跳表使用空间换时间的设计思路,通过构建多级索引来提高查询的效率,实现了基于链表的“二分查找”。跳表是一种动态数据结构,支持快速地插入、删除、查找操作,时间复杂度都是 O(logn)。
跳表的空间复杂度是 O(n)。不过,跳表的实现非常灵活,可以通过改变索引构建策略,有效平衡执行效率和内存消耗。虽然跳表的代码实现并不简单,但是作为一种动态数据结构,比起红黑树来说,实现要简单多了。所以很多时候,我们为了代码的简单、易读,比起红黑树,我们更倾向用跳表。
数据结构
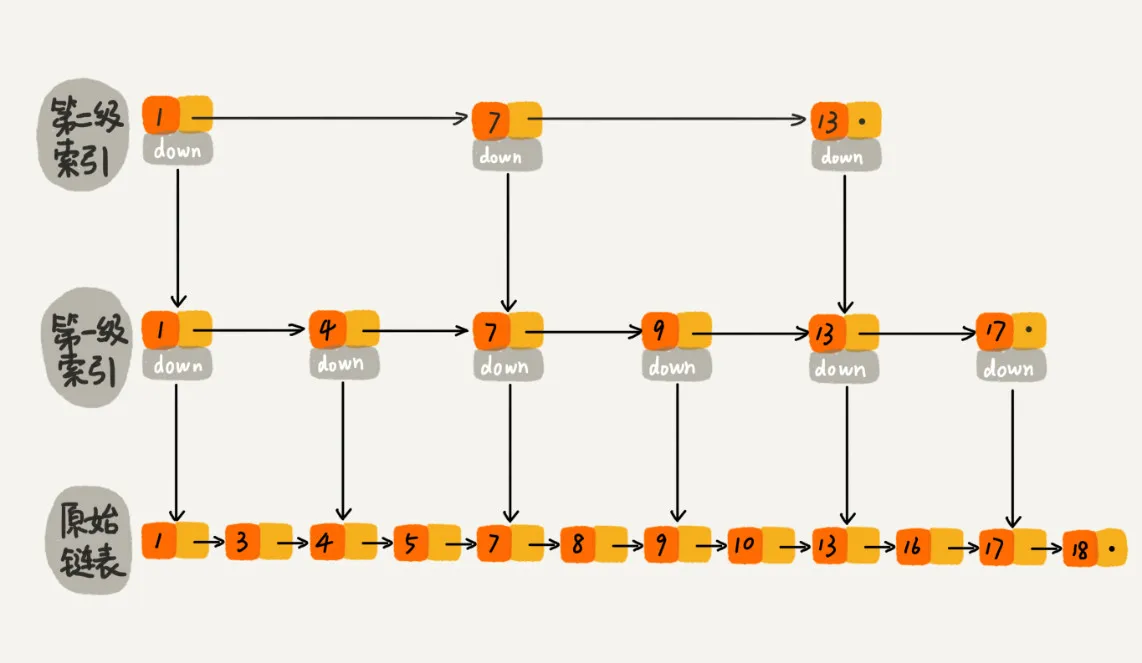
查找
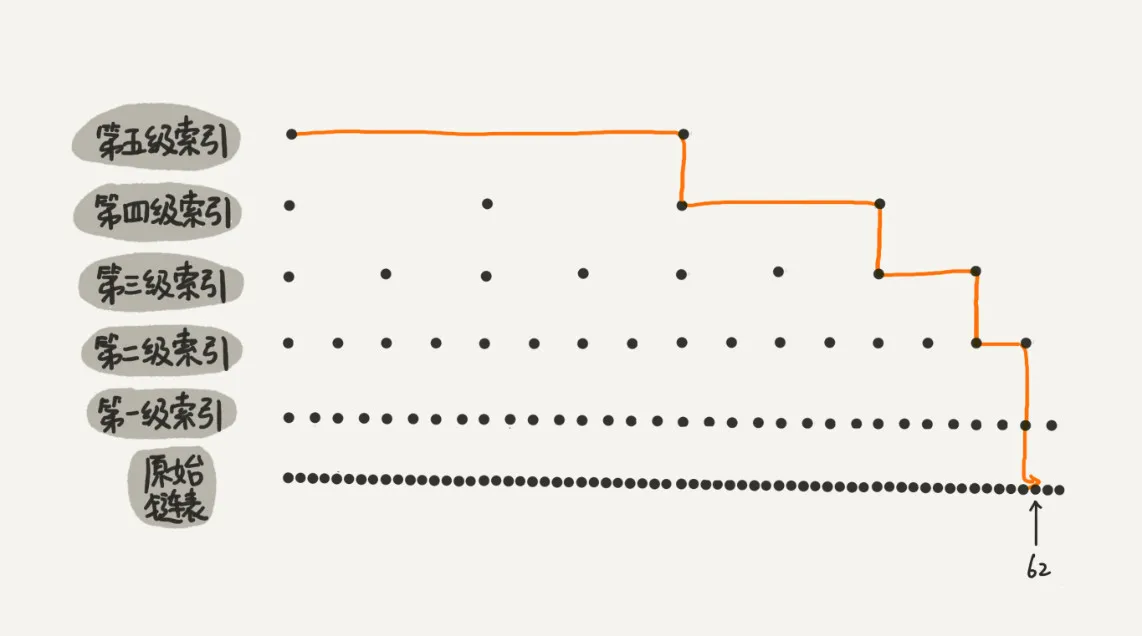
查找时间复杂度
在建立了完全索引的跳表上查找的时间复杂度为O(logn):
第 k 级索引的结点个数是第 k-1 级索引的结点个数的 1/2,那第 k级索引结点的个数就是 n/(2k)。
假设索引有 h 级,最高级的索引有 2 个结点。通过上面的公式,我们可以得到 n/(2h)=2,从而求得 h=log2n-1。如果包含原始链表这一层,整个跳表的高度就是 log2n。
每一层最多只需要进行三次查找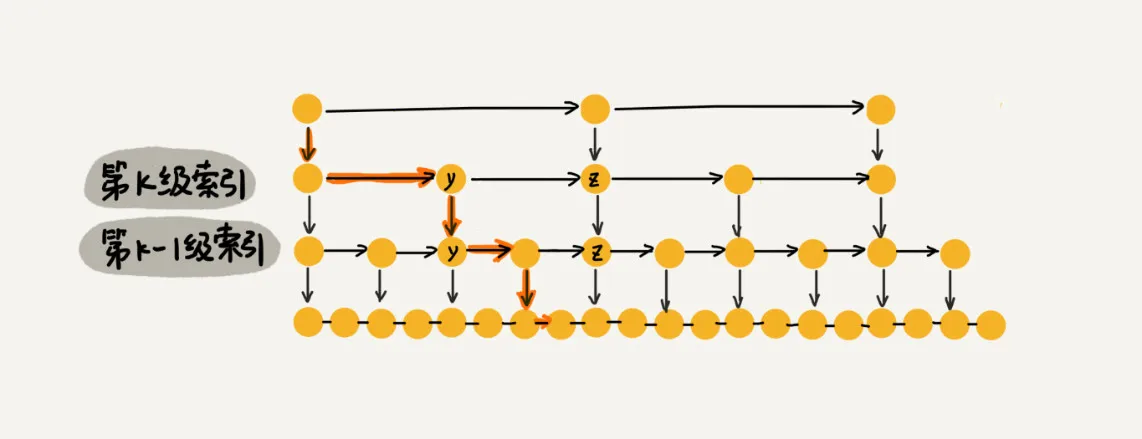
故在跳表中查询任意数据的时间复杂度就是 O(logn)
空间复杂度
建立了完全索引的跳表的空间复杂度为O(n):
等比数列求和n/2+n/4+n/8…+8+4+2=n-2
可以通过扩大间距来节省空间。
实际开发中,每个节点存储数据量会比较大,而索引节点只需要存储简单的键值和指针,远小于存储的数据。
索引动态更新
跳表是通过随机函数来维护“平衡性”。通过一个随机函数,来决定将这个结点插入到哪几级索引中,比如随机函数生成了值 K,那我们就将这个结点添加到第一级到第 K 级这 K 级索引中。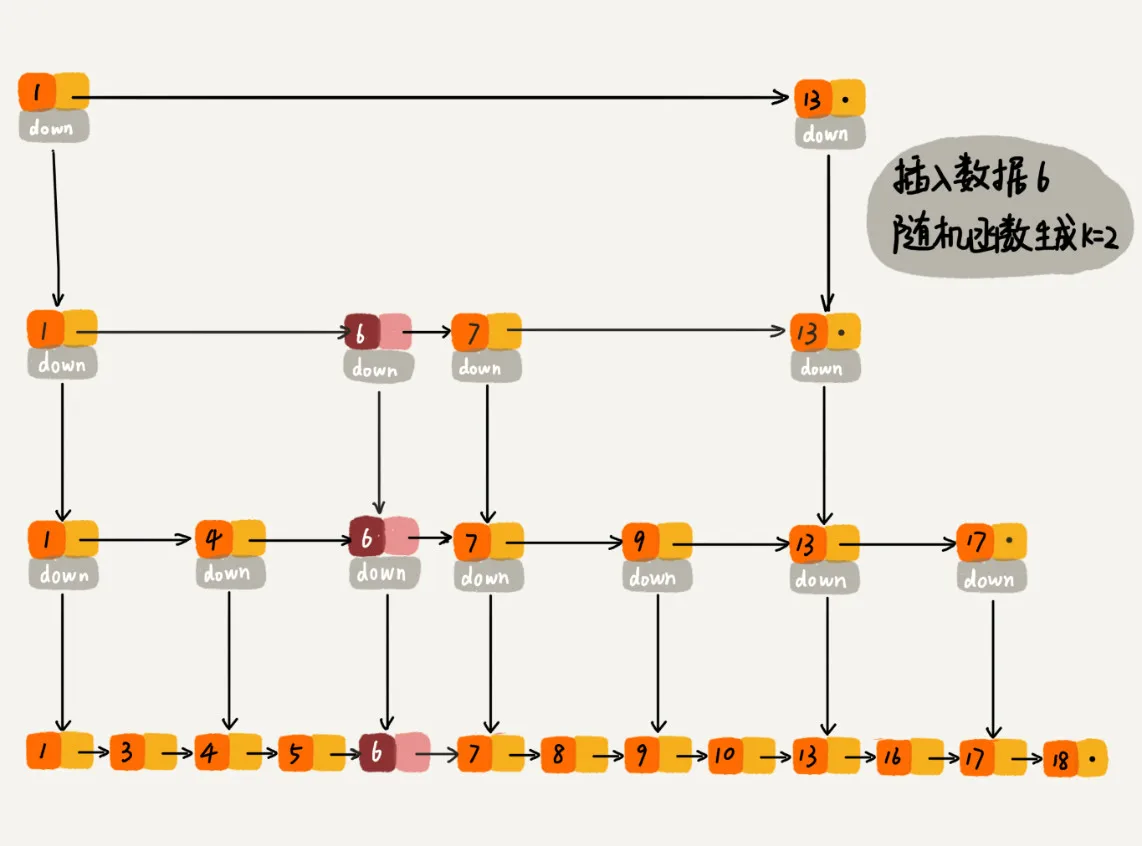
Redis为什么选择跳表实现有序集合
Redis 中的有序集合是通过跳表来实现的,严格点讲,其实还用到了散列表。
Redis 中的有序集合支持的核心操作主要有下面这几个:
- 插入一个数据;
- 删除一个数据;
- 查找一个数据;
- 按照区间查找数据(比如查找值在[100, 356]之间的数据);
- 迭代输出有序序列。
其中,插入、删除、查找以及迭代输出有序序列这几个操作,红黑树也可以完成,时间复杂度跟跳表是一样的。
但是,按照区间来查找数据这个操作,红黑树的效率没有跳表高。对于按照区间查找数据这个操作,跳表可以做到 O(logn) 的时间复杂度定位区间的起点,然后在原始链表中顺序往后遍历就可以了。这样做非常高效。
当然,Redis 之所以用跳表来实现有序集合,还有其他原因,比如,跳表更容易代码实现。虽然跳表的实现也不简单,但比起红黑树来说还是好懂、好写多了,而简单就意味着可读性好,不容易出错。还有,跳表更加灵活,它可以通过改变索引构建策略,有效平衡执行效率和内存消耗。
不过,跳表也不能完全替代红黑树。因为红黑树比跳表的出现要早一些,很多编程语言中的 Map 类型都是通过红黑树来实现的。我们做业务开发的时候,直接拿来用就可以了,不用费劲自己去实现一个红黑树,但是跳表并没有一个现成的实现,所以在开发中,如果你想使用跳表,必须要自己实现。

若有收获,就点个赞吧
0 人点赞
