笔者尝试过好几个软件,有些效果不是很好,还有的不能渲染动态页面(通过 js 渲染出来的内容,如 VUE 实现的单页应用),后来发现一个开源的 Node js 的库 puppeteer,官方介绍就是 Headless Chrome Node.js API,也就是通过真实的浏览器渲染出来网页,再进行一些操作来实现
:::tips
注意:这个 PDF 生成不是截图,而且是获取 html 内容之类的,所以在有图片的时候,生成的 PDF 文件可能会很大。
60 页 PDF 里面有 100+ 张图片,没有图片的时候 10M 不到,有图片的时候 600M+
:::
先在本地安装该依赖库
# 全局安装,笔者这里使用的是 node 14+npm install -g puppeteer
PDF 生成
编写一个 JS 文件,如 test.js ,内容如下
const puppeteer = require('puppeteer');(async function () {const browser = await puppeteer.launch({args: ['--no-sandbox', '--disable-setuid-sandbox'],})const page = await browser.newPage()// https://bookjs.zhouwuxue.com/eazy-1.html// http://localhost:81/pdf?area=&product=&id=1047await page.goto(' https://bookjs.zhouwuxue.com/eazy-1.html', {waitUntil: 'networkidle2' // 考虑在至少 500ms 内没有超过 2 个网络连接时完成导航})// 等待页面中出现 main class 的元素// 和上面完成导航配合使用,双保险await page.waitForSelector('.main', {timeout: 30000 // 默认等待 30 秒,如果该元素还没有出现则抛出异常信息}).then(() => console.log('内容已经出现'))await page.pdf({path: 'text.pdf', // 生成的 pdf 路径,写相对路径,就在你运行命令的目录下生成format: 'A4', // 大小为 A4landscape: true // 横向})await browser.close()})()// node test.js
以上文件内容的 page 等 API 可以查看 官方文档 了解是什么含义
在该 js 文件的同级目录下安装 puppeteer
# puppeteer@10.0.0 node14+npm install puppeteer
然后就可以运行命令对指定网页生成 PDF 了
node test.js
这里说一下注意事项:
你需要把你打印的内容排版成 PDF 的高宽度。关于如何精准分页(PDF 打印预览中内容不被隔断,需要 HTML 排版来控制),可以参考这个页面 https://bookjs.zhouwuxue.com/eazy-1.html (此示例是该文章的例子,它使用的是一个前端库来实现的),该页面中的重要属性应该是网页的宽高是下面这个代码(通过前端确定到下面代码是核心,至于有没有其他的辅助来控制到 A4 的宽高就不清楚了)
width: 297mm;height: 209mm;
只要使用浏览器中的打印预览是正常的,那么 puppeteer 导出的 pdf 就是正常的,浏览器中的打印预览参数如下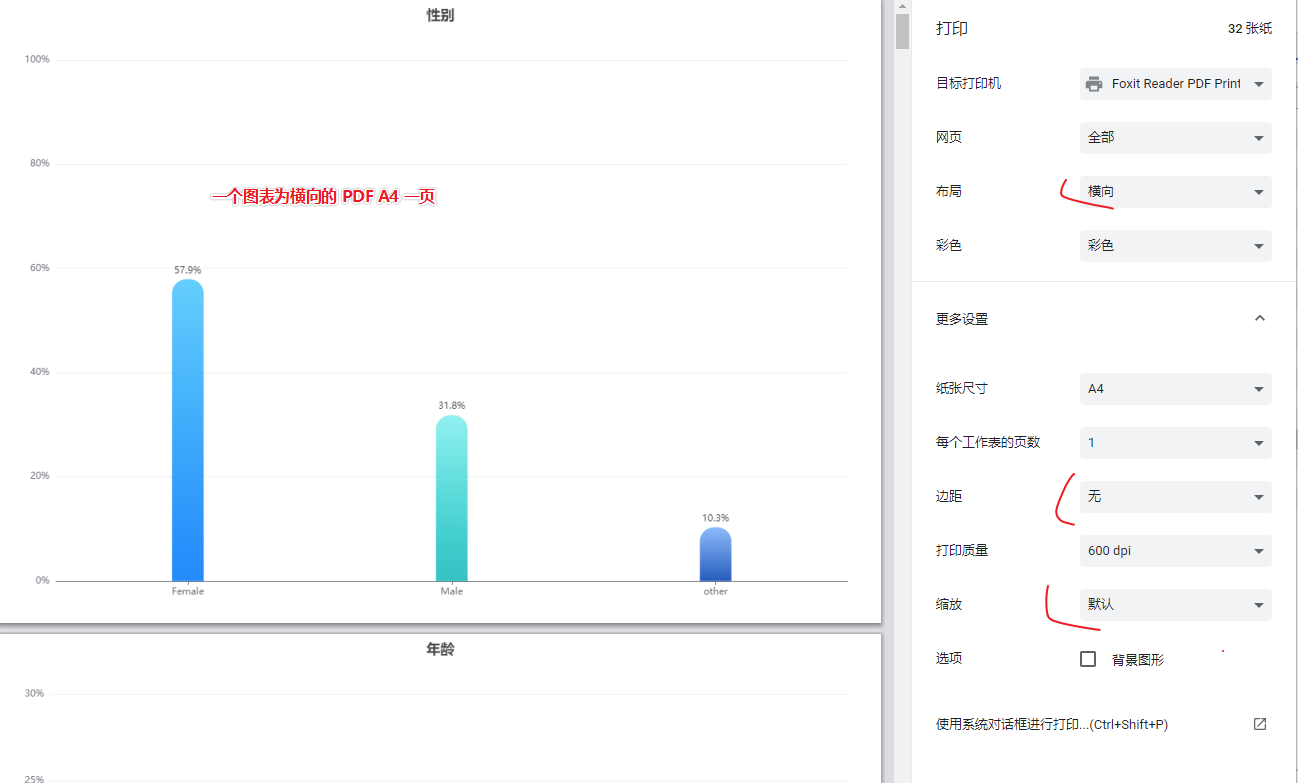
图片生成/截图
将网页截图是使用 page.screenshot API,至于如何自动滚动截图整个网页,有时间再补充
JAVA 调用 node js 文件生成 PDF
调用 js 代码如下,比较简单,原理是:使用 Process 类,去执行命令
import cn.hutool.core.lang.Console;public static void main(String[] args) throws IOException, InterruptedException {// 需要注意的是:url 在命令行中有参数信息的 url 不加双引号或则单引号会报错,// 但是在 java windows 中,加单引号,会永远阻塞// 但是在 java ubuntu 中,加双引号会永远阻塞// 最后得出结论:在命令行中自己加单引号或则双引号,在 java 中不加单双引号String command = "node D:/software/htmlToPdf.js \"http://192.168.1.107:81/pdf?id=1047&type=1\" D:/temp/22e3aea218e14ef29f112c0ef37f64db-20210604161356.pdf";// 使用 java.lang.Process 来执行命令final Process process = Runtime.getRuntime().exec(command);final int result = process.waitFor();Console.log("执行命令返回值 result = {}", result);Console.log("执行命令结果", result == 0 ? "成功" : "失败");// 如果命令执行成功,则会输出控制台中输出的信息final String successMsg = IoUtil.readUtf8(process.getInputStream());Console.log("执行命令标准输入 {}", successMsg);// 如果命令执行失败,则会有错误信息,或则直接抛出了异常final String errorMsg = IoUtil.readUtf8(process.getErrorStream());Console.log("执行命令错误输出 {}", errorMsg);}
上述判断是否成功,建议不要依赖 result 的返回值,要依赖 errorMsg 的值,如果有,那么一定是出错了
由于要实现上述可以给 js 传递参数,如:要生成的网页 URL,生成的 PDF 路径,对 js 进行改造,可以接受参数:htmlToPdf.js
const puppeteer = require('puppeteer');(async function () {// 打印从命令行传递的参数if (process.argv.length < 4) {throw new Error("参数异常,使用方式为 node htmlToPdf.js url pdfPath")}const url = process.argv[2]const pdfPath = process.argv[3]console.log(process.argv)console.log(url,pdfPath)const browser = await puppeteer.launch({args: ['--no-sandbox', '--disable-setuid-sandbox'],})const page = await browser.newPage()await page.goto(url, {// 这里的超时,是导航的超时时间,如果超过这个时间还没导航完成,这会抛出异常//timeout: 90000,// 在遇到有懒加载图片的时候,记得需要将懒加载去掉,因为暂时无法发现如何使用这个解决懒加载图片的问题// 导航完成是靠下面的参数判定的,也就是说在 500ms 内如果没有指定个数链接活动时,这说明导航已经完成了//waitUntil: 'networkidle0'waitUntil: 'networkidle2' // 考虑在至少 500ms 内没有超过 2 个网络连接时完成导航})await page.waitForSelector('.main', {timeout: 30000 // 默认等待 30 秒}).then(() => console.log('内容已经出现'))await page.pdf({path: pdfPath,format: 'A4',landscape: true})await browser.close()})()
需要说明的是以下几点:
- 当前系统中必须安装 node
- puppeteer 不是指令库,只是一个 nodejs 的库,所以需要安装 htmlToPdf.js 同级目录下,执行的时候才不会报模块找不到的错误
基于以上两点这里将 htmlToPdf.js 当成一个 node 项目来实现,项目目录如下: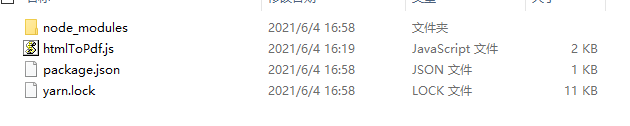
- htmlToPdf.js:上面代码实现的处理代码
- node_modules:安装的依赖包
- package.json:node 项目文件,可以通过
npm init命令生成 - yarn.lock:依赖版本锁文件
- 如果使用 npm:直接
npm install puppeteer - 也可以使用 yarn 来管理依赖包:
yarn add puppeteer,就会下载依赖并生成 yarn.lock 文件了
- 如果使用 npm:直接
有了上述的项目结构,就可以直接在 package.json 同级目录下执行 _yarn install 或则 npm install_ 一键安装好依赖了
进阶-将 nodejs 项目打包成可执行文件
上面使用 java 调用 nodejs 文件,需要先准备一系列的环境,这个当你在线上部署的时候非常的麻烦,那么这里就有一种方式将这个项目打包成可执行文件,到时候只需要调用这个可执行文件即可
在这里使用 pkg 对 nodejs 项目打包
第一步:全局安装 pkg
npm install -g pkg
全局安装之后,方便调用 pkg
第二步:编写 pkg 配置文件
这个配置文件是写在 package.json 文件里面的,默认生成的 package.json 文件内容如下
{"name": "htmltopdf","version": "1.0.0","description": "","main": "htmlToPdf.js","scripts": {"test": "echo \"Error: no test specified\" && exit 1"},"author": "","license": "ISC","dependencies": {"puppeteer": "^10.0.0"}}
增加 pkg 的配置文件
{"name": "htmltopdf","version": "1.0.0","description": "","main": "htmlToPdf.js","scripts": {"test": "echo \"Error: no test specified\" && exit 1"},"author": "","license": "ISC","dependencies": {"puppeteer": "^10.0.0"},"bin": "htmlToPdf.js","pkg": {"assets": ["node_modules/" // 这个不要,因为要了也没有用,pkg 会自动分析依赖文件,但是应该就不能控制依赖的版本了,具体如何实现就不知道了],"targets": ["node14-win"]}}
- bin:就是入口文件,执行打包好的可执行文件时,它会调用这个文件,在这里就是我们写的 htmlToPdf.js
- pkg.assets:包含的资源文件,这里写了一个 node_modules/ 目录,因为运行的话是需要该依赖的,所以打包进来
- pkg.targets:打包成可执行文件的选项,这里写了 node14-win ,也就是包含 node14 运行环境的 window 的 exe 可执行文件,这里可选的选项有 linux、mac 等,但是 node14 这个应该是当前运行 pkg 命令时的 node 版本有关,可以通过
pkg --help查阅
:::tips 这里需要注意的是:由于系统不同,下载的依赖可能也是不同的,比如你在 win 系统上下载 puppeteer ,会自动下载 win 系统的 .local-chromium 程序,所以笔者觉得这个打包要在不同的系统上打包不同的可执行程序才能行得通 :::
开始打包
打包只要执行如下命令即可
pkg .
运行完成之后就会生成 htmltopdf.exe 可执行文件,我们可以把该文件当成指令程序来运行,如
./htmltopdf.exe "http://www.baidu.com" test.pdf
这样一来,我们只要将此可执行程序随着我们的 JAVA 程序一同部署,就可以了
打包错误解决
在执行打包的时候会有如下警告,但是还会生成可执行程序,就是当你运行的时候会直接报错,如下所示
$ pkg .> pkg@5.2.1> Warning Cannot include directory %1 into executable.The directory must be distributed with executable as %2.%1: node_modules\puppeteer\.local-chromium%2: path-to-executable/puppeteer> Warning Cannot include directory %1 into executable.The directory must be distributed with executable as %2.%1: node_modules\puppeteer\.local-chromium%2: path-to-executable/puppeteer
在 pkg 的 issues 中找到了这一错误,解决方案如下:
第一步:准备 **.local-chromium** 可执行文件
上述含义是:在 node_modules\puppeteer.local-chromium 中包含可执行文件,不能包含在 pkg 的打包文件中,需要将他们随着 pgk 打包好的可执行文件一起分发。 也就是说想要这个打包好的执行程序能正常运行,需要向下面这样提供:
|- htmToPdf|- htmltopdf.exe|- chromium # chromium 目录下的内容就是 node_modules\puppeteer\.local-chromium 目录下的内容|- win64-884014
所以,你需要先把 node_modules\puppeteer\.local-chromium 目录下的内容复制出来,像上述示意一样存放。
第二步:修改 puppeteer 的程序,使用我们附带的可执行程序文件
由于 pkg 不能打包 **.local-chromium ** ,那么就意味着我们写的 puppeteer 程序不能正常工作,好在 puppeteer 的 api 提供了相关的 API 可以指定 **.local-chromium** 的路径( puppeteer.launch({"executablePath":"自定义地址"}) ),那么修改 htmlToPdf.js 文件
const puppeteer = require('puppeteer');// 以下代码主要是为了获取到同级目录下的 .local-chromium 目录的绝对路径// 主要增加是这几行代码-开始,const path = require('path')const isPkg = typeof process.pkg !== 'undefined';const chromiumExecutablePath = (isPkg? puppeteer.executablePath().replace(/^.*?\\node_modules\\puppeteer\\\.local-chromium/, //<------ 前面这个是 windows 的代码, 在 linux 下需要使用: /^.*?\/node_modules\/puppeteer\/\.local-chromium/path.join(path.dirname(process.execPath), 'chromium') //<------ 这个文件名根据你自己的需要定制,也就是前面复制在同级目录下的 chromium 目录): puppeteer.executablePath());// 主要增加是这几行代码-结束(async function () {console.log(chromiumExecutablePath)// 打印从命令行传递的参数if (process.argv.length < 4) {throw new Error("参数异常,使用方式为 node htmlToPdf.js url pdfPath")}const url = process.argv[2]const pdfPath = process.argv[3]console.log(process.argv)console.log(url,pdfPath)const browser = await puppeteer.launch({args: ['--no-sandbox', '--disable-setuid-sandbox'],executablePath: chromiumExecutablePath // 还有这里,自定义 chromium 执行文件的地址})const page = await browser.newPage()await page.goto(url, {waitUntil: 'networkidle2' // 考虑在至少 500ms 内没有超过 2 个网络连接时完成导航})await page.waitForSelector('.main', {timeout: 30000 // 默认等待 30 秒}).then(() => console.log('内容已经出现'))await page.pdf({path: pdfPath,format: 'A4',landscape: true})await browser.close()})()
如果打包不能正常成功,请追加 --public 参数
pkg . --public
升级版 1.0 参数化
前面的主要逻辑实现很多参数写死了,这个版本支持传递参数,达到不重新打包也能定制一些信息
const puppeteer = require('puppeteer')const path = require('path')const isPkg = typeof process.pkg !== 'undefined'const chromiumExecutablePath = (isPkg? puppeteer.executablePath().replace(/^.*?\\node_modules\\puppeteer\\\.local-chromium/, // <------ 前面这个是 windows 的代码, 在 linux 下需要使用:// /^.*?\/node_modules\/puppeteer\/\.local-chromium/, // 这个是 linux 下使用path.join(path.dirname(process.execPath), 'chromium') // <------ 这个文件名根据你自己的需要定制): puppeteer.executablePath())function paramsParse (argv) {const params = {}for (let index = 0; index < argv.length; index++) {if (index < 4) {continue}const elem = argv[index]const items = elem.split('=')params[items[0]] = items[1]}return params}/*基本使用方式:node htmlToPdf.js url pdfPath后面可以根参数:比如 node htmlToPdf.js url pdfPath 'selector=.main',可以配置的参数有selector:需要等待页面出现的元素,比如是 css 类名,这用 .xxxwaitForSelectorTimeout: 等待元素出现超时时间,页面加载后,如果这个元素不出现,这超过指定时间后异常,单位 毫秒pdfFormat: 宽高预设选择项目,比如 A0 ~ A6 纸张大小 可以参考官方文档 https://pptr.dev/#?product=Puppeteer&version=v10.0.0&show=api-pagepdfoptions 然后搜索 page.pdfpdfLandscape: pdf 方向, true 横向(默认), false 竖向*/(async function () {console.log(chromiumExecutablePath)// 打印从命令行传递的参数if (process.argv.length < 4) {throw new Error('参数异常,使用方式为 node htmlToPdf.js url pdfPath')}const url = process.argv[2]const pdfPath = process.argv[3]console.log(process.argv)const configParams = paramsParse(process.argv)console.log('传入配置:', configParams)const browser = await puppeteer.launch({args: ['--no-sandbox', '--disable-setuid-sandbox'],executablePath: chromiumExecutablePath})const page = await browser.newPage()// https://bookjs.zhouwuxue.com/eazy-1.html//http://localhost:81/pdf?area=&product=&id=1047&type=1&access_token=ec28ef7f0651409ebbe2e2daca9f4899await page.goto(url, {waitUntil: 'networkidle2' // 考虑在至少 500ms 内没有超过 2 个网络连接时完成导航})let selector = '.main'if (configParams.selector) {selector = configParams.selector}let waitForSelectorTimeout = 30000if (configParams.waitForSelectorTimeout) {waitForSelectorTimeout = parseInt(configParams.waitForSelectorTimeout)}await page.waitForSelector(selector, {timeout: waitForSelectorTimeout // 默认等待 30 秒}).then(() => console.log('内容已经出现'))let pdfFormat = 'A4'if (configParams.pdfFormat) {pdfFormat = configParams.pdfFormat}let pdfLandscape = trueif (configParams.pdfLandscape) {pdfLandscape = configParams.pdfLandscape == 'true'}await page.pdf({path: pdfPath,format: pdfFormat,landscape: pdfLandscape})await browser.close()})()
在 linux 部署注意事项
需要将打包好的可执行文件和 chromium 下的可执行文件增加可执行权限
chmod +x chromium/linux-884014/chrome-linux/chromechmod +x htmltopdf
添加可执行权限后,如果报错如下信息
error while loading shared libraries: libnss3.so: cannot open shared object file
这个是由于缺少共享库(依赖),需要安装,可在官方的排错文档中找到描述
ldd chromium/linux-884014/chrome-linux/chrome | grep notlibnss3.so => not foundlibnssutil3.so => not foundlibsmime3.so => not foundlibnspr4.so => not foundlibatk-1.0.so.0 => not foundlibatk-bridge-2.0.so.0 => not foundlibcups.so.2 => not foundlibxkbcommon.so.0 => not foundlibXcomposite.so.1 => not foundlibXdamage.so.1 => not foundlibXfixes.so.3 => not foundlibXrandr.so.2 => not foundlibgbm.so.1 => not foundlibpango-1.0.so.0 => not foundlibcairo.so.2 => not foundlibatspi.so.0 => not foundlibxshmfence.so.1 => not found
可以看到这些都没有被找到,根据官方排错指南,安装不同的依赖项,这里以 Ubuntu 为例
apt-get install ca-certificates fonts-liberation libappindicator3-1 libasound2 libatk-bridge2.0-0 libatk1.0-0 libc6 libcairo2 libcups2 libdbus-1-3 libexpat1 libfontconfig1 libgbm1 libgcc1 libglib2.0-0 libgtk-3-0 libnspr4 libnss3 libpango-1.0-0 libpangocairo-1.0-0 libstdc++6 libx11-6 libx11-xcb1 libxcb1 libxcomposite1 libxcursor1 libxdamage1 libxext6 libxfixes3 libxi6 libxrandr2 libxrender1 libxss1 libxtst6 lsb-release wget xdg-utils
安装依赖之后,再次运行 ldd chromium/linux-884014/chrome-linux/chrome | grep not 就发现没有输出项目了
在 docker 容器中使用
官方文档中有教程将 puppeteer 封装成 docker 镜像,然后运行 docker 镜像来指定我们写好的 js,但是这样并不符合我们使用 java 应用调用 puppeteer 这一需求。
所以解决方案还是在打 java 包的时候,将缺少的公共依赖库给安装上,Dockerfile 如下
FROM openjdk:8u212-jre-slimWORKDIR /appCOPY build/libs/dpa-be-*.jar app.jar# 添加一个仓库源,然后安装缺少的公共库RUN sed -i 's/deb.debian.org/mirrors.tuna.tsinghua.edu.cn/g' /etc/apt/sources.list &&\apt-get update && \apt-get install -y ca-certificates fonts-liberation libappindicator3-1 libasound2 libatk-bridge2.0-0 \libatk1.0-0 libc6 libcairo2 libcups2 libdbus-1-3 libexpat1 libfontconfig1 libgbm1 libgcc1 libglib2.0-0 \libgtk-3-0 libnspr4 libnss3 libpango-1.0-0 libpangocairo-1.0-0 libstdc++6 libx11-6 libx11-xcb1 libxcb1 \libxcomposite1 libxcursor1 libxdamage1 libxext6 libxfixes3 libxi6 libxrandr2 libxrender1 libxss1 libxtst6 \lsb-release wget xdg-utils &&\apt-get clean && \rm -rf /var/lib/apt/lists/*EXPOSE 80ENTRYPOINT ["java", "-jar", "-XX:+HeapDumpOnOutOfMemoryError", "-XX:HeapDumpPath=/app/heap-dump/", "app.jar"]
这样再配合上面打包成二进制文件的 puppeteer 应用,就不在需要在镜像中安装 node 相关环境了,就很方便的能使用 java 调用 puppeteer 了
docker 容器中中文乱码
这里有两种方案解决:
- 调用 puppeteer 应用的 docker 容器安装中文字体:相对来说通用,ubantu 中可以安装
fonts-arphic-uming,在前面 Dockerfile 中安装依赖的地方添加进去一同安装 - 访问的页面上直接加在线字体,然后指定使用这个在线字体:这个最简单,但是就只能对这种的网页使用,不是很通用

若有收获,就点个赞吧
0 人点赞
