散列表
散列表用的就是数组支持按照下标随机访问的时候,时间复杂度是 O(1) 的特性。我们通过散列函数把元素的键值映射为下标,然后将数据存储在数组中对应下标的位置。当我们按照键值查询元素时,我们用同样的散列函数,将键值转化数组下标,从对应的数组下标的位置取数据。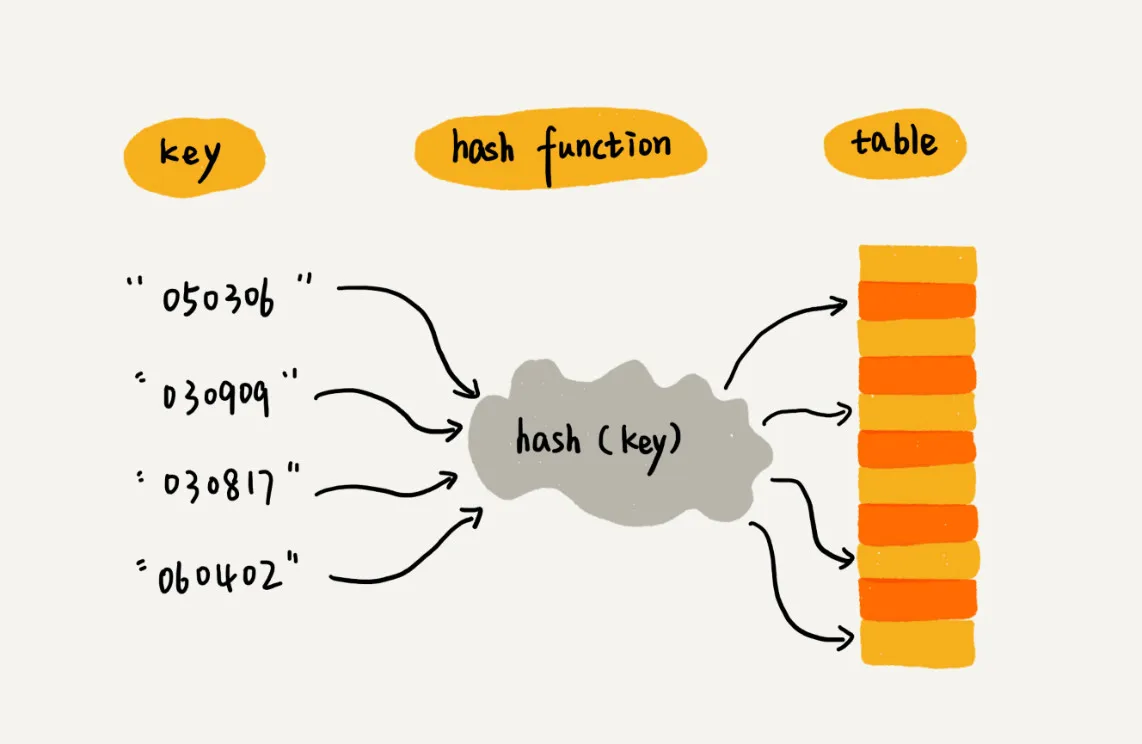
散列函数
散列函数的基本要求:
- 散列函数计算得到的散列值是一个非负整数;
- 如果 key1 = key2,那 hash(key1) == hash(key2);
- 如果 key1 ≠ key2,那 hash(key1) ≠ hash(key2)。
其中,第三点很难实现,当key不通,hash值相同时,称为散列冲突,或者hash碰撞。
散列函数的设计:
散列函数的设计不能太复杂。过于复杂的散列函数,势必会消耗很多计算时间,也就间接地影响到散列表的性能。
其次,散列函数生成的值要尽可能随机并且均匀分布,这样才能避免或者最小化散列冲突,而且即便出现冲突,散列到每个槽里的数据也会比较平均,不会出现某个槽内数据特别多的情况。
散列冲突
散列冲突的应对方案:开放寻址法(open addressing)和链表法(chaining)。
开放寻址法
开放寻址法的核心思想是,如果出现了散列冲突,我们就重新探测一个空闲位置,将其插入。
线性探测(Linear Probing):
往散列表中插入数据时,如果某个数据经过散列函数散列之后,存储位置已经被占用了,我们就从当前位置开始,依次往后查找,看是否有空闲位置,直到找到为止。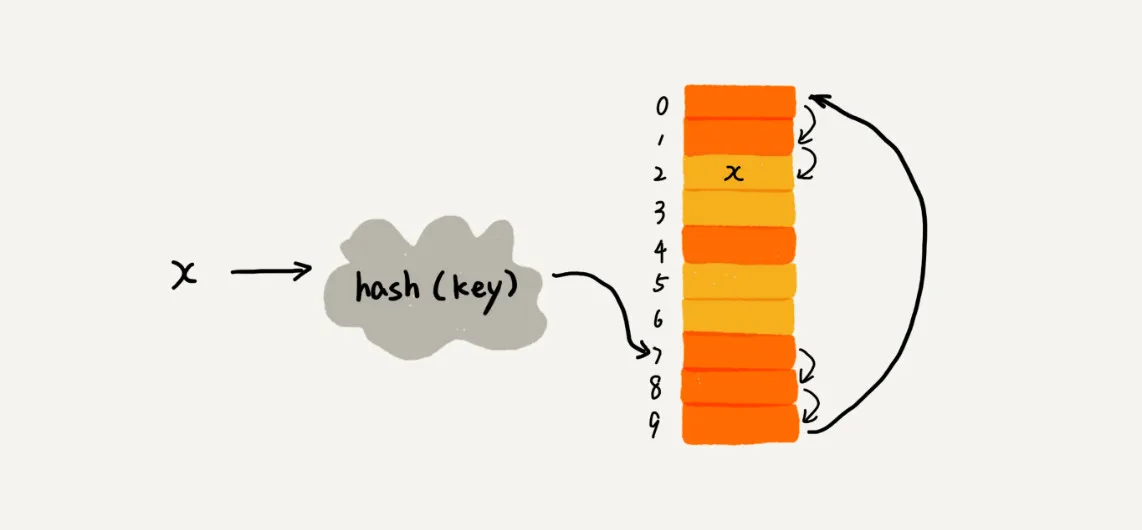
二次探测:跟线性探测很像,线性探测每次探测的步长是 1,那它探测的下标序列就是 hash(key)+0,hash(key)+1,hash(key)+2……而二次探测探测的步长就变成了原来的“二次方”,也就是说,它探测的下标序列就是 hash(key)+0,hash(key)+12,hash(key)+22……
双重探测:使用一组散列函数 hash1(key),hash2(key),hash3(key)……我们先用第一个散列函数,如果计算得到的存储位置已经被占用,再用第二个散列函数,依次类推,直到找到空闲的存储位置。
开放寻址的优点:开放寻址法不像链表法,需要拉很多链表。散列表中的数据都存储在数组中,可以有效地利用 CPU 缓存加快查询速度。而且,这种方法实现的散列表,序列化起来比较简单。链表法包含指针,序列化起来就没那么容易。
开放寻址的缺点:用开放寻址法解决冲突的散列表,删除数据的时候比较麻烦,需要特殊标记已经删除掉的数据。而且,在开放寻址法中,所有的数据都存储在一个数组中,比起链表法来说,冲突的代价更高。所以,使用开放寻址法解决冲突的散列表,装载因子的上限不能太大。这也导致这种方法比链表法更浪费内存空间。
总结一下,当数据量比较小、装载因子小的时候,适合采用开放寻址法。这也是 Java 中的ThreadLocalMap使用开放寻址法解决散列冲突的原因。
链表法
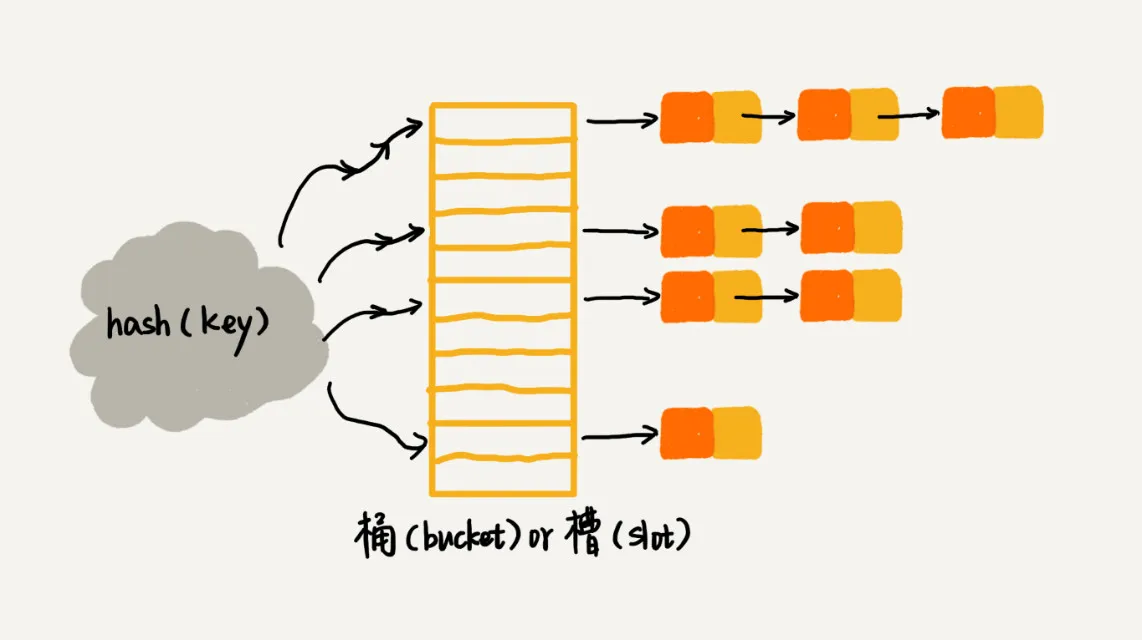
优点:
- 链表法对内存的利用率比开放寻址法要高。因为链表结点可以在需要的时候再创建,并不需要像开放寻址法那样事先申请好。
- 链表法比起开放寻址法,对大装载因子的容忍度更高。开放寻址法只能适用装载因子小于 1 的情况。接近 1 时,就可能会有大量的散列冲突,导致大量的探测、再散列等,性能会下降很多。但是对于链表法来说,只要散列函数的值随机均匀,即便装载因子变成 10,也就是链表的长度变长了而已,虽然查找效率有所下降,但是比起顺序查找还是快很多。
- 链表因为要存储指针,所以对于比较小的对象的存储,是比较消耗内存的,还有可能会让内存的消耗翻倍。而且,因为链表中的结点是零散分布在内存中的,不是连续的,所以对 CPU 缓存是不友好的,这方面对于执行效率也有一定的影响。
- 可以实现一个更加高效的散列表。那就是,我们将链表法中的链表改造为其他高效的动态数据结构,比如跳表、红黑树。这样,即便出现散列冲突,极端情况下,所有的数据都散列到同一个桶内,那最终退化成的散列表的查找时间也只不过是 O(logn)。这样也就有效避免了前面讲到的散列碰撞攻击。
总结一下,基于链表的散列冲突处理方法比较适合存储大对象、大数据量的散列表,而且,比起开放寻址法,它更加灵活,支持更多的优化策略,比如用红黑树代替链表。
案例
Java 中 LinkedHashMap 就采用了链表法解决冲突,ThreadLocalMap 是通过线性探测的开放寻址法来解决冲突。
散列表扩容
装载因子
当散列表中空闲位置不多的时候,散列冲突的概率就会大大提高。为了尽可能保证散列表的操作效率,一般情况下,我们会尽可能保证散列表中有一定比例的空闲槽位。我们用装载因子(load factor)来表示空位的多少。
装载因子的计算公式是:散列表的装载因子=填入表中的元素个数/散列表的长度
装载因子越大,说明空闲位置越少,冲突越多,散列表的性能会下降。
渐进式扩容
通常情况下,每次扩容会一次性把旧空间的数据复制到新空间,数据量大时,会造成卡顿。
渐进式扩容:每次插入数据时,把哈希桶一并复制到新空间,将复制操作均摊。
工业级散列表
应该具备的特性:
- 支持快速地查询、插入、删除操作;
- 内存占用合理,不能浪费过多的内存空间;
- 性能稳定,极端情况下,散列表的性能也不会退化到无法接受的情况。
1. 初始大小
HashMap 默认的初始大小是 16,当然这个默认值是可以设置的,如果事先知道大概的数据量有多大,可以通过修改默认初始大小,减少动态扩容的次数,这样会大大提高 HashMap 的性能。
2. 装载因子和动态扩容
最大装载因子默认是 0.75,当 HashMap 中元素个数超过 0.75*capacity(capacity 表示散列表的容量)的时候,就会启动扩容,每次扩容都会扩容为原来的两倍大小。
3. 散列冲突解决方法
HashMap 底层采用链表法来解决冲突。即使负载因子和散列函数设计得再合理,也免不了会出现拉链过长的情况,一旦出现拉链过长,则会严重影响 HashMap 的性能。于是,在 JDK1.8 版本中,为了对 HashMap 做进一步优化,我们引入了红黑树。而当链表长度太长(默认超过 8)时,链表就转换为红黑树。我们可以利用红黑树快速增删改查的特点,提高 HashMap 的性能。当红黑树结点个数少于 8 个的时候,又会将红黑树转化为链表。因为在数据量较小的情况下,红黑树要维护平衡,比起链表来,性能上的优势并不明显。
4. 散列函数
散列函数的设计并不复杂,追求的是简单高效、分布均匀。
int hash(Object key) {int h = key.hashCode();return (h ^ (h >>> 16)) & (capicity -1); //capicity表示散列表的大小}
其中,hashCode() 返回的是 Java 对象的 hash code。比如 String 类型的对象的 hashCode() 就是下面这样:
public int hashCode() {int var1 = this.hash;if(var1 == 0 && this.value.length > 0) {char[] var2 = this.value;for(int var3 = 0; var3 < this.value.length; ++var3) {var1 = 31 * var1 + var2[var3];}this.hash = var1;}return var1;}

若有收获,就点个赞吧
0 人点赞
