pandas
直接合并
可以直接两个表格相加,非常简单粗暴。
还可以使用 .add 。还可以通过设定参数去除缺失值。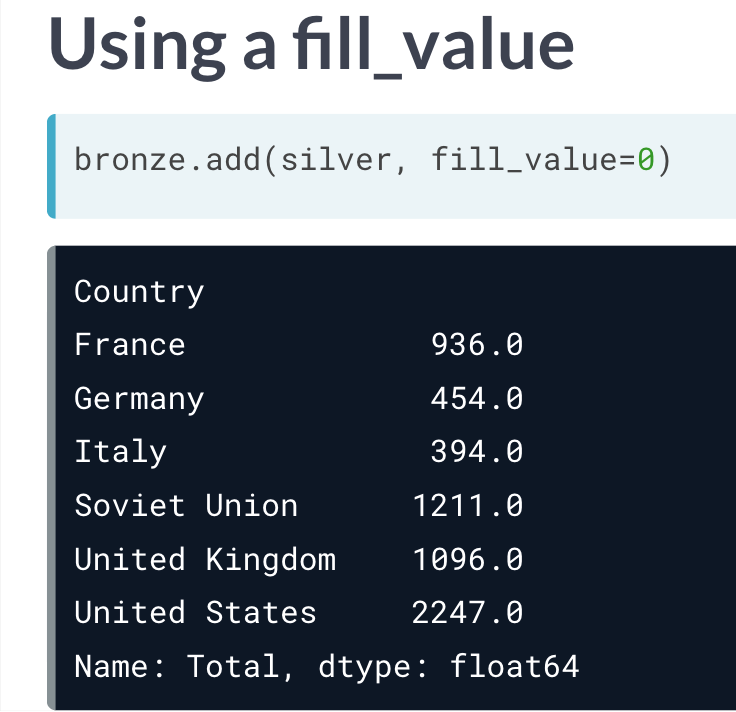
concat()与append()
利用链式方法append 或者输入列表到concat。
- append()
- concat()
```python
Create a list of weather_max and weather_mean
weather_list = [weather_max, weather_mean]
Concatenate weather_list horizontally
weather = pd.concat(weather_list, axis = 1)
Print weather
print(weather)
其中axis = 'columns' 与1 相当于通过列合并(横着并),而axis = 'rows' 与0 表示通过行合并(竖着并)。<a name="TjrIs"></a>### 创建多索引的列表合并在调用concat时候,设定参数 `keys` ,作为外部索引标记原先表格的索引,但需要注意,输入参数的顺序需与concat输入的表格顺序一致。也可以使用字典,将待录入的表格存入一个字典的值中,而键则是指定的外部索引。<a name="eDteK"></a>### concat 与参数join<a name="GT8t5"></a>#### inner_join只保留连接列表中均有数值的索引内容。(非共有部分直接drop掉了)```python# Create the list of DataFrames: medal_listmedal_list = [bronze, silver, gold]# Concatenate medal_list horizontally using an inner join: medalsmedals = pd.concat(medal_list, keys=['bronze', 'silver', 'gold'], axis=1, join='inner')# Print medalsprint(medals)'''the index parts that are not the co-existing row indexs have been dropped.<script.py> output:bronze silver goldTotal Total TotalCountryUnited States 1052.0 1195.0 2088.0Soviet Union 584.0 627.0 838.0United Kingdom 505.0 591.0 498.0'''
outer_join
当有只在某个列表中有数值记录的索引时,另一个列表相关记录的信息会用NaN替代。(但还是会保留全部的记录)
merge
merge 方法是对concat 的拓展。 pd.merge(data_frame_a, data_frame_b) 。 on 参数可以被设定,作为合并两个列表的纽带。(和R的join 太像了。)
且两个列表中共同存在的列会被添加上一个suffix,默认按照merge 中输入的表格顺序添加,第一个为_x,第二个为_y,也可通过 suffixes = 设定。(或者分别设定 lsuffix = , rsuffix = )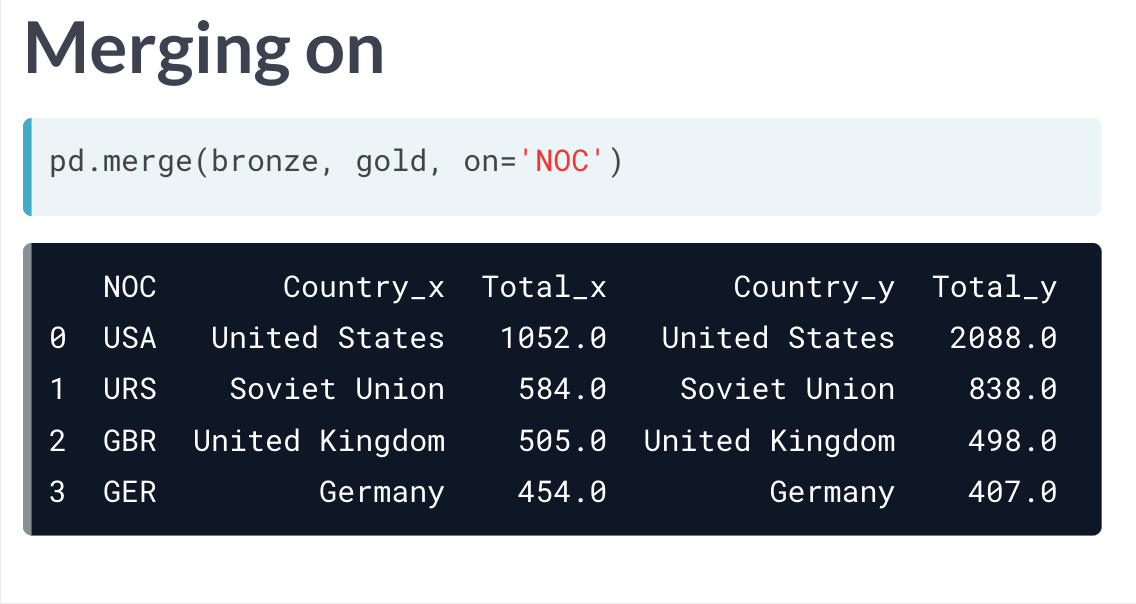
但直接设定merge,前提是两个表格需要有相同名字的col_index,可是通常情况下,在不同表格中,col_index的名字不尽相同,因此需要通过参数设定。pd.merge(data_frame_a, data_frame_b, left_on = 'a_col_idx', right_on = 'b_col_idx')
# Perform the first merge: merge_default
merge_default = pd.merge(sales_and_managers, revenue_and_sales)
# Print merge_default
print(merge_default)
# Perform the second merge: merge_outer
merge_outer = pd.merge(sales_and_managers, revenue_and_sales, how='outer')
# Print merge_outer
print(merge_outer)
# Perform the third merge: merge_outer_on
merge_outer_on = pd.merge(sales_and_managers, revenue_and_sales, on=['city','state'], how='outer')
# Print merge_outer_on
print(merge_outer_on)
join参数
merge 默认为inner_join 连接,可以通过 how 参数设定,相当于concat 中的 join 参数。
merge_ordered() 与merge_asof()
merge_ordered 相当于默认将设定的on 的列作为排序选项,进行升序。(类似于 .sort_values() )。merge_asof() 与上者类似,也会对on 列进行排序,只不过默认为left join 的连接方式。
处理缺失值的方法
通过参数 fill_method 可以设定如何处理缺失值,类似 003. 使用pandas进行数据分析 中提到的,如 ffill 可以将NaN向上取值进行替代(最近的一个有数值的行)。
003. 使用pandas进行数据分析
几种类型的join
- inner join
保留共有的列。
- outer join
保留全部列,无值内容为NaN。
- left join
保留第一个列表全部列,无值内容为NaN。
- right join
保留第二个列表全部列,无值内容为NaN。
join
a_df.join(b_df) ,默认参数为left_join。相当于简化版的merge,也可以设定 how 参数。
如何选择连接的方法

小问题
需要注意的是,无论是利用append 还是concat 添加的表格,会保留原来的index,因此在利用ilib 等根据index 选取表格的方法时,可能会有问题。
我们可以用 .reset_index(drop = True) 删去重复的索引。另外一个解决的方法是设定参数 ignore_index = True ,也可以达到一样的效果。
numpy
numpy 的表格除了必须包含相同类型的元素外,与pandas 有非常多的相似之处,因此在进行合并时也有类似的操作。
concatenate(), [hv]stack()

h(horizontal), hstack 相当于axis = 1(columns)的concatenate。
v(vertical), vstack 相当于axis = 0(rows)的concatenate。
注意
一、使用concat, hstack, append 等合并表格时,如果时行合并(竖着)则必须要有相同的列数,反之亦然。
二、

若有收获,就点个赞吧
0 人点赞
