器

| 将新增的6387作为master节点加入集群 redis-cli —cluster add-node 自己实际IP地址:6387 自己实际IP地址:6381 6387 就是将要作为master新增节点 6381 就是原来集群节点里面的领路人,相当于6387拜拜6381的码头从而找到组织加入集群 |
|---|
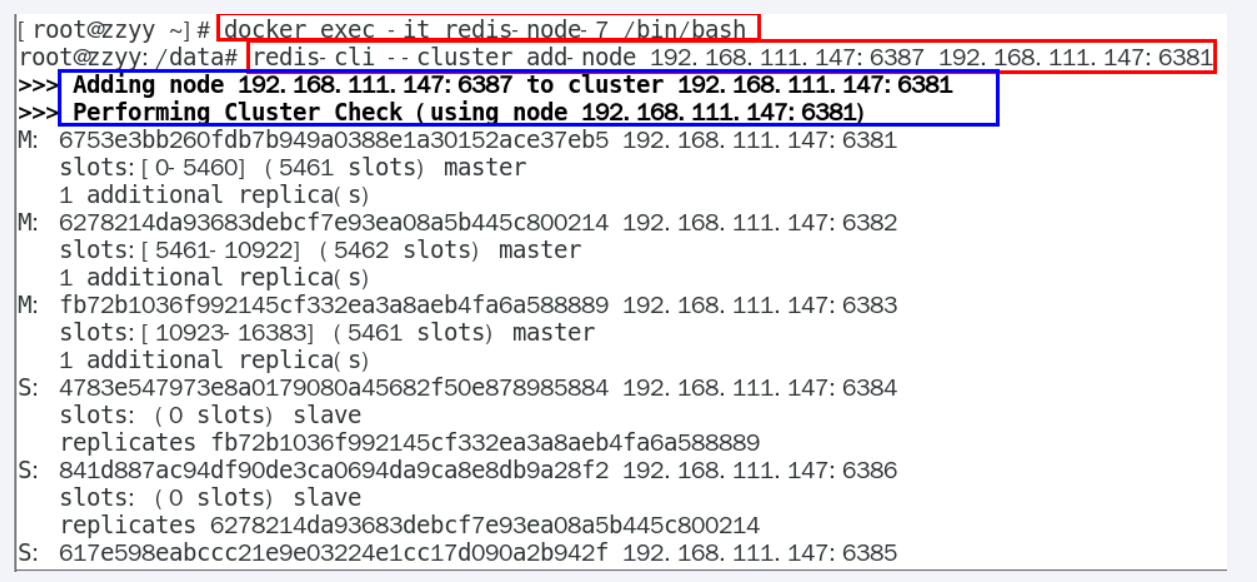
上面做完以后,查看集群信息
第二个没有分配 槽位,所以需要我们分配槽位。
槽位分配
| 重新分派槽号 命令:redis-cli —cluster reshard IP地址:端口号 redis-cli —cluster reshard 192.168.111.147:6381 |
|---|
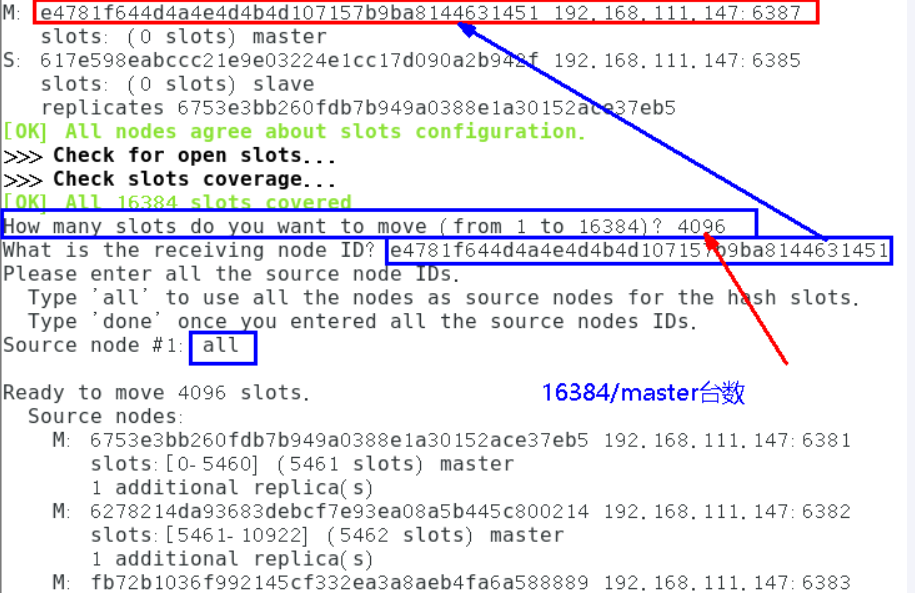
现在查看集群情况
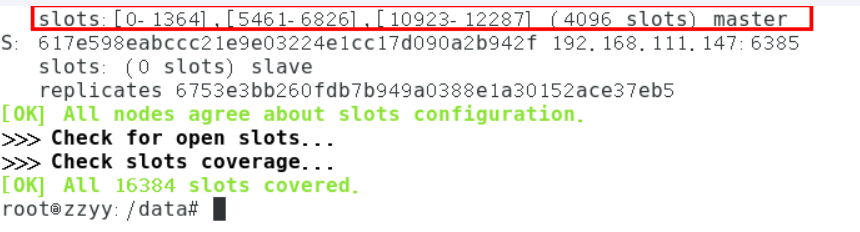
为什么6387是3个新的区间,以前的还是连续?
重新分配成本太高,所以前3家各自匀出来一部分,从6381/6382/6383三个旧节点分别匀出1364个坑位给新节点6387
这时候6387还没有slaver需要把6388挂到6387下做slave
命令:redis-cli —cluster add-node ip:新slave端口 ip:新master端口 —cluster-slave —cluster-master-id 新主机节点ID
redis-cli —cluster add-node 192.168.111.147:6388 192.168.111.147:6387 —cluster-slave —cluster-master-id e4781f644d4a4e4d4b4d107157b9ba8144631451———-这个是6387的编号,按照自己实际情况
主从缩容
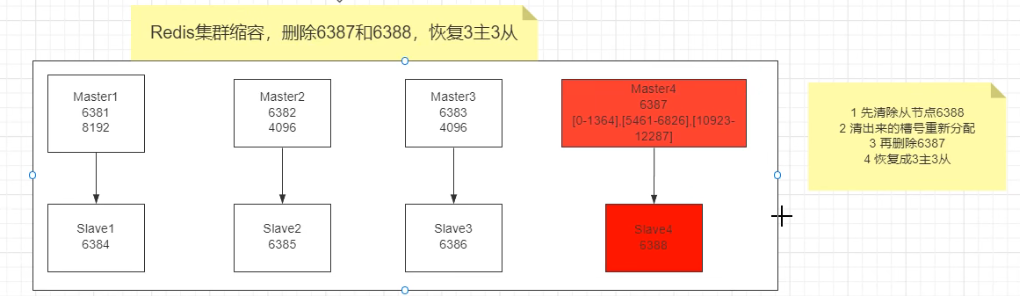
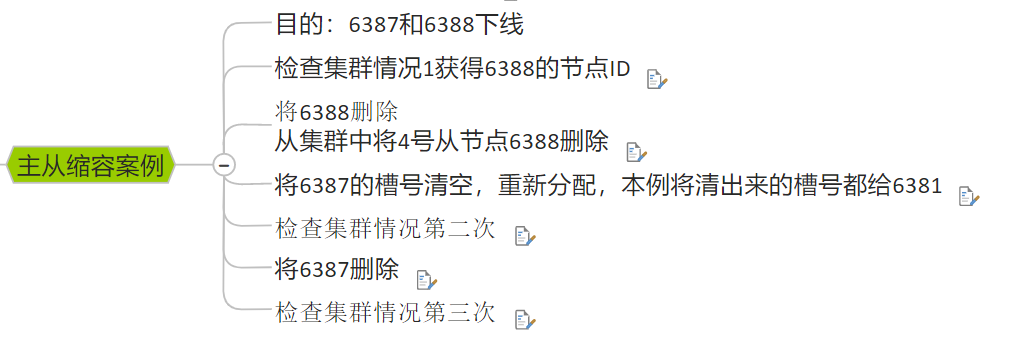
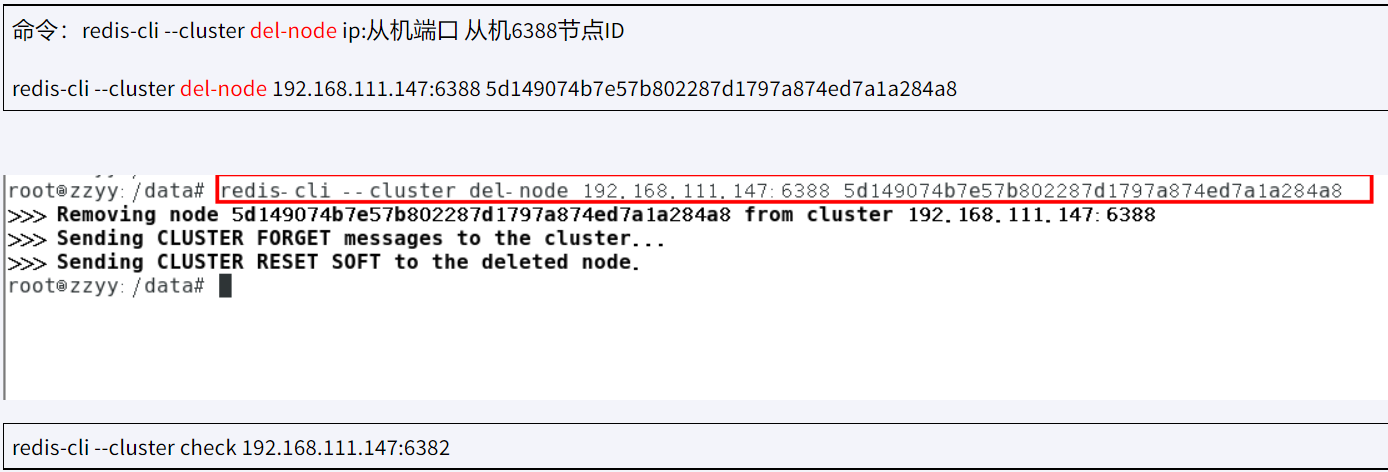
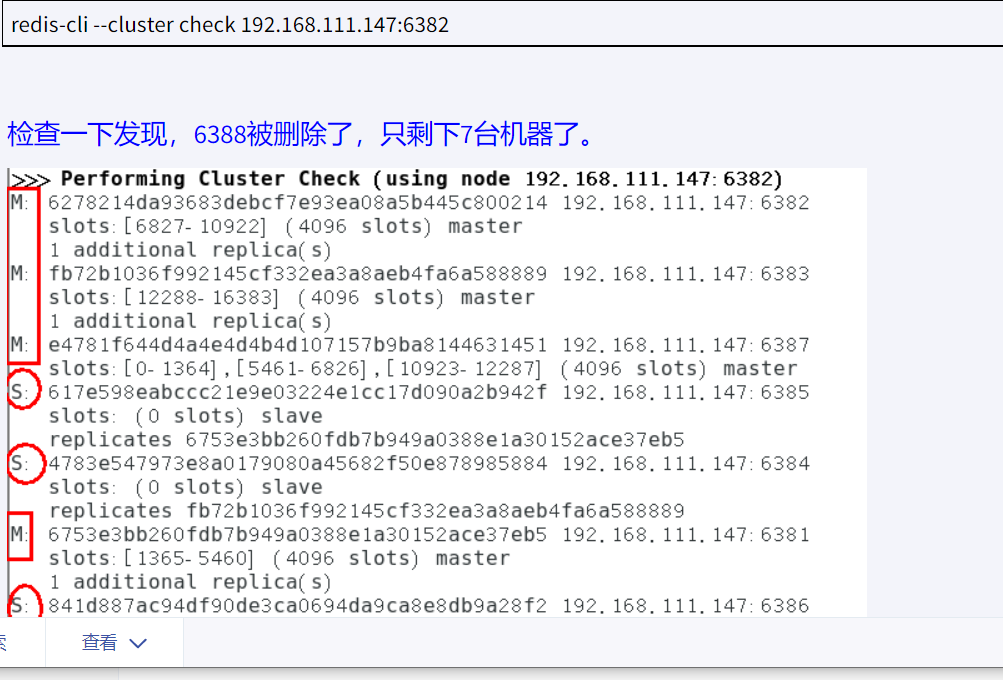
删除节点
重新分配槽位
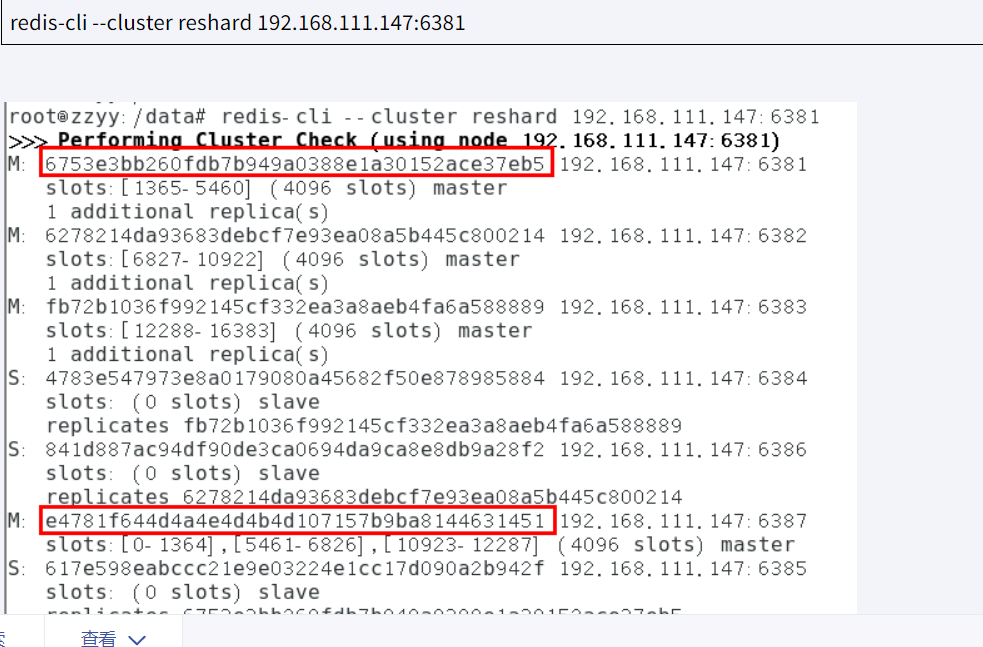
槽都分配给6381节点(你可以每次分100,1000给不同的节点,这里是一次性全给6381)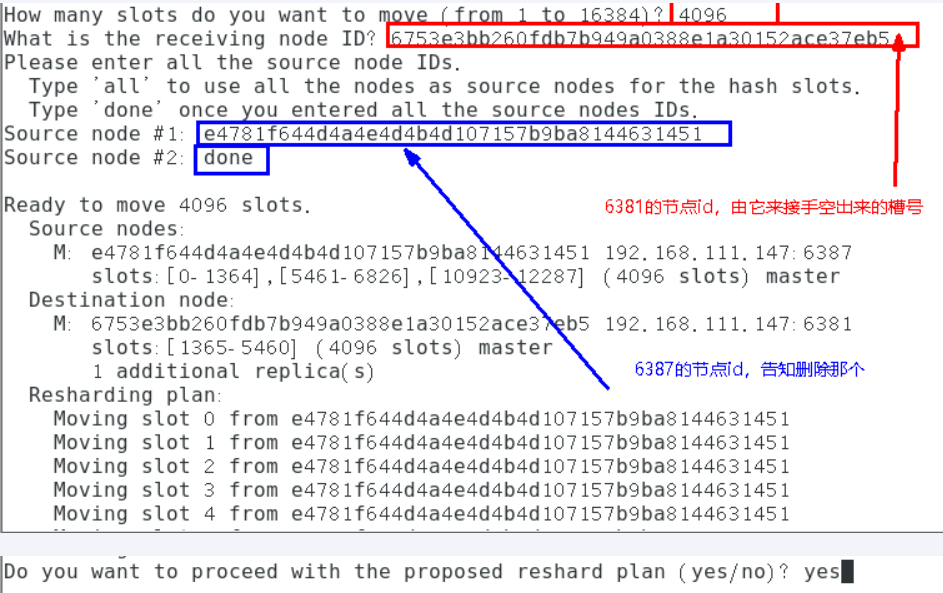
再检查集群情况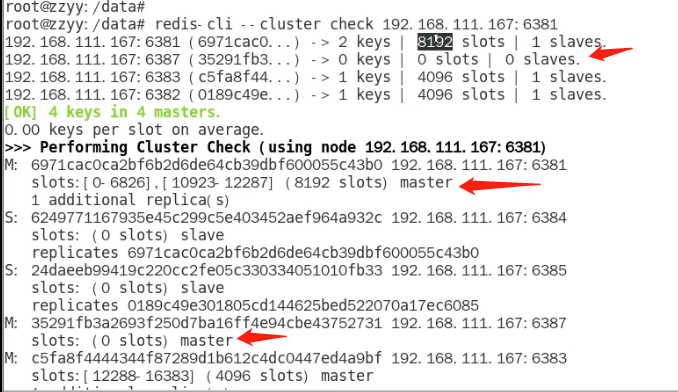
然后删除6387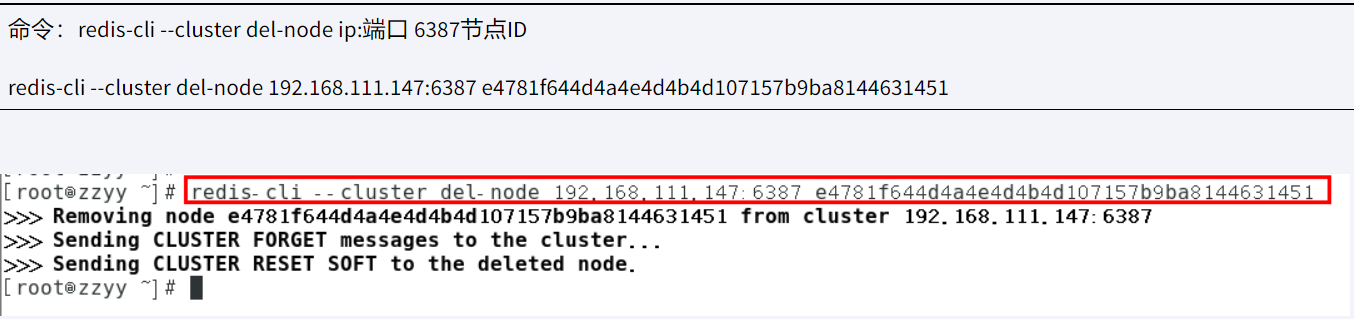

若有收获,就点个赞吧
0 人点赞
