pandaspythondata_clean
为什么需要数据清理?
数据类型问题
将字符串转为数字
有时候本身应该为数字格式的信息却因为存在某些标记而存储为字符串格式,比如 $2019 。
这时候可以使用, .str.strip('$') 去掉特殊符号。
接着使用 .astype('int') 变为指定类型的整数或其他类型内容。
可以使用assert 验证一下。
# Strip duration of minutesride_sharing['duration_trim'] = ride_sharing['duration'].str.strip('minutes')# Convert duration to integerride_sharing['duration_time'] = ride_sharing['duration_trim'].astype('int')# Write an assert statement making sure of conversionassert ride_sharing['duration_time'].dtype == 'int'# Print formed columns and calculate average ride durationprint(ride_sharing[['duration','duration_trim','duration_time']])print(ride_sharing['duration_time'].mean())
将字符串转为日期
使用 pd.to_datatime() 。
数值范围问题
有的时候可能会因为人工或其他因素,使数值超出了预期的范围,比如订票系统出现了“未来人”的订票时间,五星评分机制出现了“六星”评分。这时候需要我们处理这些数据。
去除超范围数据
这是最简单的一种方法,不对劲就删掉好了。
inplace 表示直接将符合条件整行删除,不创建新的对象。
将超范围数值转为最小最大值
# Convert tire_sizes to integer
ride_sharing['tire_sizes'] = ride_sharing['tire_sizes'].astype('int')
# Set all values above 27 to 27
ride_sharing.loc[ride_sharing['tire_sizes'] > 27, 'tire_sizes'] = 27
# Reconvert tire_sizes back to categorical
ride_sharing['tire_sizes'] = ride_sharing['tire_sizes'].astype('category')
# Print tire size description
print(ride_sharing['tire_sizes'].describe())
重复值问题
找出重复值
df.duplicated() ,会返回对于索引的布尔值数据的列表,显示为True 的行即表示有重复值。
或将其作为条件,直接筛选表格对应的列。
该函数有两个重要参数:
1)subset,用于比较重复的列。
2)keep,选择是否保留重复值,默认不保留,或设定 first, last 保留第一个或最后一个,或设定False保留所有重复值。
删除重复值
.drop_duplicates() 。
和.duplicated() 有相同的参数外,多了一个 inplace ,True 即为直接删除正行。
整合重复值
除了直接暴力删除重复值,另外一个比较好的方式是整合重复值信息。
我们可以利用分组,将作为筛选重复值独立条件的信息也作为分组条件,并对分组信息进行计算,比如平均或最高值等。
# Drop complete duplicates from ride_sharing
ride_dup = ride_sharing.drop_duplicates()
# Create statistics dictionary for aggregation function
statistics = {'user_birth_year': 'min', 'duration': 'mean'}
# Group by ride_id and compute new statistics
ride_unique = ride_dup.groupby('ride_id').agg(statistics).reset_index()
# Find duplicated values again
duplicates = ride_unique.duplicated(subset = 'ride_id', keep = False)
duplicated_rides = ride_unique[duplicates == True]
# Assert duplicates are processed
assert duplicated_rides.shape[0] == 0
资格问题
类似于重复值,资格(membership)错误也是比较常见的人工错误之一。它主要是由于记录过程中,录入了本来不存在的内容。比如记录血型时,记录过程中录入了错误信息,把A+ 记为Z+,则会凭白无故多出来一个种类。
但不同于重复值单纯从表示上就是重复的,资格问题中的内容为内容上的重复(不同的表达,相同的意味),因此处理起来也比单纯的重复值问题要繁琐。
查询方式
通过几个步骤可以将该种类找到并与原表格分离:
1)调用原先统计血型类型表中的内容,并将之与记录表格中的血型进行比较,使用 difference 函数。
2)找出类型错误值对应的行。
3)以类型错误值对应的行作为条件,选择或反选择(~)出错误值对应表格信息与错误值外对应表格信息。
# 将记录表中的血型作为集合,再和种类表中的血型进行比较。
inconsistent_categories = set(record['blood_type']).difference(categories['blood_type'])
# 找出类型错误值对应的行
inconsistent_categories_rows = record['blood_type'].isin(inconsistent_categories)
# 分别选出矛盾与非矛盾数据
inconsistent_categories_data = record[inconsistent_categories_rows]
consistent_categories_data = record[~inconsistent_categories_rows]
df['col'].unique() 可以将列中的单一值返回为一个列表。
处理方式
常见问题:
1)大小写。
2)笔误。
3)额外空格。
大小写
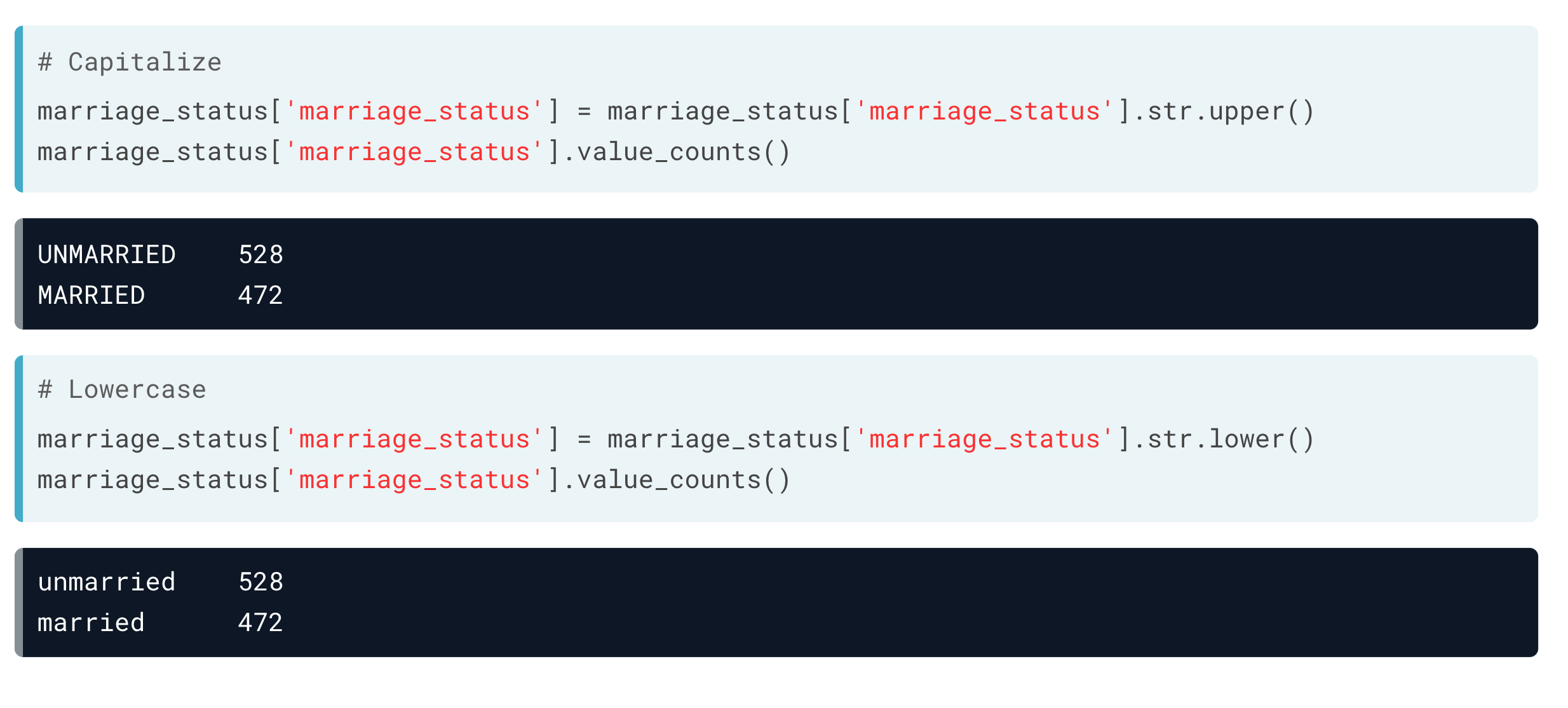
笔误
如果能找到其正确对应的类型,可以直接修改这些值。
比如使用replace函数。
空格
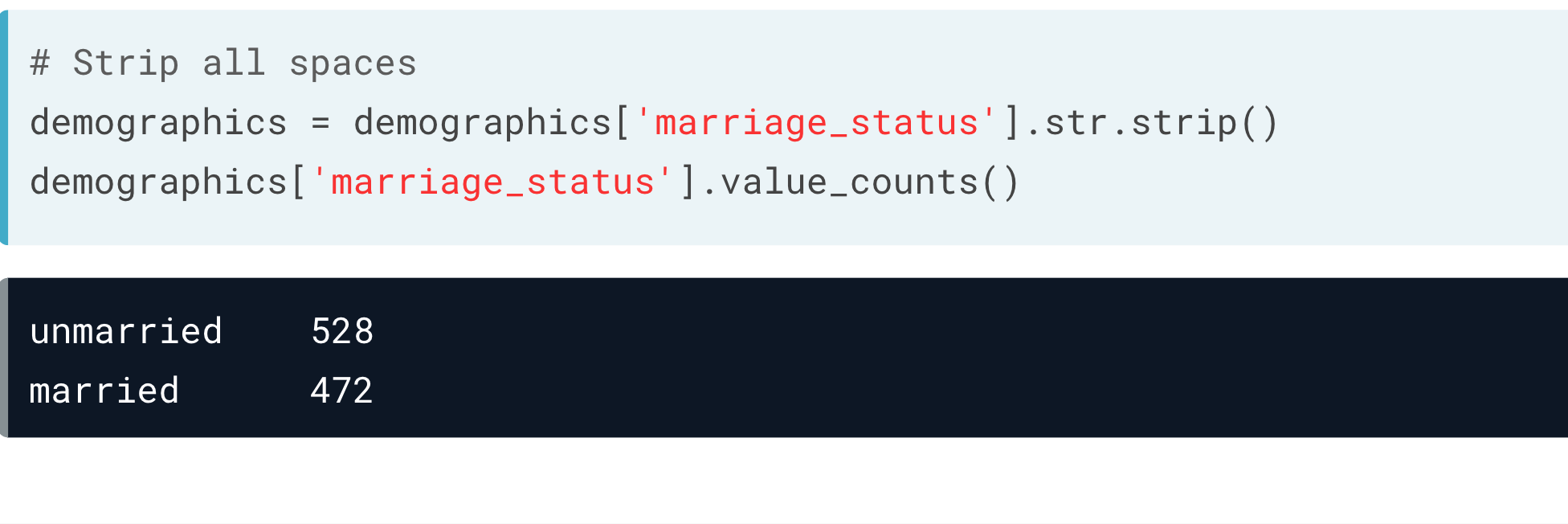
最小编辑距离算法

分类问题
qcut&&cut
可以利用qcut与cut 设定新的列,用于添加替换本来的分类数据。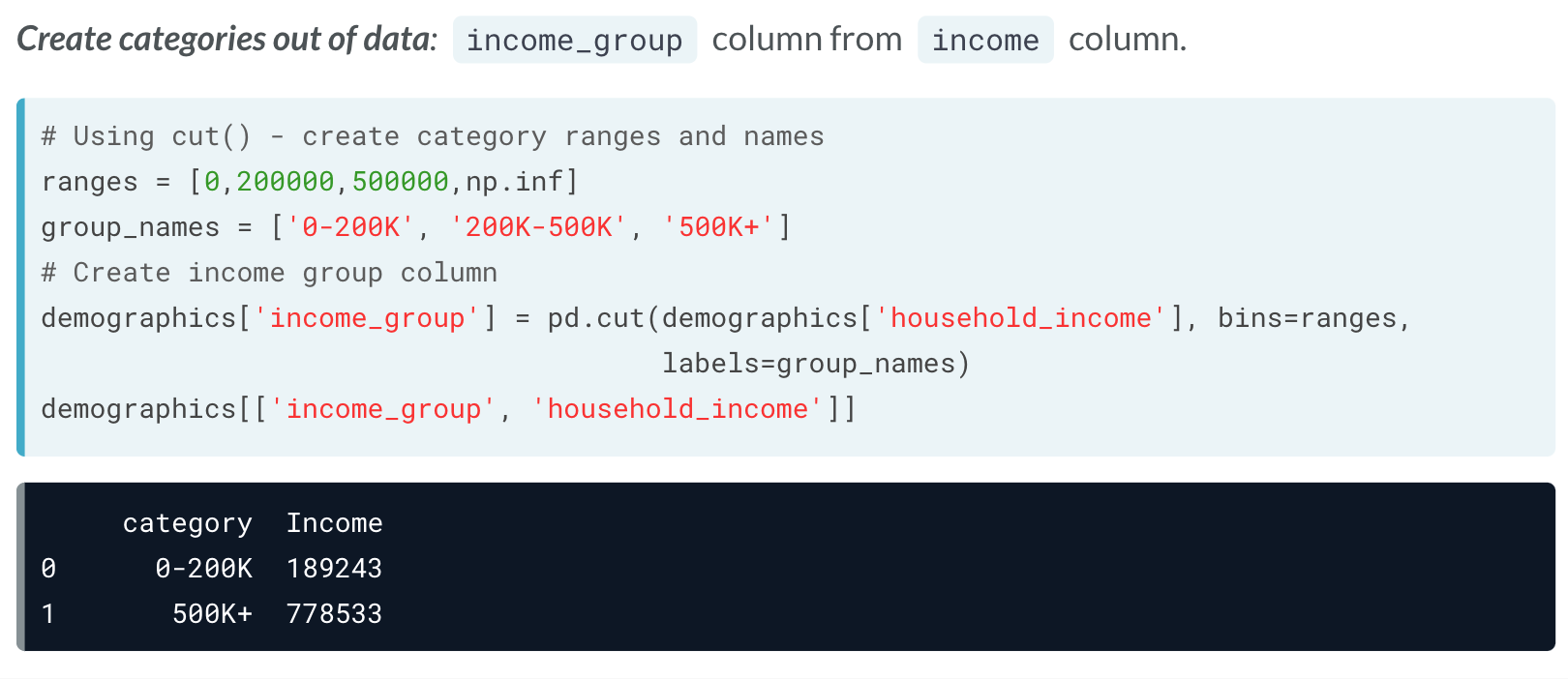
# Create ranges for categories
label_ranges = [0, 60, 180, np.inf]
label_names = ['short', 'medium', 'long']
# Create wait_type column
airlines['wait_type'] = pd.cut(airlines['wait_min'], bins = label_ranges,
labels = label_names)
replace
除此之外,还可以利用replace,使用字典,直接将原先表格中的内容替换掉。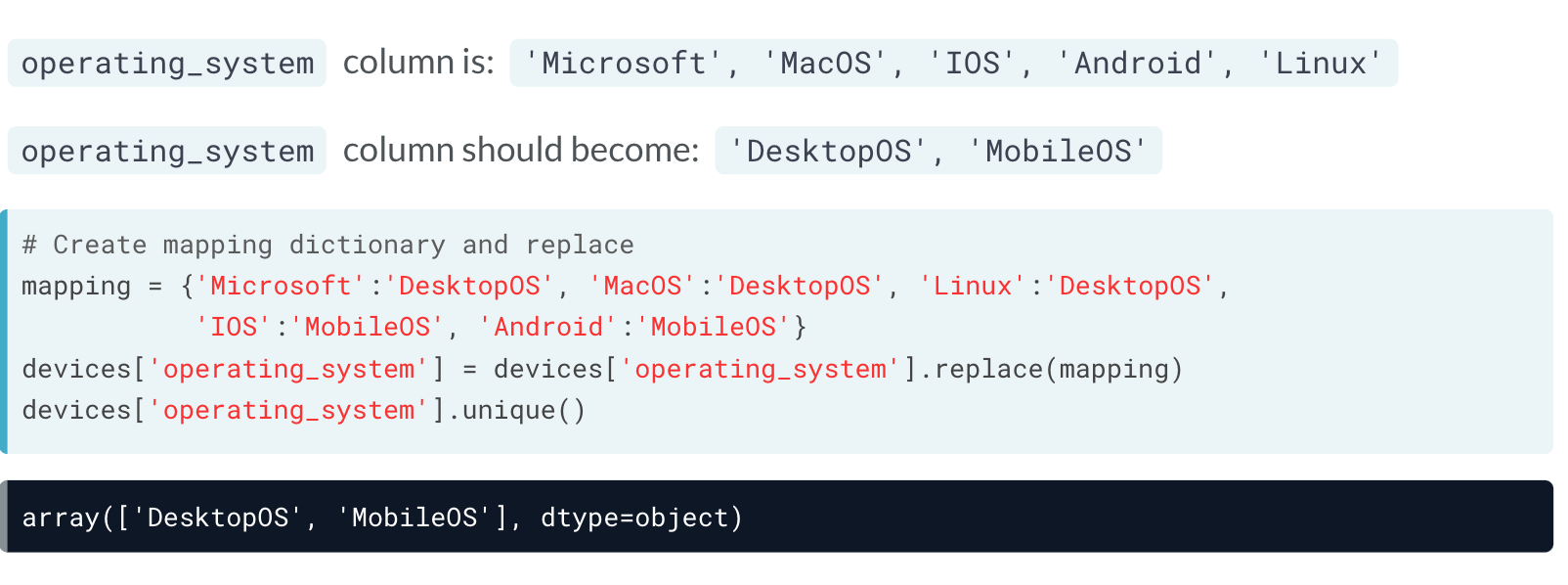
# Create mappings and replace
mappings = {'Monday':'weekday', 'Tuesday':'weekday', 'Wednesday': 'weekday',
'Thursday': 'weekday', 'Friday': 'weekday',
'Saturday': 'weekend', 'Sunday': 'weekend'}
airlines['day_week'] = airlines['day'].replace(mappings)
此外replace 还可以使用正则表达式替换,在替换字符前加 r ,具体细节参考:
https://www.yuque.com/mugpeng/pyscrapy/db8wll
格式转换问题
有的时候,对于相同表格,虽然记录的是同一信息,但可能采取了不同的格式,因而记录的结果也大相径庭。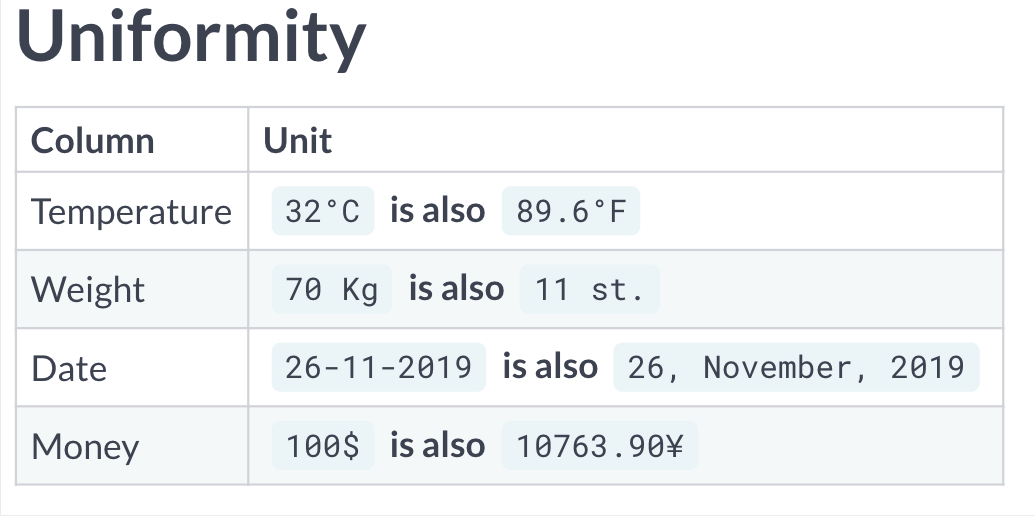
具体问题需要具体解决。
数字类型
如温度(摄氏度与华氏度、千克与磅),可以先分类再换算的方式,最终再将换算后的结果重新赋值回去。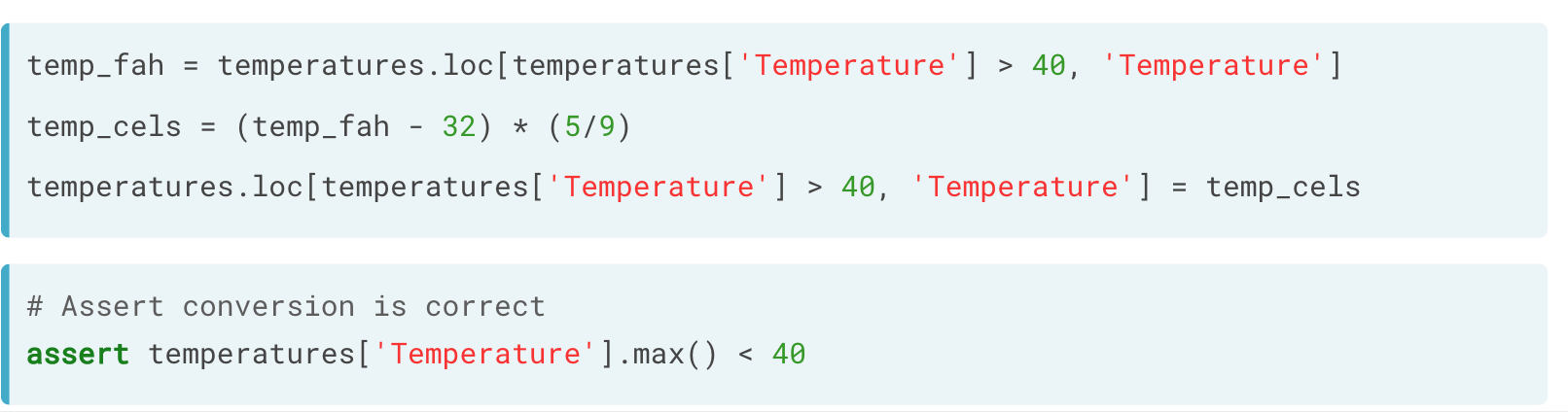
日期类型
如%d-%m-%y 格式与%c 格式。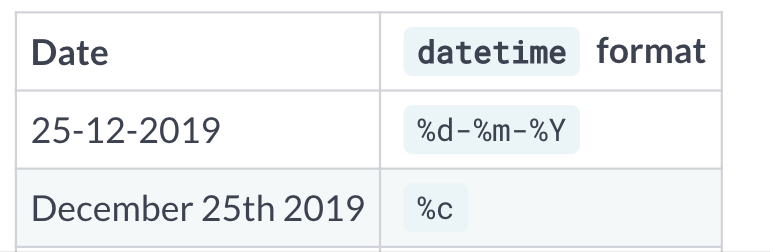
首先是将df 中的date 类型的信息转化为date 格式,即便存在超限(或不符合规范)的日期类型,也可以设定 infer_datetime_format=True 与 errors='coerce' ,使它们转化为 NaT 。
另外,通过 dt.strftime() ,也可自行调整类型。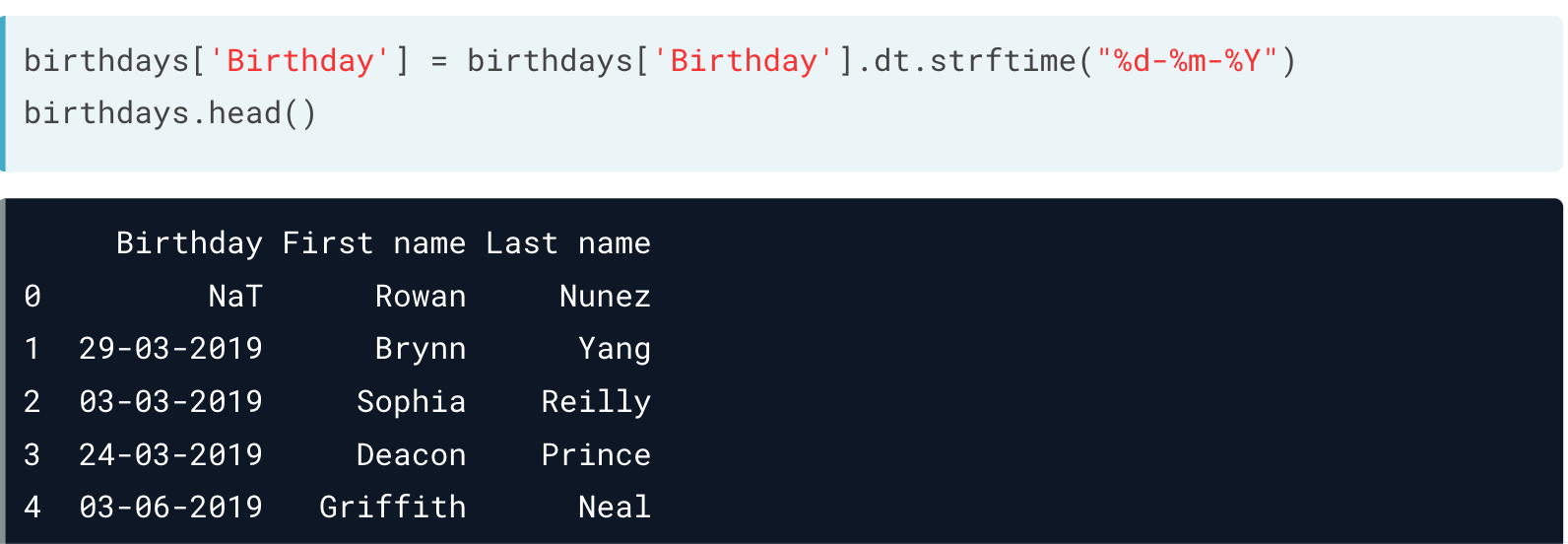
# Print the header of account_opend
print(banking['account_opened'].head())
# Convert account_opened to datetime
banking['account_opened'] = pd.to_datetime(banking['account_opened'],
# Infer datetime format
infer_datetime_format = True,
# Return missing value for error
errors = 'coerce')
# Get year of account opened
banking['acct_year'] = banking['account_opened'].dt.strftime('%Y')
# Print acct_year
print(banking['acct_year'])
缺失值问题
这一部分中的部分内容我直接复制了003.pandas数据分析中的内容。
缺失数据类型
根据缺失产生的原因,可分成以下几类。
查看缺失数据
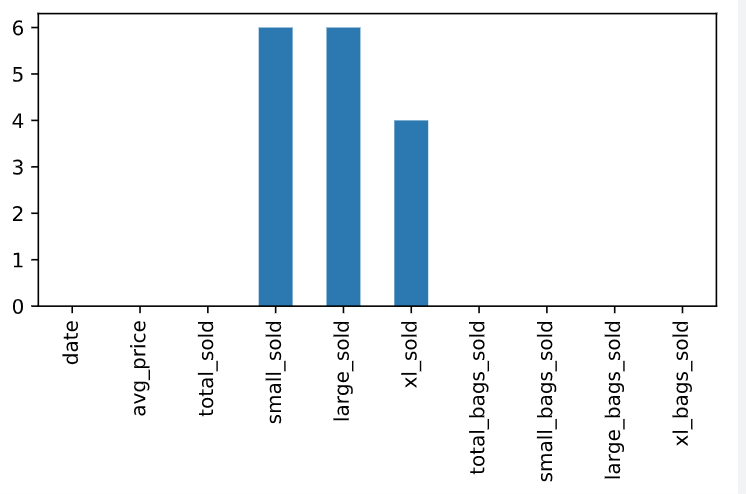
df.isna() 。将表格中的全部数据以布尔值形式返回,缺失值返回True。但对于大量数据,这样有点儿不方便。df.col.isnull() 则可以查询表格中的特定列中的缺失值。df.isna().any() ,会返回每列是否有缺失值,有缺失值返回True。df.isna().sum() ,返回每列缺失值的总数。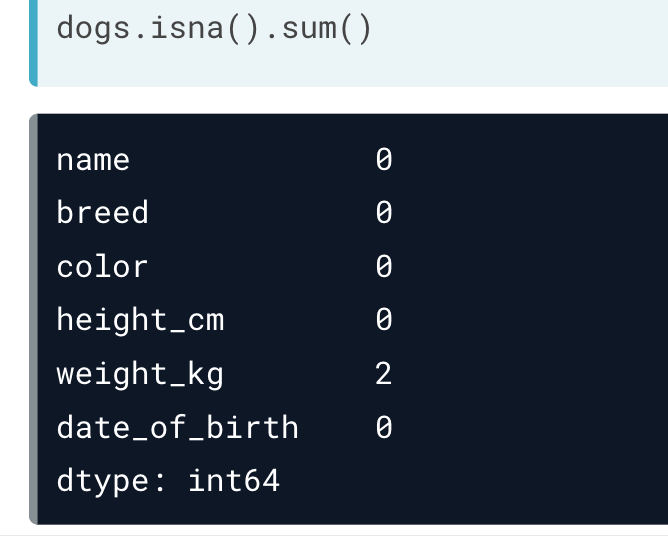
这里还可以联合条形图,图像化显示各组的缺失值信息。
# Bar plot of missing values by variable
avocados_2016.isna().sum().plot(kind = 'bar')
# Show plot
plt.show()
另外,可以直接使用用于缺失数据可视化的包 missingno 。

处理缺失数据
df.dropna() ,直接将存在丢失值的一行删去。df.fillna(0) ,将缺失值用0替代。
也可以指定一个字典,将key中的内容用value 中的内容替代。
# Drop missing values of cust_id
banking_fullid = banking.dropna(subset = ['cust_id'])
# Compute estimated acct_amount
acct_imp = banking_fullid['inv_amount'] * 5
# Impute missing acct_amount with corresponding acct_imp
banking_imputed = banking_fullid.fillna({'acct_amount':acct_imp})
# Print number of missing values
print(banking_imputed.isna().sum())
df.ffill() ,会将缺失值向上取值进行替代(最近的一个有数值的行)。
# Import pandas
import pandas as pd
# Reindex weather1 using the list year: weather2
weather2 = weather1.reindex(year)
# Print weather2
print(weather2)
# Reindex weather1 using the list year with forward-fill: weather3
weather3 = weather1.reindex(year).ffill()
# Print weather3
print(weather3)
'''
<script.py> output:
Mean TemperatureF
Month
Jan 32.133333
Feb NaN
Mar NaN
Apr 61.956044
May NaN
Jun NaN
Jul 68.934783
Aug NaN
Sep NaN
Oct 43.434783
Nov NaN
Dec NaN
Mean TemperatureF
Month
Jan 32.133333
Feb 32.133333
Mar 32.133333
Apr 61.956044
May 61.956044
Jun 61.956044
Jul 68.934783
Aug 68.934783
Sep 68.934783
Oct 43.434783
Nov 43.434783
Dec 43.434783
'''
不同表格合并资格问题
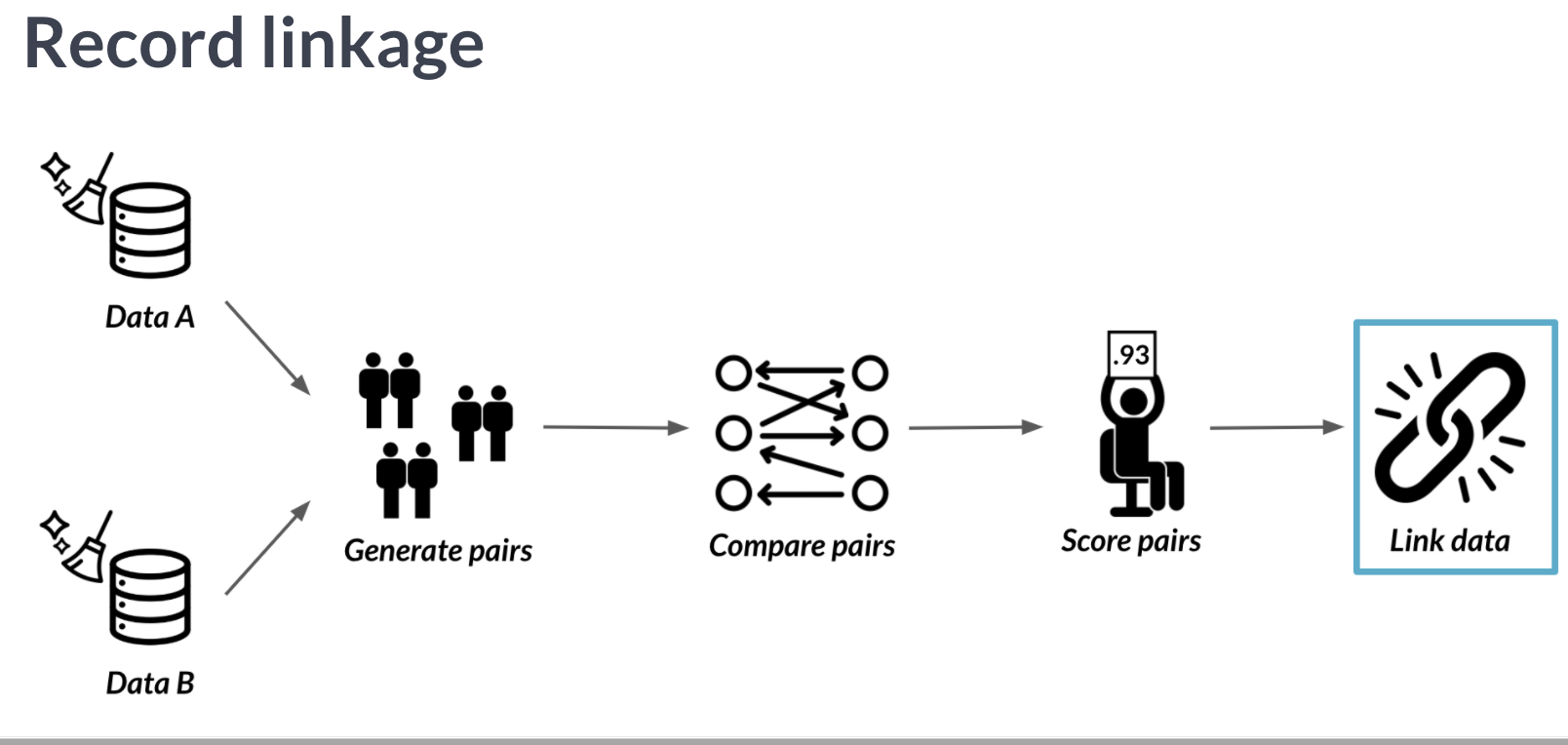
有时两个不同的表格可能记录有相同的信息,比如人口普查A(旧的)与人口普查B(新的),新旧之间虽然会有出入,但大概率会有许多重复的信息。
我们可以利用recordlinkage 包中的 成对 方式,将两表成对,以进行比较。
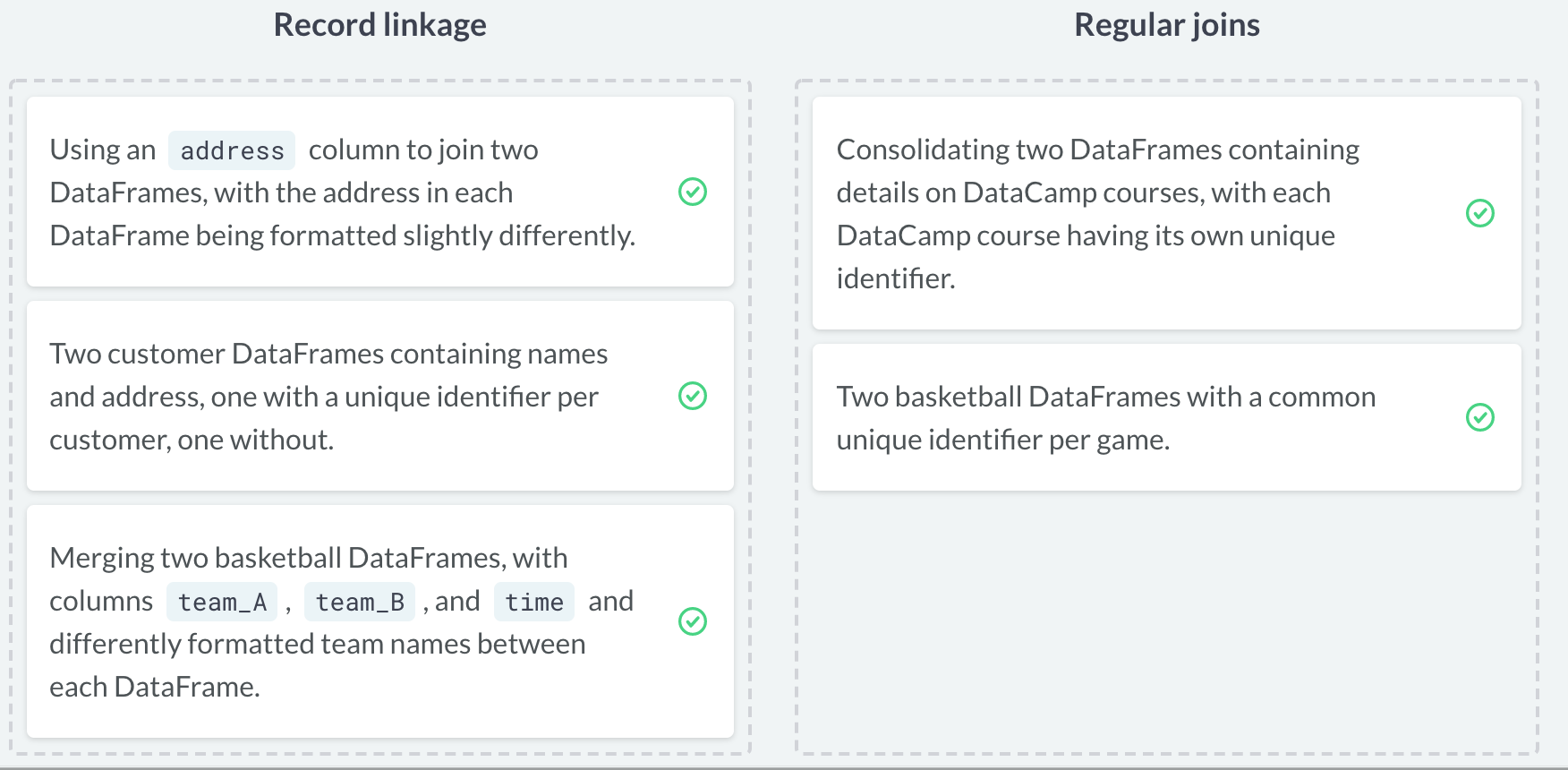
record linkage 和join 类似,但不同于join,它并不需要完全地匹配表格中地内容,只需要他们满足一定相似度即可。比如有时候不同表格中的信息其记录格式可能存在差异,而join 则会将不一致的信息视为独立的observations。
可以简单的理解为,当合并表格内容时,相同信息的记录格式完全一致就用 join ,即便存在略微差异,都需要使用 recordlinkage (从相似度比较这点来看,record linkage 似乎更为强大)。
利用相似内容建立表格联系
# Create an indexer and object and find possible pairs
indexer = recordlinkage.Index()
# Block pairing on cuisine_type
indexer.block('cuisine_type')
# Generate pairs
pairs = indexer.index(restaurants, restaurants_new)
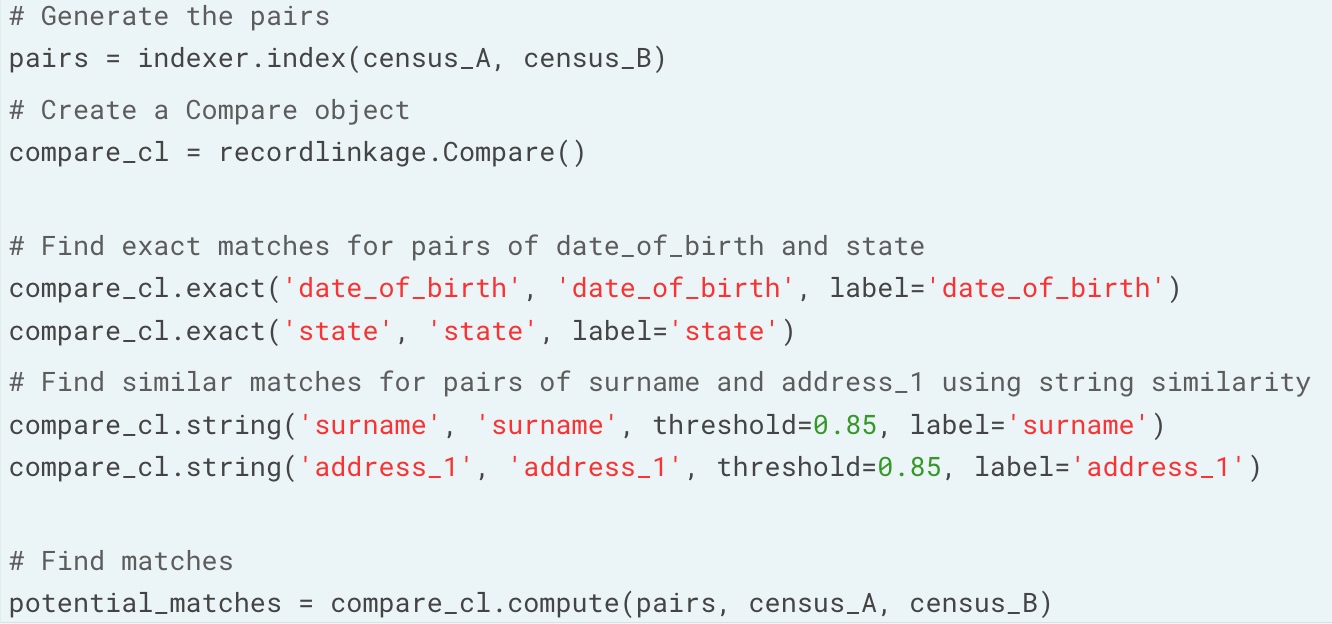
设定一个阈值,筛选出大概率匹配的信息。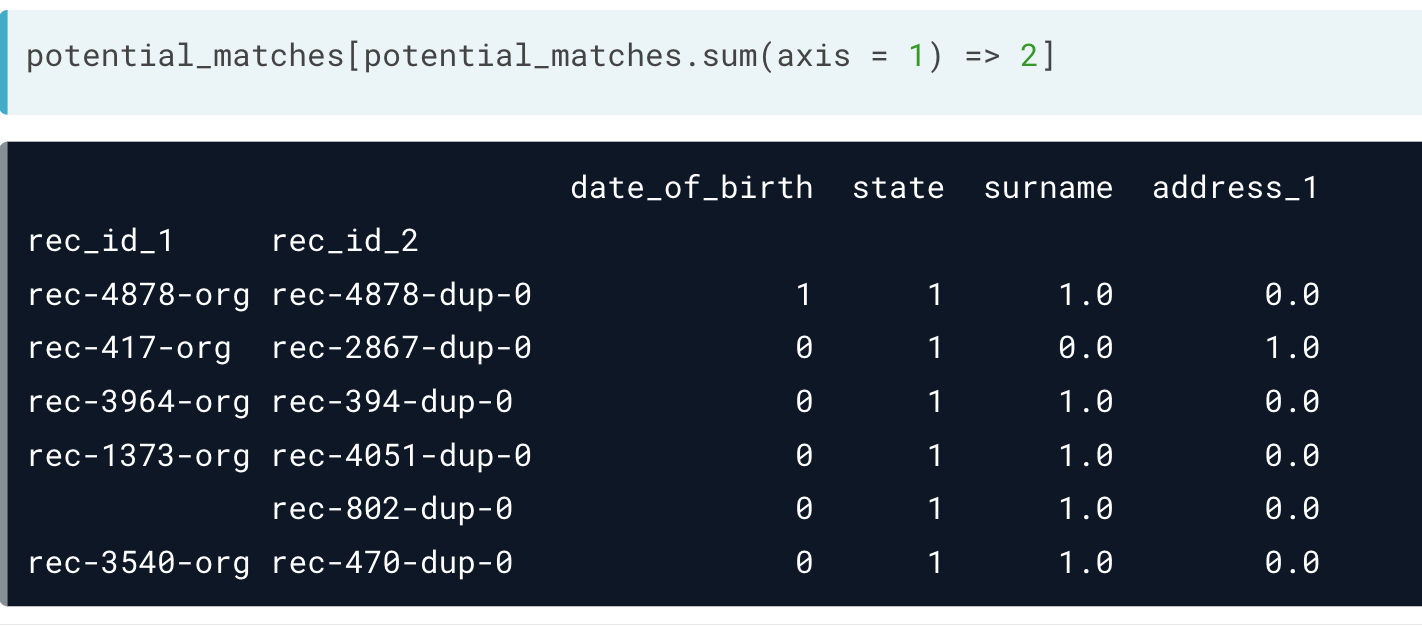
连接表格数据建立新表
首先可以获取不同表格的索引。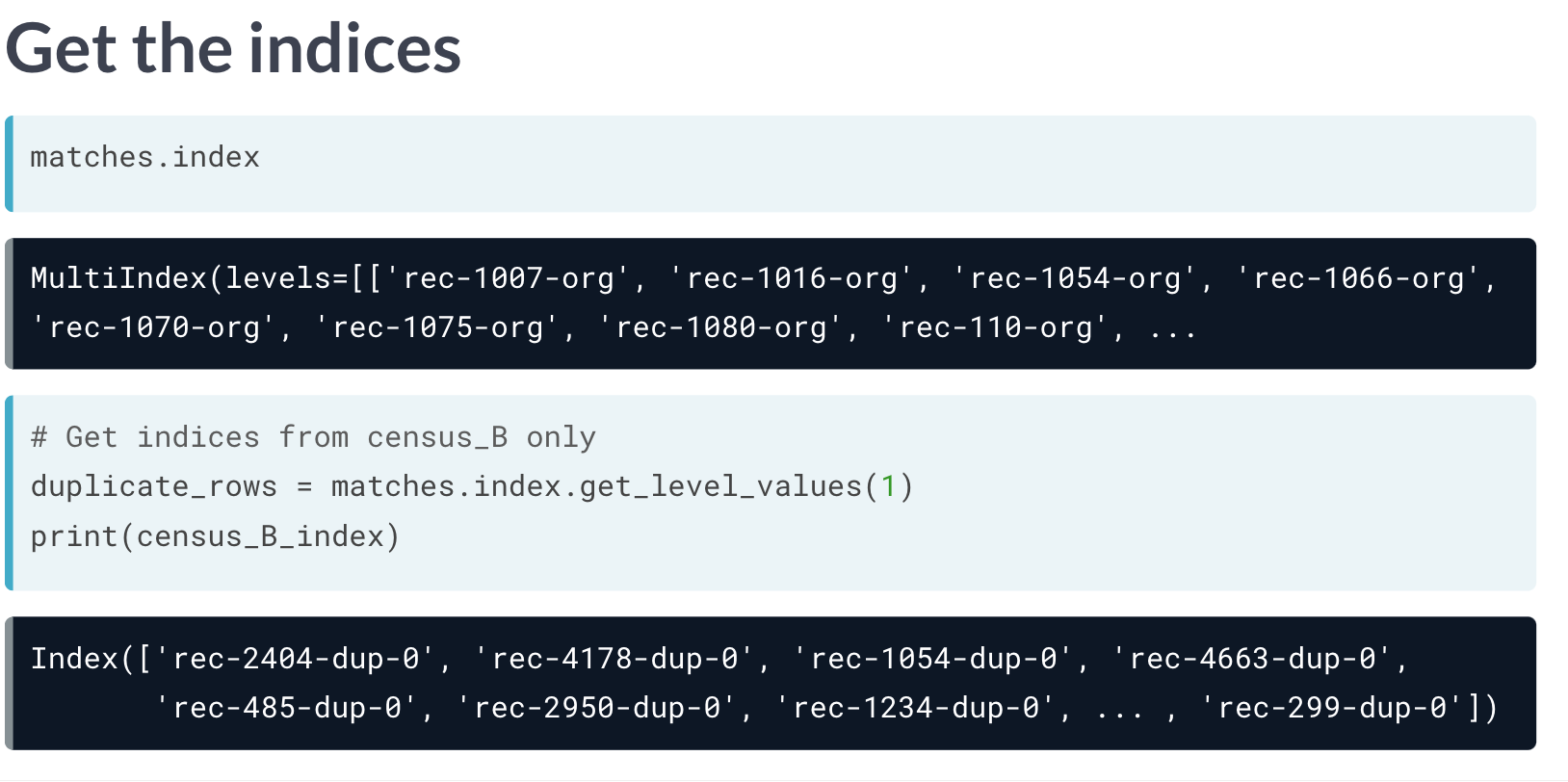
将匹配出的B表中信息作为筛选条件,反选可以获得B表中A表不存在的内容,直接通过 append 实现合并。
这里的 .get_level_values() 既可以是0,1的顺序选择index,也可以直接输入index 列名。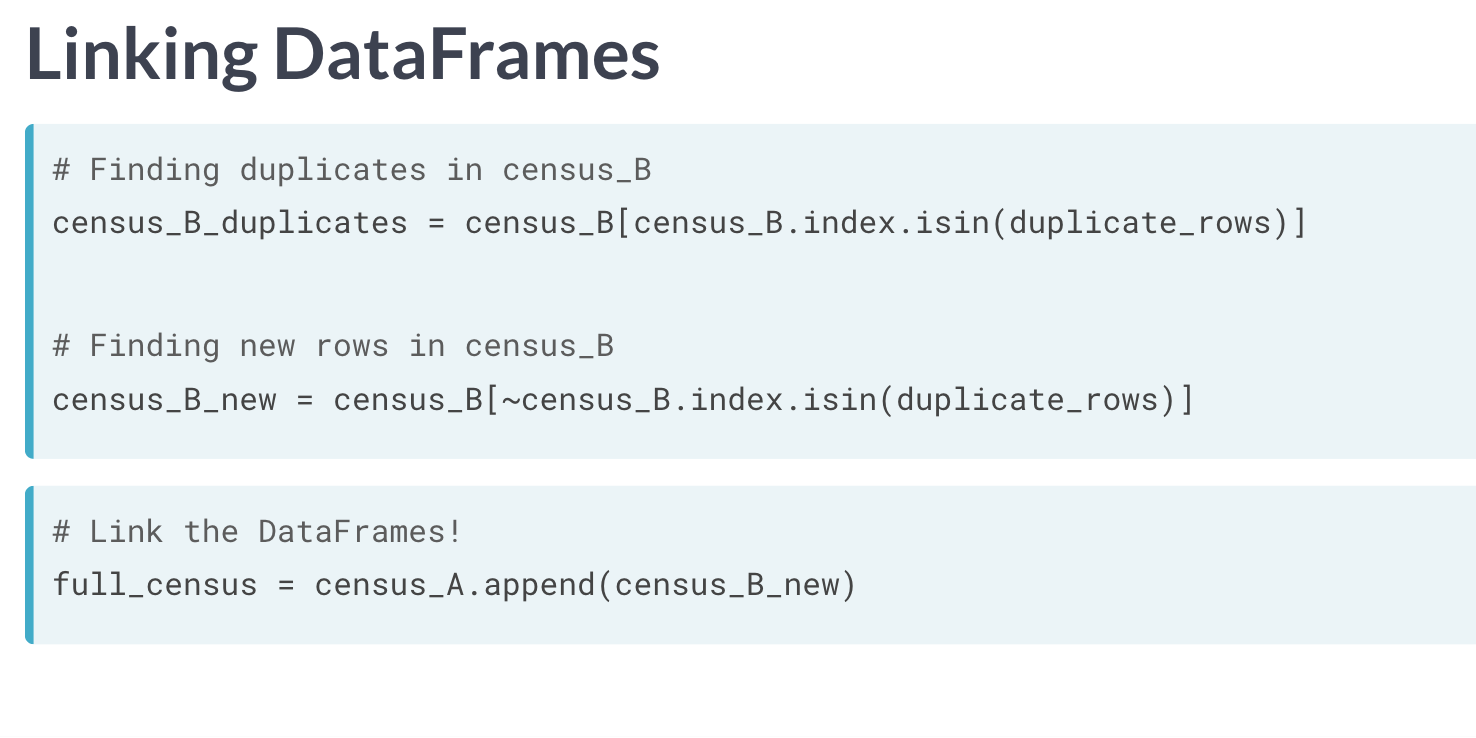
复习

验证错误的方法
交叉表格验证
通过整合表格,合并验证两个表格信息的合理。
思路也非常简单,红色方框中的内容之和,应该等于右边绿色框值。
另外一个则是相对复杂的年龄验证。
# Store today's date and find ages
today = dt.date.today()
ages_manual = today.year - banking['birth_date'].dt.year
# Find rows where age column == ages_manual
age_equ = banking['age'] == ages_manual
# Store consistent and inconsistent data
consistent_ages = banking[age_equ]
inconsistent_ages = banking[~age_equ]
# Store consistent and inconsistent data
print("Number of inconsistent ages: ", inconsistent_ages.shape[0])
assert 检验
可以使用assert 查看是否完成,True 则不返回内容。
assert airlines['full_name'].str.contains('Ms.|Mr.|Miss|Dr.').any() == False
最小编辑距离
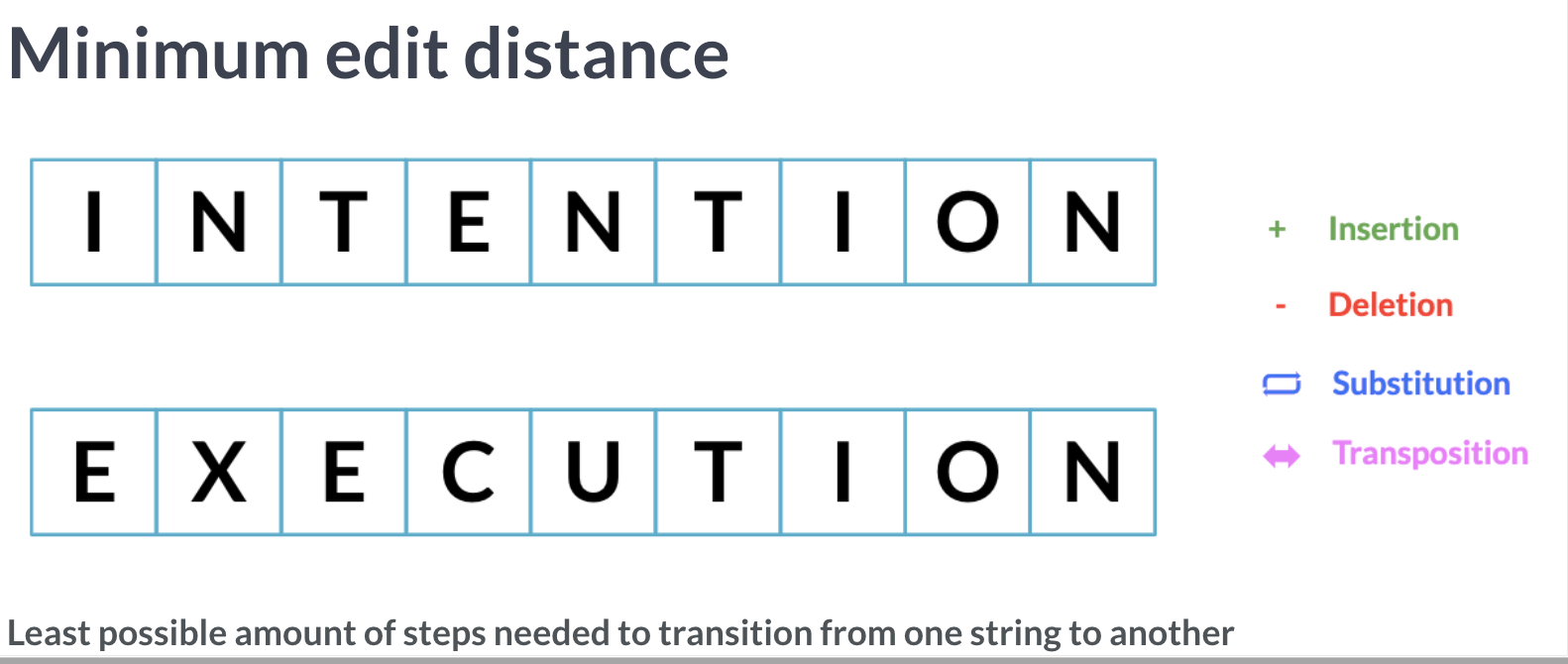
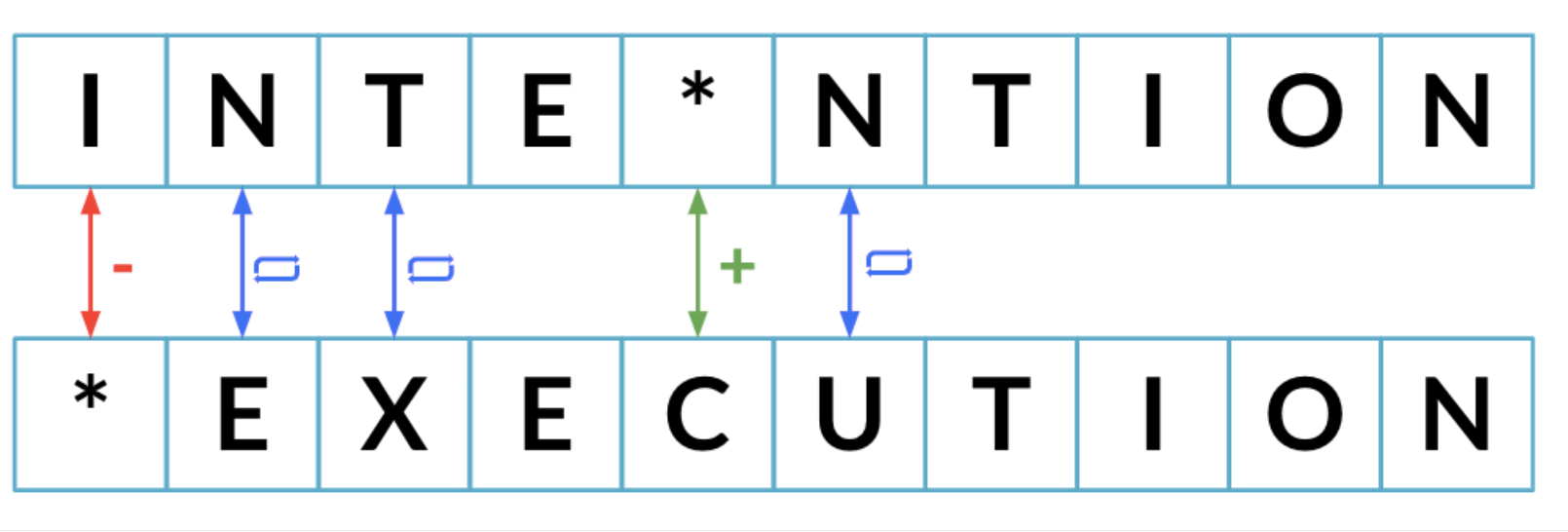

简单字符串比较

其他算法
文本的比较实际和氨基酸或核酸的序列比对并无太多差异,本质是差不多的游戏。
比如有类似的局部比对算法
多组字符串比较

迭代修正重复值(资格问题)
categories = ['asian', 'american', 'italian']
# For each correct cuisine_type in categories
for cuisine in categories:
# Find matches in cuisine_type of restaurants
matches = process.extract(cuisine, restaurants['cuisine_type'],
limit = restaurants.shape[0])
# For each possible_match with similarity score >= 80
for possible_match in matches:
# [1] refers similarity, [0] indicates matched position
if possible_match[1] >= 80:
# Find matching cuisine type
matching_cuisine = restaurants['cuisine_type'] == possible_match[0]
restaurants.loc[matching_cuisine, 'cuisine_type'] = cuisine
# Print unique values to confirm mapping
print(restaurants['cuisine_type'].unique())

若有收获,就点个赞吧
0 人点赞
