参考 zookeeper
zookeeper 可以做什么?
在现代的分布式应用中,往往会出现节点和节点之间的协调问题,其中就包括了:选主、集群管理、分布式锁、分布式配置管理、统一命名服务、状态同步。
解决分布式集群中,应用系统的一致性问题。提供类似文件系统目录节点树方式的 数据存储,用以维护和监控存储数据的状态变化。通过监控数据状态的变化,基于数据的变化进行集群管理。
数据结构
zookeeper 会维护一个具有层次关系的数据结构,非常类似一个文件系统。
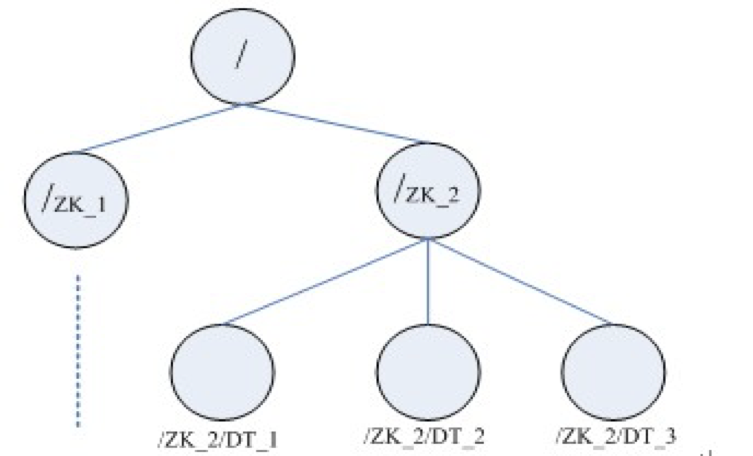
每一个节点(Znode)可以看作是一个文件,也可以看作是一个目录。
Znode 节点有三种类型:
- 临时节点(EPHEMERAL):session 过期自动删除;
- 持久化节点:持久化到硬盘;
- 有序节点(SEQUENCE):包括临时节点和有序节点两种类型;
Znode维护着数据、ACL(access control list,访问控制列表)、时间戳等交换版本号等数据结构,它通过对这些数据的管理来让缓存生效并且令协调更新。每当Znode中的数据更新后它所维护的版本号将增加,这非常类似于数据库中计数器时间戳的操作方式。另外Znode还具有原子性操作的特点:命名空间中,每一个Znode的数据将被原子地读写。读操作将读取与Znode相关的所有数据,写操作将替换掉所有的数据。除此之外,每一个节点都有一个访问控制列表,这个访问控制列表规定了用户操作的权限。
Zookeeper 约定
Guarantees
ZooKeeper is very fast and very simple. Since its goal, though, is to be a basis for the construction of more complicated services, such as synchronization, it provides a set of guarantees. These are:
- Sequential Consistency - Updates from a client will be applied in the order that they were sent.
- Atomicity - Updates either succeed or fail. No partial results.
- Single System Image - A client will see the same view of the service regardless of the server that it connects to.
- Reliability - Once an update has been applied, it will persist from that time forward until a client overwrites the update.
- Timeliness - The clients view of the system is guaranteed to be up-to-date within a certain time bound.

事件监听

Leader选举
ZooKeeper 需要在所有的服务(可以理解为服务器)中选举出一个 Leader ,然后让这个 Leader 来负责管理集群。此时,集群中的其它服务器则成为此 Leader 的 Follower 。并且,当 Leader 故障的时候,需要ZooKeeper 能够快速地在 Follower 中选举出下一个 Leader 。这就是 ZooKeeper 的 Leader 机制,下面我们将简单介绍在 ZooKeeper 中, Leader 选举( Leader Election )是如何实现的。
此操作实现的核心思想是:首先创建一个 EPHEMERAL 目录节点,例如“ /election ”。然后。每一个ZooKeeper 服务器在此目录下创建一个 SEQUENCE| EPHEMERAL 类型的节点,例如“ /election/n_ ”。在SEQUENCE 标志下, ZooKeeper 将自动地为每一个 ZooKeeper 服务器分配一个比前一个分配的序号要大的序号。此时创建节点的 ZooKeeper 服务器中拥有最小序号编号的服务器将成为 Leader 。
**
在实际的操作中,还需要保障:当 Leader 服务器发生故障的时候,系统能够快速地选出下一个 ZooKeeper服务器作为 Leader 。一个简单的解决方案是,让所有的 follower 监视 leader 所对应的节点。当 Leader 发生故障时, Leader 所对应的临时节点将会自动地被删除,此操作将会触发所有监视 Leader 的服务器的 watch 。这样这些服务器将会收到 Leader 故障的消息,并进而进行下一次的 Leader 选举操作。但是,这种操作将会导致“从众效应”的发生,尤其当集群中服务器众多并且带宽延迟比较大的时候,此种情况更为明显。
在 Zookeeper 中,为了避免从众效应的发生,它是这样来实现的:每一个 follower 对 follower 集群中对应的比自己节点序号小一号的节点(也就是所有序号比自己小的节点中的序号最大的节点)设置一个 watch 。只有当follower 所设置的 watch 被触发的时候,它才进行 Leader 选举操作,一般情况下它将成为集群中的下一个Leader 。很明显,此 Leader 选举操作的速度是很快的。因为,每一次 Leader 选举几乎只涉及单个 follower 的操作。
应用场景
spring cloud + zk 实现 configServer 配置中心;
elastic-job = quarz + zookeeper;
dubbo rpc 框架使用 zookeeper 作为服务注册中心;
配置管理
将配置发布到 zk 节点,供订阅者动态获取数据,实现配置文件的集中式管理、动态更新。例如:全局的配置信息,地址列表;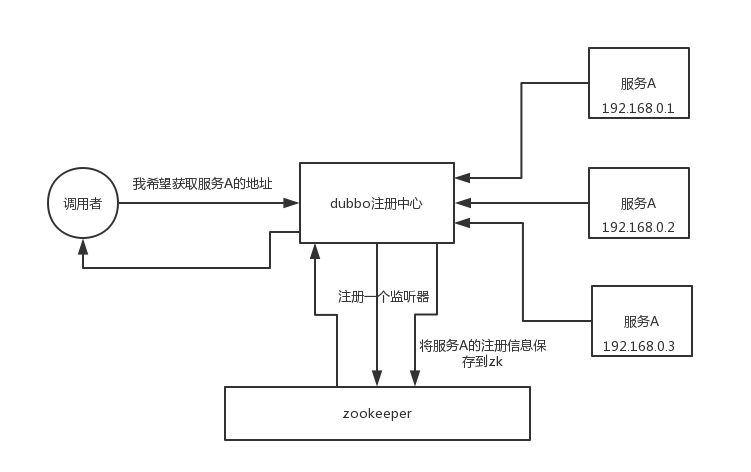
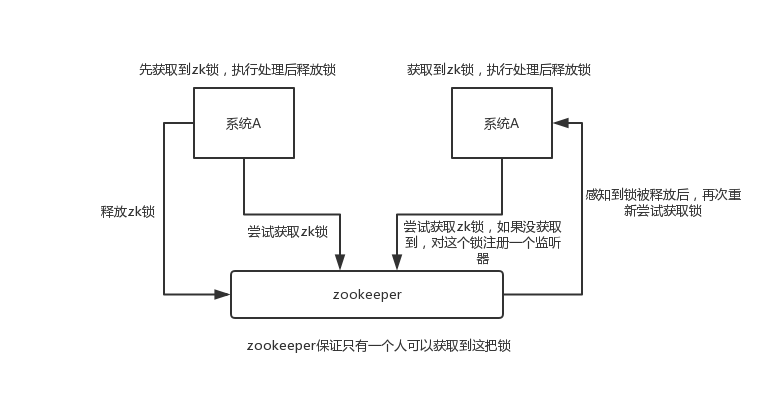
分布式锁
HA高可用性
比如 hadoop、hdfs、yarn 等很多大数据系统,都选择基于 zookeeper 来开发 HA 高可用机制,就是一个重要进程一般会做主备两个,主进程挂了立马通过 zookeeper 感知到切换到备用进程。
一般会起两个进程,先启动的进程会首先获取锁,成功启动,后面启动的进程会一直等待锁,如果先启动的进程挂了,zk会触发回调方法,等待的进程会获取锁,启动对外提供服务。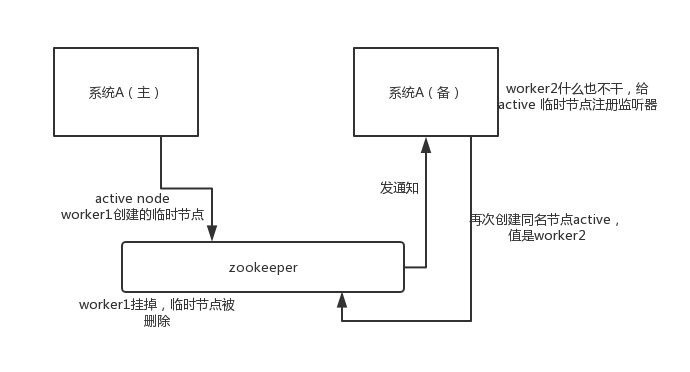

若有收获,就点个赞吧
0 人点赞
