什么是训练量化
与离线量化不同,训练量化需要在训练中模拟量化操作的影响,并通过训练使得模型学习并适应量化操作所带来的误差,从而提高量化的精度。因此训练量化也称为Quantization-aware Training(QAT),意指训练中已经意识到此模型将会转换成量化模型。
如何在MNN中使用训练量化
已经通过其他训练框架如TensorFlow、Pytorch等训练得到一个float模型,此时可以通过先将此float模型通过MNNConverter转换为MNN统一的模型格式,然后使用MNN提供的离线量化工具直接量化得到一个全int8推理模型。如果此模型的精度不满足要求,则可以通过训练量化来提高量化模型的精度。
使用步骤:
- 首先通过其他训练框架训练得到原始float模型;
- 编译MNNConverter模型转换工具;
- 使用MNNConverter将float模型转成MNN统一格式模型,因为要进行再训练,建议保留BN,Dropout等训练过程中会使用到的算子,这可以通过MNNConverter的 —forTraining 选项实现;
- 参考MNN_ROOT/tools/train/source/demo/mobilenetV2Train.cpp 中的 MobilenetV2TrainQuant demo来实现训练量化的功能,下面以MobilenetV2的训练量化为例,来看一下如何读取并将模型转换成训练量化模型
- 观察准确率变化,代码保存下来的模型即为量化推理模型 ```cpp // mobilenetV2Train.cpp
// 读取转换得到的MNN float模型 auto varMap = Variable::loadMap(argv[1]); if (varMap.empty()) { MNN_ERROR(“Can not load model %s\n”, argv[1]); return 0; } // 指定量化比特数 int bits = 8; if (argc > 6) { std::istringstream is(argv[6]); is >> bits; } if (1 > bits || bits > 8) { MNN_ERROR(“bits must be 2-8, use 8 default\n”); bits = 8; } // 获得模型的输入和输出 auto inputOutputs = Variable::getInputAndOutput(varMap); auto inputs = Variable::mapToSequence(inputOutputs.first); auto outputs = Variable::mapToSequence(inputOutputs.second);
// 扫描整个模型,并将inference模型转换成可训练模型,此时得到的模型是可训练的float模型
std::shared_ptr
<a name="E73VK"></a># MNN训练量化原理MNN训练量化的基本原理如下图所示<br />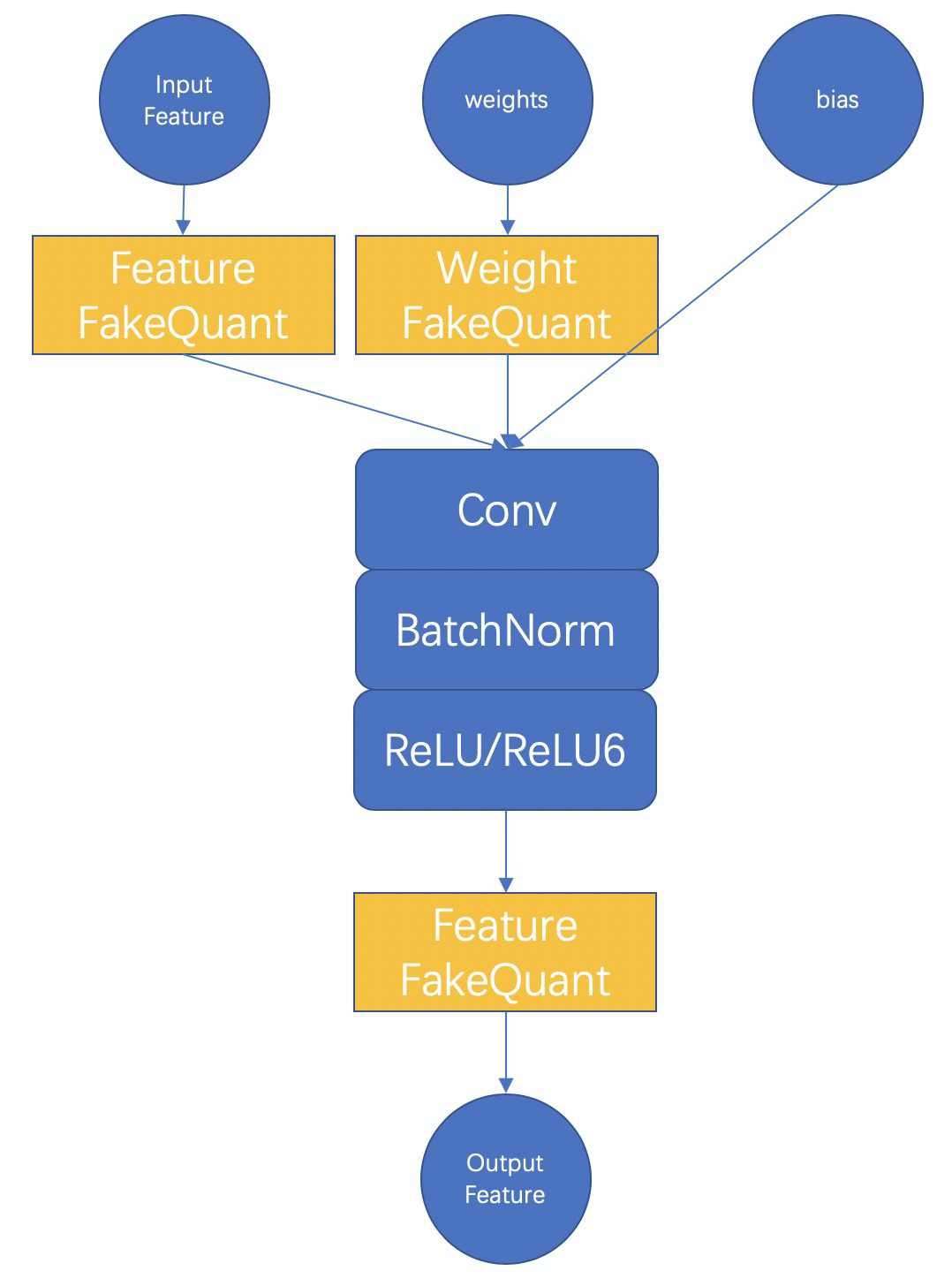<br />以int8量化为例,首先要理解全int8推理的整个过程,全int8推理,即feature要量化为int8,weight和bias也要量化为int8,输出结果可以是float或者是int8,视该卷积模块的后面一个op的情况而定。而训练量化的本质就是在训练的过程中去模拟量化操作的影响,借由训练来使得模型学习并适应这种影响,以此来提高最后量化模型的准确率。<br />因此在两种 FakeQuant 模块中,我们的主要计算为<br />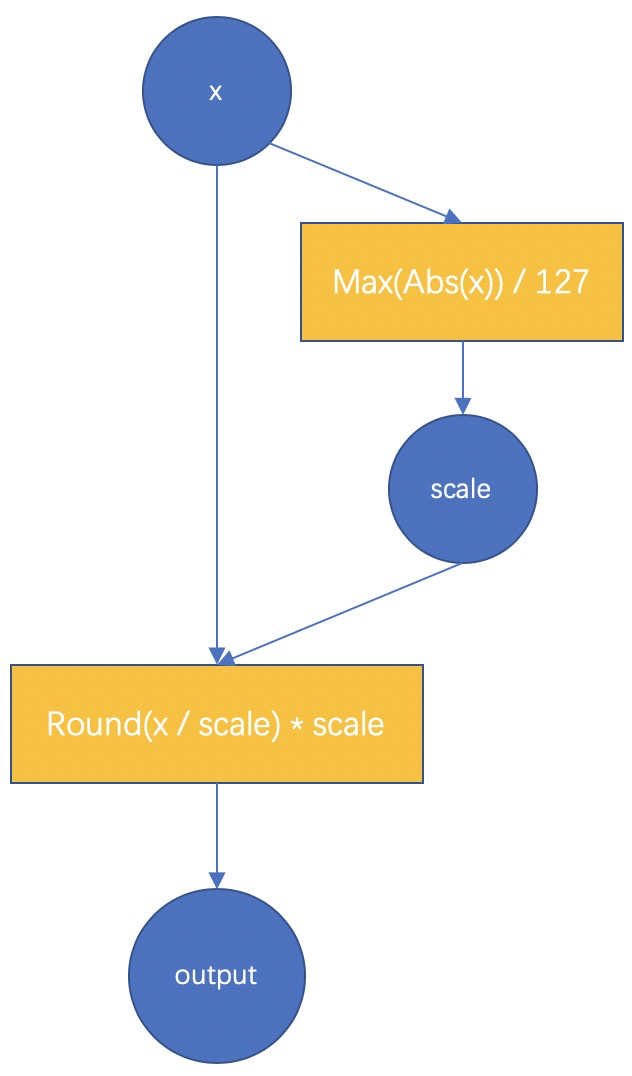<br />对于权值和特征的fake-quant基本都和上图一致,不一样的是对于特征由于其范围是随输入动态变化的,而最终int8模型中必须固定一个对于输入特征的scale值,所以,我们对每一此前向计算出来的scale进行了累积更新,例如使用滑动平均,或者直接取每一次的最大值。对于权值的scale,则没有进行平均,因为每一次更新之后的权值都是学习之后的较好的结果,没有状态保留。<br />此外,对于特征,我们提供了分通道(PerChannel)或者不分通道(PerTensor)的scale统计方法,可根据效果选择使用。对于权值,我们则使用分通道的量化方法,效果较好。上述是在训练中的training阶段的计算过程,在test阶段,我们会将BatchNorm合进权值,使用训练过程得到的特征scale和此时权值的scale(每次重新计算得到)对特征和权值进行量化,并真实调用MNN中的 _FloatToInt8 和 _Int8ToFloat 来进行推理,以保证测试得到的结果和最后转换得到的全int8推理模型的结果一致。最后保存模型的时候会自动保存test阶段的模型,并去掉一些冗余的算子,所以直接保存出来即是全int8推理模型。<a name="twKi8"></a># 训练量化结果目前我们在Lenet,MobilenetV2,以及内部的一些人脸模型上进行了测试,均取得了不错的效果,下面给出MobilenetV2的一些详细数据| | 准确率 / 模型大小 || --- | --- || 原始float模型 | 72.324% / 13M || MNN训练量化int8模型 | 72.456% / 3.5M || TF训练量化int8模型 | 71.1% / 3.5M (原始 71.8% / 13M) |上述数据是使用batchsize为32,训练100次迭代得到的,即仅使用到了3200张图片进行训练量化,在ImageNet验证集5万张图片上进行测试得到。可以看到int8量化模型的准确率甚至比float还要高一点,而模型大小下降了73%,同时还可以得到推理速度上的增益。【注】此处使用到的float模型为TensorFlow官方提供的模型,但官方给出的准确率数据是71.8%,我们测出来比他们要高一点,原因是因为我们使用的预处理代码上有细微差别所致。<a name="mMwAl"></a># 使用训练量化的一些建议1. 模型转换时保留BatchNorm和Dropout等训练中会用到的算子,这些算子对训练量化也有帮助1. 要使用原始模型接近收敛阶段的训练参数,训练参数不对,将导致训练量化不稳定1. 学习率要调到比较小1. 我们仅对卷积层实现了训练量化,因此如果用MNN从零开始搭建模型,后期接训练量化,或者Finetune之后想继续训练量化,那么需要用卷积层来实现全连接层即可对全连接层也进行训练量化。示例代码如下```cpp// 用卷积层实现输入1280,输出为4的全连接层NN::ConvOption option;option.channel = {1280, 4};mLastConv = std::shared_ptr<Module>(NN::Conv(option));
训练量化的配置选项
详见 MNN_ROOT/tools/train/source/module/PipelineModule.hpp
// 特征scale的计算方法enum FeatureScaleStatMethod {PerTensor = 0, // 对特征不分通道进行量化PerChannel = 1 // 对特征分通道进行量化,deprecated};// 特征scale的更新方法enum ScaleUpdateMethod {Maximum = 0, // 使用每一次计算得到的scale的最大值MovingAverage = 1 // 使用滑动平均来更新};// 指定训练量化的bit数,特征scale的计算方法,特征scale的更新方法,void toTrainQuant(const int bits = 8, NN::FeatureScaleStatMethod featureScaleStatMethod = NN::PerTensor,NN::ScaleUpdateMethod scaleUpdateMethod = NN::MovingAverage);

若有收获,就点个赞吧
0 人点赞
