

flat files
也叫做平面文件。一般指.txt,.csv 这些由文本构成的文件,一般具有以下两个特性:1)通过指定的分隔符将文件信息分隔开;2)具有头部信息,一般作为文本信息的注释(理解为pandas 中framedata 里的索引就好了。)
python 喜欢flat。这点可以从 Zen of Python 窥得一二。
In [1]: import thisThe Zen of Python, by Tim PetersBeautiful is better than ugly.Explicit is better than implicit.Simple is better than complex.Complex is better than complicated.Flat is better than nested.Sparse is better than dense.Readability counts.Special cases aren't special enough to break the rules.Although practicality beats purity.Errors should never pass silently.Unless explicitly silenced.In the face of ambiguity, refuse the temptation to guess.There should be one-- and preferably only one --obvious way to do it.Although that way may not be obvious at first unless you're Dutch.Now is better than never.Although never is often better than *right* now.If the implementation is hard to explain, it's a bad idea.If the implementation is easy to explain, it may be a good idea.Namespaces are one honking great idea -- let's do more of those!
读取文件

需要注意每次获得文件并读取完毕后,需要关闭文件。
另外,如果想要检查文件是否关闭,通过指令 file.closed 可以返回一个布尔值查看。
除了上部分的 file.read() 外,file.readline 提供了只读取文本
使用with 读取
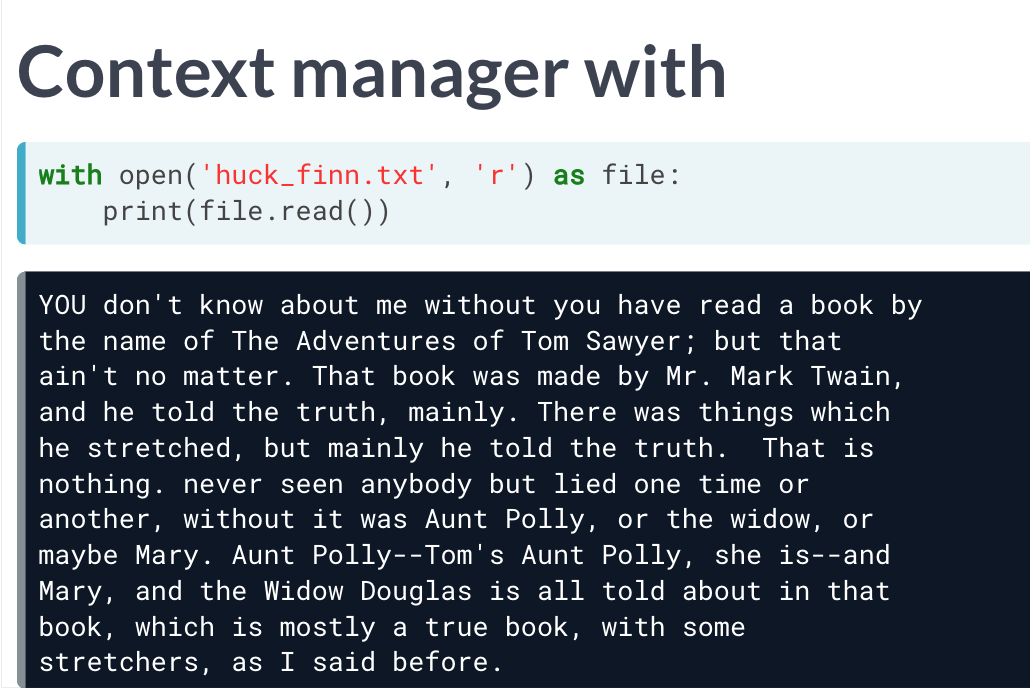
通过with 进行文件读取的好处是,文件的打开只在with 内部有效,因此也无需担心代码结束后忘记关闭文件的问题。
file.readline() #可以跳过列名
写入文件
有时候我们不仅仅需要读取文件,还需要对文件中的内容进行修改。
使用NumPy 导入文件
读取文件
读取单一数据类型文件
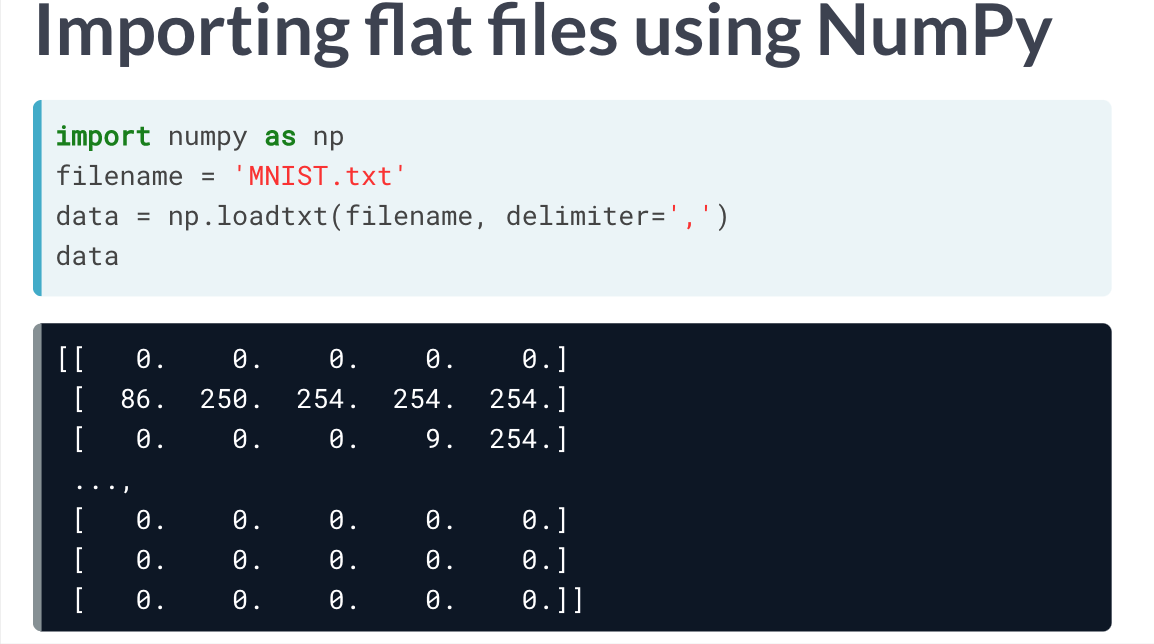
其中还有一些重要参数:
1) skip[rows|cols]=[] 用于跳过读取文件中的列或行。
2) use[rows|cols]=[x, y] 选择x到y 行或列的文件数据。
3) dtype 用于设定导入的文件类型,比如可以设定为str,将所有数据以string 形式导入。
4) names 告知读取文件是否有头信息,有则取True。
读取混合类型数据文件
通常来说如果数据包含了多种混合类型的信息,loadtxt 可能会难以胜任。这时候就需要 genfromtxt() 的上场了。
ps: np.recfromcsv() 也和它差不多,只不过dtype 默认为None 罢了。
当然读取混合类型数据文件最好用的还是pandas,这个可以参见005. 使用pandas读取及写入相关文件(.csv等等)。
其他类型文件
使用pandas 导入csv 文件
前言
pandas 可以将很多类型的数据进行导入及生成。
可以毫不夸张的说,pandas 的出现,就是为了让使用python 的人们可以不用学R 就可以胜任数据处理的工作。

CSV
读取csv
read_csv('filepath')
其中有几个参数:index_col 指定某一列作为index。parse 可用于解释某些特殊格式的信息,如 parse_dates = [] 可以用来将日期格式类型文本内容读取为 日期 类型数据。header 设定文件有无头部信息,无则赋值为None。n[rows|cols] 用于取指定行或列。na_values = [] 用于赋以列表类型,而表格中存在的列表中的元素会被pandas 识别为NaN 进行处理。
写入csv
dataframe_name.to_csv('filepath') ,可以将表格以csv 形式保存。
复制其他表格
new_file = old_file.copy() ,可以直接复制。
读取文件的高级操作
利用循环

# Import pandas
import pandas as pd
# Create the list of file names: filenames
filenames = ['Gold.csv', 'Silver.csv', 'Bronze.csv']
# Create the list of three DataFrames: dataframes
dataframes = []
for filename in filenames:
dataframes.append(pd.read_csv(filename))
# Print top 5 rows of 1st DataFrame in dataframes
print(dataframes[0].head())
glob 包

glob 将会寻找当前或指定目录下的全部符合其语法要求的文件,形成一个可迭代对象。
使用pandas导入excel 文件

excel类型的变量具有以下几个属性及功能:
1) .sheet_names 可以获得Excel 中各表格名。
2) .parse 可以将字符串或数字解析为excel 中的表单。
# Import pandas
import pandas as pd
# Assign spreadsheet filename: file
file = 'battledeath.xlsx'
# Load spreadsheet: xls
xls = pd.ExcelFile(file)
# Print sheet names
print(xls.sheet_names)
使用pandas 导入SAS/Stata 文件
SAS

# Import sas7bdat package
from sas7bdat import SAS7BDAT
# Save file to a DataFrame: df_sas
with SAS7BDAT('sales.sas7bdat') as file:
df_sas = file.to_data_frame()
# Print head of DataFrame
print(df_sas.head())
sas 文件使用特殊的context manager, 因此常规的open 命令没有办法处理。
Stata

导入HDF5 文件

和SAS 文件一样,HDF5 文件也需要特殊的打开方式(使用h5py包)。
HDF5 是一个具有层级结构的数据文件。
每一层都是字典,键对应值,值也是字典,一直展开,直到底层。
首先是三层:
以meta 为例,其中还有: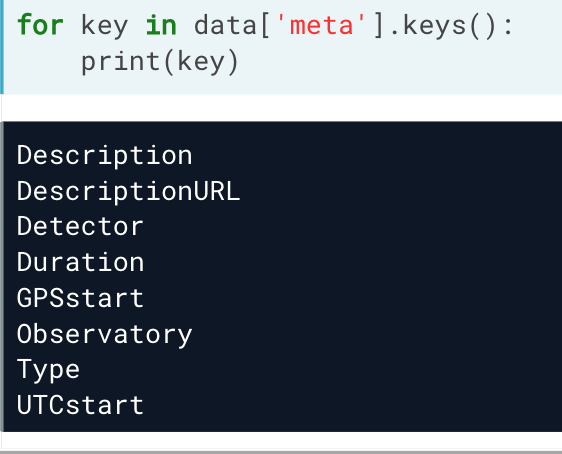
# Get the HDF5 group: group
group = data['strain']
# Check out keys of group
for key in group.keys():
print(key)
# Set variable equal to time series data: strain
strain = data['strain']['Strain'].value
# Set number of time points to sample: num_samples
num_samples = 10000
# Set time vector
time = np.arange(0, 1, 1/num_samples)
导入pickled文件

pickled 文件加载到python,会转变为字典类型。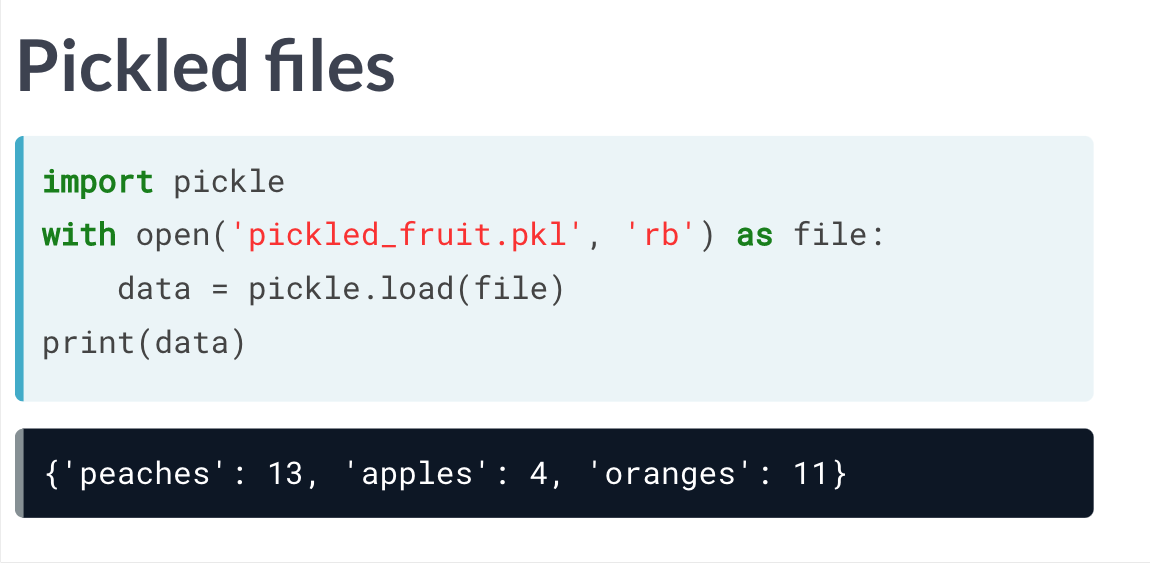
# Import pickle package
import pickle
# Open pickle file and load data
with open('data.pkl', 'rb') as file:
d = pickle.load(file)
# Print data
print(d)
'''
<script.py> output:
{'June': '69.4', 'Aug': '85', 'Airline': '8', 'Mar': '84.4'}
<class 'dict'>
'''
导入MATLAB 文件

matlab 是许多领域所喜爱使用的建模软件,也因此,很多数据都以.mat 保存。
关系型数据库
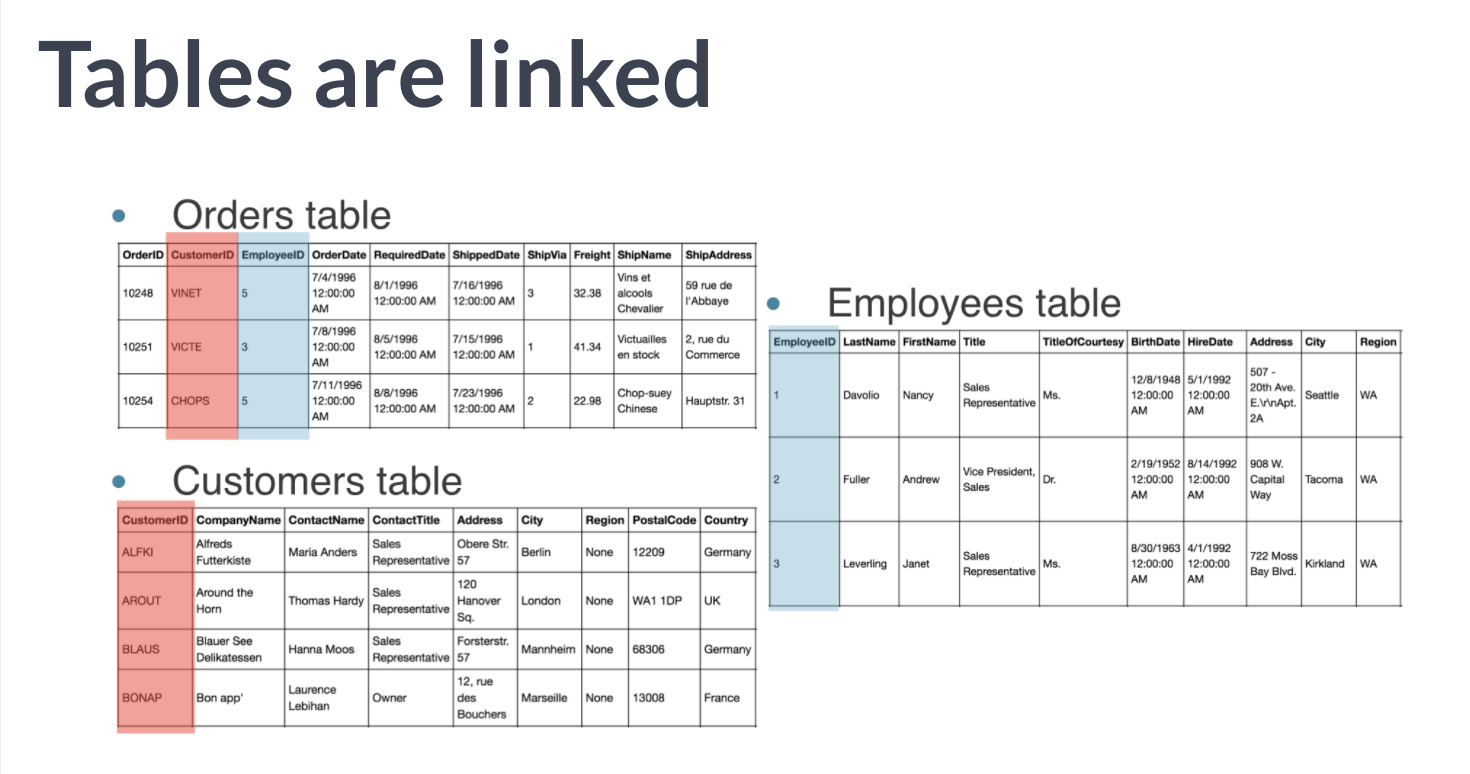
关系型数据库12律(实际有13条,第一条是0,hhh)
使用python 创建SQLite database
# Import necessary module
from sqlalchemy import create_engine
# Create engine: engine
engine = create_engine('sqlite:///Chinook.sqlite')
python 进行sql 工作流

将sql表格转为pandas 表格
# Import packages
from sqlalchemy import create_engine
import pandas as pd
# Create engine: engine
engine = create_engine('sqlite:///Chinook.sqlite')
# Open engine connection
con = engine.connect()
# Perform query: rs
rs = con.execute("SELECT * FROM Album")
# Save results of the query to DataFrame: df
df = pd.DataFrame(rs.fetchall())
# Close connection
con.close()
# Print head of DataFrame df
print(df.head())
另外,如果更改 fetchall() 为 fetchmany() ,还可以设定参数 size = ,限定获取的记录数目(也就是行数)。
在execute 中,可以使用SQL 的语句对表格内容进行选择。
pandas 暴力读取sql表格
按照sql 一般的操作,在为sql database 建立engine 后,还需要先建立联系,接着执行sql 命令选择表格, 再将选择的表格转换为dataframe,非常麻烦。
而pandas 其实直接一部就能完成,和读取csv 等等文件一样。df = pd.read_sql_query("SELECT * FROM Album", engine)
# Execute query and store records in DataFrame: df
df = pd.read_sql_query(
"SELECT * FROM PlaylistTrack INNER JOIN Track ON PlaylistTrack.TrackId = Track.TrackId WHERE Milliseconds < 250000",
engine
)
# Print head of DataFrame
print(df.head())
SQL 基础
为了区分SQL 语句和其他语句,并且SQL 自身语句无视大小写的,所以SQL 的所有命令均为大写。
FROM,选择某个表格。
SELECT,选择表格中的某列或几列,*表示全部。
WHERE,限定条件,可以对行进行筛选。
ORDER BY,选定为某行,按该行以一定条件排序。
INNER JOIN XXX on a = b,内部连接表格XXX,且行 a、b 相连。

若有收获,就点个赞吧
0 人点赞
