定义
图(Graph)
元素叫顶点(vertex)
顶点之间的连线叫做边(edge)
顶点相连接的边的条数叫度(degree)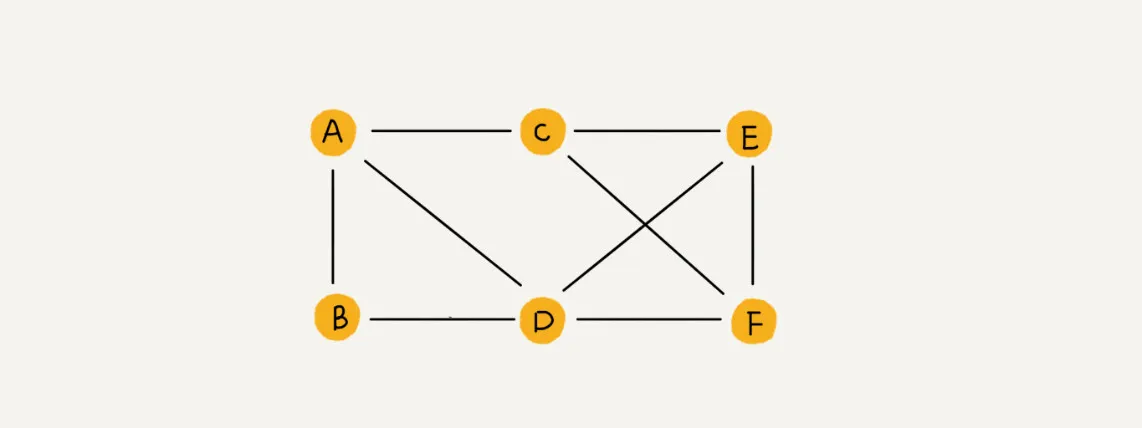
有向图
在有向图中,度分为入度(In-degree)和出度(Out-degree)。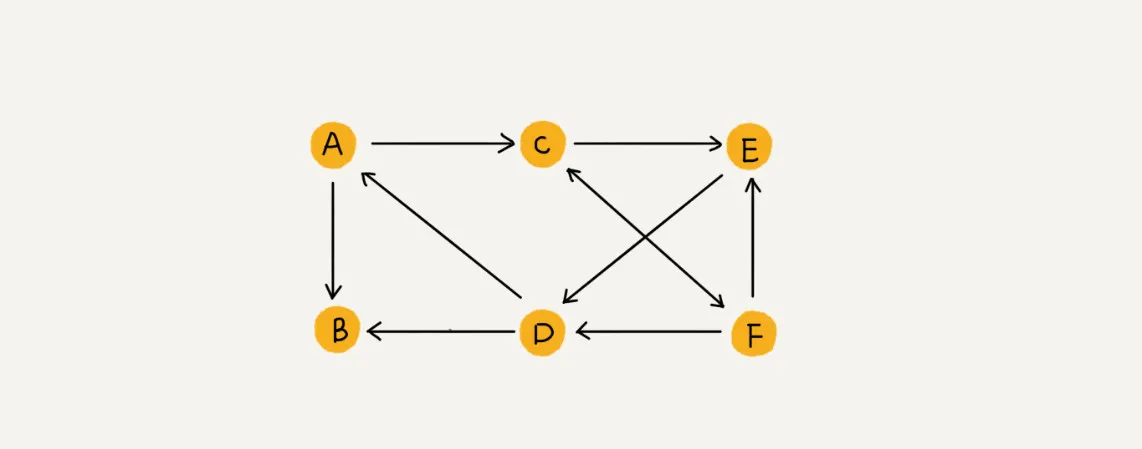
带权图(weighted graph)。每条边都有一个权重(weight)。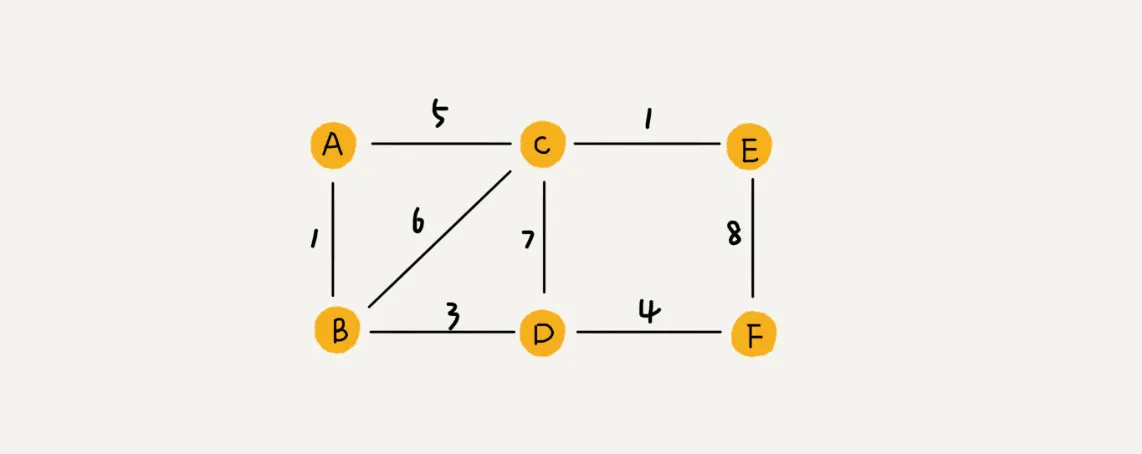
邻接矩阵存储法
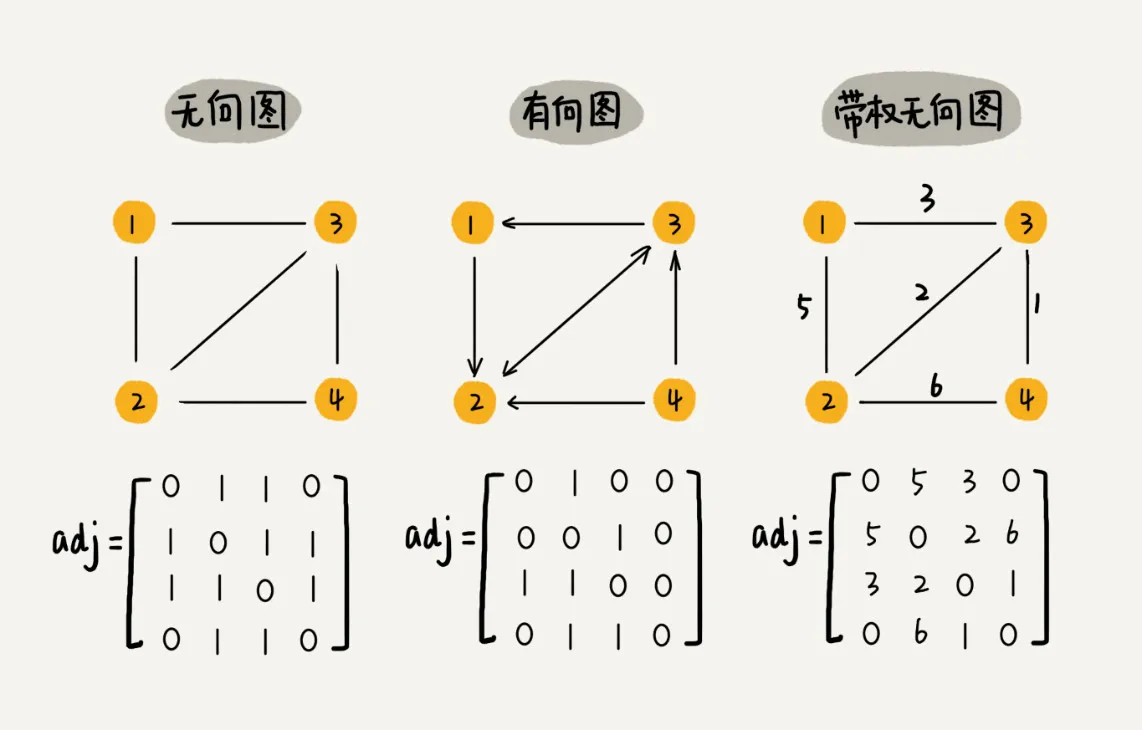
邻接矩阵的存储方式简单、直接,因为基于数组,所以在获取两个顶点的关系时,就非常高效。其次,用邻接矩阵存储图的另外一个好处是方便计算。这是因为,用邻接矩阵的方式存储图,可以将很多图的运算转换成矩阵之间的运算。
用邻接矩阵来表示一个图,虽然简单、直观,但是比较浪费存储空间。
如果存储的是稀疏图(Sparse Matrix),也就是说,顶点很多,但每个顶点的边并不多,那邻接矩阵的存储方法就更加浪费空间了。比如微信有好几亿的用户,对应到图上就是好几亿的顶点。但是每个用户的好友并不会很多,一般也就三五百个而已。如果我们用邻接矩阵来存储,那绝大部分的存储空间都被浪费了。
邻接表存储方法
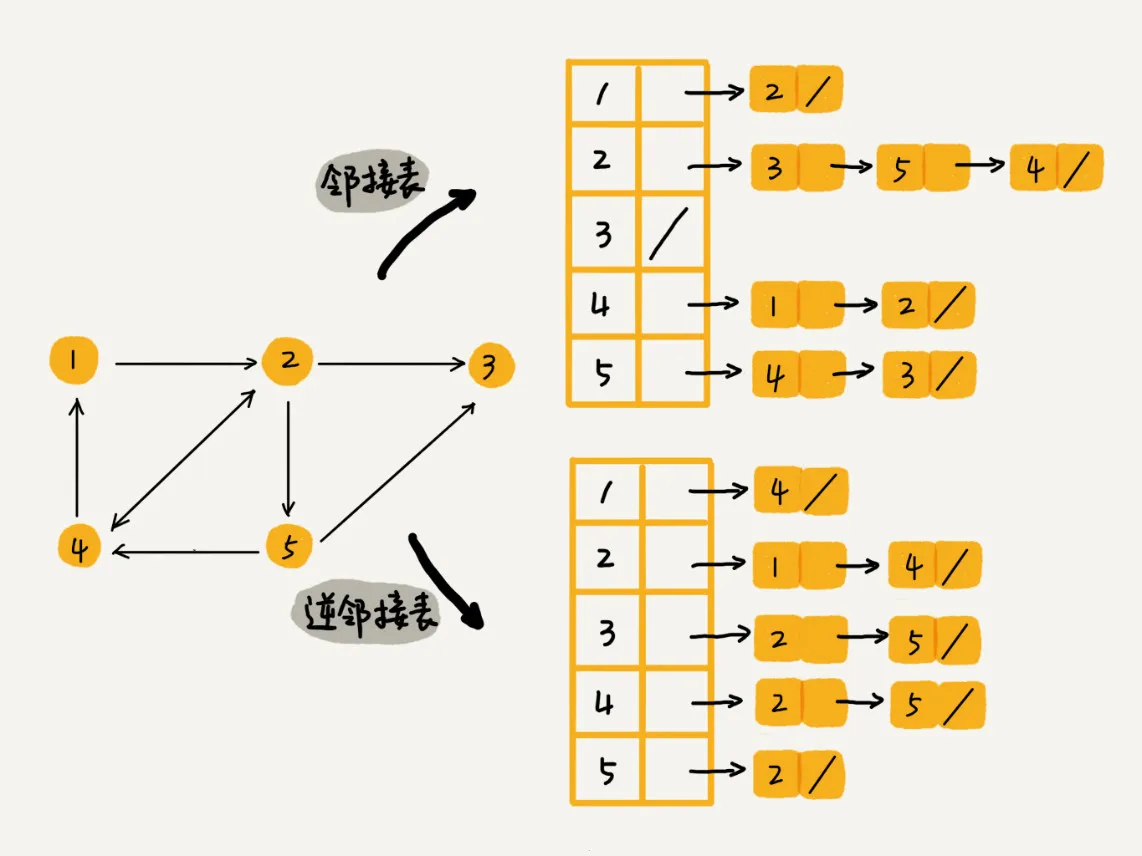
邻接矩阵存储起来比较浪费空间,但是使用起来比较节省时间。相反,邻接表存储起来比较节省空间,但是使用起来就比较耗时间。
链表的存储方式对cpu缓存不友好。所以,比起邻接矩阵的存储方式,在邻接表中查询两个顶点之间的关系就没那么高效了。
可以将邻接表中的链表改成平衡二叉查找树。实际开发中,我们可以选择用红黑树。这样,我们就可以更加快速地查找两个顶点之间是否存在边了。当然,这里的二叉查找树可以换成其他动态数据结构,比如跳表、散列表等。除此之外,我们还可以将链表改成有序动态数组,可以通过二分查找的方法来快速定位两个顶点之间否是存在边。
广度优先搜索(BFS)
广度优先搜索(Breadth-First-Search),我们平常都简称 BFS。直观地讲,它其实就是一种“地毯式”层层推进的搜索策略,即先查找离起始顶点最近的,然后是次近的,依次往外搜索。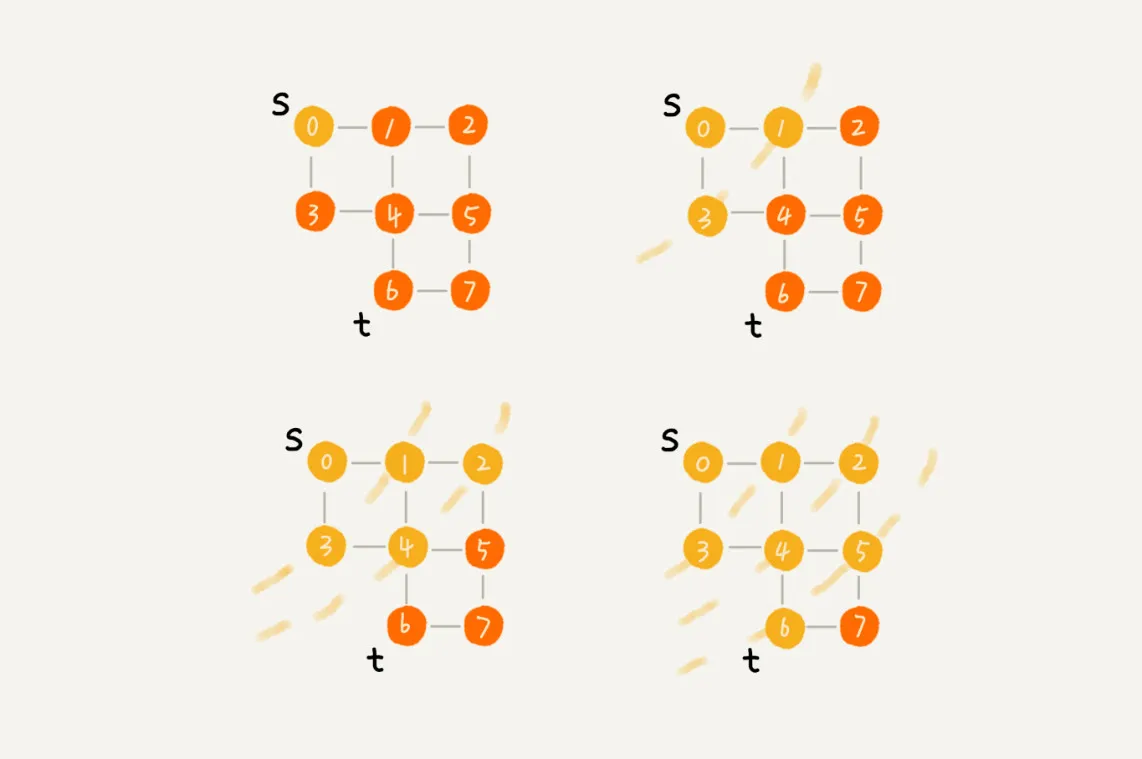
深度优先搜索(DFS)

若有收获,就点个赞吧
0 人点赞
