1.扩大可选择的k的范围,看对于vgg16、resnet20等比较复杂的模型或者svhn等数据量比较大的样本,在k的上界增加到一定程度后是否能用轮廓系数选择出一个较为合适的k的同时效果也有一定程度的提升
将原来的10-50改为10-200
2.观察同样是使用onehot_refine_200_2000降维至100后的矩阵进行聚类,为什么fashion和svhn的效果不好,还是否是因为虽然同样是使用简单的模型—lenet5,如果需要处理的数据更复杂,是否需要减小模型的变异程度或者在其他方面做出调整。
mnist_lenet1、mnist_lenet4、mnist_lenet5、cifar10_vgg16、cifar10_resnet20使用onehot_refine的变异模型预测结果与原模型预测结果的差值的分布都大致和mnist_lenet5的差不多,随着差异越大,变异模型的个数越少,呈下降趋势。
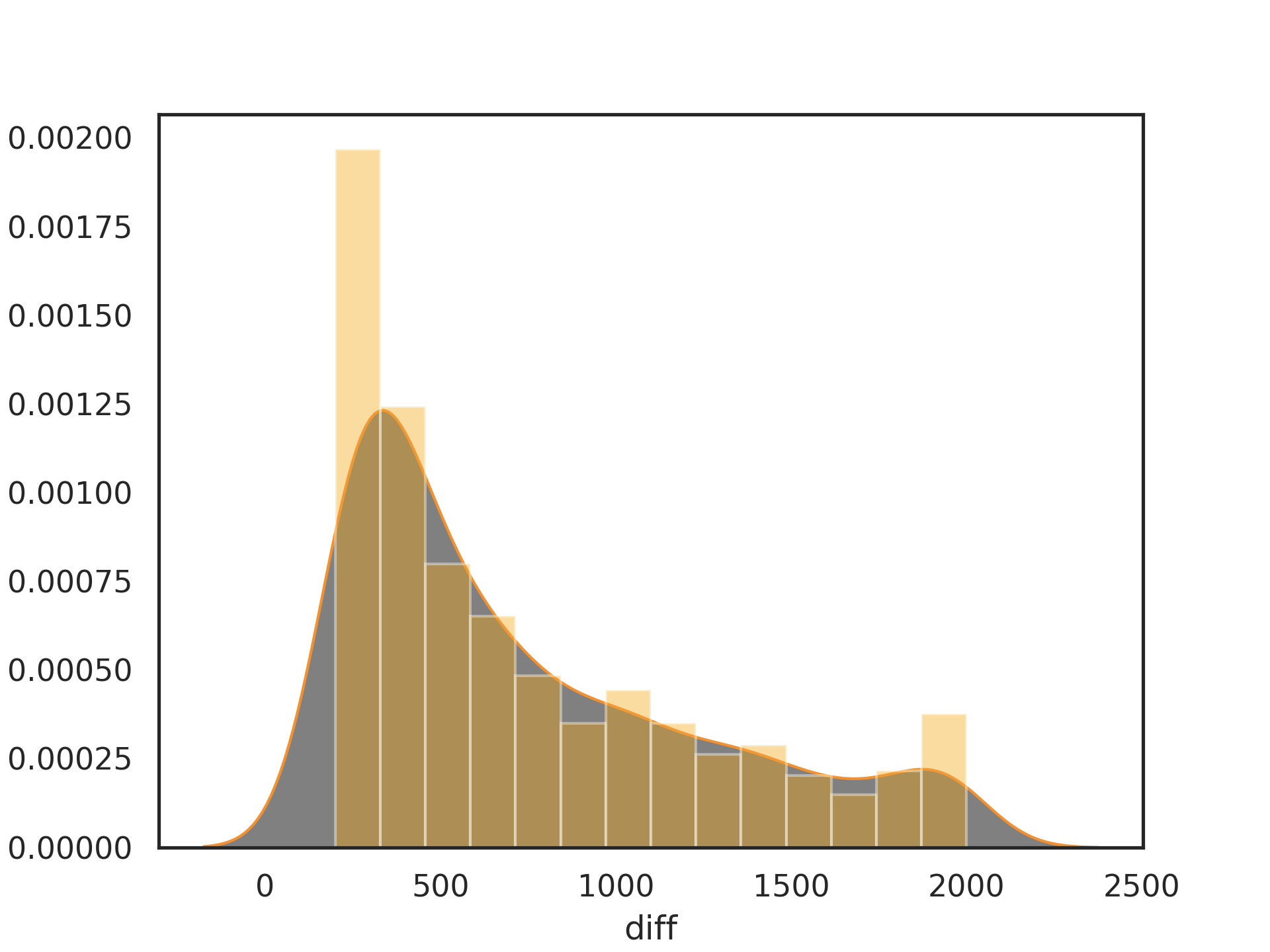
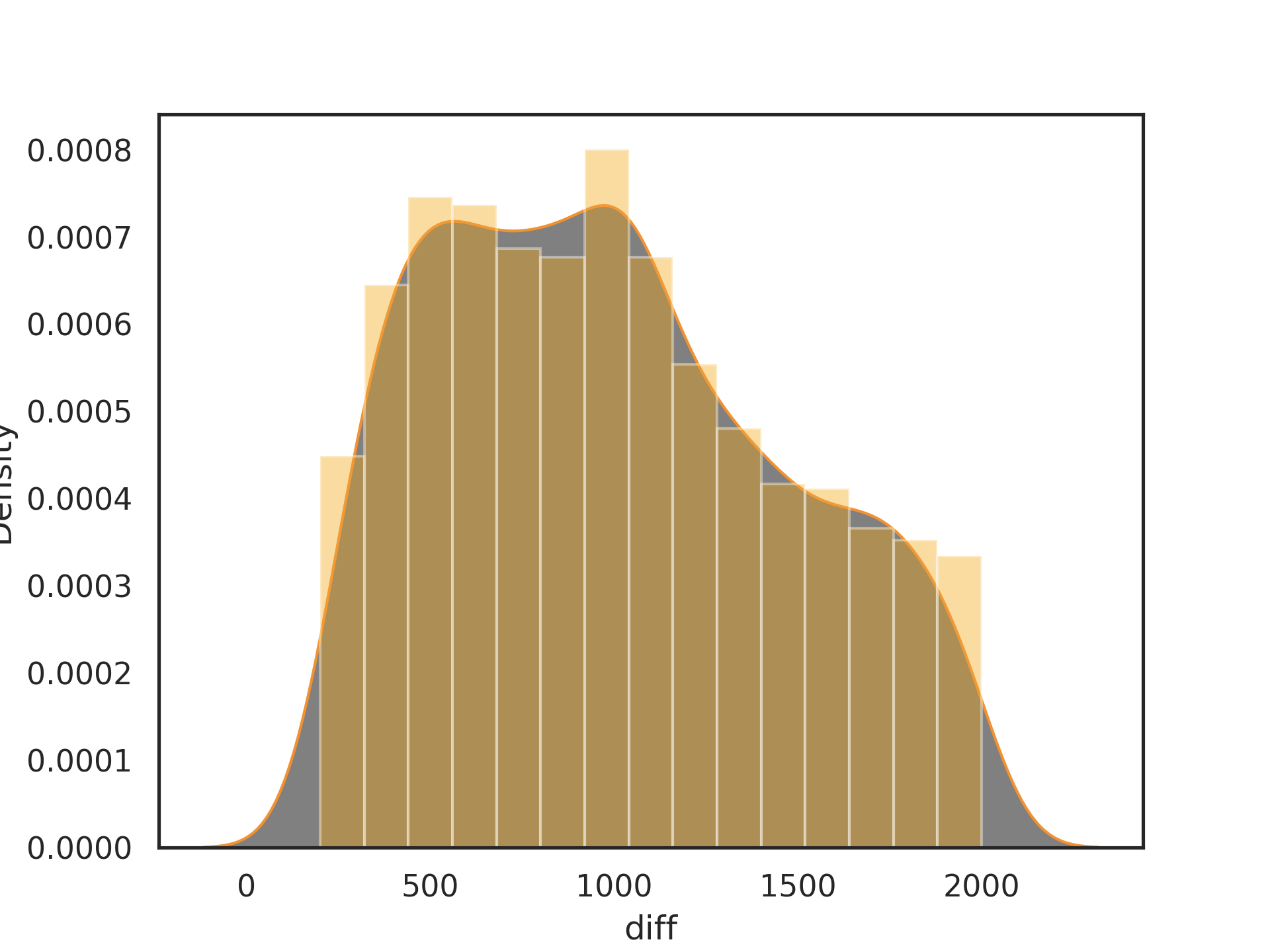

fashion svhn
重新生成一批svhn和fashion的变异模型,使得最后选取的模型尽量接近⬆️lenet5的分布,观察实验效果。
🌟之前同样以四个算子WS、GF、NAI、NEB在ratio 0.1 0.2 0.3 0.4 0.5的情况下生成共4000个模型,fashion_lenet5和svhn_lenet5生成的变异模型相较于mnist_lenet5的变异模型精度下降地较多
在选择用于聚类的变异模型时需要考虑:
1.原模型的精度(mnist_lenet5的acc为0.9872而fashion_lenet5的acc只有0.8988)
2.数据集的大小,因为方法中不能使用数据的label,因此在选择变异模型的时候依据的是变异模型预测结果与原模型预测结果的差异,这个差异的范围需要根据数据集的大小进行调整或者以百分比指定范围(svhn的测试集大小为26032,而mnist的测试集大小为10000)
3.生成的模型,因此虽然在同样的设置下生成变异模型,但其存在随机性,这个可以用生成的角度再去仔细考虑
/test/fashion_svhn/fashion_lenet5_refine1.npy✅
是在原本onehot_refine_0_2000的基础上0-500每100的范围内至多取200个,500-1000每100的范围内至多取100个,1000-1500每100的范围内至多取50个,1500-2000每100的范围内至多取20个
/test/fashion_svhn/svhn_lenet5_refine1.npy❌
是在原本combined_onehot的基础上0-1000每200的范围内至多取200个,1000-2000每200的范围内至多取100个,2000-3000每200的范围内至多取50个,3000-4000每200的范围内至多取20个
/test/fashion_svhn/svhn_lenet5_refine2.npy✅
是在原本onehot_refine_0_2000的基础上0-500每100的范围内至多取200个,500-1000每100的范围内至多取100个,1000-1500每100的范围内至多取50个,1500-2000每100的范围内至多取20个
/test/fashion_svhn/svhn_lenet5_refine3.npy✅
是两次combined_prediction共8000个模型的基础上去重 0-500每100的范围内至多取200个,500-1000每100的范围内至多取100个,1000-1500每100的范围内至多取50个,1500-2000每100的范围内至多取20个
/test/fashion_svhn/fashion_lenet5_refine3.npy✅
是两次combined_prediction共8000个模型的基础上去重 0-500每100的范围内至多取200个,500-1000每100的范围内至多取100个,1000-1500每100的范围内至多取50个,1500-2000每100的范围内至多取20个

若有收获,就点个赞吧
0 人点赞
