常用网站
Mysql 8 参考手册:https://dev.mysql.com/doc/refman/8.0/en/,具体的版本修改其中的数字版本号
- 优化章节
-
笔记
给程序员的 MySQL 8.0 必知必会:数据建模、数据库访问、SQL 开发、SQL 优化、事物和高并发
- DML 语法:还挺不错的
- 阿里新零售数据库设计与实战:零售业务讲解、数据库表设计、常见问题与企业级解决方案、性能优化、数据库集群、分库分表、binlog 等
- 高性能 MySQL(第三版)
- MySQL 最大链接数设置,查看当前链接等信息:enjoy csdn
查看/修改自增
mysql 版本:5.7+
背景:某些需求可能会让账户的 ID 从 1000 开始自增,这个时候就需要修改当前表的自增数据
方案:
- 在创建表的时候,通过语句指定
- 表创建之后再通过语句修改
创建表指定
CREATE TABLE `Test` (`ID` INT ( 11 ) NOT NULL AUTO_INCREMENT,`NAME` VARCHAR ( 50 ) NOT NULL,`SEX` VARCHAR ( 2 ) NOT NULL,PRIMARY KEY ( `ID` )) ENGINE = INNODB AUTO_INCREMENT = 1001 DEFAULT CHARSET = utf8mb4 COMMENT = '测试表';
通过语句修改
-- 查看表当前的自增数据, 需要先插入一条数据后,才能获得insert ...; select last_insert_id()+1;-- 查看表当前的自增数据,通过 information_schema 表SELECT AUTO_INCREMENT FROM information_schema.tables where table_name="表名" and table_schema = '数据库名';-- 修改指定表的自增数据,也就是下一个自增 ID 的值ALTER TABLE `表名` auto_increment=1001 ;
docker 容器中备份/还原数据
备份
# mysql-db 是数据库的 docker 名称# xxxpwd 是 root 用户密码# app-db 是要备份的数据名称# xx.sql 是宿主机上的路径,可以是 ./xx.sql 当前执行命令的目录docker exec mysql-db mysqldump -uroot -pxxxpwd --databases app-db > xx.sql
还原
# 将数据拷贝到容器中docker cp xxx mysql-db:/tmp# 进入 mysql 命令行docker exec -it mysql-db mysql -uroot -pxxxpwd# 导入mysql> source /tmp/${BACK_DATA}.sql
UPDATE 表数据
UPDATE table_name SET field1=new-value1, field2=new-value2[WHERE Clause]
比较复杂一点的的更新语句 请参考笔记
列增加
ALTER TABLE 表名 ADD COLUMN 列名 char(1) NULL AFTER 放在已有列名后面-- 默认放在最后ALTER TABLE 表名 ADD COLUMN 列名 char(1) NULL
常用函数
时间/日期函数
-- 日期格式化,年、月、日、时分秒、季度、SELECTdate_format( 20210501, '%Y' ) AS YEAR,date_format( 20210501, '%m' ) AS MONTH,date_format( 20210501, '%d' ) AS day,date_format( 20210501230201, '%H-%i-%S' ) AS hhmmss,QUARTER ( 20210501 ) AS QUARTER
结果如下
| YEAR | MONTH | day | hhmmss | QUARTER |
|---|---|---|---|---|
| 2021 | 05 | 01 | 23-02-01 | 2 |
| %a | 缩写星期名 |
|---|---|
| %b | 缩写月名 |
| %c | 月,数值 |
| %D | 带有英文前缀的月中的天 |
| %d | 月的天,数值(00-31) |
| %e | 月的天,数值(0-31) |
| %f | 微秒 |
| %H | 小时 (00-23) |
| %h | 小时 (01-12) |
| %I | 小时 (01-12) |
| %i | 分钟,数值(00-59) |
| %j | 年的天 (001-366) |
| %k | 小时 (0-23) |
| %l | 小时 (1-12) |
| %M | 月名 |
| %m | 月,数值(00-12) |
| %p | AM 或 PM |
| %r | 时间,12-小时(hh:mm:ss AM 或 PM) |
| %S | 秒(00-59) |
| %s | 秒(00-59) |
| %T | 时间, 24-小时 (hh:mm:ss) |
| %U | 周 (00-53) 星期日是一周的第一天 |
| %u | 周 (00-53) 星期一是一周的第一天 |
| %V | 周 (01-53) 星期日是一周的第一天,与 %X 使用 |
| %v | 周 (01-53) 星期一是一周的第一天,与 %x 使用 |
| %W | 星期名 |
| %w | 周的天 (0=星期日, 6=星期六) |
| %X | 年,其中的星期日是周的第一天,4 位,与 %V 使用 |
| %x | 年,其中的星期一是周的第一天,4 位,与 %v 使用 |
| %Y | 年,4 位 |
| %y | 年,2 位 |
分段统计 ELT + INTERVAL
当需要统计某个字段数据中的值,按范围划分的话(比如在 0~1249 这个范围的值统计为一个,并标记它属于 0_1249 这个范围),可以使用如下的方式
SELECTELT(INTERVAL ( ibe8588, 0, 1250, 1500, 1750, 2000, 2500, 3000, 3500, 4000, 5000, 6000, 7000 ),'0_1249','1250_1499','1500_1749','1750_1999','2000_2499','2500_2999','3000_3499','3500_3999','4000_4999','5000_5999','6000_6999','7000_99999999') AS k,count( 1 ) AS vFROMsingle_data_1014GROUP BYk;
这个是结果,如果某一条数据没有值,就会被统计到空这一项里面。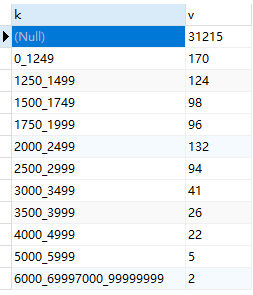
interval 的含义
SELECTibe6164,INTERVAL ( ibe6164, 1, 6, 97, 118 )FROMxxxWHEREcd_id = 1069LIMIT 10
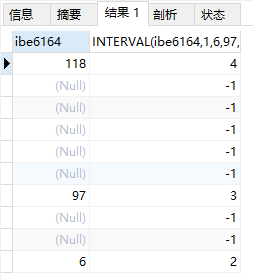
如上图所示: interval 是按照你定义的范围判定数据的值在哪一个范围端,比如数字 6,在第 2 段,因为:
- 第一段是
1 <= x < 6 - 第二段是
6 <= x < 97
不匹配的则计算为 -1.
ELT 含义
SELECTibe6164,INTERVAL ( ibe6164, 1, 6, 97, 118 ),ELT( INTERVAL ( ibe6164, 1, 6, 97, 118 ), '1_5', '6_96', '97_117', '118 以上' ) AS kFROMsingle_data_1014WHEREcd_id = 1069LIMIT 10
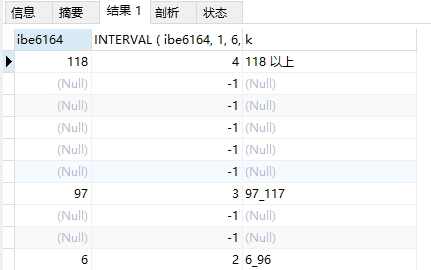
如上图所示,则是将对应的值映射为给出的文字上
查询某个表是否包含某个字段
SELECTcount(*)FROMinformation_schema.COLUMNSWHERETABLE_SCHEMA = '数据库名称'AND TABLE_NAME = '表名称'AND COLUMN_NAME = '列名称'
插入数据
从其他表查询出数据,插入到新的表中:
# 语法如下INSERT INTO 表名 (列明,列明1,列明2...)VALUES(数值,数值1,数值2,数值3)# 当需要从其他表查询数据,并插入到新表中的时候可以用以下语句# 后面的 select 语句 最后的结果,就相当于是 VLUES, 记得给出的顺序 要与前面 表名后面定义的字段顺序一致Insert into wallet(balance,mch_id) select 0 AS balance,id as mch_id from groups;
查询随机数据
SELECT * FROM xxx ORDER BY rand() LIMIT 5;
生成随机时间
# 结果是 2022-04-10 10:10:20 这种时间SELECT concat('2022-04',"-",floor(1+rand()*30),' ', floor(10+rand()*10),':',floor(10+rand()*49),':',floor(10+rand()*49))
随机更新某些数据的时间为 随机时间
结合前面的功能:随机 100 条数据将他们的 publish_time 更新为 2022 年 4 月份的随机时间
UPDATE xxx SET publish_time = (SELECT concat('2022-04',"-",floor(1+rand()*30),' ', floor(10+rand()*10),':',floor(10+rand()*49),':',floor(10+rand()*49)))ORDER BY rand() LIMIT 100;-- 比如说按照条件随机UPDATE xxx SET publish_time = (SELECT concat('2021-11',"-",floor(1+rand()*30),' ', floor(10+rand()*10),':',floor(10+rand()*49),':',floor(10+rand()*49)))where publish_time >= '2022-05-01 00:00:00' and publish_time <= '2022-05-31 23:59:59' order BY rand() LIMIT 5000;
判断 CASE … WHEN…THEN…ELSE..END
比如如下语句:当某个字段的值等于 1 时,返回 1 或则 0,然后将这些数据相加
SELECT sum(CASE WHEN ibe8637 = 1 THEN 1 ELSE 0 END) AS '1',sum(CASE WHEN ibe8637 = 2 THEN 1 ELSE 0 END) AS '2',sum(CASE WHEN ibe8637 = 3 THEN 1 ELSE 0 END) AS '3',sum(CASE WHEN ibe8637 = 4 THEN 1 ELSE 0 END) AS '4',sum(CASE WHEN ibe8637 = 5 THEN 1 ELSE 0 END) AS '5',sum(CASE WHEN ibe8637 = 6 THEN 1 ELSE 0 END) AS '6',sum(CASE WHEN ibe8637 = 7 THEN 1 ELSE 0 END) AS '7',sum(CASE WHEN ibe8637 = 8 THEN 1 ELSE 0 END) AS '8',sum(CASE WHEN ibe8637 = 9 THEN 1 ELSE 0 END) AS '9',sum(CASE WHEN ibe8637 = 'A' THEN 1 ELSE 0 END) AS 'A',sum(CASE WHEN ibe8637 = 'B' THEN 1 ELSE 0 END) AS 'B',sum(CASEWHEN ibe8637 = 'C' THEN 1WHEN ibe8637 = 'D' THEN 1WHEN ibe8637 = 'E' THEN 1WHEN ibe8637 = 'F' THEN 1WHEN ibe8637 = 'G' THEN 1WHEN ibe8637 = 'H' THEN 1WHEN ibe8637 = 'I' THEN 1WHEN ibe8637 = 'J' THEN 1WHEN ibe8637 = 'K' THEN 1WHEN ibe8637 = 'L' THEN 1ELSE 0END) AS 'C',sum(CASE WHEN ibe8637 = 'V' THEN 1 ELSE 0 END) AS 'V',sum(CASE WHEN ibe8637 = 'W' THEN 1 ELSE 0 END) AS 'W',sum(CASE WHEN ibe8637 = 'X' THEN 1 ELSE 0 END) AS 'X',sum(CASE WHEN ibe8637 = 'Y' THEN 1 ELSE 0 END) AS 'Y',sum(CASE WHEN ibe8637 = 'Z' THEN 1 ELSE 0 END) AS 'Z',sum(CASEWHEN ibe8637 = '' THEN 1WHEN ibe8637 is null THEN 1ELSE 0END) AS 'other'FROM xxx
或则进行更新, 按照某个字段的值进行分等级,然后更新到新的字段上
update xxxset emotion_score_level = (CASEWHEN emotion_score is null THEN -1WHEN emotion_score > 15 then 4WHEN emotion_score > 5 then 3WHEN emotion_score > -1 then 2WHEN emotion_score > -10 then 1else 0end);
Mysql5.7 去重保留最新的数据
目前有这样的数据
SELECTid,mlssm_author_id as authorId,publish_timeFROMmls_smWHEREmlssm_author_id != - 1ORDER BYmlssm_author_id,publish_time DESC
| id | authorId | publish_time |
|---|---|---|
| 13190 | 2 | 2022-05-07 19:35:12 |
| 2 | 2 | 2022-05-01 19:10:44 |
| 82405 | 3 | 2022-06-30 19:58:12 |
| 82555 | 3 | 2022-06-30 18:32:40 |
| 82462 | 3 | 2022-06-30 17:43:23 |
| 82498 | 3 | 2022-06-30 15:50:31 |
| 82262 | 3 | 2022-06-30 13:41:20 |
| 82266 | 3 | 2022-06-30 12:30:23 |
| 82501 | 3 | 2022-06-30 11:41:49 |
| 82362 | 3 | 2022-06-30 10:26:33 |
需求就是要获取最新一条帖子数据的 authorId ,这个最新帖子数据是根据 publish_time决定的,而不是 ID 大小,如上表,留下来的数据去重后只会有下面 2 条
| id | authorId | publish_time |
|---|---|---|
| 13190 | 2 | 2022-05-07 19:35:12 |
| 82405 | 3 | 2022-06-30 19:58:12 |
要满足这个需求,可以使用变量方式先组内排序
SELECT id,publish_time,mlssm_author_id as authorId,@last := IF(@FIRST = mlssm_author_id, @last + 1, 1) AS rn,@FIRST := mlssm_author_id as vAuthorIdFROM mls_smWHERE mlssm_author_id != - 1ORDER BY mlssm_author_id,publish_time DESC-- @FIRST 那一行变量赋值,只能写到 @last 这一行的后面-- @last 这里就是每有一行就 +1, 也就是 rn 显示的组内排序,根据上面的条件,rn=1 的就是最新的一条数据
| id | publish_time | authorId | rn | vAuthorId |
|---|---|---|---|---|
| 13190 | 2022-05-07 19:35:12 | 2 | 1 | 2 |
| 2 | 2022-05-01 19:10:44 | 2 | 2 | 2 |
| 82405 | 2022-06-30 19:58:12 | 3 | 1 | 3 |
| 82555 | 2022-06-30 18:32:40 | 3 | 2 | 3 |
| 82462 | 2022-06-30 17:43:23 | 3 | 3 | 3 |
| 82498 | 2022-06-30 15:50:31 | 3 | 4 | 3 |
| 82262 | 2022-06-30 13:41:20 | 3 | 5 | 3 |
| 82266 | 2022-06-30 12:30:23 | 3 | 6 | 3 |
| 82501 | 2022-06-30 11:41:49 | 3 | 7 | 3 |
| 82362 | 2022-06-30 10:26:33 | 3 | 8 | 3 |
看上图,帖子按 publish_time 和 authorId 进行了排序,最新的数据在最前面,rn=1 的就是最新的数据,那么这样就好办了
select *from (SELECT id,publish_time,mlssm_author_id as mlssmAuthorId,@last := IF(@FIRST = mlssm_author_id, @last + 1, 1) AS rn,@FIRST := mlssm_author_id as vMlssmAuthorIdFROM mls_smWHERE mlssm_author_id != - 1ORDER BY mlssm_author_id,publish_time DESC) tempwhere rn = 1
| id | publish_time | mlssmAuthorId | rn | vMlssmAuthorId |
|---|---|---|---|---|
| 13190 | 2022-05-07 19:35:12 | 2 | 1 | 2 |
| 82405 | 2022-06-30 19:58:12 | 3 | 1 | 3 |
最终就出来了:去重并保留最新的一条数据。
:::tips 在上面的过程中,会偶然出现一个 BUG,在同一个 session 中运行多次查询语句的话,可能会导致 @FIRST 变量异常,也就是我们排序不会从 0 开始 ::: 处理方法是,每次查询都添加上初始化语句,如下所示
select *from (SELECT id,publish_time,mlssm_author_id as mlssmAuthorId,@last := IF(@FIRST = mlssm_author_id, @last + 1, 1) AS rn,@FIRST := mlssm_author_id as vMlssmAuthorIdFROM mls_sm,(SELECT @last :=0,@FIRST := NULL) rownumWHERE mlssm_author_id != - 1ORDER BY mlssm_author_id,publish_time DESC) tempwhere rn = 1

若有收获,就点个赞吧
0 人点赞
