主要对 hutool 的 ExcelUtil._readBySax(_inputStream, 0, rowHandler_)_; API 进行了增强,自定义 RowHandler 实现如下的增强功能:
- 解析一行数据,给出一个对象
- 自己对某个业务字段判定时,可以获取到该字段在文件中的位置信息,比如第 n 行,n 列
- 每个字段转换异常可以获取到详细信息
依赖如下
implementation 'cn.hutool:hutool-all:5.5.4'implementation 'org.apache.poi:poi:4.1.2'implementation 'org.apache.poi:poi-ooxml:4.1.2'// 数据对象使用了 lombok 注解,可以自行解决不使用compileOnly 'org.projectlombok:lombok'annotationProcessor 'org.projectlombok:lombok'
工具代码
核心处理器 DataRowHandler
package cn.mrcode.parse.data;import java.lang.reflect.Field;import java.util.HashMap;import java.util.LinkedHashMap;import java.util.List;import java.util.Map;import java.util.function.Function;import java.util.function.Supplier;import java.util.stream.Collectors;import cn.hutool.core.annotation.Alias;import cn.hutool.core.convert.Convert;import cn.hutool.core.util.StrUtil;import cn.hutool.poi.excel.sax.handler.RowHandler;import lombok.Data;/*** 通用详细位置的数据行解析* <pre>* 接受行内容的数据对象, 请继承 DataRowNumber 对象,可以给你提供行号* 另外,对象字段使用 cn.hutool.core.annotation.Alias 注解指定对应表头信息,如下所示:* @Alias("客户名称")* private String customerName;* 使用方式:ExcelUtil.readBySax(inputStream, 0, rowHandler); 将本对象传递给 rowHandler* </pre>** @param <T> 接受行内容的数据对象* @author mrcode* @date 2021/9/16 20:03*/public class DataRowHandler<T extends DataRowNumber> implements RowHandler {private DataRowFunction<T, Boolean> successFun;private Function<DataRowFailMsg, Boolean[]> failFun;private Supplier<T> factoryNew;private List<String> headers;Map<String, FieldItem> fieldItemMap; // 字段类型映射/*** @param successFun 当一行数据解析成功时的回调函数,你处理之后,如果需要继续处理,请返回 true,否则返回 false* @param failFun 当某行数据的某个字段解析失败时的回调函数,返回两个值:1:决定当前对象剩余字段是否还继续解析,2:当前整个文件解析是否还继续, true* 继续,false 停止; 或则直接返回 null,会继续解析剩余数据* @param factoryNew 当需要一个新的行对象时,请返回一个初始化对象*/public DataRowHandler(DataRowFunction<T, Boolean> successFun,Function<DataRowFailMsg, Boolean[]> failFun,Supplier<T> factoryNew) {this.successFun = successFun;this.failFun = failFun;this.factoryNew = factoryNew;this.buildFieldItemMap();}/*** 获取该行对应的某个字段信息** @param headerName 表头字段的别名* @param item 给你的行结果信息,主要为了获取里面的行号* @return*/public DataRowFieldInfo getFieldInfo(String headerName, T item) {final DataRowFieldInfo fieldInfo = new DataRowFieldInfo();fieldInfo.setRowNum(item.getRowNum());fieldInfo.setField(headerName);// 根据表头字段顺序定位该字段在 excel 中的位置for (int i = 0; i < headers.size(); i++) {if (headerName.equals(headers.get(i))) {fieldInfo.setPosition(ExcelColumnUtil.excelColIndexToStr(i + 1) + item.getRowNum());break;}}return fieldInfo;}@Overridepublic void handle(int sheetIndex, long rowIndex, List<Object> rowList) {// 第 0 行为:表头字段if (rowIndex == 0) {// 将表头收集起来,后续以此顺序 判定某个字段所在的位置headers = rowList.stream().map(Object::toString).collect(Collectors.toList());return;}// 将该行内容与 表头一一对应上final int headerSize = headers.size();final int rowSize = rowList.size();final Map<String, Object> kvMap = new LinkedHashMap<>(headerSize);for (int i = 0; i < headerSize; i++) {if (i < rowSize) {kvMap.put(headers.get(i), rowList.get(i));}}// 解析该行内容成对象T row = parse(rowIndex, kvMap);if (!successFun.apply(row, this)) {throw new DataRowParseStopException();}}private T parse(long rowIndex, Map<String, Object> kvMap) {final long excelRowNum = rowIndex + 1;final T row = factoryNew.get();row.setRowNum(excelRowNum);// 按表头顺序获取内容for (int i = 0; i < headers.size(); i++) {final String header = headers.get(i);final Object valueObject = kvMap.get(header);if (valueObject == null || valueObject.toString() == "") {continue;}final FieldItem fieldItem = fieldItemMap.get(header);// 当一行中出现了某个字段是无法识别时,该行解析失败if (fieldItem == null) {final DataRowFailMsg dataRowFailMsg = new DataRowFailMsg();dataRowFailMsg.setRowNum(excelRowNum);dataRowFailMsg.setField(header);dataRowFailMsg.setPosition(ExcelColumnUtil.excelColIndexToStr(i + 1) + excelRowNum);dataRowFailMsg.setMsg("无法识别的字段");// 如果不继续,则直接抛出停止异常final Boolean[] isContinues = failFun.apply(dataRowFailMsg);if (isContinues != null) {// 剩余文件不继续解析if (!isContinues[0]) {throw new DataRowParseStopException();}// 剩余字段不继续解析if (!isContinues[1]) {break;}// 剩余字段继续解析continue;}}// 利用反射给对应的字段赋值final Class<?> type = fieldItem.getType();final Field field = fieldItem.getField();try {final Object value = Convert.convert(type, valueObject);field.set(row, value);} catch (Exception e) {String msg = StrUtil.format("值转换异常,目标值类型={} ,原始值={}",type.getName(),valueObject);final DataRowFailMsg dataRowFailMsg = new DataRowFailMsg();dataRowFailMsg.setRowNum(excelRowNum);dataRowFailMsg.setField(header);dataRowFailMsg.setPosition(ExcelColumnUtil.excelColIndexToStr(i + 1) + excelRowNum);dataRowFailMsg.setMsg(msg);// 如果不继续,则直接抛出停止异常final Boolean[] isContinues = failFun.apply(dataRowFailMsg);if (isContinues != null) {// 剩余文件不继续解析if (!isContinues[0]) {throw new DataRowParseStopException();}// 剩余字段不继续解析if (!isContinues[1]) {row.setError(true);break;}// 剩余字段继续解析row.setError(true);continue;}}}return row;}/*** 构建字段别名* <pre>* 表头使用中文字段,想要处理过程中中文字段与对象字段对应上,* 该方法就是将:中文字段 与 对象的字段 关联上,方便后续的 set 操作* </pre>*/private void buildFieldItemMap() {final Class clzz = factoryNew.get().getClass();final Field[] declaredFields = clzz.getDeclaredFields();Map<String, FieldItem> fieldItemMap = new HashMap<>();for (Field declaredField : declaredFields) {final Class<?> type = declaredField.getType();final Alias aliasAnno = declaredField.getAnnotation(Alias.class);if (aliasAnno == null) {continue;}final String value = aliasAnno.value();declaredField.setAccessible(true);fieldItemMap.put(value, new FieldItem(declaredField, type));}this.fieldItemMap = fieldItemMap;}@Dataprivate static class FieldItem {// 字段实例private Field field;// 参数类型private Class<?> type;public FieldItem(Field field, Class<?> type) {this.field = field;this.type = type;}}}
其他辅助类,响应的字段位置、行号、异常等类
package cn.mrcode.parse.data;import lombok.Data;import lombok.ToString;/*** 数据所在行* @author mrcode* @date 2021/9/16 20:03*/@Data@ToStringpublic class DataRowNumber {// 行号private Long rowNum;// 这一行数据中是否有解析错误的信息,当某个字段解析失败还继续解析剩余字段时,这里就会标识为 true,标识该条数据不完整private boolean isError;}
package cn.mrcode.parse.data;import lombok.Data;import lombok.EqualsAndHashCode;/*** 某个字段的位置信息* @author mrcode* @date 2021/9/16 20:03*/@Data@EqualsAndHashCode(callSuper = true)public class DataRowFieldInfo extends DataRowNumber {// 位置private String position;// 字段private String field;@Overridepublic String toString() {return "DataRowFieldInfo{" +"rowNum=" + getRowNum() +", position='" + position + '\'' +", field='" + field + '\'' +'}';}/*** 转换为错误信息,可用于二次加工** @return*/public DataRowFailMsg toFailMsg() {final DataRowFailMsg failMsg = new DataRowFailMsg();failMsg.setRowNum(this.getRowNum());failMsg.setField(this.field);failMsg.setPosition(this.position);return failMsg;}}
package cn.mrcode.parse.data;import lombok.Data;import lombok.EqualsAndHashCode;/*** 解析失败时的位置定位信息详情* @author mrcode* @date 2021/9/16 20:03*/@Data@EqualsAndHashCode(callSuper = true)public class DataRowFailMsg extends DataRowFieldInfo {// 错误信息private String msg;@Overridepublic String toString() {return "DataRowFailMsg{" +"rowNum=" + getRowNum() +", position='" + getPosition() + '\'' +", field='" + getField() + '\'' +", msg='" + msg + '\'' +'}';}}
package cn.mrcode.parse.data;/*** 解析停止时的异常; 用于手动停止解析的中断逻辑流程* @author mrcode* @date 2021/9/16 20:03*/public class DataRowParseStopException extends RuntimeException {public DataRowParseStopException() {}}
package cn.mrcode.parse.data;/*** 数据解析成功,回调函数* @author mrcode* @date 2021/9/16 20:03*/@FunctionalInterfacepublic interface DataRowFunction<T, R> {/*** @param t* @param handler 行解析对象本身* @return*/R apply(T t, DataRowHandler handler);}
excel 位置信息工具类
package cn.mrcode.parse.data;/*** Excel 列的下标 和 字母互转** @author Stephen.Huang* @version 2015-7-8*/public class ExcelColumnUtil {public static int excelColStrToNum(String colStr) {return excelColStrToNum(colStr, colStr.length());}/*** 列字母转数字* <pre>** 注意:Excel column index 从 1 开始** </pre>** @param colStr* @param length* @return*/public static int excelColStrToNum(String colStr, int length) {int num = 0;int result = 0;for (int i = 0; i < length; i++) {char ch = colStr.charAt(length - i - 1);num = (int) (ch - 'A' + 1);num *= Math.pow(26, i);result += num;}return result;}/*** 将列转成字母** @param columnIndex 注意:Excel column index 从 1 开始* @return*/public static String excelColIndexToStr(int columnIndex) {if (columnIndex <= 0) {return null;}String columnStr = "";columnIndex--;do {if (columnStr.length() > 0) {columnIndex--;}columnStr = ((char) (columnIndex % 26 + (int) 'A')) + columnStr;columnIndex = (int) ((columnIndex - columnIndex % 26) / 26);} while (columnIndex > 0);return columnStr;}public static void main(String[] args) {String colstr = "AA";int colIndex = excelColStrToNum(colstr, colstr.length());System.out.println("'" + colstr + "' column index of " + colIndex);colIndex = 26;colstr = excelColIndexToStr(colIndex);System.out.println(colIndex + " column in excel of " + colstr);colstr = "AAAA";colIndex = excelColStrToNum(colstr, colstr.length());System.out.println("'" + colstr + "' column index of " + colIndex);colIndex = 466948;colstr = excelColIndexToStr(colIndex);System.out.println(colIndex + " column in excel of " + colstr);}}
业务代码与测试
步骤 1:首先准备一份 excel 文件,如下图所示:第一行是表头,第二行开始是数据
步骤 2:准备对应的数据对象
package cn.mrcode.parse.data.test;import cn.mrcode.parse.data.DataRowNumber;import cn.hutool.core.annotation.Alias;import lombok.Data;import lombok.EqualsAndHashCode;import lombok.ToString;@Data@ToString@EqualsAndHashCode(callSuper = true)public class CustomerRow extends DataRowNumber {@Alias(CustomerRowFieldAlias.CUSTOMER_NAME)private String customerName;@Alias(CustomerRowFieldAlias.COMPANY)private String company;@Alias(CustomerRowFieldAlias.PRODUCT_TYPE)private String productType;@Alias(CustomerRowFieldAlias.BRAND)private String brand;@Alias(CustomerRowFieldAlias.WEBSITE)private String website;@Alias(CustomerRowFieldAlias.AREA)private String area;@Alias(CustomerRowFieldAlias.CHANNEL_CODE)private String channelCoding;@Alias(CustomerRowFieldAlias.SOURCE)private String source;@Alias(CustomerRowFieldAlias.CONTACT_INFO)private String contactInfo;@Alias(CustomerRowFieldAlias.DEMAND)private String demand;@Alias(CustomerRowFieldAlias.REMARK)private Integer remark;}
文件表头对应的别名常量类
public interface CustomerRowFieldAlias {String CUSTOMER_NAME="客户名称(必填)";String COMPANY="客户公司";String PRODUCT_TYPE="产品品类";String BRAND="客户品牌";String WEBSITE="客户网站";String AREA="地区";String CHANNEL_CODE="来源渠道(必填)";String SOURCE="来源";String CONTACT_INFO="联系方式";String DEMAND="客户需求";String REMARK="备注";}
步骤 3:编写解析代码测试
package cn.mrcode.parse.data.test;import cn.mrcode.parse.data.test.CustomerRow;import cn.mrcode.parse.data.test.CustomerRowFieldAlias;import org.junit.jupiter.api.Test;import java.io.IOException;import java.io.InputStream;import java.nio.file.Files;import java.nio.file.Path;import java.nio.file.Paths;import cn.hutool.core.util.StrUtil;import cn.hutool.poi.excel.ExcelUtil;/*** @author mrcode* @date 2021/9/16 20:03*/class DataRowHandlerTest {@Testvoid handle() {Path path = Paths.get("C:\\clue-customer.xlsx");try (final InputStream inputStream = Files.newInputStream(path)) {final DataRowHandler<CustomerRow> rowHandler = new DataRowHandler<>(// 一行数据解析成功(item, handler) -> {System.out.println("数据解析成功,其中是否有某个字段解析失败?" + item.isError());System.out.println("数据解析成功:" + item);// 这里可以做业务的校验等,比如该字段是必须的,final String customerName = item.getCustomerName();if (StrUtil.isBlank(customerName)) {// 校验失败之后,获取该字段在文件中的位置信息DataRowFieldInfo fieldInfo = handler.getFieldInfo(CustomerRowFieldAlias.CUSTOMER_NAME, item);System.out.println("业务校验未通过,字段信息:" + fieldInfo);// 遇到一个错误之后,就不再继续解析文件了return false;}return true;},// 一行的某个字段解析失败时调用item -> {System.out.println("数据解析失败:" + item);// 如果该字段解析失败,还需要继续往下解析,发挥 true,否则返回 false// 第一个值:剩余文件是否还继续解析, 如果文件都不继续了,则直接返回,剩余字段信息也不会解析// 第二个值:剩余字段还是否继续解析, 如果是 true,那么这一行数据将可能会出现多个字段解析异常的消息,最后会回调解析成功的函数// 继而可以在回调成功的函数中,使用 item.isError() 判定该条数据是否完整return new Boolean[]{true, false};},// 一行数据的承载对象CustomerRow::new);// 开始解析,只解析第一个 sheet 的内容ExcelUtil.readBySax(inputStream, 0, rowHandler);} catch (DataRowParseStopException e) {System.out.println("手动中断解析");} catch (IOException e) {e.printStackTrace();System.out.println("未知异常,需要看源码确定是哪里的问题");}}}
自定义业务校验失败时
数据解析成功:CustomerRow(customerName=null, company=北京科技有限公司, productType=成衣,假发, brand=null, website=null, area=null, channelCoding=请填写渠道编码,如:abc123, source=来源渠道补充信息, contactInfo=联系名称和联系方式用英文冒号分隔,多个用英文;分隔,如:手机:123456;QQ:123456, demand=null, remark=null)业务校验未通过,字段信息:DataRowFieldInfo{rowNum=2, position='A2', field='客户名称(必填)'}手动中断解析
某行字段解析失败,并且剩余文件不继续解析、剩余字段不继续解析时
数据解析失败:DataRowFailMsg{rowNum=2, position='K2', field='备注', msg='值转换异常,目标值类型=java.lang.Integer ,原始值=15xxx,解析错误'}手动中断解析
某行字段解析失败,并且剩余文件继续解析、剩余字段不继续解析时:
数据解析失败:DataRowFailMsg{rowNum=2, position='K2', field='备注', msg='值转换异常,目标值类型=java.lang.Integer ,原始值=算法ss'}数据解析成功,其中是否有某个字段解析失败?true数据解析成功:CustomerRow(customerName=张三, company=北京科技有限公司, productType=成衣,假发, brand=null, website=null, area=null, channelCoding=请填写渠道编码,如:abc123, source=来源渠道补充信息, contactInfo=联系名称和联系方式用英文冒号分隔,多个用英文;分隔,如:手机:123456;QQ:123456, demand=null, remark=null)
真实业务场景使用
需求:对一个文件进行解析入库,解析成功的行、经过业务校验通过后,入库,未经过校验的或则解析失败的,响应详细信息给前端
@Override@AccessLog(value = "线索导入", isPrintRes = false)public ImportCustomerResult importCustomer(Path path, UserInfo userInfo) {// 解析的总数AtomicReference<Integer> totalCount = new AtomicReference<>(0);// 失败的数量AtomicReference<Integer> failCount = new AtomicReference<>(0);// 成功的数量AtomicReference<Integer> successCount = new AtomicReference<>(0);// 用于存储失败行的错误信息,每行错误信息只存储一条List<DataRowFailMsg> errDetails = new ArrayList<>();try (final InputStream inputStream = Files.newInputStream(path)) {final DataRowHandler<CustomerRow> rowHandler = new DataRowHandler<>(// 一行数据解析成功(item, handler) -> {//由于忽略某一行解析失败, 除了致命的文件解析异常,都会进入到这里,在这里进行总行数的统计totalCount.getAndSet(totalCount.get() + 1);// 该行数据有异常,剩余文件数据继续解析if (item.isError()) {// 失败数量+1failCount.getAndSet(failCount.get() + 1);return true;}final DataRowFailMsg failMsg = this.checkData(item, handler);if (failMsg != null) {errDetails.add(failMsg);failCount.getAndSet(failCount.get() + 1);return true;}successCount.getAndSet(successCount.get() + 1);// 插入数据库操作return true;},// 一行的某个字段解析失败时调用item -> {errDetails.add(item); // 将该行数据的第一个错误信息添加到详情中// 某个字段解析失败,文件继续解析,剩余字段不继续解析return new Boolean[]{true, false};},// 一行数据的承载对象CustomerRow::new);// 开始解析,只解析第一个 sheet 的内容ExcelUtil.readBySax(inputStream, 0, rowHandler);} catch (DataRowParseStopException e) {// 响应导入结果final ImportCustomerResult result = new ImportCustomerResult();result.setTotalCount(totalCount.get());result.setFailCount(failCount.get());result.setSuccessCount(successCount.get());result.setErrDetails(errDetails);return result;} catch (IOException e) {log.error("文件解析异常", e);throwErr("导入失败,未知错误");}// 响应导入结果final ImportCustomerResult result = new ImportCustomerResult();result.setTotalCount(totalCount.get());result.setFailCount(failCount.get());result.setSuccessCount(successCount.get());result.setErrDetails(errDetails);return result;}/*** 业务数据校验** @param item* @param handler* @return*/private DataRowFailMsg checkData(CustomerRow item, DataRowHandler handler) {final String customerName = item.getCustomerName();if (StrUtil.isBlank(customerName)) {DataRowFieldInfo fieldInfo = handler.getFieldInfo(CustomerRowFieldAlias.CUSTOMER_NAME, item);DataRowFailMsg failMsg = fieldInfo.toFailMsg();failMsg.setMsg("该数据必填");return failMsg;}final String channelCoding = item.getChannelCoding();if (StrUtil.isBlank(channelCoding)) {DataRowFieldInfo fieldInfo = handler.getFieldInfo(CustomerRowFieldAlias.CHANNEL_CODE, item);DataRowFailMsg failMsg = fieldInfo.toFailMsg();failMsg.setMsg("该数据必填");return failMsg;}// 客户名称不能重复校验// 渠道编码真实性校验return null;}
返回给前端渲染报告图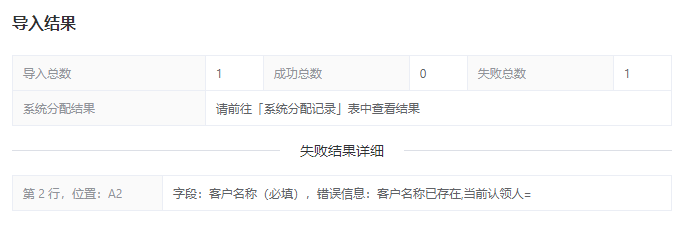

若有收获,就点个赞吧
0 人点赞
