- 有关selection中的retrain问题
ATS中的实验设置,将候选集均分成两份,一份用于从中选择样本,一份用于验证retrain的效果。
- 候选集的准确率较低,因为retrain之后有明显的效果提升,而如果我们仅仅将测试集作为候选集再取一半作为验证集,retrain的效果不升反降
- 如果依照ATS的实验设置,使用同样的候选集,我们方法的效果和random差不多
- 候选集的构造方法:使用七种常见的图像变化方式旋转、剪切等对原始图像进行变换并且重新获取标签(标签如果改变即为ER样本)。
- 分层抽样和其他采样方式结合起来,比如mmd(无法解释)
以mnist_lenet5为例,测试用例杀死变异模型数量的分布如下(考虑到并不一定都是等量分布,分层的时候并不一定要等分):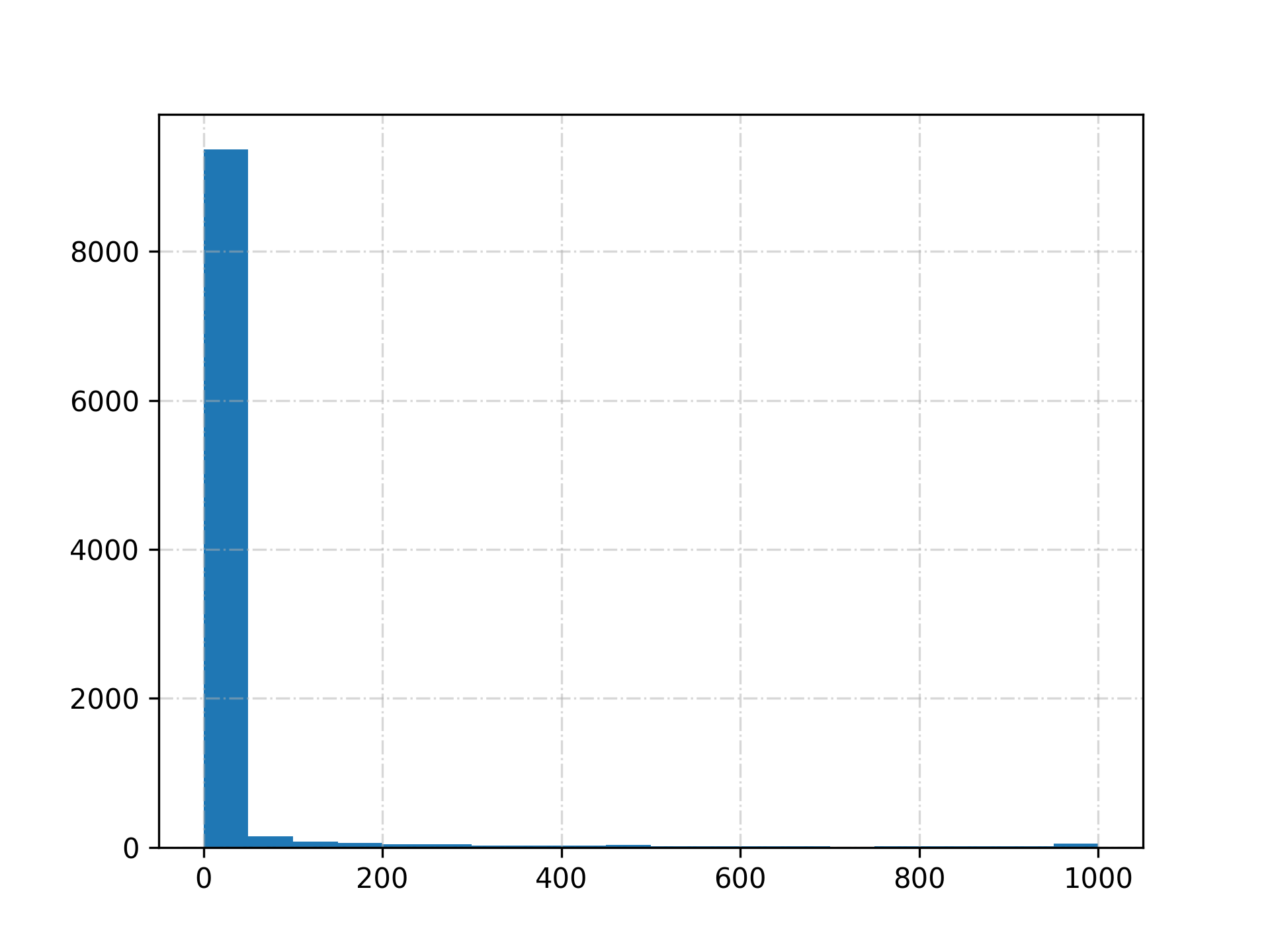
- 使用类似CES的拟合分布的方法的话需要更改测试用例的特征表示向量,但是要注意量纲的变化。
- 分类类别最后预测置信度的相对改变数值,例如(在变异模型上的置信度-在原模型上的置信度)/在原模型上的置信度(但依然不是概率的表现形式,不能直接套用CES的方法)
- SSOA:从无偏估计地角度出发随机采样从而证明在多次重复实验的情况下,SSOA的性能要优于SRS、CES、CSS和DeepEST
- 先将所有的测试用例分成几部分(依据预测标签的置信度,方法一:聚类;方法二:直接按照置信度排序然后分三步)
- 获得每一部分测试用例准确率的方差(方法一:training data;方法二:pre-sampling)
- 根据每一部分的方差确定从每个部分选择的测试用例的个数
- 最后从每个部分随机选择测试用例构成最终的测试子集

若有收获,就点个赞吧
0 人点赞
