MQ(消息队列)在软件架构中是经常被使用的,特别是在分布式系统中也是使用频率很高的组件。
以下从消息队列的使用场景、概念、常见问题及解决方案来详细讲解。
1. 消息队列使用场景
1.1 常见的使用场景
系统解耦
在分布式环境下,系统间的相互依赖,最终会会导致整个依赖关系混乱,特别在微服务环境下,会出现相互依赖,甚至是循环依赖的情况,对后期系统的拆分和优化都带来极大负担。那么我们就可以用MQ来进行处理。上游系统将数据投递到MQ,下游系统取MQ的数据进行消费,投递和消费可以用同步的方式处理,因为MQ接收数据的性能是非常高的,不会影响上游系统的性能。
异步处理
如果采用同步的方式,系统的性能(并发量,吞吐量,响应时间)会有瓶颈。如何解决这个问题呢?引入消息队列,将不必要的业务逻辑异步处理。
异步处理也可以引来 并行处理 的使用姿势。在工作中,我们基于消息开发了一个简单的分布式任务处理组件。该组件简单分为三块分别是 切分、加载、执行三个阶段.
每个阶段都是以作为消费者,然后处理完毕后再作为生产者发送消息。消息消费无状态,可以按需无限拓容。
流量削峰
由于使用消息,我们的链路变成了生产者发送消息,消息中间件存储消息,最后消费者从消息中间件拉取消息的一个过程。而消息中间件的存储能力能够有效的帮助消费者进行缓冲。试想下,正常流量下消费者能够愉快的进行消费,瞬时高峰流量来的时候,消费者消费能力跟不上,刚好阻塞在消息中间件,等峰值过后,消费者又能很快的将阻塞的消息进行消费。
流量削锋也是消息队列中的常用场景,一般在秒杀或团抢活动中使用广泛!
数据分发
大部分开源的MQ中间件基本都支持一对多或者广播的模式,而且都可以根据规则选择分发的对象。这样上游的一份数据,众多下游系统中,可以根据规则选择是否接收这些数据,这样扩展性就很强了。
1.2 消息使用的先决条件
以上四种是MQ中间件最常见的场景,但是我们细想,MQ中间件的引入会带来什么问题呢?那就是实时性。所以MQ中间件使用的先决条件是:能容忍延迟,只要求最终一致性较为合适。
2. 消息相关的概念
MQ特点
- 先进先出
不能先进先出,都不能说是队列了。消息队列的顺序在入队的时候就基本已经确定了,一般是不需人工干预的。而且,最重要的是,数据是只有一条数据在使用中。 这也是MQ在诸多场景被使用的原因。 - 发布订阅
发布订阅是一种很高效的处理方式,如果不发生阻塞,基本可以当做是同步操作。这种处理方式能非常有效的提升服务器利用率,这样的应用场景非常广泛。 - 持久化
持久化确保MQ的使用不只是一个部分场景的辅助工具,而是让MQ能像数据库一样存储核心的数据。 - 分布式
在现在大流量、大数据的使用场景下,只支持单体应用的服务器软件基本是无法使用的,支持分布式的部署,才能被广泛使用。而且,MQ的定位就是一个高性能的中间件。
在JMS标准中,有两种消息模型 P2P(Point toPoint)和 Publish/Sub(Pub/Sub)。**P2P**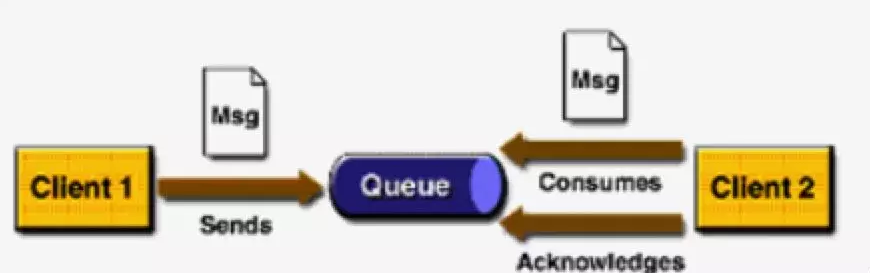
点对点,一个发,一个消费。涉及到的角色 发布者(Publisher)、消费者(Consumer)、消息队列(Queue)
特点
- 一个消息只能被一个消费者消费,消费后会从队列里移除
- 发布者和消费者无关系,发布者发送消息的行为不会随消费者而改变
- 消费者消费完成消息,需要向队列Ack,消息队列发现消息消费成功即做消息移除
**Pub/Sub**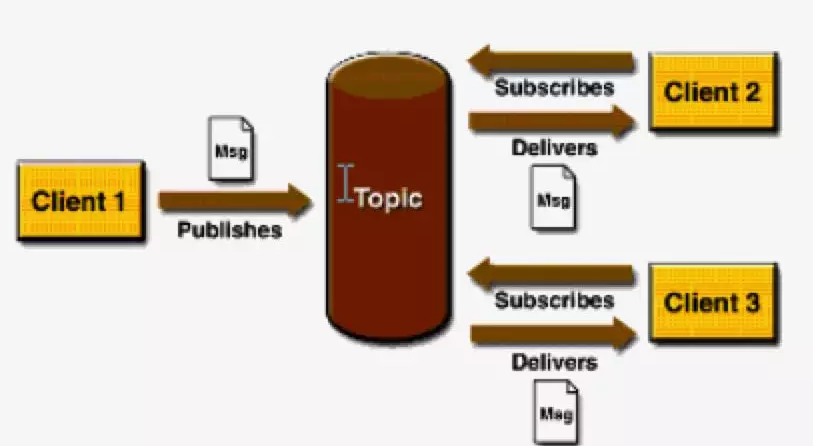
发布订阅模式,一个发布,多方订阅。涉及到的角色有 发布者(Publisher)、主题(Topic)、订阅者(Subscriber)。
特点
- 每个消息可以有多个消费者
- 针对某个主题(Topic)的订阅者,必须创建一个订阅者之后,才能消费发布者的消息
- 为了消费消息,订阅者必须保持运行的状态
3. 常见问题及解决方案
消息阻塞
1、消息阻塞一般都是流量激增,超过消费者消费能力;
2、或者消费者出现逻辑问题,导致不断的重试或长时间等待。
第一种可以通过扩容解决
第二种只能紧急修复问题,发布上线,在阻塞的过程中会造成大量的消息积压,这种情况也可以考虑临时扩容
重复消费
重复消费一般发生下消费端,比如消费者处理完毕,在准备进行ack的时候出现了问题,应用重启后,消息中间件以为该消息还未处理又推给了消费者,或者消费者拉取的时候重复。一般的做法是消费端做幂等。
消息丢失
消息丢失一般分为生产者发送失败、消息中间件丢失、消费丢失。
生产者丢失:可能以为网络问题或者消息中间处理失败导致,消息遗漏。
消息中间的丢失:一般中间件可以设置丢弃策略,大部分MQ中间件产品可以保证数据不丢失,这种情况基本不用考虑。
消费丢失:有的消息中间件支持自动ack,当消费者消费到消息,消息中间件也不管是否消费成功自动 ack。这时候一般选择消费者主动 ack 比较合适。
消息顺序性
消息顺序性一般通过MQ中间件保证,大部分MQ中间件只能做到局部有序,比如 Kafka,只能保证单个partition队列有序。有些也会做到全局有序,但是成本比较高。
4. 消息中间件对比
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 单机吞吐量 | 万级,吞吐量比RocketMQ和Kafka要低了一个数量级 | 万级,吞吐量比RocketMQ和Kafka要低了一个数量级 | 10万级,RocketMQ也是可以支撑高吞吐的一种MQ | 10万级别,这是kafka最大的优点,就是吞吐量高。 一般配合大数据类的系统来进行实时数据计算、日志采集等场景 |
| topic数量对吞吐量的影响 | topic可以达到几百,几千个的级别,吞吐量会有较小幅度的下降 这是RocketMQ的一大优势,在同等机器下,可以支撑大量的topic |
topic从几十个到几百个的时候,吞吐量会大幅度下降 所以在同等机器下,kafka尽量保证topic数量不要过多。如果要支撑大规模topic,需要增加更多的机器资源 |
||
| 时效性 | ms级 | 微秒级,这是rabbitmq的一大特点,延迟是最低的 | ms级 | 延迟在ms级以内 |
| 可用性 | 高,基于主从架构实现高可用性 | 高,基于主从架构实现高可用性 | 非常高,分布式架构 | 非常高,kafka是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
| 消息可靠性 | 有较低的概率丢失数据 | 经过参数优化配置,可以做到0丢失 | 经过参数优化配置,消息可以做到0丢失 | |
| 功能支持 | MQ领域的功能极其完备 | 基于erlang开发,所以并发能力很强,性能极其好,延时很低 | MQ功能较为完善,还是分布式的,扩展性好 | 功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用,是事实上的标准 |
| 优劣势总结 | 非常成熟,功能强大,在业内大量的公司以及项目中都有应用 偶尔会有较低概率丢失消息 而且现在社区以及国内应用都越来越少,官方社区现在对ActiveMQ 5.x维护越来越少,几个月才发布一个版本 而且确实主要是基于解耦和异步来用的,较少在大规模吞吐的场景中使用 |
erlang语言开发,性能极其好,延时很低; 吞吐量到万级,MQ功能比较完备 而且开源提供的管理界面非常棒,用起来很好用 社区相对比较活跃,几乎每个月都发布几个版本分 在国内一些互联网公司近几年用rabbitmq也比较多一些 但是问题也是显而易见的,RabbitMQ确实吞吐量会低一些,这是因为他做的实现机制比较重。 而且erlang开发,国内有几个公司有实力做erlang源码级别的研究和定制?如果说你没这个实力的话,确实偶尔会有一些问题,你很难去看懂源码,你公司对这个东西的掌控很弱,基本职能依赖于开源社区的快速维护和修复bug。 而且rabbitmq集群动态扩展会很麻烦,不过这个我觉得还好。其实主要是erlang语言本身带来的问题。很难读源码,很难定制和掌控。 |
接口简单易用,而且毕竟在阿里大规模应用过,有阿里品牌保障 日处理消息上百亿之多,可以做到大规模吞吐,性能也非常好,分布式扩展也很方便,社区维护还可以,可靠性和可用性都是ok的,还可以支撑大规模的topic数量,支持复杂MQ业务场景 而且一个很大的优势在于,阿里出品都是java系的,我们可以自己阅读源码,定制自己公司的MQ,可以掌控 社区活跃度相对较为一般,不过也还可以,文档相对来说简单一些,然后接口这块不是按照标准JMS规范走的有些系统要迁移需要修改大量代码 还有就是阿里出台的技术,你得做好这个技术万一被抛弃,社区黄掉的风险,那如果你们公司有技术实力我觉得用RocketMQ挺好的 |
kafka的特点其实很明显,就是仅仅提供较少的核心功能,但是提供超高的吞吐量,ms级的延迟,极高的可用性以及可靠性,而且分布式可以任意扩展 同时kafka最好是支撑较少的topic数量即可,保证其超高吞吐量 而且kafka唯一的一点劣势是有可能消息重复消费,那么对数据准确性会造成极其轻微的影响,在大数据领域中以及日志采集中,这点轻微影响可以忽略 这个特性天然适合大数据实时计算以及日志收集 |
总结:
- 业务量不大的情况下,首选 rabbitMq 延迟小,吞吐量也可以,mq功能完善;
- 对吞吐量有一定的要求首选 RocketMq,经过双十一大业务量的考验,java 开发,对扩展开发都比较友好;,同等资源,支持更多的 topic;
- 涉及到大数据量的实时数据计算、日志采集等场景使用 kafka;

若有收获,就点个赞吧
0 人点赞
