原文 : link
当需要存储的数据量变得很大、一台机器的磁盘无法存储下时,就需要将这些数据存储到多台机器上。
数据分布
将数据分布到不同的节点上的方式有:
- 哈希分布:比如按数据主键进行一致性哈希分布
- 顺序分布:将数据按照主键切分为有序的范围,每个有序范围内的数据存储到一个节点上
- 根据哈希/顺序范围,负载均衡分布:分布式存储系统自动识别负载(机器Load值、CPU、内存、磁盘、网络、QPS、线程等资源使用率)高的节点,将它服务的部分数据迁移到其他机器,实现自动负载均衡
- 分布式存储系统的每个集群中一般都有一个总控节点。
- 通过总控节点调度实现负载均衡:工作节点通过心跳包(Heartbeat,定时发送)将节点负载相关的信息发送给主控节点;主控节点计算出工作节点的负载以及需要迁移的数据,生成迁移任务放入迁移队列中等待执行。
- 分布式存储系统的每个集群中一般都有一个总控节点。
很多人可能会觉得总控节点会成为分布式系统的瓶颈,任务P2P架构(无中心节点)架构更有优势。然而事实并非如此,主流的分布式存储系统大多带有总控节点,因为使用总控节点架构更易于维护、且也能够支持成千上万的集群规模。关于总控节点的瓶颈问题优化,后面会展开讲。
总控节点主要用于全局调度、元数据管理(分片位置信息等)。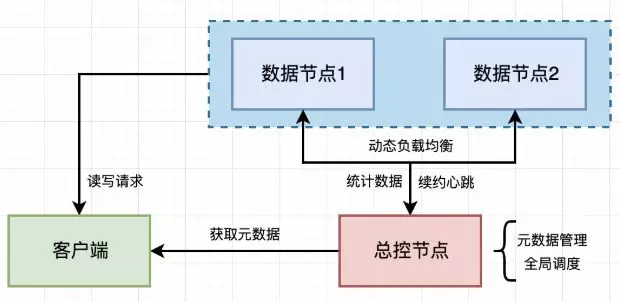
当然,也有很多存储系统是无中心架构的,比如Redis
数据节点高可用
数据备份/复制
在分布式存储系统中,随着集群规模变得越来越大,故障发生的概率也越来越大。大规模集群每天都有故障发生,其中出现故障最高概率的是:单机故障、磁盘故障。
为了保证分布式存储系统的高可靠和高可用,需要对每个节点的数据进行多副本复制备份:
- 主副本(Primary)一般只有一个,可以提供读 / 写服务;
- 备副本(Backup)可以有多个,不对外服务 / 提供只读服务。
- 若主副本出现故障,需要选举一个备副本成为新的主副本,这个操作成为“选举”。
- 可以通过总控节点租约协议、分布式锁、选举协议比如Paxos协议(使用典例:ZooKeeper)等进行新主副本的选举。
- 可以通过总控节点租约协议、分布式锁、选举协议比如Paxos协议(使用典例:ZooKeeper)等进行新主副本的选举。
主备副本之间的数据复制,主要通过同步操作日志(Commit Log)实现:主副本首先将操作日志同步到备副本,备副本回放操作日志,完成后通知主副本。(关于操作日志,更多可以阅读《数据存储技术:单机篇》)
分布式存储系统通过复制协议将数据同步到多个存储节点,并确保多个副本之间的数据一致性。
复制协议分为2种:强同步复制、异步复制。
- 强同步复制:要求用户的写请求同步到备副本才可以返回成功;若备副本不止一个,还可以要求至少需要同步到几个备副本。
- 可以保证主备副本之间的强一致性,但当备副本出现故障时,也可能阻塞存储系统的正常写服务,影响系统可用性
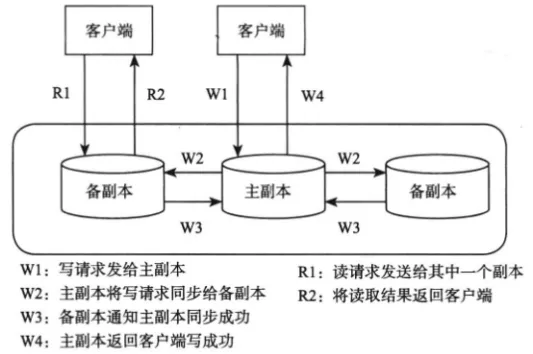
- 可以保证主备副本之间的强一致性,但当备副本出现故障时,也可能阻塞存储系统的正常写服务,影响系统可用性
- 异步复制:主副本不需要等待备副本的回应,只需要本地修改成功就可以告知客户端写操作成功。同时,主副本通过异步机制,比如单独的复制线程将客户端修改操作推动到其他副本。
- 可用性相对较好,但主备副本之间的数据一致性得不到保障,如果主副本发生不可恢复故障,则可能丢失最后一部分更新操作
- 可用性相对较好,但主备副本之间的数据一致性得不到保障,如果主副本发生不可恢复故障,则可能丢失最后一部分更新操作
根据CAP原理,一致性和可用性是矛盾的。存储系统设计时,需要在一致性和可用性之间权衡。根据实际需求,有以下几种模式可用选择:
- 最大保护模式:即强同步复制协议。保证了主备副本数据的强一致性,但可用性低
- 最大性能模式:即异步复制协议。保证了性能及可用性,但可能丢失数据
- 最大可用模式:以上两种模式的折衷。正常情况下相当于最大保护模式;如果主备之间的网络出现故障,则切换为最大性能模式。这种模式在一致性和可用性之间做了很好的权衡
同构复制
通常情况下,数据备份时,会将存储节点分为若干组,每个组内的节点服务完全相同的数据,其中有一个节点为主副本节点,其他节点为备副本节点。
由于同一个组内的节点服务相同的数据,这样的系统成为同构系统。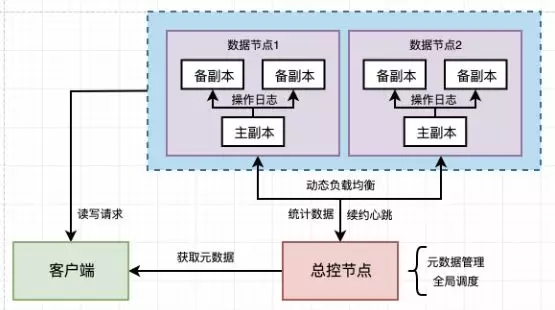
异构复制
同构系统的问题在于:当某个副本节点发生故障,系统需要自动增加新副本,这时需要迁移的数据量太大。假设每个存储节点服务的数据为1TB,内部传输带宽限制为20MB/s,那么增加一个副本节点,需要的拷贝数据时间为1TB / 20MB/s = 50000s,大约十几个小时;由于拷贝数据的过程中存储节点再次发生故障的概率很高,所以这样的架构很难做到自动化,不适用于大规模分布式存储系统。
异构系统将数据划分为很多大小接近的分片,每个分片的多个副本可以分布到集群中的任何一个存储节点。如果某个节点发生故障,原有的服务将由整个集群而不是某几个固定的存储节点来恢复。由于整个集群都参与到该故障节点的恢复过程,所以故障恢复时间很短;并且集群规模越大,优势就会越明显。
数据节点故障检测与恢复
系统检测到故障出现时,自动使用备份数据进行故障恢复。
基于总控节点的故障检测与恢复:
- 心跳机制:总控节点每隔一段时间,比如1秒,向工作节点发动一个心跳包。如果工作节点没有发生故障,则可以正常响应总控节点的心跳包;否则,总控节点在重试一定次数都没有收到工作节点的响应后,则会认为该工作节点发生了故障。
- 心跳机制的问题:总控节点没有收到工作节点的心跳响应,并不能确定工作节点发生故障并停止了服务。在系统运行过程中,可能发生各种错误,比如网络故障、工作节点过于繁忙而导致无法响应心跳包。由于总控节点判断工作节点发生故障后,往往需要将该工作节点上面的服务迁移到集群中的其他服务器,为了保证强一致性,需要确保没有响应心跳包的工作节点不再提供服务,否则将出现多台服务器同时提供同一份数据的服务而导致数据不一致的情况。
- 租约机制:在机器之间的本地时差相差不大的前提下(实践中,机器之间会进行时钟同步),所以可以通过租约(Lease)机制进行故障检测,避免心跳机制的问题。租约机制就是带有超时时间的一种授权。总控节点可以给工作节点发放租约,工作节点持有的租约在有效期内才允许提供服务,否则主动停止服务。工作节点的租约快要到期的时候,需要向总控节点重新申请租约延期。若工作节点出现故障或与总控节点之间的网络发生故障时,其租约将过期,从而总控节点能够确保该工作节点不再提供服务(由于机器之间的时钟有误差,若租约有效期为10秒,则总控节点判断工作节点故障的时间需要加上一个前提量,比如11秒时,才可以认为该工作节点租约过期),其服务可以被安全地迁移到其他服务器。
基于分布式锁选主:
- 主备副本工作节点共用争夺同一个分布式锁,争取到分布式锁的节点作为主副本
- 主副本工作节点故障后,自动释放分布式锁;其他备副本可以重新争夺到分布式锁成为主副本,对外提供服务
- 分布式锁也需要实现高可用,常用的高可用协调服务有:Apache ZooKeeper、Google Chubby等
使用例子:跨机房部署,当主机房发生故障时,除了手工切换到备机房,还可以采用分布式锁服务实现自动整体切换。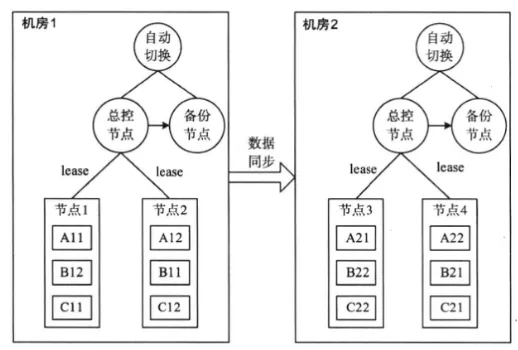
集群选主协议自恢复:
- 在主备副本节点之间构成一个集群,实现自选举协议
- 实现参考:ZooKeeper集群中的各个节点基于Paxos选举协议实现数据强一致性和集群高可用性
- 优点:总控节点和工作节点之间不需要保持租约,总控节点出现故障也不会对工作节点产生影响
- 缺点:工程实现复杂
总控节点高可用
总控节点备份
除了工作节点需要通过数据备份、故障自动检测与恢复实现高可用外,总控节点自身也同样需要实现高可用。
主控节点也需要集群部署,集群选主也可以通过心跳租约、分布式锁等方式实现: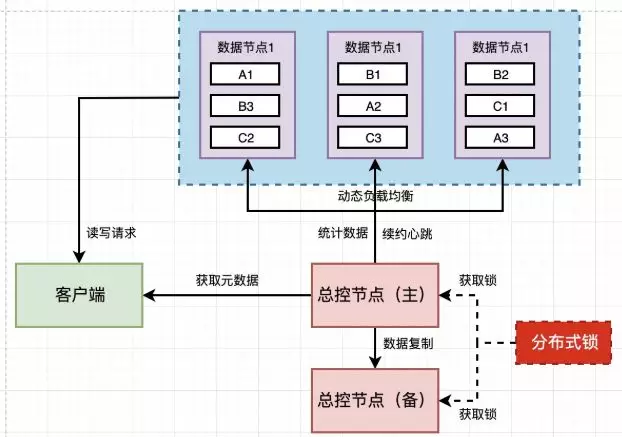
总控节点瓶颈
- 内存瓶颈:
- 为了快速响应请求,总控节点需要维护所有数据节点的元信息在内存中。随着节点的增多,内存容量可能会成为性能瓶颈
- 解决方式:在总控机与工作机之间增加一层元数据节点,每个元数据节点只维护一部分而不是整个分布式存储系统的元数据;这样总控节点只需要维护元数据节点的元数据即可。
- 为了快速响应请求,总控节点需要维护所有数据节点的元信息在内存中。随着节点的增多,内存容量可能会成为性能瓶颈
- QPS瓶颈:
- 如果客户端每次访问数据前,都要先请求主控节点获取路由信息,则总控节点QPS可能会变得很高
- 解决方式:客户端本地缓存一份路由信息;可以每隔一段时间 / 当总控节点中的路由信息更新时,再更新本地缓存
- 如果客户端每次访问数据前,都要先请求主控节点获取路由信息,则总控节点QPS可能会变得很高
分布式存储系统范型
分布式文件系统
主控节点需要保存文件目录元数据信息;文件被拆分/合并为固定大小的数据分片,分布式异构保存在数据节点中。
- 大文件:拆分成固定大小的数据块,作为备份分片(比如Google File System里的chunk)
- 小文件:合并成一个大文件数据块,作为备份分片(比如Taobao File System里的block)
Google File System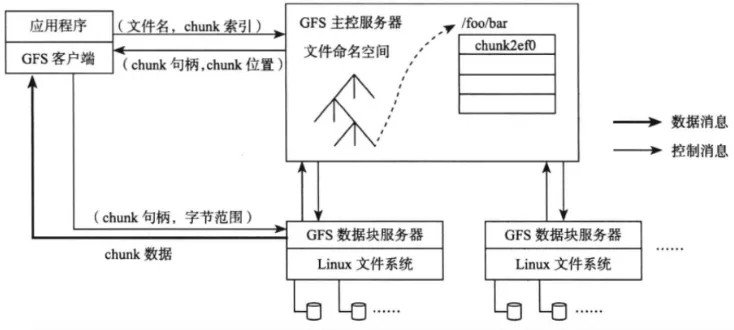
Taobao File System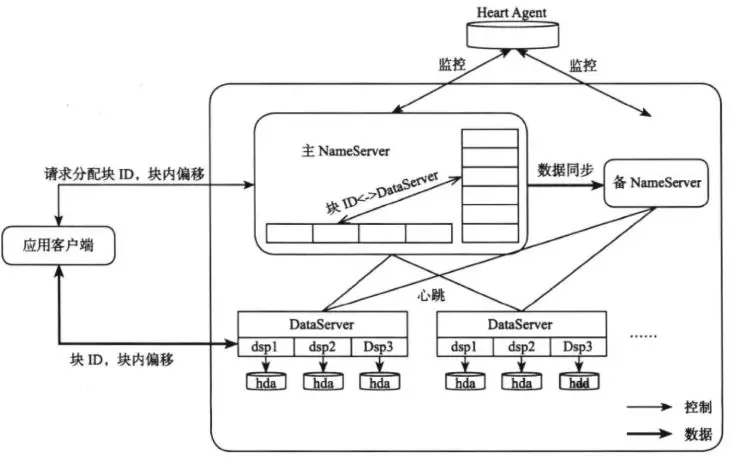

分布式键值系统
数据分布一般采用一致性哈希
淘宝Tair
- 中心控制节点:Config Server,采用一主一备的形式保证可靠性
- 数据服务节点:Data Server
- Config Server负责管理所有Data Server,维护其状态信息和数据分布策略;Data Server对外提供各种数据服务,并以心跳的形式将自身状况汇报给Config Server
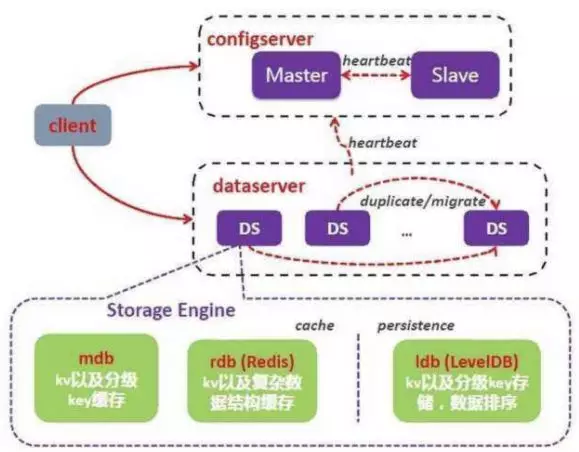
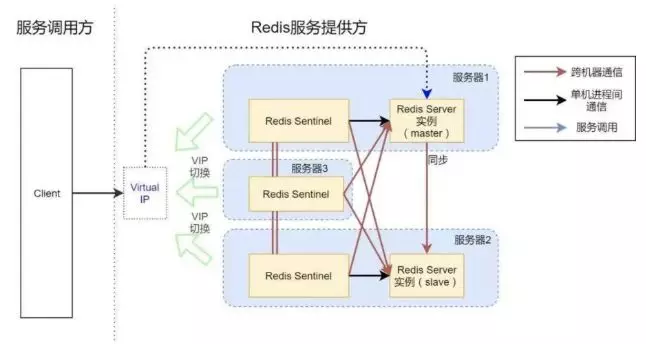
Redis
Redis采取的是无中心化架构
- 分布式:Redis Cluster
- 数据分区:Redis Cluser采用虚拟槽分区(一致性哈希的一种优化)
- 请求路由:在集群模式下, Redis接收任何键相关命令时首先计算键对应的槽, 再根据槽找出所对应的节点, 如果节点是自身, 则处理键命令;否则回复MOVED重定向错误, 通知客户端请求正确的节点。
- 节点通信:采用P2P的Gossip( 流言) 协议,节点彼此不断通信交换信息, 一段时间后所有的节点都会知道集群完整的信息
- 数据分区:Redis Cluser采用虚拟槽分区(一致性哈希的一种优化)
- 高可用:Redis Sentinel
- 保证Redis节点的故障发现和故障自动转移
- 保证Redis节点的故障发现和故障自动转移
**
分布式数据库(分库分表)可以在应用层实现,也可以在中间件层实现。
- 中间件层实现的好处是对应用透明,应用就像查单库单表一样去查询中间件层;缺点是除了维护中间件外,还要考虑中间件的HA/负载均衡等,增加了部署和维护困难。
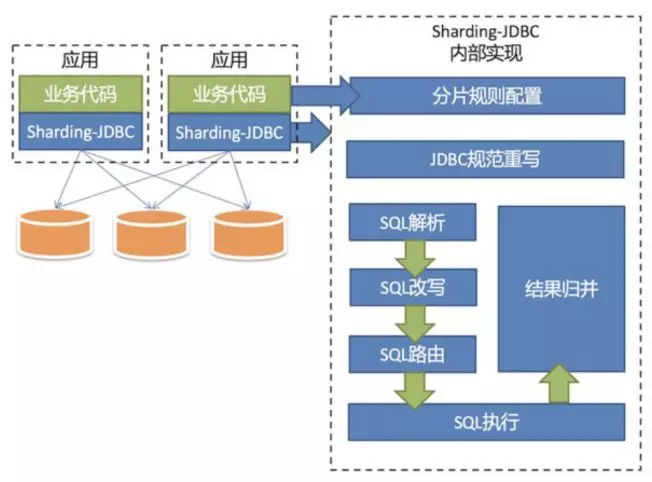
- 应用层实现可以在JDBC驱动层、DAO框架层,如MyBatis/Hibernate上完成,如当当的sharding-jdbc是JDBC驱动层实现,阿里的cobar-client是基于DAO框架iBatis实现。
MySQL Sharding
中间件层实现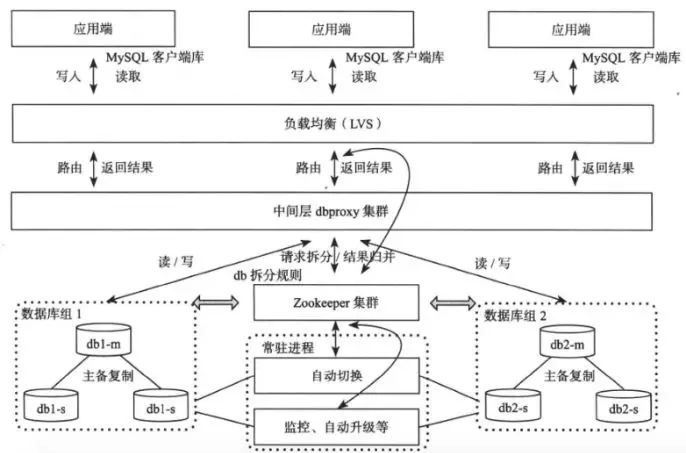

Sharding JDBC
应用层实现

大数据存储
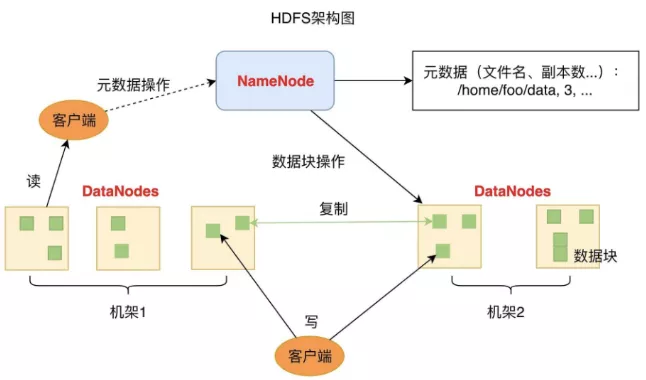
Hadoop大数据家族的底层存储,主要使用的是HDFS文件系统。
HDFS的关键组件有两个,一个是DataNode,一个是NameNode
- DataNode负责文件数据的存储和读写操作,HDFS将文件数据分割成若干数据块(Block),每个DataNode存储一部分数据块,这样文件就分布存储在整个HDFS服务器集群中。HDFS为了保证数据的高可用,会将一个数据块复制为多份(缺省情况为3份),并将多份相同的数据块存储在不同的服务器上,甚至不同的机架上;即HDFS文件系统的DataNodes中存储的数据分片都是异构的。
- NameNode负责整个分布式文件系统的元数据(MetaData)管理,也就是文件路径名、数据块的ID以及存储位置等信息,相当于操作系统中文件分配表(FAT)的角色。
- 应用程序客户端(Client)可以并行对这些数据块进行访问,从而使得HDFS可以在服务器集群规模上实现数据并行访问,极大地提高了访问速度。
云存储
云存储就是通过网络,将大量普通存储设备构成的集群,虚拟化为易扩展、弹性、透明、具有伸缩性的存储资源池,以统一的接口、按需提供给授权用户;授权用户可以通过网络对存储资源池进行任意的访问和管理,并按使用付费。

若有收获,就点个赞吧
0 人点赞
