Numpy 包提供了一种特别的list,叫做 Numpy Array ,它可以实现许多额外的功能。比如,可以对其进行数学运算。
导入numpy
import numpy as np #简化调用
numpy 下载可以直接使用 pip install numpy 或通过anaconda 下载。
使用numpy
快速创建numpy_array
numpy.arange(n).reshape(x, y) ,创建一个二维numpy_array(单独的一行也是一个列表),一共有n个元素,显示为x行,每行有y个元素。
arrange(x, y, n) 也可输入三个参数,表示x 到y-n,以n 为间隔进行数字取值。
将列表转化为numpy 格式
np_list = np.array(list)
使用numpy.array 进行简单数学运算
np_height_m = np.array(height_in) * 0.0254
np_weight_kg = np.array(weight_lb) * 0.453592
bmi = np_weight_kg / np_height_m ** 2
过滤列表中的信息
light = bmi < 21
#会返回一个numpy列表,其元素为布尔值,符合条件元素对应为True。
bmi_light = bmi[light]
选择指定子集
在数学符号运算上,numpy 与一般列表不同。你可以试试一般列表的相加与numpy 的相加。
但numpy 也和一般列表有共同之处。
我们也可以提取numpy_array中的元素,或直接使用切片操作。
np_list = np.array([1,2,3,4,5])
np_list_selected = np_list[1:3]
创建多维列表
np_2dlist = np.array([[1,2],[3,4]])
可以通过 shape 查看array 信息。
np_2dlist.shape
(2, 2) #2X2,2行,每行2列(2个元素)
2d列表的提取也可以直接提取或使用切片操作。array[][] ,也可以直接用逗号分隔 array[,]
使用切片
>>> np_2dlist[:,0]
array([1, 3])
简单的统计学计算
# np_baseball is available
# Import numpy
import numpy as np
# Print mean height (first column)
avg = np.mean(np_baseball[:,0])
print("Average: " + str(avg))
# Print median height. Replace 'None'
med = np.median(np_baseball[:,0])
print("Median: " + str(med))
# Print out the standard deviation on height. Replace 'None'
stddev = np.std(np_baseball[:,0])
print("Standard Deviation: " + str(stddev))
# Print out correlation between first and second column. Replace 'None'
corr = np.corrcoef(np_baseball[:,0], np_baseball[:,1])
print("Correlation: " + str(corr))
比较字符串
Numpy 无法直接使用and, or, not 这些比较字符串。
但其可以使用np包中的函数: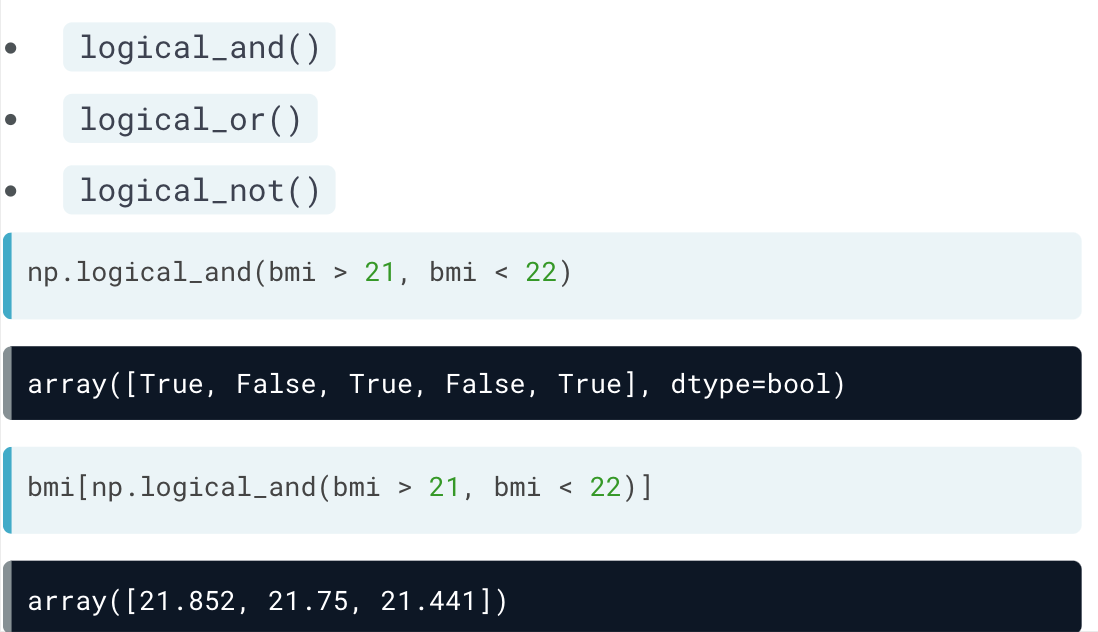
注意项
numpy_array 只可以存储一种类型的数据。
如果尝试在其中存储多个类型的元素,则numpy 会自动将表格元素进行同质化(homogeneous)处理,这个过程也叫做类型强迫(type coercion)。

若有收获,就点个赞吧
0 人点赞
