实验尝试1: 关于mutation score
实验目的:探究mutation score与其他变量之前的相关性,主要是观察样本能否被正确预测和MS之间的相关性。
实验数据(kill_rate基于原始模型预测):
| mnist_lenet5 | mnist_lenet4 | mnist_lenet1 | cifar10_vgg16 | cifar10_resnet20 | fashion_lenet5 | |
|---|---|---|---|---|---|---|
| label-kill_rate | 0.4116 | 0.4798 | 0.4951 | 0.4910 | 0.5605 | 0.4891 |
| pcs-kill_rate | -0.7722 | -0.9380 | -0.9385 | -0.8541 | -0.9223 | -0.9263 |
| label-pcs | -0.4832 | -0.5137 | -0.5146 | -0.4553 | -0.5165 | -0.5042 |
实验结论:
1.从整体来看,两者的mutation score几乎相同且接近100%,因为无论是正确样本还是错误样本,他们的pcs值都在0-1之前且呈均匀分布,置信度较高的样本只能杀死较少的变异模型,而边缘样本往往能够杀死绝大多数的变异模型(其实一小部分边缘样本的集合的MS就能接近100%)。
2.测试用例的label(true/false)与kill_rate的相关性远不如pcs值(最后预测的类别的置信度)与kill_rate的相关性,且在某些模型上pcs值与kill_rate的相关性达到了0.9以上。
下图中的红色曲线为利用分层抽样根据pcs值的大小选择一定比例的正确样本和错误样本重复50次的结果,结果要普遍略优于baseline和random。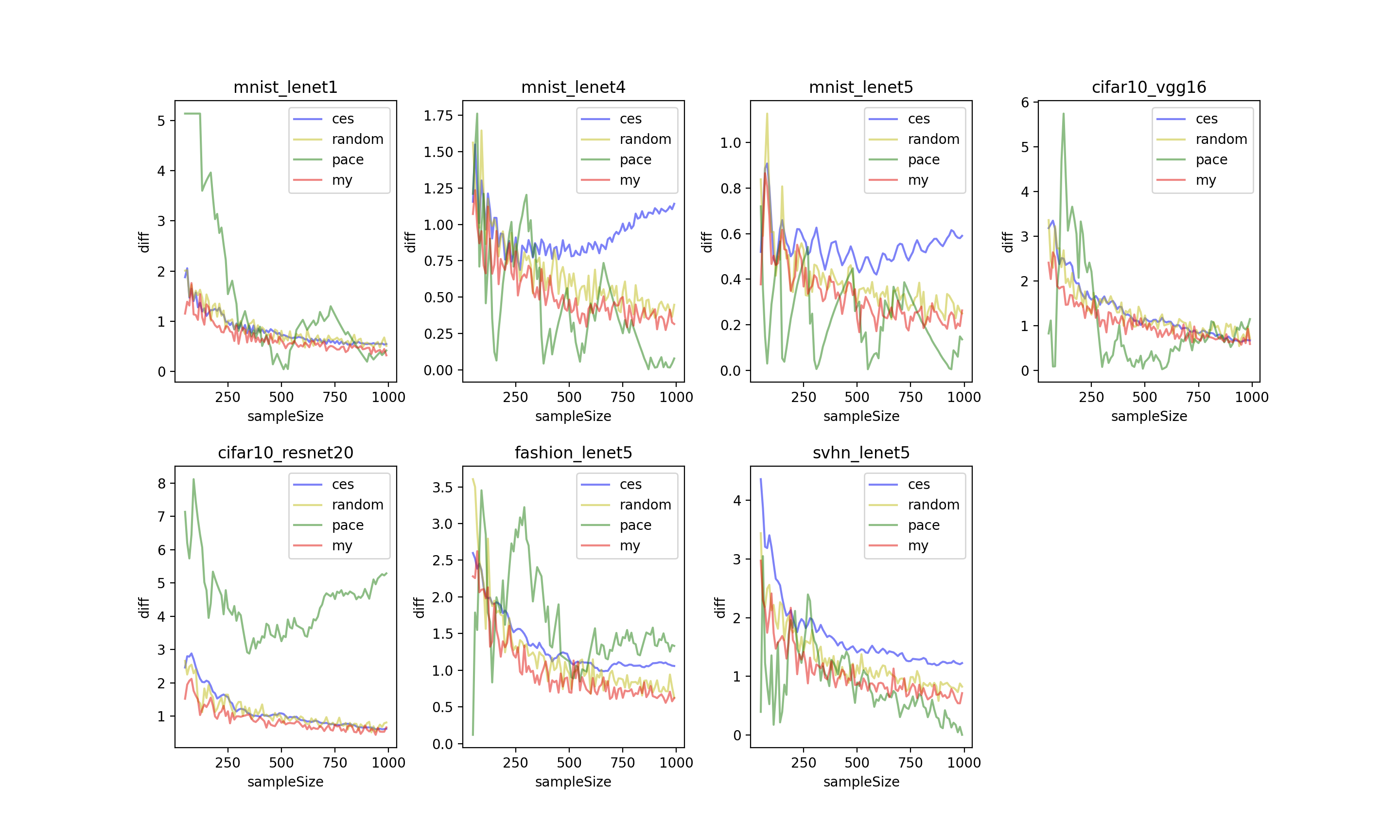
实验尝试2:置信度差值矩阵
实验目的:现在使用的测试用例的特征表示向量包含的信息太少且kill_rate与label的相关性本身就不够强,希望通过细化变异模型的预测结果从而使特征表示向量中包含更多的信息。
实验设计:
置信度差值矩阵:每一个测试用例在每一个变异模型上的表示为其在原模型的预测出的标签的置信度与在变异模型上此标签的置信度的差值。
实验结论:当使用置信度差值矩阵代替原来的killing_matrix即0/1矩阵时,这个矩阵就几乎没有包含kill_rate的信息,仅有的label与kill_rate的相关性都没有利用好,因此效果远不如现有效果。
实验尝试3:有监督的方法
实验目的:充分利用好label与kill_rate的相关性
实验设计:
假设已经拥有测试集的标签,对于每一个变异模型计算出它被正确样本杀死的比例&被错误样本杀死的比例,在选择模型时优先选择那些两个数值相差较大的模型。(理想情况:这个模型只能被错误用例杀死或者只能被正确用例杀死)
实验结论:
几乎不存在这样的模型,因为模型能否被样本杀死还是取决于它的pcs值而非它是否是正确或错误样本
效果没有改善,根本原因还是因为kill_rate和label的相关性不够高
实验尝试4:
实验目的:通过对中间指标的一些可视化方式,理解我们之前的方法为什么起作用&没起作用,给下一步改进提供一些启发。
实验设计(以下的可视化结果均来自针对类生成的模型):
1.整体精度分布: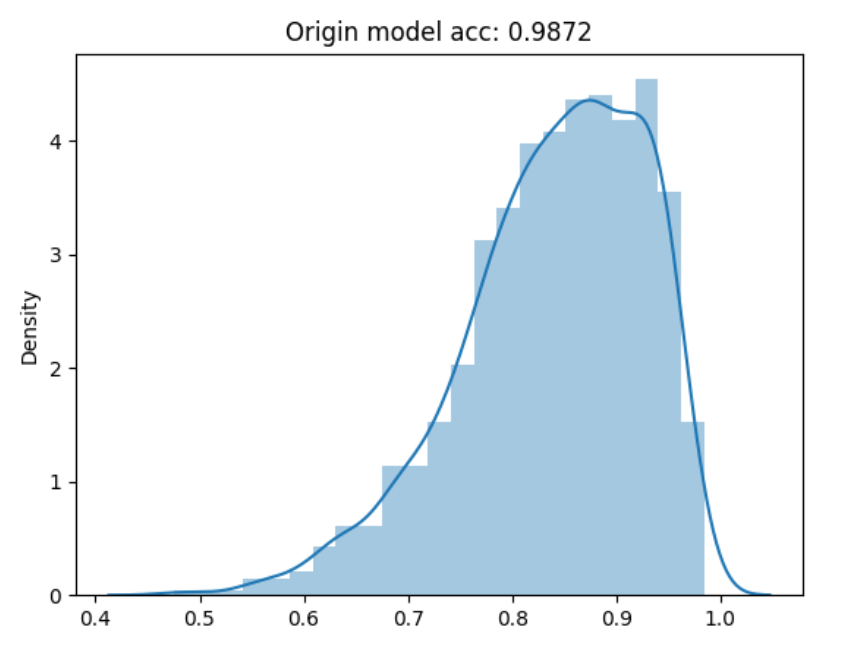
2.分类别分布: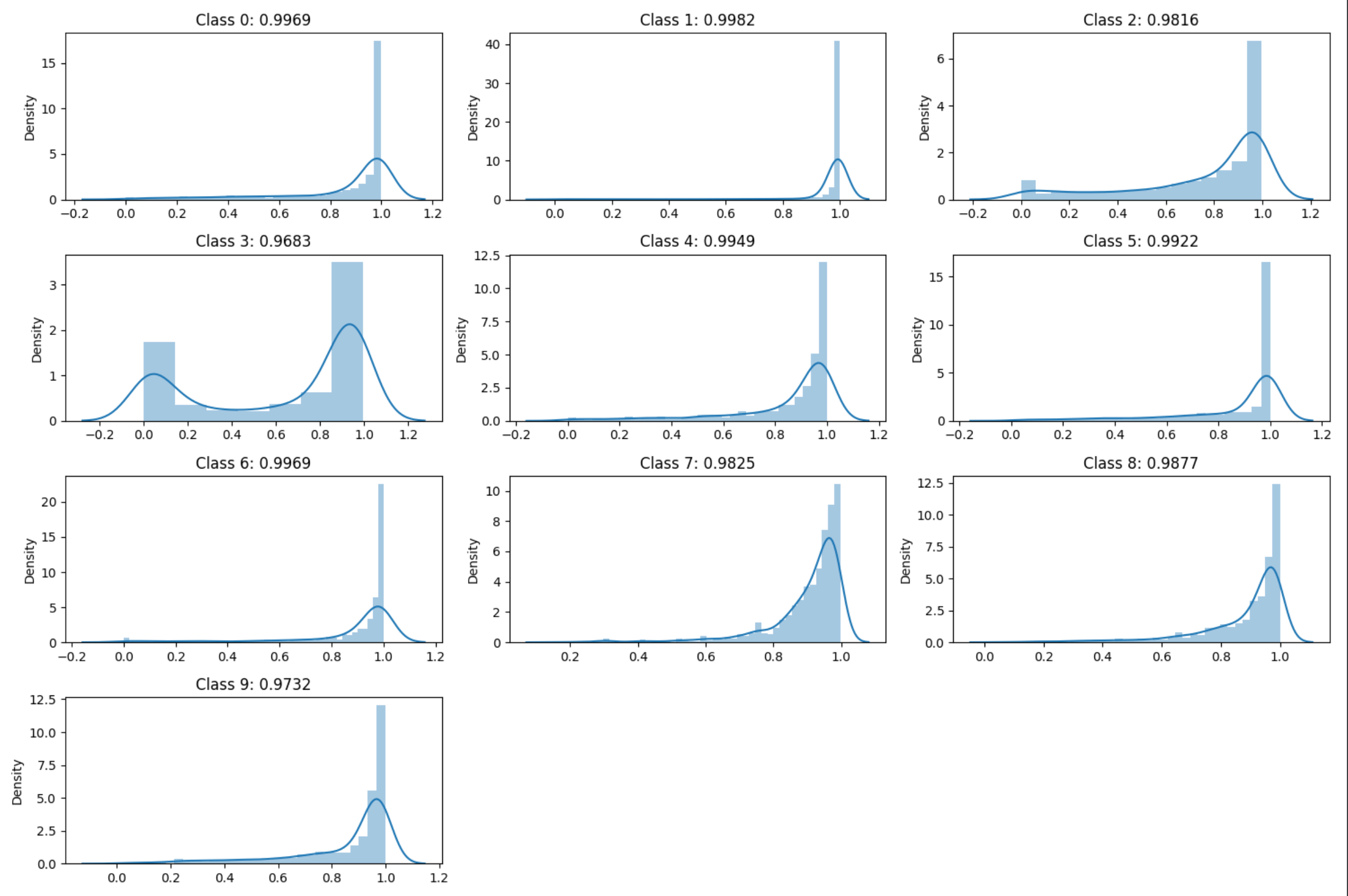
3.inputs 的kill_rate 分布: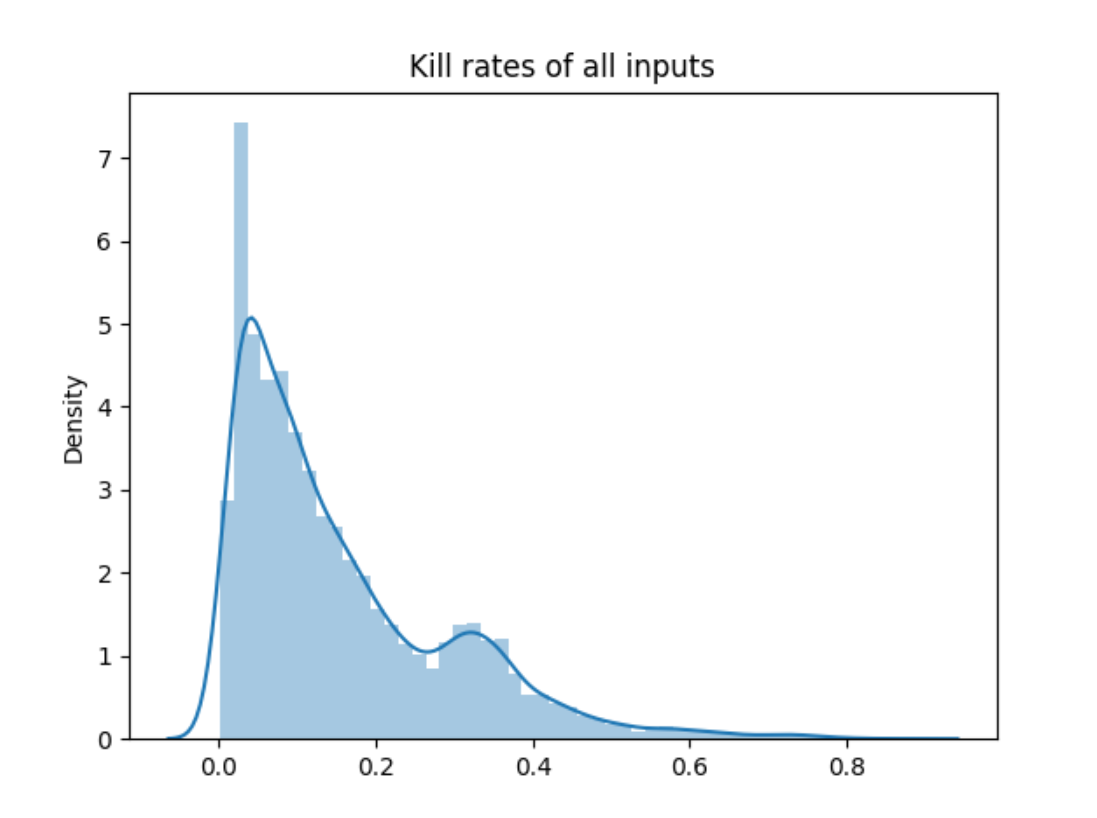
4.分别使用低方差滤波和SVD进行降维,以轮廓系数作为聚类评估依据。但是发现两者最后均只能聚成两类。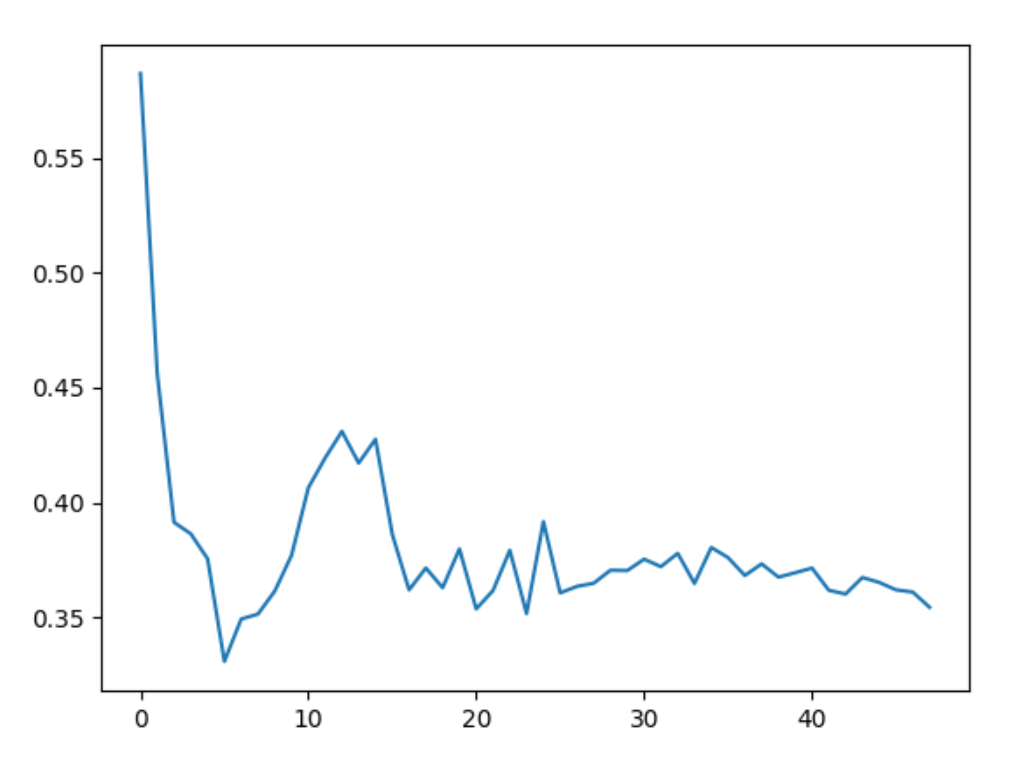
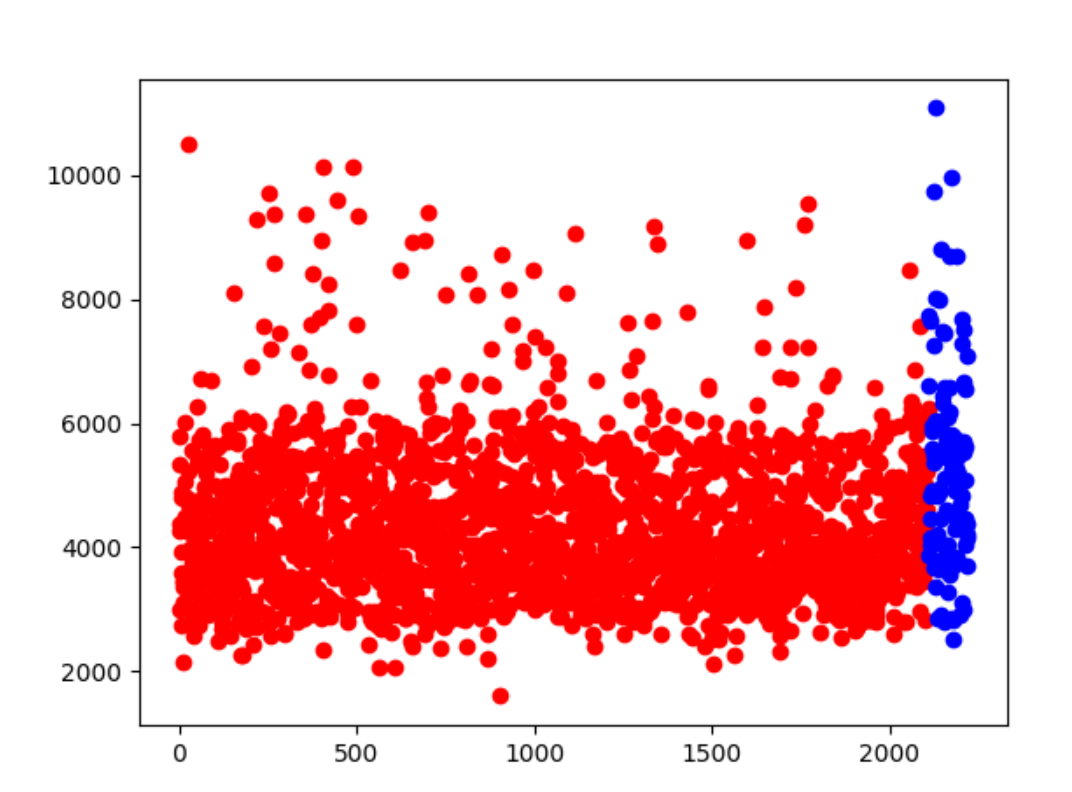
5.在这两类中,正负样本分布及其距离聚类中心的距离情况是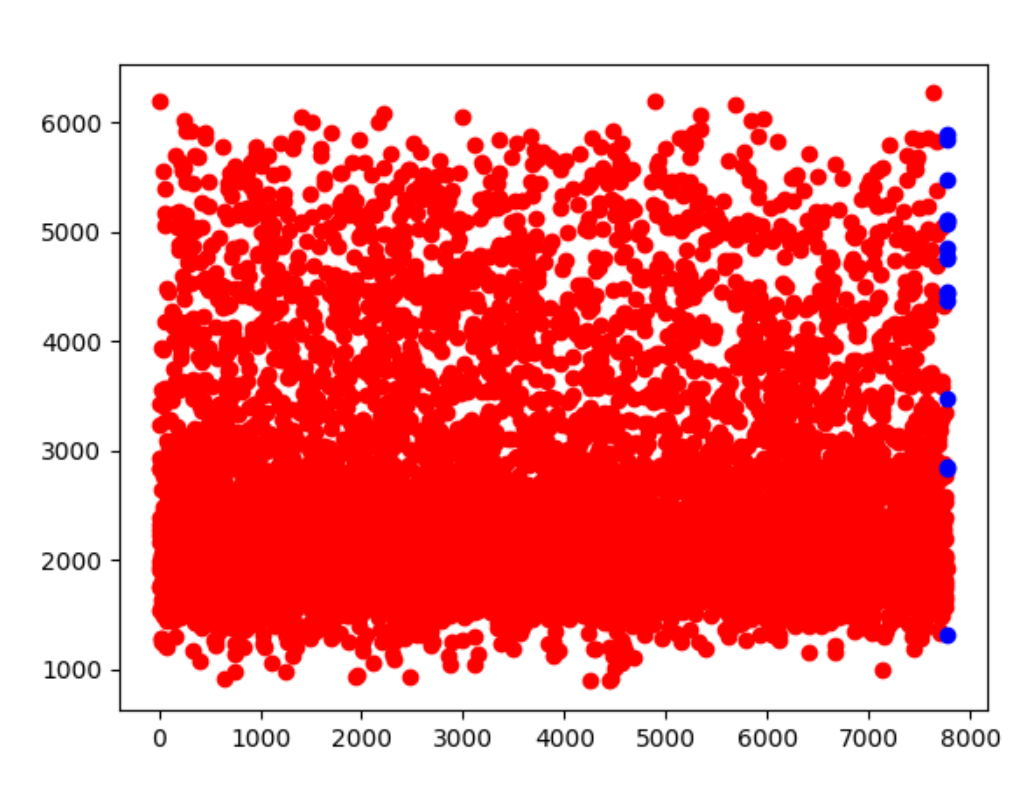
效果较好的K聚类情况(k=3):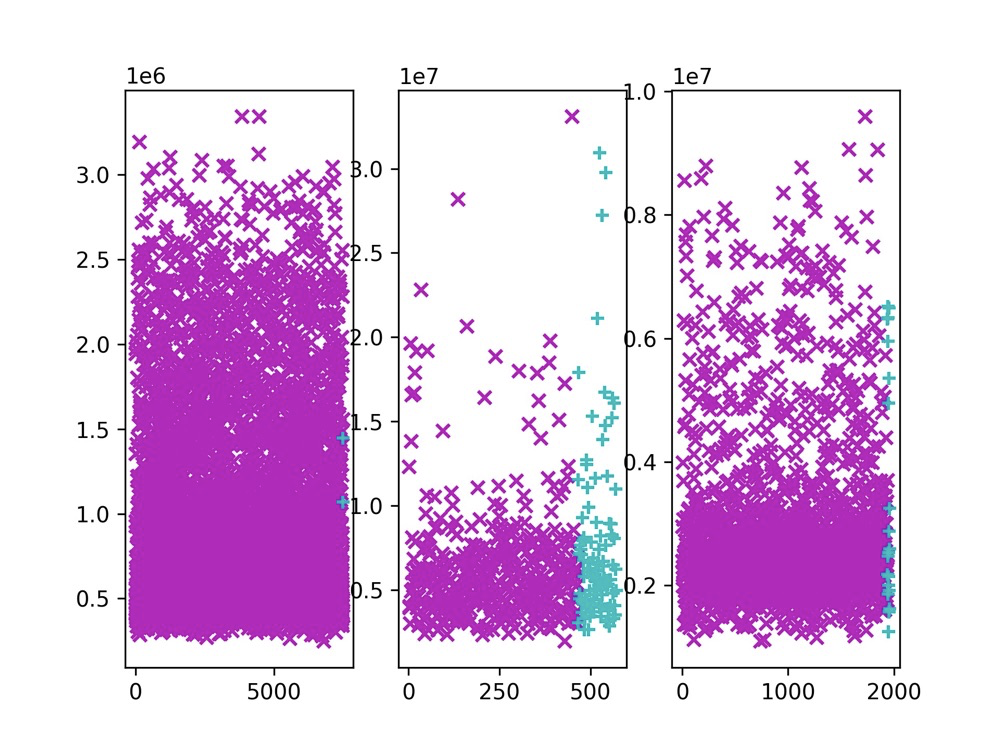
最后选取样本的时候就是根据选择的样本的个数在每个子路中拉一条水平线,选择这条水平线以下的样本,观察不出簇的个数即k与效果的规律。
现有结论与问题:
1.无论是之前随机扰动生成的模型,还是针对类重要神经元生成的模型,模型的精度分布还是测试用例kill_rate的分布都较为合理。
2.kill_rate对于正确/错误样本的区分起到了一定的作用,现在我们的方法之所以有效果应该也是由于kill_rate和label之间存在一定的相关性,但为什么效果迟迟没有大的起色,应该也是由于这个相关性还不够强。
如果专注于提升错误测试用例的kill_rate和正确测试用例的kill_rate的差值:
- 测试用例选择需要默认标签未知
- 受pcs值影响,提升这个差值非常困难
- 如果能提升这个差值,测试用例选择->测试用例排序

若有收获,就点个赞吧
0 人点赞
