定义
迭代器模式(Iterator Design Pattern),也叫作游标模式(Cursor Design Pattern)。提供一个对象来顺序访问聚合对象中的一系列数据,而不暴露聚合对象的内部表示。
结构
主要角色:
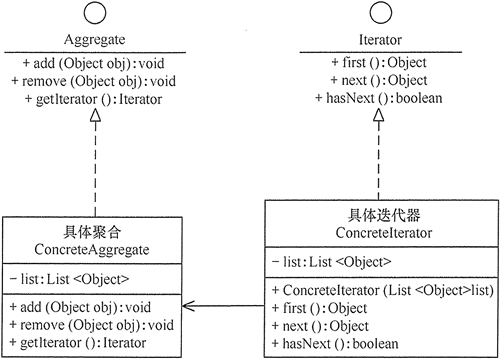
- 抽象聚合(Aggregate)角色:定义存储、添加、删除聚合对象以及创建迭代器对象的接口。
- 具体聚合(ConcreteAggregate)角色:实现抽象聚合类,返回一个具体迭代器的实例。
- 抽象迭代器(Iterator)角色:定义访问和遍历聚合元素的接口,通常包含 hasNext()、first()、next() 等方法。
- 具体迭代器(Concretelterator)角色:实现抽象迭代器接口中所定义的方法,完成对聚合对象的遍历,记录遍历的当前位置。
结构图:
**
应用
简单例子
public class ArrayIterator<E> implements Iterator<E> {private int cursor;private ArrayList<E> arrayList;public ArrayIterator(ArrayList<E> arrayList) {this.cursor = 0;this.arrayList = arrayList;}@Overridepublic boolean hasNext() {return cursor != arrayList.size(); //注意这里,cursor在指向最后一个元素的时候,hasNext()仍旧返回true。}@Overridepublic void next() {cursor++;}@Overridepublic E currentItem() {if (cursor >= arrayList.size()) {throw new NoSuchElementException();}return arrayList.get(cursor);}}public class Demo {public static void main(String[] args) {ArrayList<String> names = new ArrayList<>();names.add("xzg");names.add("wang");names.add("zheng");Iterator<String> iterator = new ArrayIterator(names);while (iterator.hasNext()) {System.out.println(iterator.currentItem());iterator.next();}}}
JAVA集合
MySQL ResultSet
优点
- 访问一个聚合对象的内容而无须暴露它的内部表示。
- 遍历任务交由迭代器完成,这简化了聚合类。
- 它支持以不同方式遍历一个聚合,甚至可以自定义迭代器的子类以支持新的遍历。
- 增加新的聚合类和迭代器类都很方便,无须修改原有代码。
- 封装性良好,为遍历不同的聚合结构提供一个统一的接口。
缺点
增加了类的个数,这在一定程度上增加了系统的复杂性。
扩展
为什么要用迭代器
首先,对于类似数组和链表这样的数据结构,遍历方式比较简单,直接使用 for 循环来遍历就足够了。但是,对于复杂的数据结构(比如树、图)来说,有各种复杂的遍历方式。比如,树有前中后序、按层遍历,图有深度优先、广度优先遍历等等。如果由客户端代码来实现这些遍历算法,势必增加开发成本,而且容易写错。如果将这部分遍历的逻辑写到容器类中,也会导致容器类代码的复杂性。
其次,前面也多次提到,应对复杂性的方法就是拆分。我们可以将遍历操作拆分到迭代器类中。比如,针对图的遍历,我们就可以定义 DFSIterator、BFSIterator 两个迭代器类,让它们分别来实现深度优先遍历和广度优先遍历。其次,将游标指向的当前位置等信息,存储在迭代器类中,每个迭代器独享游标信息。这样,我们就可以创建多个不同的迭代器,同时对同一个容器进行遍历而互不影响。
最后,容器和迭代器都提供了抽象的接口,方便我们在开发的时候,基于接口而非具体的实现编程。当需要切换新的遍历算法的时候,比如,从前往后遍历链表切换成从后往前遍历链表,客户端代码只需要将迭代器类从 LinkedIterator 切换为 ReversedLinkedIterator 即可,其他代码都不需要修改。除此之外,添加新的遍历算法,我们只需要扩展新的迭代器类,也更符合开闭原则。
如何应对遍历时改变集合导致的未决行为
我们在 ArrayList 中定义一个成员变量 modCount,记录集合被修改的次数,集合每调用一次增加或删除元素的函数,就会给 modCount 加 1。当通过调用集合上的 iterator() 函数来创建迭代器的时候,我们把 modCount 值传递给迭代器的 expectedModCount 成员变量,之后每次调用迭代器上的 hasNext()、next()、currentItem() 函数,我们都会检查集合上的 modCount 是否等于 expectedModCount,也就是看,在创建完迭代器之后,modCount 是否改变过。
如果两个值不相同,那就说明集合存储的元素已经改变了,要么增加了元素,要么删除了元素,之前创建的迭代器已经不能正确运行了,再继续使用就会产生不可预期的结果,所以我们选择 fail-fast 解决方式,抛出运行时异常,结束掉程序,让程序员尽快修复这个因为不正确使用迭代器而产生的 bug。
如何在遍历的同时安全地删除集合元素?
iterator.remove(),但只能连续调1次,关于这个的讲解忽略。
设计迭代器的快照
基于原型模式
基于时间戳
这部分省略

若有收获,就点个赞吧
0 人点赞
