分布式系统最基本的思维方式是去中心化把大的计算任务分而治之; 无论是数据库后期的扩展还是分布式任务调度扩展,都是通过集群去提高系统的算力。
elastic-job
官网:官网链接
elastic底层的任务调度还是使用的 quartz, 通过 zookeeper来动态给 job节点分片;
**
功能
a) 分布式:重写Quartz基于数据库的分布式功能,改用Zookeeper实现注册中心。
b) 并行调度:采用任务分片方式实现。将一个任务拆分为n个独立的任务项,由分布式的服务器并行执行各自分配到的分片项。
c) 弹性扩容缩容:将任务拆分为n个任务项后,各个服务器分别执行各自分配到的任务项。一旦有新的服务器加入集群,或现有服务器下线,elastic-job将在保留本次任务执行不变的情况下,下次任务开始前触发任务重分片。
d) 集中管理:采用基于Zookeeper的注册中心,集中管理和协调分布式作业的状态,分配和监听。外部系统可直接根据 Zookeeper 的数据管理和监控 elastic-job。
e) failover 失效转移:弹性扩容缩容在下次作业运行前重分片,但本次作业执行的过程中,下线的服务器所分配的作业将不会重新被分配。失效转移功能可以在本次作业运行中用空闲服务器抓取孤儿作业分片执行。同样失效转移功能也会牺牲部分性能。
架构
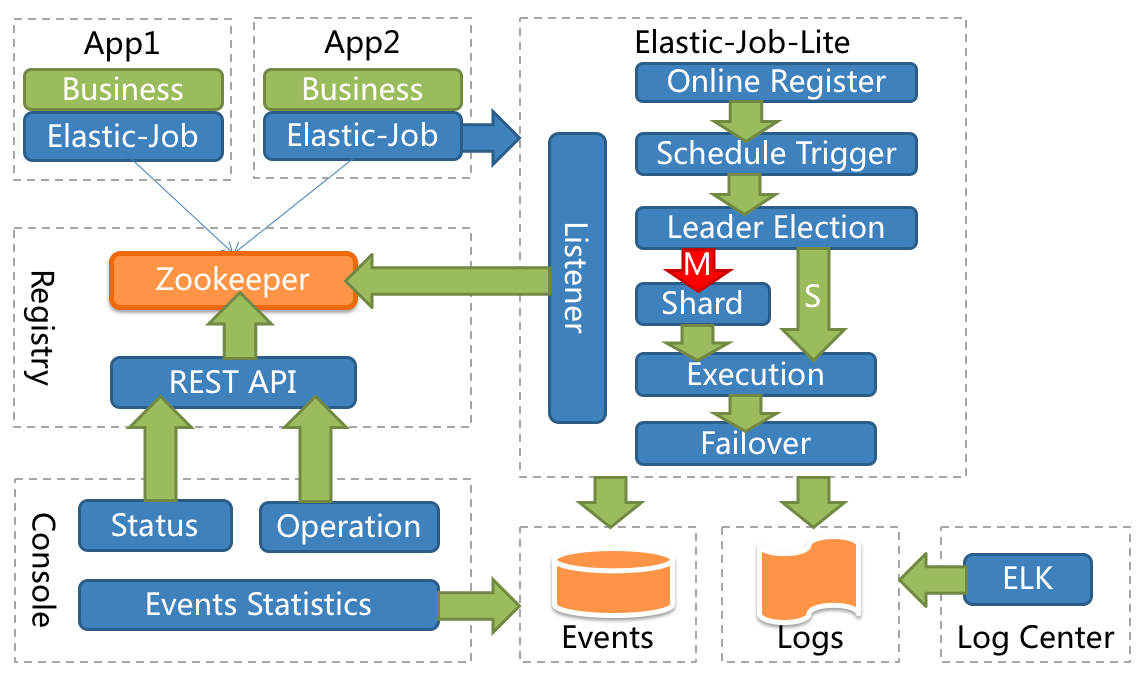
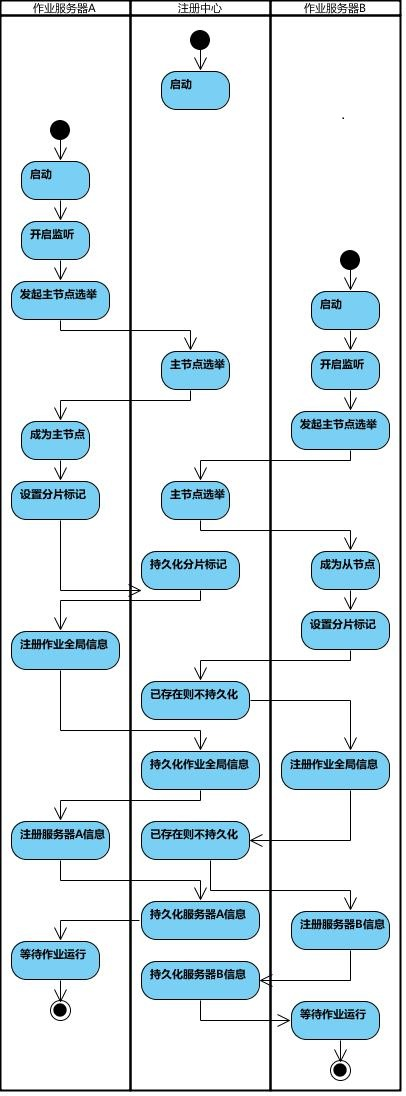
作业启动
应用服务器启动时,向 zk 注册服务
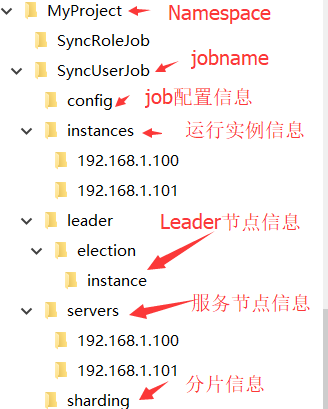
zk 中的结构如下:
config 存储 job 配置 json信息:
{"jobName":"com.alibaba.fota.job.SimpleJobDemo","jobClass":"com.alibaba.fota.job.SimpleJobDemo","jobType":"SIMPLE","cron":"0/1 * * * * ?","shardingTotalCount":1,"shardingItemParameters":"0=A","jobParameter":"parameter","failover":false,"misfire":true,"description":"","jobProperties":{"job_exception_handler":"com.dangdang.ddframe.job.executor.handler.impl.DefaultJobExceptionHandler","executor_service_handler":"com.dangdang.ddframe.job.executor.handler.impl.DefaultExecutorServiceHandler"},"monitorExecution":true,"maxTimeDiffSeconds":-1,"monitorPort":-1,"jobShardingStrategyClass":"","reconcileIntervalMinutes":10,"disabled":false,"overwrite":true}
作业执行
作业执行由 quarz 触发
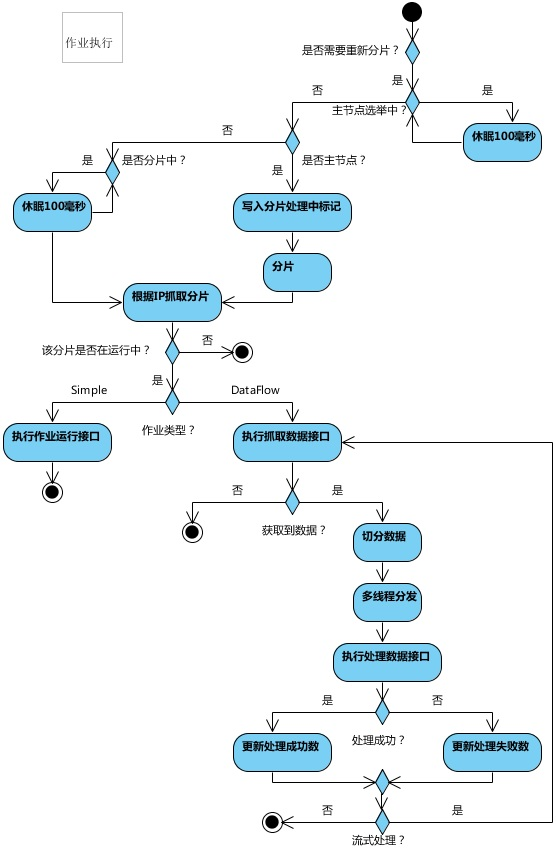
分片逻辑(核心)
1. 什么时候需要分片
- 通过 elastic-job 控制台修改 job 配置信息时;
- 作业服务器上下线时;
- 作业第一次启动;
2. 源码分析
作业启动会注册所有监听器
/*** 开启所有监听器.*/public void startAllListeners() {electionListenerManager.start();shardingListenerManager.start();failoverListenerManager.start();monitorExecutionListenerManager.start();shutdownListenerManager.start();triggerListenerManager.start();rescheduleListenerManager.start();guaranteeListenerManager.start();jobNodeStorage.addConnectionStateListener(regCenterConnectionStateListener);}
ShardingListenerManager.start() 注册了下面两个监听器:
ShardingTotalCountChangedJobListener: 分片数修改
ListenServersChangedJobListener :服务器数量变化
// 内存里的分片数与 zk config 节点里面的配置数量不一致class ShardingTotalCountChangedJobListener extends AbstractJobListener {@Overrideprotected void dataChanged(final String path, final Type eventType,final String data) {if (configNode.isConfigPath(path) && 0 != JobRegistry.getInstance().getCurrentShardingTotalCount(jobName)) {int newShardingTotalCount = LiteJobConfigurationGsonFactory.fromJson(data).getTypeConfig().getCoreConfig().getShardingTotalCount();if (newShardingTotalCount != JobRegistry.getInstance().getCurrentShardingTotalCount(jobName)) {// zk 上创建临时节点 nshardingService.setReshardingFlag();JobRegistry.getInstance().setCurrentShardingTotalCount(jobName, newShardingTotalCount);}}}}当新的分片节点加入或原的分片实例宕机后,需要进行重新分片。当${namespace}/jobname/servers或${namespace}/jobname/instances路径下的节点数量是否发生变化,如果检测到发生变化,设置需要重新分片标识。class ListenServersChangedJobListener extends AbstractJobListener {@Overrideprotected void dataChanged(final String path, final Type eventType,final String data) {if (!JobRegistry.getInstance().isShutdown(jobName)&& (isInstanceChange(eventType, path) || isServerChange(path))) {shardingService.setReshardingFlag();}}private boolean isInstanceChange(final Type eventType, final String path) {return instanceNode.isInstancePath(path) && Type.NODE_UPDATED != eventType;}private boolean isServerChange(final String path) {return serverNode.isServerPath(path);}}/*** 设置需要重新分片的标记.*/public void setReshardingFlag() {jobNodeStorage.createJobNodeIfNeeded(ShardingNode.NECESSARY);}
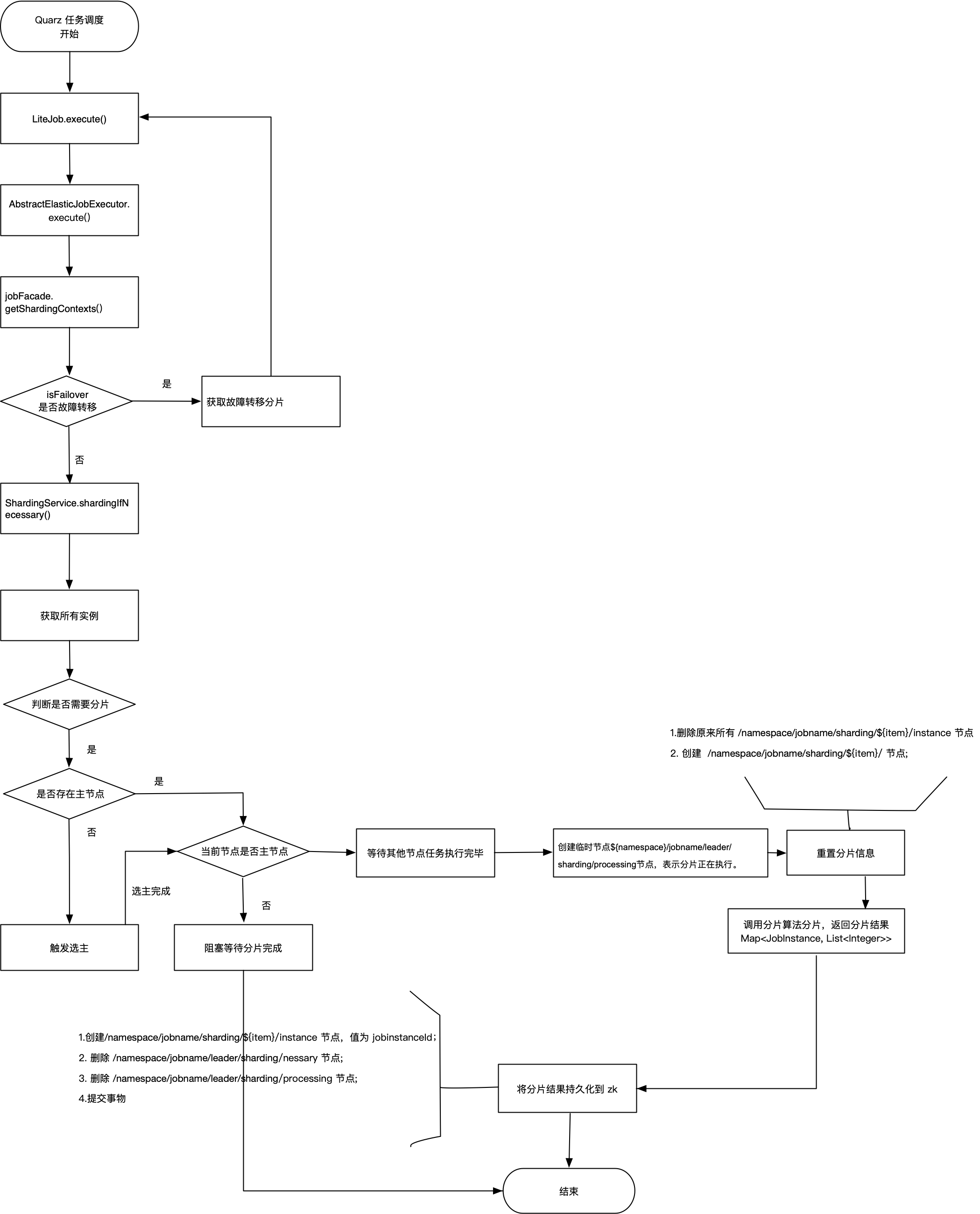
具体分片逻辑在定时任务调度每次调度时发生:
AbstractElasticJobExecutor.execute() 方法
ShardingContexts shardingContexts = jobFacade.getShardingContexts();
/**
* 执行作业
*/
public final void execute() {
try {
jobFacade.checkJobExecutionEnvironment();
} catch (final JobExecutionEnvironmentException cause) {
jobExceptionHandler.handleException(jobName, cause);
}
// 分片
ShardingContexts shardingContexts = jobFacade.getShardingContexts();
}
// 执行具体分片逻辑
public ShardingContexts getShardingContexts() {
boolean isFailover = configService.load(true).isFailover();
if (isFailover) {
List<Integer> failoverShardingItems = failoverService.getLocalFailoverItems();
if (!failoverShardingItems.isEmpty()) {
return executionContextService.getJobShardingContext(failoverShardingItems);
}
}
shardingService.shardingIfNecessary();
List<Integer> shardingItems = shardingService.getLocalShardingItems();
if (isFailover) {
shardingItems.removeAll(failoverService.getLocalTakeOffItems());
}
shardingItems.removeAll(executionService.getDisabledItems(shardingItems));
return executionContextService.getJobShardingContext(shardingItems);
}
public void shardingIfNecessary() {
List<JobInstance> availableJobInstances = instanceService.getAvailableJobInstances();
if (!isNeedSharding() || availableJobInstances.isEmpty()) {
return;
}
if (!leaderService.isLeaderUntilBlock()) {
blockUntilShardingCompleted();
return;
}
waitingOtherShardingItemCompleted();
LiteJobConfiguration liteJobConfig = configService.load(false);
int shardingTotalCount = liteJobConfig.getTypeConfig().getCoreConfig().getShardingTotalCount();
log.debug("Job '{}' sharding begin.", jobName);
jobNodeStorage.fillEphemeralJobNode(ShardingNode.PROCESSING, "");
resetShardingInfo(shardingTotalCount);
JobShardingStrategy jobShardingStrategy = JobShardingStrategyFactory.getStrategy(liteJobConfig.getJobShardingStrategyClass());
jobNodeStorage.executeInTransaction(new PersistShardingInfoTransactionExecutionCallback(jobShardingStrategy.sharding(availableJobInstances, jobName, shardingTotalCount)));
log.debug("Job '{}' sharding complete.", jobName);
}
3.分片流程图
作业启动,开启节点监听器,如果监听到节点变化,生成 分片临时节点;
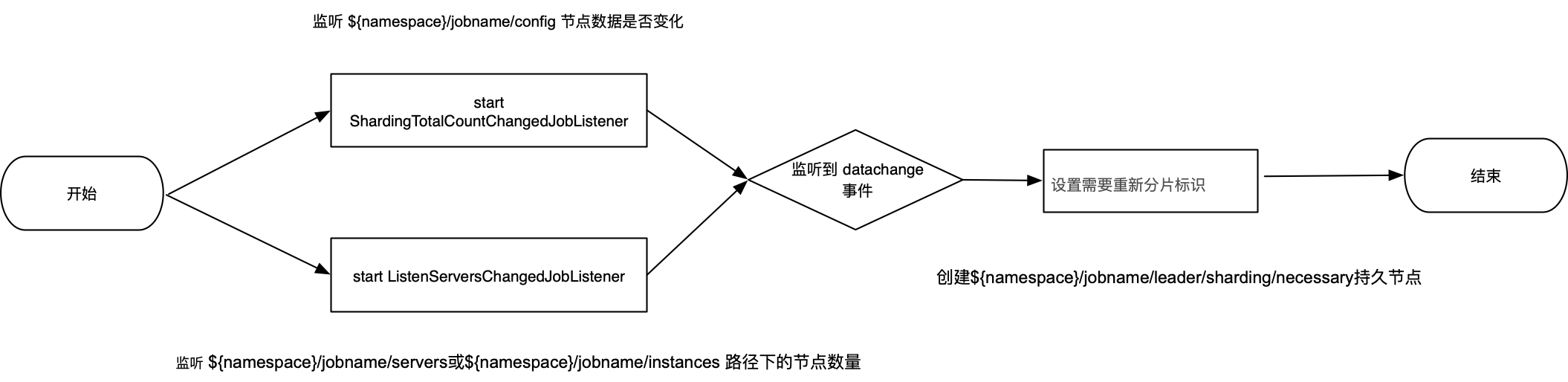
每次作业执行时,如果是主节点,且需要分片。主节点会分片,将分片信息持久化到zk;
参考:博客链接

若有收获,就点个赞吧
0 人点赞
