- 《人人都在说谎:赤裸裸的数据真相》
- Statista
- Why Amazon Knows so much about You
- Ranked: The Most Popular Paid Subscription News Websites
- 焦点分析丨挨了社区团购致命一刀,「永辉超市」还有力反击吗?
- How big data analytics impact your business success
- V’s of Big data
- 数据挖掘框架 CRISP-DM
- What is the Data Science strategy of Netflix?
- All the Datasets You Need to Practice Data Science Skills and Make a Great Portfolio
- Seeing Theory
- Understand Data Analytics Framework with a case study in the business world
- HR Analytics of UPS Case Study
- “数字控制”下的劳动秩序
- 计算机进行人格判断比人类更准确
- 外卖骑手的困局,算法不背这个锅
- 私人特质和属性可以通过人类行为的数字记录来预测
- 人工智能与机器学习技术在医疗保健行业中的应用
- 普林斯顿 - 根据邮政地址数据收取不同费用
- Linkein - “数据团队”的产业化才刚开始
- Testin - AI时代的互联网金融智能运营实践
- Testin公司
- A/B测试
- 结果收集
- 多渠道版本的A/B测试
- B站 - B站给传统企业的数字化营销带来启发
- 背景
- B站成长路径
- B站的数字化营销
- 小结
《人人都在说谎:赤裸裸的数据真相》
本书是一本以看似离奇但又符合逻辑的案例构成的数据科学入门读物。通过这些故事或者案例,我们可以了解到人们都用那些数据干了什么事情。不过作者从另一个维度也在提醒数据并不是万能的。除了米国背景和翻译的一点问题,可以作为数据思维,或者了解数据都是怎么使用的入门书。

以搜索为数据
搜索引擎能够揭露非常多的数据,而且这种数据还比较真实。种族主义搜索(和黑鬼相关的搜索)量分布图与预测的支持特朗普的共和党投票人十分吻合:

这些数据中有一部分包含原本不会被任何人接收的信息。如果把这些信息整合起来,使之保持匿名状态以确保我们永远不会知晓任何特定个体的恐惧、欲望及行为,再加上数据科学,我们就会对人类有一个新的认识——他们的行为、他们的欲望和他们的本性。事实上,尽管听起来有夸大其词的风险,但我越来越相信,数字时代日益普及的新数据将大大拓展我们对人类的理解。
以身体为数据
塞德搬到了宾夕法尼亚的乡下,在全身心投入自己相马的爱好之前,他曾尝试过纺织和运动医学等多领域的工作。赛马的数字很不精准,在奥卡拉拍卖会上展出的1000匹两周岁马中,只有最受全美瞩目的最终会赢得比赛,拿到丰厚的奖金。
彼时塞德决定测量马匹内脏的大小。凭借当时的技术根本不可能完成这项工作,于是他自己组装了一部便携式超声波仪器。结果令人振奋。他发现,心脏的大小,尤其是左心室的大小,是赛马成功的重要预测指标,也是最重要的变量。另一个重要的器官是脾脏:脾小的马几乎一分钱都赚不了。
塞德还有更多的发现。他将数千段赛马比赛的视频资料数字化,发现某些步法确实与比赛成功相关。他还发现,一些两周岁马在开跑0.125英里(约200米)后会发出呼哧呼哧的喘息声。这样的马有时会卖到100万美元,但是塞德的数据告诉他,这样的马是不会赢得比赛的。于是他派了一名助理坐在终点线附近,排除掉那些开跑不久就喘息的马。
在奥卡拉拍卖会上,1 000匹马中大概只有10匹能通过塞德的所有测试。他完全忽略血统,除非血统会影响马匹的售价。“血统告诉我们,一匹马可能有那么一丝机会是一匹好马,”他说,“但是如果我能看出它是一匹好马,又何必在意它的出身呢?”。比如他选中的85号,就取得了不菲的成绩,请注意【左心室大小】这个参数。
| 百分位数 | |
|---|---|
| 身高 | 56 |
| 体重 | 61 |
| 血统 | 70 |
| 左心室大小 | 99.61 |
AB测试两三事


Statista
官方链接:https://www.statista.com/ Statista是一个领先的全球综合数据资料库,所提供的数据包括了世界主要国家和经济体。Statista 庞大的数据资料内容,及其强大的搜索技术可以帮助学生、科研学者、市场研究规划人员等及时有效地找到所需要的统计数据资料和各国的市场信息,为定量研究提供权威有效的数据。 Statista除了直接提供统计数据外,Statista还为用户提供了直接有效地搜索和数据源定位,是科学研究及数据调查的重要途径。
Statista目前有200多万个统计数据,超过22500个数据源,其中45%的数据是从其他公司(如Nielson、Scarborough、IPSO等)购买;45%是由独家合作的公司提供(如GFK、Mackenzie、Deloitte、Ernst & Young等);10%是由各国家统计局,政府等公立机构提供。每天由在德国总部的超过450位统计学家和数据分析师进行更新,录入和检验。该数据库的内容包括超过40个国家200,000个的市场预测,7000多份行业专家编写的档案, 16000多个热点信息图表(可以看到例子有福布斯,华尔街日报,金融时报等)。
Why Amazon Knows so much about You
来源(BBC官方amazon专栏):https://www.bbc.co.uk/news/extra/CLQYZENMBI/amazon-data
这篇文章非常详细的描述了亚马逊公司到底拥有了用户的那些数据,可以说Amazon的最大资源就是它的数据,文章作者Leo Kelion从1999年开始就是亚马逊的用户,他提交了一份数据主题访问请求,要求亚马逊公开它所知道的关于我的一切,以下是亚马逊的反馈:
- 一共数百个文件
- 一个数据库包含了我的家人与虚拟助手 Alexa 所有31082次互动的记录。录音片段也提供。
- 48次播放《放手吧》的请求表明了我女儿对迪斯尼动画片《冰雪奇缘》的迷恋。
- 在卧室深夜音乐播放音乐的要求,提供一个统计成人活动的线索。
- 一个文件显示了自2017年以来我在其店内进行的2670次产品搜索。每个栏目都有60多个补充栏目,包含了一些信息,比如我使用的是什么设备,我后来点击了多少条链接,以及一串暗示我所在位置的数字。
- 一个电子表格实际上触发了一个警告信息,说它太大了,我的软件无法处理。它包含了我自2018年以来使用的83657次 Kindle 交互的详细信息,包括每次点击的确切时间。一个相关的文档为每本电子书将我的阅读时间分配到毫秒。
Ranked: The Most Popular Paid Subscription News Websites
来源:https://www.visualcapitalist.com/ranked-the-most-popular-paid-subscription-news-websites/
Visual Capitalist的可视化图都非常精美,这次的付费新闻展示中,发现财新位居第10,非常不错。
焦点分析丨挨了社区团购致命一刀,「永辉超市」还有力反击吗?
来源:https://36kr.com/p/1208020172165248 作者:孙亚飞 @36Kr
- 4月最后一个交易日,中国生鲜超市龙头「永辉超市」上演跳水行情,低开低走,中间一度跌停,并最终收跌9.87%。市场之所以反应激烈,源于前一日官方披露的2021年一季度报“爆雷”,Q1归母净利润同比大幅下滑98.51%。
- 去年一季度明明还赚15.68亿元,结果一年过去后,利润只剩个零头,仅为2332万元。而截至同一时期末,永辉已在全国开出1027家超市业态。换算下来,过去的一季度每家超市平均只有2万多元的利润。
- 定位于生鲜超市的永辉,本身“非标准”的生鲜产品毛利就较低,这有一部分是出于“低价”引流考虑,并通过食品用品(含服装)等“标准”的高毛利产品连带销售来提升整体毛利率。但现在,引流款产品对用户的吸引力正在下降。

- 永辉线上业务的毛利率要低于线下业务水平。
- 生鲜品类,正是去年三季度以来,随着巨头下场后竞争最激烈的领域。日常家庭餐桌的鲜活水产、蔬菜瓜果、禽蛋奶等生鲜产品,成为巨头们“社区团购”业务的重点补贴品类,在初期为了抢占市场,通常以极低的毛利,甚至负毛利进行竞争。
- 此前十荟团在武汉的毛利可以做到19%左右,巨头进入后直接掉到14%-15%,并被迫跟进,加大对品类和团长的补贴力度。

- 生鲜电商激烈竞争的战火未熄,根据此前36氪报道,美团优选、多多买菜、橙心优选、兴盛优选在2021年的GMV目标分别是2000亿、1500亿和1000亿、800亿。永辉的劣势局面未来一段时间恐很难扭转。
- 小店业态:跑不通但又无法放弃。
- 社区是永辉必然要迈过去的一道坎,而实际情况是,他们反而摔了跟头。
- 永辉为创新摸索付出了惨痛代价,包括2017年度、2018年、2019年、2020年永辉云创分别净亏损2.67亿元、6.17亿元(2018年前9月)、1.28亿元、1.51亿元。对于这么一个极低净利润率甚至无法盈利的生鲜超市来说,这是一笔不菲的投入。
How big data analytics impact your business success
来源:https://medium.com/@Apiumhub/how-big-data-analytics-impact-your-business-success-b19b2f6d68b 作者:Apiumhub @Medium
:::info “Without Big Data, you are blind and deaf and in the middle of a freeway”– Geoffrey Moore :::
Key statistics about Big Data that you shouldn’t ignore
- 91% 的市场营销人员认为成功的品牌利用客户数据来决定营销策略
- 投资于数据分析的公司收入增长49% ,而没有投资于数据分析的公司收入增长49%
- 35% 的营销人员说数据通过个性化改善了他们的客户参与度
- 60% 充分利用大数据分析能力的零售商可以提高他们的营业利润率高达60%
- 60% 的受访专业人士认为数据在他们的组织中产生了收益
83% 的专业人士认为数据分析使现有的服务和产品更有利可图。亚洲在这方面处于领先地位,63% 的受访者表示,他们通常从数据中创造价值。
Walmart Case
沃尔玛是世界上最好的零售商之一。超过2.45亿顾客访问了10900家商店,其员工数量实际上超过了零售商的一些顾客数量。
- 根据销售数据,Walmart预测弗朗西斯飓风之后需要什么。除了手电筒和应急设备的销售预计将出现增长外,啤酒和草莓馅饼的需求也出现了意想不到的增长。这些数据被用来为库存决策提供信息,并导致了强劲的销售。在飓风来临前,草莓馅饼的销量增长了7倍。
V’s of Big data
来源:https://towardsdatascience.com/data-analytics-big-data-case-study-vs-of-big-data-1d3dc5118759 作者:Towards Data Science @Medium
非常详细的扩展解释了大数据的3个V(最开始提出来时是3个V,第四个Value是后加的比较牵强的,并且有其他补充版本的内容)。
数据挖掘框架 CRISP-DM
- 中文详细介绍 https://cloud.tencent.com/developer/article/1557101
- 框架使用统计 https://www.datascience-pm.com/crisp-dm-2/
- 详细带案例资料(SPSS)https://the-modeling-agency.com/crisp-dm.pdf
综合来讲,Cross Industry Standard Process for Data Mining 就是最流行的数据分析框架(其中的DM是数据挖掘,比数据分析更早出圈的概念)
市场份额

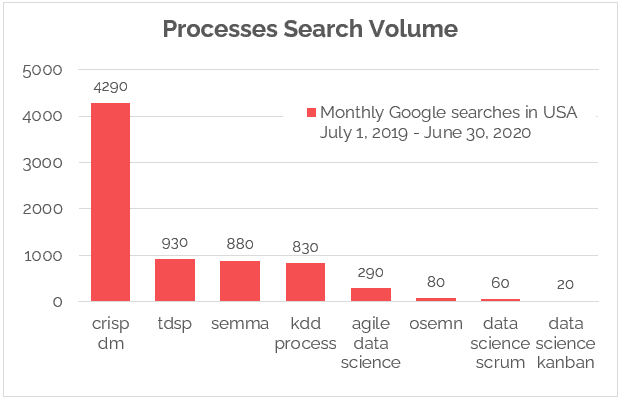
耗时占比
根据统计,各个步骤的耗时:
- 收集数据集,19%;
- 清理和组织数据,60%;
- 构建训练集,3%;
- 根据数据挖掘模式,9%;
- 算法调优,4%;
- 执行其他任务,5%。
通用任务与产出
Generic tasks (bold) and outputs (italic) of the CRISP-DM reference mode
按阶段产出以及依据
数据公民月报表格What is the Data Science strategy of Netflix?
https://www.analyticsinsight.net/what-is-the-data-science-strategy-of-netflix/ ^20210417 ^Analytics Insight https://www.nytimes.com/2021/05/04/business/netflix-cinemark-army-of-the-dead.html
Netflix film ‘Army of the Dead’ will be released in theaters first, as cinimas and streaming adapt. ^20210504 ^The New York Times
由于 Netflix 与其订阅用户的直接关系,以及观众如何与其内容互动的大量数据,该公司可以很容易地确定人们想要什么样的内容。在推出《纸牌屋》的三个月内,Netflix 在美国增加了200万用户,在国际上增加了100万用户。
在收集数据方面,Netflix 拥有超过1.48亿用户的庞大用户基础,这给它带来了巨大的优势。然后重点关注度量——被观看的日期内容; 观看内容的设备; 观看内容的性质如何根据设备而变化; 在其平台上的搜索; 被重新观看的部分内容; 内容是否暂停; 用户位置数据; 观看内容的一天和一周的时间,以及它如何影响观看的内容种类。一旦数据收集完毕,Netflix 就会在很多方面使用这些数据。
这个推荐系统是这样设计的,Netflix 专注于通过一个个性化的推荐系统给每个用户提供用户想要的东西,这个推荐系统根据收集到的用户的个人信息来组织每个 Netflix 用户的收藏。像 Netflix 一样,你可以使用大数据来确保提供给每个用户的内容都受到用户个人活动和与你的品牌互动的影响,确保每个用户的内容体验都是独一无二的。
用户最近浏览的内容记录了用户近期在播放视频时的行为记录,比如是否播放完成或者重放,又或者用户是否因为发现内容不感兴趣而停止观看。利用这些数据进行分析确保 Netflix 不会让其用户感到厌烦的关键; 如果用户活动表明缺乏兴趣,最好是降级的内容(的理解难度),并提供更有趣的东西。
Netflix电影也在加大和传统院线的合作,2021年5月4日美国第三大连锁影院 Cinemark 宣布,将于5月14日在其250多家影院上映该公司即将上映的僵尸电影《死亡大军》(Army of the Dead) ,这是迄今为止最明显的迹象,表明影院对 Netflix 的态度正在软化。一周后,该电影将在网上上映。
去年,当流行病肆虐、大多数连锁影院关门时,Netflix 和 Cinemark 在几家影院试映了 Netflix 的三部影片: 《黑底》(Ma Rainey’s Black Bottom)、《午夜天空》(Midnight Sky)和《圣诞传奇2》(The Christmas Chronicles 2)结果是鼓舞人心的,他们尝试更广泛的发行时,该国的大多数影院已经重新开放。

All the Datasets You Need to Practice Data Science Skills and Make a Great Portfolio
https://towardsdatascience.com/all-the-datasets-you-need-to-practice-data-science-skills-and-make-a-great-portfolio-857a348883b5
^20200826 ^Towards Data Science 比较全面的典型数据收集
Seeing Theory
https://seeing-theory.brown.edu/basic-probability/index.html ^Seeing Theory 可视化概率解释,非常惊喜,共有5章涉及从基础到复杂的数据科学概率内容讲解。
Understand Data Analytics Framework with a case study in the business world
https://becominghuman.ai/understand-data-analytics-framework-with-a-case-study-in-the-business-world-15bfb421028d ^20190911 ^Becoming Human 文章中对于通用公司3类分析的细节描述较多,可以参考理解数据分析的类型。
数据分析框架是如何应用于通用电气的

1. 描述性和诊断性分析
通用电气的交易模型关注的是通用电气的销售额、运营设备的销售额以及零部件和服务的销售额。通用电气需要做些什么来提高销售额。因此,在分析方面,通用电气需要进行描述性和诊断性分析,以增加其设备、零部件和服务的销售。
2. 预测分析
在合同模式层面,通用电气将保证其销售给客户的设备的性能。现在他们需要进入预测分析的水平。
3. 指令性分析
通用电气的最后一个模型是扩展的客户结果,这是在规定的分析水平。通用电气真正告诉客户,他们应该如何使用设备,以最大限度地提高价值。这对客户来说更有价值也更难做到,因为通用电气需要收集更多的数据,更仔细地分析它。
这改变了通用电气的商业模式,因为通用电气实际上不仅销售设备、零部件和服务,通用电气销售的分析意味着通用电气将为这种合作关系收取费用,通用电气可以告诉客户如何最好地操作设备。因此,这实际上为通用电气和客户创造了更多的价值。
最后的想法
通过使用大数据和分析来确定新的趋势,组织将能够为他们的消费者创造新的服务产品。以及新的商业模式。使用数据和分析并不仅限于高科技行业。无论你从事哪个行业,无论是金融、医疗、教育、保险、运输、体育、能源、媒体、制造业、零售业,还是其他任何行业,大数据和分析都能够而且将会发挥关键作用。因此,使用大数据解决方案的组织需要跟上其不断变化的本质,而那些仍然不愿投资的组织应该重新考虑其组织政策。
HR Analytics of UPS Case Study
https://ai.plainenglish.io/hr-analytics-of-ups-case-study-e179c99a82f4 ^Rachel Sung @Aritificial Intelligence 可视化在 Tableau 上可以互动 https://public.tableau.com/profile/chiachi.sung#!/vizhome/HRDashboard_16148973535320/Dashboard1?publish=yes DART Rate https://www.safeopedia.com/2/1367/safety-standards/dart-rate-what-it-is-and-how-to-calculate-it UPS中国 https://www.ups.com/cn/zh/Home.page
第三方Driver Schedule软件 https://www.driverschedule.com/
Company Overview

联合包裹服务公司又名 UPS,是世界上最大的包裹递送公司之一,在全球拥有超过528,000名员工,服务于220多个国家和地区。2019年,UPS 平均每天交付2190万件邮件,总收入为741亿美元。UPS 拥有强大的全球网络和多种服务,如航空、地面、国内、国际、商业和住宅,具有竞争优势。UPS 还专注于尖端技术,帮助他们不仅提高运营生产率,客户满意度,而且降低整体碳强度。
Current Pain Points
- 增加的需求: 新的标准,2019冠状病毒疾病已经使网上购物更具吸引力
- 激烈的竞争: 来自行业竞争者和新进入者的威胁
-
Goal
在2018年 UPS 公司报告中,管理层列出了提高 UPS 健康与安全措施的3个目标:
2% 改善员工敬业度指数
- 1% 改善损失的时间损伤频率
- 3% 改善汽车事故发生率
DART Rate
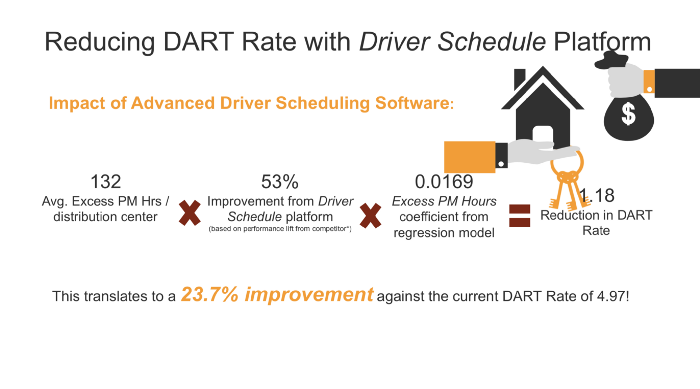

分析表明,DART Rate和这3个目标关系紧密,公司需要降低DART Rate来达到目标。DART Rate是计算公司工作安全的指标,Days Away、 Restricted 或 Transferred 的缩写。这是职业安全与健康管理局用来衡量工伤影响的指标之一。它跟踪任何因工伤或疾病而停止正常工作的工人。这包括任何不得不:
- Cease working 停止工作
- Restricted their work activities 限制他们的工作活动
- Transferred to different department or job 调到不同的部门或工作
计算公式为:DART Rate = (造成工人离开、限制或转移的可记录的伤害和疾病的总数 x200,000)/所有员工工作的总时数
Solution
上线Driver Schedule司机调入软件,降低DART Rate。
- 费用

2. 收入

- ROI计算

- 利润预测


“数字控制”下的劳动秩序
北京大学的一篇外卖论文 http://www.shehui.pku.edu.cn/upload/editor/file/20201223/20201223141710_4025.pdf 作者在快递实际参加劳动半年,有一些独特的细节和数据。 PDF归档:20201223141710_4025.pdf
计算机进行人格判断比人类更准确
https://www.pnas.org/content/112/4/1036/tab-figures-data date: 201501 source:PNAS
简述
评判他人的性格是成功社交生活中必不可少的技能,因为性格是人们互动,行为和情感背后的关键驱动力。尽管准确的人格判断源于社交认知技能,但机器学习的发展表明,计算机模型也可以做出有效的判断。这项研究使用了86,220名完成100个选项(是否喜欢)的人格问卷的志愿者,比较了基于人和计算机的人格判断的准确性。对于某些结果,他们甚至超过了自我评价的人格分数。在人格判断方面,计算机超越人类,这在心理评估,市场营销和隐私方面都带来了巨大的机遇和挑战,我们发现:
- 基于 Facebook Likes 的计算机预测比参与者的朋友使用性格问卷做出的预测更准确(r = 0.56 )对比(r = 0.49),其中 r 是相关系数,越接近1越准确;
- 计算机模型显示出较高的内部一致性(指5型人格中的相互关系影响符合逻辑);
- 在预测诸如吸毒,政治态度和身体健康等生活结果时,计算机人格判断具有较高的外部效度(与其他性格外的预测有较强关系)
测试方法
被试填写的是有100个项目的国际人格项目库(IPIP)人格五因素模型调查表,测量开放,认真,外向,和,和神经质的特征。预测是否准确人是从参与者Facebook朋友那里获得的,他们被要求使用10个选项的IPIP人格测度来描述给定的参与者。为了计算局外人的赞同和外部效度,我们收集了一个朋友评判的17622名样本与两个朋友评判的14,410名参与者的样本。
过程图如下,黄色的是个人填写。根据7万多数据进行线性回归训练,得到IPIP问卷和Facebook Likes之间的关系。最后就可以比较他人验证、自己评价和机器学习结果的区别了(最下面的三个小人)。

实验结果
标准1 - 1好友评价(Self-Other Agreement)

- 红色线是其他线的平均(Big5人格测试有5个维度)
- X轴是用于预测的Likes数量,Y轴是准确程度。可见随着用于分析数据的增加,准确率上升。
具体数据:我们最近对每个人的平均喜欢次数的估计是227(95%CI = 224,230),r = 0.56。该准确性显着高于一般朋友的判断,并且可以与平均配偶相媲美。当“喜欢”次数超过500,r = 0.66。使用的点赞次数与计算机准确性之间的近似对数线性关系,但增益会逐渐降低。(r为相关性越接近1越好,;CI是置信区间,代表有多少百分比真实结果会包含在特定区间里)
标准2 - 2好友评价(Interjudge Agreement)
这里使用的是上面数据中有2个好友评价的数据进行实验。
- 将两个好友的评价是否一致做区分为2组(较高一致性和较低一致性)。
- 结果为 r = 0.62,高于标准1的结论。
- 可能原因是有较高一致性的一组,在个性展现与判断上比较明确,便于进行预测(相当于由于个人原因,数据质量更好)
标准3 - 外部有效性(External Validity)
判断准确性的第三项衡量标准,即外部有效性,侧重于判断如何预测外部标准,例如现实生活中的行为,与行为相关的特征和生活成果。将参与者的自我评价人格分数以及人类和计算机的判断结果输入回归模型(分别针对连续变量和二分变量进行线性或逻辑分析),以预测13种生活成果和以前与人格相关的特征:生活满意度,沮丧,政治取向,自我监控,冲动性,价值观,轰动性兴趣,研究领域,药物使用,身体健康,社交网络特征和Facebook活动有关详细说明。
如图所示,在13项标准中,有12项的计算机判断的外部有效性高于人类判断的有效性(生活满意度除外)。此外,在13个条件中的4个条件中,计算机模型的外部有效性甚至优于自我评价的人格:Facebook活动,药物使用,研究领域和网络规模;在预测政治态度和社交网络特征方面具有可比性。外卖骑手的困局,算法不背这个锅
人工智能在医疗保健行业主要场景为机器人辅助手术、图像识别判断、行政工作流程助理等等。作为一项新的工具,人工智能越来越受医学界承认。并且获得越来越多得投资与利润。但无论怎样,人在其中得作用也非常重要,是能够在医疗行业运用好人工智能得关键。
资料来源:Alfred数据室(公众号) 文章日期:20200909 原文链接:https://mp.weixin.qq.com/s/a4qPSC-zEsr-vCuR2mKYpQ 相关链接:《外卖骑手,困在系统里》(比较长的一篇文章)https://zhuanlan.zhihu.com/p/225120404
外卖平台算法
阿里本地生活智慧物流团队发布的论文《Order Fulfillment Cycle Time Estimation for On-Demand Food Delivery》(外卖履约时间预估)讨论了饿了么外卖预估时间的逻辑:
算法的实现是使用一个深度神经网络算法来预测订单的配送时间:
问题出在那里
在实际算法的计算时会结合很多因素,比如:
- 订单信息:包括订单的空间因素(用户、餐厅的坐标,城市、配送区块的ID等)、订单的时间因素(小时时刻、是否工作日等)、订单大小(菜品数量和价格等);
- 聚合因素:包括通过骑手手机的GPS轨迹等计算出来的聚合因素;
- 菜品因素:比如说拉面、披萨、火锅等不同菜品的种类等;
- 餐厅备餐时间
- 供需关系因素:一是骑手的供需关系(骑手手上的订单越多,送餐越慢)、二是餐厅的供需关系(餐厅手上的订单越多,备餐越慢);
- 骑手因素:包括骑手到餐厅的距离、骑手目前手上未完成订单数量、订单送达剩余时间等
- 多维度相似订单的配送段ETA:配送段预计到达时间即骑手到达用户目的地下车后,把餐食送到用户手中所用的时间,比如说包括骑手等电梯的时间;这部分时间的预估采用K近邻算法找出与之维度相似的若干历史订单,计算加权平均时间;
- 气象因素:包括气温、空气质量指数、风速、天气状况等;
因此从上面所列的因素看,算法工程师在设计算法的时候,并非没有考虑天气状况、餐厅出餐时间、骑手等电梯的时间。基本上影响外卖履约时间的因素,算法都考虑进去了。通过历史数据提取这些因素进行训练得出的每组因素的重要程度如下:
结果
- 外卖平台:通过这个游戏提高效率,肯定是获利的。
- 部分骑手一开始是获利的,但是大家都为了时间不顾生命危险拼命赶单时,便是亏损的
- 用户享受到了非常便捷快速的外卖服务,也是获利的。
- 社会大众。骑手为了省时逆行闯红灯,社会大众徒增了很多道路交通安全上面的危险,是亏损的。涉及到社会大众的问题,使用属于大众的公权力来解决是一个合理的选择。
对策
面对外卖平台,需要有监督和惩罚机制,当重罚也被列入考虑因素的时候,便能迫使平台去规范自身的行为;
面对骑手,上海推行的电子马甲骑手扣分制,便是一个思路:每个骑手必须穿上印有编号的电子马甲,一个季度内扣完36分不允许再上路。思考
作为一个在北京,经常骑车上下班的同学。外卖小哥逆行还是经常能碰到的。但是这里有两个方面觉得也需要考虑:
- 首先,逆行不光是外卖小哥,其他电动车也有很多逆行的。比率感觉上外卖占比较大。
- 外卖另一个让人很不放心的地方是,边骑边看手机刷单。这个在并排或者骑行超车时候觉得很危险(有时候行车线是歪的,都怕被撞上。
总体感觉这是一个公地悲剧的例子。因为逆行的人会比其他快递员更快,就会获得奖励。而慢的根据数据,落后就经济就要受到影响。所以:
总有人会更快 》 平均数据会上升 》 预测时间会缩短 》 其他人不加速就被罚 》 只好也逆行从结论上:
- 外卖平台:我觉得外卖平台是治理责任,因为算法中的权重、运送的时间下限是可以限定的。算法无辜,但是算法是商业意志的体现,希望平台能够进行优化。
- 监管责任:对于上海的执法真是一个好想法。最好直接能够给公司开罚单,而且逆行的人要匿名,这样能够加大对公司的控制。
- 作为用户:从用户来讲,可以备注:小慢不投诉、可以敲门后放门口等等可以接受的内容。虽然你在街上遇到的小哥,不是送你这单的小哥。但作为多次博弈的这么一个游戏,可能还是有些帮助的。
私人特质和属性可以通过人类行为的数字记录来预测
https://www.pnas.org/content/110/15/5802 date:201304 source:PNAS
人工智能与机器学习技术在医疗保健行业中的应用
人工智能在医疗保健行业主要场景为机器人辅助手术、图像识别判断、行政工作流程助理等等。作为一项新的工具,人工智能越来越受医学界承认。并且获得越来越多得投资与利润。但无论怎样,人在其中得作用也非常重要,是能够在医疗行业运用好人工智能得关键。 资料来源:sigmoidal.io 文章日期:20200528 原文链接:https://zhuanlan.zhihu.com/p/34918987 原文链接英:https://sigmoidal.io/artificial-intelligence-and-machine-learning-for-healthcare/
背景
1. 从听诊器到人工智能
医学界花了一段时间才接受听诊器。承认人工智能是一个成熟的医疗工具还需要一段时间,尽管它有着巨大的变革医疗保健的潜力。然而,它是如此强大,当它最终在医疗保健中占据应有的位置时,取代听诊器将标志这一切的开始。
2. 机器学习切实带来利益
人工智能、机器学习和深度学习已经增加了医疗行业的利润。例如,根据研究公司Frost & Sullivan的数据显示,到2021年,人工智能系统将为全球医疗保健行业带来约67亿美元的收入。2014年,他们只创造了6.34亿美元—这一指标将以每年40%的比例增长。
3. 医疗行业加大投资
对这些技术的投资正蓬勃发展。2014年,跨行业IT平均收入支出为3.3 %,但医疗保健提供商的平均支出为4.2 %。大约35 %的医疗保健组织将在未来两年内实施人工智能解决方案,其中一半以上的组织计划在未来五年内效仿。我已经分析了这一趋势,并认识到增长的驱动因素是医疗保健领域的任何业务运营的各种特定需求,包括创建足够安全且遵守隐私保护法的电子医疗保健记录的需求。2012年至2017年期间,电子医疗记录的普及率从40%增至67%;。我发现这一统计数据对于医疗保健领域机器学习的未来至关重要,因为数据的可用性对其发展至关重要。
4. 医疗应用场景
- 机器人辅助手术( 400亿美元)
- 虚拟护理助理( 200亿美元)
- 行政工作流程助理( 180亿美元)
具体场景案例
1. 判断发展中国家的结核病情况
识别图像中的模式(Pattern)是现有人工智能系统中最强有力的一点,研究人员现在正在训练人工智能检查胸部x光片,识别结核病。这项技术可以为缺乏放射学家的结核病流行地区带来有效的筛查和评估手段。
2. 检测脑出血
以色列医疗技术公司MedyMatch和IBM Watson Health正在使用人工智能,通过检测颅内出血,帮助医院急诊室的医生更有效地治疗中风和头部外伤患者。AI系统使用临床洞察力(clinical insight)、深度学习、患者数据和机器视觉来自动标记潜在的脑出血,以供医生检查。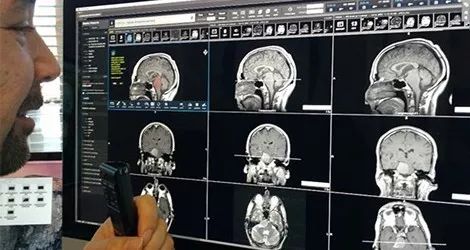
3. 癌症诊断
用于检测和诊断癌症的传统方法包括计算机断层扫描( CT )、磁共振成像( MRI )、超声和X射线。不幸的是,许多癌症无法通过这些技术得到足够准确的诊断,从而可靠地挽救生命。微阵列基因图谱的分析是一种替代方法,但这项技术需要计算很多小时,除非这项技术可以使用AI替换。现在已经被证明,斯坦福大学的人工智能诊断算法与由21名经委员会认证的皮肤科医生的团队一样有效地从图像中检测潜在的皮肤癌。Startup Enlitic正在使用深度学习来检测CT图像中的肺癌结节,其算法比作为一个团队工作的专家胸科医生的准确率高50%。
4. 机器人辅助手术
在价值潜力方面,机器人辅助手术是人工智能辅助方向的佼佼者。AI-enabled机器人技术可以通过集成实时操作矩阵、来自实际手术医生的数据以及来自手术前病历的信息来提高和指导手术器械的精度。事实上,埃森哲报告说,人工智能机器人技术带来的进步缩短了21 %的停留时间。
小结
我们不应该对机器学习和人工智能将如何改变我们所知道的医疗保健行业感到太兴奋。如果我们想看到这些变化发生,人们还有很多工作要做。事实上,在这种情况下,人的因素对这一成功至关重要。此外,提出这一议题可能对参与这一进程的各方机构造成不必要的压力。Kevin Pho大概总结行业情况,Kevin认为,我们需要将重点转移到将我们的优先事项(priority)和工作流程转换到模型上,以便技术能够以我们需要的方式改进医疗保健。
科技是伟大的。但是人和过程改善了护理。最好的预测只是建议,直到付诸于实际行动。在医疗保健领域,这是最困难的部分。成功需要与人交谈,并花时间学习环境和工作流程—无论供应商或投资者多么不愿意相信这一点。如果能够通过安装软件来实现医疗保健行业的转型,这将是一件非常棒的事情。
历史上总会有过度宣传技术的案例,但人工智能和机器学习绝对不在其中。
尽管我们处于技术的新生边缘,其潜力几乎没有被理解,但由于人工智能和机器学习,医疗保健行业正经历着生产力和收入的大量涌入。大多数主要的医疗保健机构已经在投资人工智能,以此来确认人工智能在当前和未来行业中的作用。
普林斯顿 - 根据邮政地址数据收取不同费用
价格歧视问题不仅仅存在于打车软件和电商软件。《普林斯顿评论》会根据邮政地址数据收取不同费用。在亚裔较多地区的费用是非洲裔较多地方的2倍。整体价格判断基于邮政编码数据。
资料来源:ProPublica 收录时间:2020年7月 文章日期:2015年9月 原文链接英:https://www.propublica.org/article/asians-nearly-twice-as-likely-to-get-higher-price-from-princeton-review
背景
每年,通过《普林斯顿评论》的考试准备服务,成千上万的高中学生为SAT做好了准备。但是大多数人都不知道这个服务的价格是有区别的。
根据邮政编码数据定价
《普林斯顿评论》在线SAT辅导包的价格根据客户居住地的不同而有很大差异。如果他们在公司的网站上键入一些邮政编码,他们将以低至6,600美元的价格获得《普林斯顿评论》的总理课程。对于其他邮政编码,同一门课程的费用高达$ 8,400。
采用地理定价方法的一个意想不到的影响是,亚洲人获得的价格比非亚洲人价格高出近一倍。数据来源是Haigh的一位同学在公共网站上发布的代码收集到的数据。数据显示,《普林斯顿评论》为同一“高级”在线辅导包提供了四种不同的价格。
许多价格是地区性的。例如,整个纽约市区域,包括长岛,都获得了最高的价格,为8,400美元。除了圣地亚哥之外,加利福尼亚州的大部分地区价格都居第二位,为7,200美元,而圣地亚哥的邮政编码则是最低价。
分析表明,高收入地区获得更高价格的可能性是普通人群的两倍。例如,华盛顿特区的富裕郊区收取较高的价格。但是,情况并非总是如此:达拉斯富裕社区的居民收取的最低价格为6,600美元。
不论收入多少,亚洲人口密度高地区的客户获得更高价格的可能性是其1.8倍。例如,加利福尼亚州威斯敏斯特市这个肮脏的工业城市的居民被收取了第二高的价格,该城市是中产阶级,而中产阶级的收入低于大多数。
公司声明
《普林斯顿评论》声明说。这些类型的价格差异不是非法的,其后果不是故意的,但研究人员表示,在像Uber这样的服务时代,这种差异可能会变得越来越普遍,Uber通过计算机算法确定价格。《普林斯顿评论》说,它的价格仅由地理区域决定。
《普林斯顿评论》说,称其定价行为为歧视是错误的。该公司在声明中说:“将这种基于地域的定价所造成的偶然影响等同起来,这种普遍定价在美国所有商业中都带有歧视性,因此误解了该词的字面,法律和道德含义,”该公司在声明中说。
该公司表示,其在线补习服务的价格是根据当地补习老师的价格而定的,“实际上就像每种商品或服务所做的一样,无论是汽油,房租还是鸡蛋”。
小结
即使价格差异不是故意的,哈佛大学的学生说他们发现它们令人不安。发现变化的学生Haigh是经济学专业的学生,他说,除非特定的人口群体受到影响,否则他一般不会反对价格差异。
在现实世界中,我们对于不同位置提供相同服务的不同价格已经接受。比如不同加油站的油价,不同超市的可乐价格。或者洗车以及服务费用。
价格歧视让人感到愤怒的地方是即使使用同一种服务,也会得到不同价格。比如两个好朋友一起打车,但出租费却不一样。同一件在线商品不同账户购买价格也不同。
这篇文章介绍的内容是,在购买线上服务时,可以只根据邮政编码就能进行不同定价区分。在教育行业也实现价格歧视。
Linkein - “数据团队”的产业化才刚开始
“数据科学家”或许不再性感,但“数据团队”的产业化才刚开始。本文介绍了领英的数据团队结构和职责变迁。
资料来源:大数据文摘 文章日期:2020年7月 摘录日期:2020年7月 原文链接:https://mp.weixin.qq.com/s/fYhT7f6_qKeirkdzkg7vvA
领英的数据科学团队
1. 数据科学家来历
2008年,正是在这家公司,DJ Patil建立了全球首个真正意义上的“数据科学团队”,并开始用“数据科学家”(Data Scientist)这个词来描述这些Data man们的工作性质。在这之后,“数据科学家”开始被誉为21世纪最性感的工作,也成为全球技术精英们近年来最理想的职位之一。
尽管已经过去了十多年,但当我们请领英全球数据科学团队负责人许亚给数据科学团队下个定义时,她还是表示,这不容易。尽管数据科学在学术领域的概念50多年前就有了,但作为职业,相比业内更多成熟的团队和路径,这依然是个相对很新的概念。
2. 领英的数据科学家团队
“对于领英来说,数据科学团队的整体趋势更加走向专业化,他们的职责不再是建立数据基础设施或平台,而是怎样去使用数据科学和工程来最大化数据的价值。”
“嵌入式工作,中心化管理”,数据科学团队更加“专业化”、“工程化”
和多数互联网公司一样,领英的数据科学团队规模也在近几年飞速增长。许亚表示,仅是近两年来,领英的数据团队扩张了近一倍,从150人增加到目前的300多人。数据团队是指领英中心化的数据科学部门。如果用一句话来概括领英的中心数据科学团队的运作方式,那就是“嵌入式工作,中心化管理”。
和国内不少互联网公司将数据分析师归属于业务BU、向业务主管汇报不同,领英的数据科学团队成员由许亚的中心部门统筹。虽然在项目工作上,数据科学家们依然会在工位分布和职能上与业务部门紧密联系,但是从职级从属上,都直接向许亚汇报,不同领域的数据科学家在工作中会有交集,还会一起开会。
3. 工作方式:数据团队与工程团队紧密相连
目前领英的数据科学和人工智能团队都在同一个大组里,数据团队和人工智能/工程团队是紧密相连的。这也从一个侧面说明,随着对数据科学团队的需求逐渐增大,数据团队的工作会越来越“工程化”。跑的数据会越来越多,对工程团队的需求也会越来越大,需要对工程团队越来越多的要求和技术定位。
4. 数据团队3个工作方向
- 工程专家:可以很有效的建立起数据管道(data pipeline) 和数据流 (data flow);
- 算法专家:在预测、算法领域的技术咖;
- 业务专家:有很强的业务属性,将数据见解和公司战略结合起来;
由于工作侧重不同,在管理的过程中也会有意的区分这三类数据科学家,并且保持各类员工的竞争力。
团队KPI
1. 数据易得性和工作效率
数据易得性,指的是当外界需要数据的时候,获得这些数据的难易程度;工作效率,指的是一个人的工作是否可以提升整个团队的工作效率。
数据科学家之前被人诟病过于追求新鲜感,喜欢挑战高难度问题,但做完MVP (Minimum Viable Product) 后没有维护迭代的习惯,永远都在追逐下一个新难题。数据团队拥有许多数据资源,比如原始数据,指标数据,数据模型,数据可视化。
有些数据科学家做了一个很不错的分析,但是不太关心怎么把这个分析过程自动化,所以每次有人提需求的时候就需要有人再手动跑一次模型,其实都是重复劳动,不同的人在做相同的重复劳动。如果这个分析实现了自动化,大家都可以享用,其他人就不需要花太多时间精力在这个模型上,整个数据科学团队的集体工作效率都提高了。
2. 战略化思维
战略化思维,指的是数据分析结果对公司重要战略性决策是否有指导作用。
数据团队和公司很多高层会打交道,因为他们团队有一个很重要的职责就是通过数据来确保公司重要决策的大方向是准确的。比如他们需要了解用户在疫情期间是如何使用领英服务,如何通过领英的产品获取价值的。
在疫情后,用户的行为多少会发生一些不可逆转的改变,数据可以帮助团队更好地去学习用户行为变化,从而在战略上指引公司对哪些领域进行重点投资。不管是产品开发还是市场战略的决定,都需要依靠数据。
3. 直接商业影响力
直接商业影响力 (Direct Business Impact),指的是工作成果对公司商业目标的直接影响力。每个部门的工作开展是和公司要实现的大目标息息相关的,领英有公司层面的四个核心指标,数据部门在计划工作的时候,需要考虑如何对公司的商业目标产生积极影响。
AB Test
我们都知道,企业在做产品/功能测试时一般都会用到 A/B test ,即分为两组用户,一组对照组,一组实验组。对照组采用已有的产品或功能,实验组采用新功能。要做的是找到他们的不同反应,并以此确定哪个版本更好。A/B test 能对大范围的事情进行测试,例如亚马逊对个性化推荐进行 A/B test 后,发现个推能显著提升收益;谷歌在对搜索广告进行排名时也用到了A/B test。
许亚和Ron Kohavi、Diane Tang共同写的一本书关于A/B Test 的书籍《Trustworthy Online Controlled Experiments: A Practical Guide to A/B Testing》,在今年4月出版了,书里有很多关于A/B Test的例子。
基本上我们在领英网站上能感知到的更新,领英团队都会做A/B Test,有些是前端的改变,有些是后端系统的调整。当你打开领英APP,从搜索栏,搜索引擎算法,底部导航,到页面文字大小,这些都是经过A/B Test的。领英的产品文化以用户为主导,领英自己不会去假设用户喜好,一切都通过数据来说话,而不是靠谁的直觉。除了看得到的东西,后端用户看不到的,领英也会进行A/B Test。比如打开APP要加载内容,需要从后端系统里获取数据,每次获取20条数据还是100条数据,这个决策就涉及到平衡与取舍,获取数据越多,页面加载时间越长;获取数据越少,用户浏览的时候就需要频繁刷新。所以到底一次获取多少数据,领英还是通过A/B Test来决定。
领英有非常完备的A/B Test平台,可以解决大部分实验需求,包括实验设计、实施和分析,所以数据团队不需要介入到每个A/B Test。这对推广实验文化和数据文化很有帮助,因为大家都可以去做实验,享受数据和实验带来的好处。领英内部每天大概有100个新实验在进行,数据团队无法关注每个实验,但是会集中关注一些重要的实验,深入参与到研究和分析工作中。
在领英以数据为主导的文化浸染下,长远来看所有人都受益于这样科学的决策机制。也因为有A/B Test的文化,所以可以跳过争论,直接做个A/B Test就见分晓了。整个过程简单公正,方案落选的组也可以通过这个机会学习到一些关于用户的新知识。A/B Test提倡数学引导的创新,这种创新不取决于谁的职位更高,因此任何团队都可以放心大胆的去做测试来发掘新点子。
领英的社会责任
领英对公平的定义是,拥有同等才能的两个人,应该获得同等的职业机会。而不受到种族或者自身人脉的影响。过去两年时间领英做了很多努力来解决公平问题,取得了不错的成果。
1. 领英很重视可量化、可测量的指标
因为如果一个问题没有被数据抓取到,就很难注意到。例如,每次领英发布新产品,都需要通过量化的指标来测量这个新产品对用户带来影响是否公平。一开始领英的测量指标比较粗线条,他们会看这个产品平均下来对用户是否有积极影响,但如果细看数据,有可能这个产品只对一部分人有益,但会损害另一部分人的利益。因此,后来领英采用了一个指数来衡量是否在一个群体内无意间引入了不公平因素,也就是对每个新产品,领英想知道其带来的提升是否是公平的。
2. 领英关注现有平台上是否存在公平问题的盲点
例如一个以男性为主体的数据集,训练出来的模型就更倾向于男性,这是一个隐蔽的不公平点。很多猎头和HR用领英产品来招人,如果算法推荐的候选人都是男性,女性就失去了公平的竞争机会。大概一年前左右领英推出了一个代表性指数来衡量推荐结果对整体数据集的代表性。比如所有可能候选人的男女比例是1:1,那领英给猎头推送的前100位候选人的男女比例也应该是1:1。有了这些量化指标,领英可以更好地规范和规避不公平的举措。
之前领英有一个内推功能,当某个人想申请Google的工作,会收到提示说我的一位好友在Google工作,我可以找他要个内推。上线初期,领英内部对这个新功能很满意,因为可以帮助那些有广泛人脉资源的人更快找到工作,后来领英意识到这个功能会让那些没有人脉资源的人更难找到工作,所以就关闭了这个功能。取而代之的是领英推出了一个新工作快速提示功能,一个新职位刚发布出来,领英会立刻给所有对此类职位感兴趣的用户推送提示。这个功能不仅能帮助所有用户更快找到工作,对那些关系少的人尤其有帮助,因为他们的消息相对更闭塞一点,所以这个功能能让更多的人受益。最近领英也开源了这套技术,希望能助力其他公司去构建一个更公平的社会环境。
其实这个功能能够帮助雇主找到更多的候选人。对雇主更加方便高效。
3. 保护数据隐私
随着近年来数据泄漏事件频频爆发,数据隐私和安全问题被推上了风口浪尖。许亚也跟大数据文摘聊了聊领英在保护用户的数据隐私方面都做了什么。
所以在GDPR这些开始之前,领英在保护用户隐私上已经有了很多投资。许亚提到,除了实现规定里的要求,领英也用一些很前沿的技术去确保不泄露隐私,比如现在认为是数据隐私保护的“Gold Standard”——差分隐私(Differential Privacy)。
领英全球有超过6.9亿用户和5000万家企业,领英的愿景是为全球劳动力市场中的每一位创造经济机会,通过将所有在领英平台发生的行为数据可视化,进而打造全球“经济图谱”。因此用户数据对领英至关重要,如果没有用户的信任,领英就没有办法去实现他们的愿景和使命。
差分隐私只是一种保证。假设你的信息在一堆数据里面,如果把这些信息删掉,再运行同样的一些算法,从数据当中得到的两个的结果都是一样的。相当于你的数据在或者不在这个数据库里面,最后对于得到的信息没有影响。这样用户就不需要担心他们的数据隐私被泄露。领英三年前就开始针对数据隐私问题进行一些重要的研究,同时也有一些比较成功的应用,例如最近一个针对广告商的产品,客户想要用领英的API去获得一些信息,比如用户互动量前十的文章,像这样一些集合的信息,领英也用差分隐私去确保用户的信息不泄露。
3. 利用数据优势,帮助个人应对不确定性
今年,一场突如其来的疫情,全球的劳动力市场都受到了不同程度的影响,不论是就业还是工作方式都迎来了一种新常态。领英利用数据优势,实时展现劳动力市场的趋势变化,帮助个人更好地应对当下的不确定性。在分析数据时,领英还发现不同分组内的用户受到的影响程度不一样,比如刚入职场的新人会受到更大的冲击,疫情对女性的负面影响可能大于男性。
通过数据观察到这些问题后,领英数据科学团队和业务部门迅速沟通,快速响应,针对各个市场及时提供了一系列有针对性的服务来帮助这些人,让每个人都能在自己能力范围内获得平等的工作机会。
Testin - AI时代的互联网金融智能运营实践
A/B测试,让数据产生价值。
资料来源:Testin 文章日期:2018年8月 摘录日期:2020年8月 原文链接:http://ab.testin.cn/blog/testindataai_internetfinance.html
Testin公司

Testin是一家2011年成立的公司,是一个以AI技术为基础的互联网App服务商,其中的A/B测试平台为公司提供了智能化的A/B测试引擎。公司的A/B测试在金融行业服务范围接近全国一半的银行,包括四大行里的三家。接下来我们就以金融业App AB测试的例子,来了解下 A/B测试在App应用中的价值。测试!增加哈哈哈!
A/B测试

由于金融APP的普及,整个公司的功能都要在App中体现,这对App设计的结构、层次、样式等展示问题是一个非常大的挑战。比如说App中常有的首页推荐内容,到底是用什么方式、在什么位值、如何展示等等都是一个会影响用转化率的问题。
通过使用A/B测试,给其中一小部分比率用户看到不同的页面,进行不同方案中的对比。再通过收集得到的数据进行分析。通过上线结果更好的方案,提高转化率,提高公司收益。
A/B测试的好处是使用统计学实验的方法进行了效果的客观判定,而不是靠设计师或者高管的经验来判定。当然,在最后方案的选择时,还会依据公司其他因素做综合决策,但是A/B测试的结果在以数据驱动的决策过程中也能够提供很多靠经验得不到或者不准确的数据支撑。
结果收集

如图所示,左右两个版本的区别所在是色系和推荐图不同。通过数据的收集与分析,可以得出左边红色版本的转化率比蓝色版本转化率要高出3倍,达到了48%。相比右侧蓝色版本的11%,使用红色版本达到了提高转化率的目的。
图中左侧的一系列表格展现的数据是和实验相关的基础数据,包括A/B两种方案的随机分配比率(可以进行动态调整),以及访问人数及成交额等数量。右侧的一系列图标则展示了A/B两个测试的统计分析结果,包括销量对比,子类组成以及地域分布等等。
多渠道版本的A/B测试

另外,由于互联网金融涉及用户广泛,一个推广活动往往有很多备选方案。这种情况就需要合理安排A/B测试的顺序和相互关系。是否先测一组数据,等有了结论再测后续相关的调整数据。又或者是根据地域对颜色偏好不同,对不同地理位置的用户推荐不同色系的测试内容。
比如某互金融互联网公司产品的备选方案如图,有17个版本之多。如此大量的测试,对于投入也十分巨大。但从商业效果来衡量,测试多,可能得到的效果提升也就会变多,如果测试中有5个有了百分之二的提升,总体提升就能够达到10%。
综上,A/B测试对于企业效益的提升有很大帮助,但同时也要注意测试的设计和成本控制。A/B测试的价值能够给企业带来基于统计实验的客观结果,这些结果能够辅助专家、领导结合自己的经验进行企业经营中的决策,改企业带来价值。
B站 - B站给传统企业的数字化营销带来启发
B站出圈是经过深耕细作的结果。
资料来源:DataHunter 收录时间:2020年7月 文章时间:2020年3月 原文链接:https://mp.weixin.qq.com/s/gkTOLHak9csErrneB6st8Q
背景
2019年最后一夜,有一场特殊的跨年晚会,它不是因为疫情,而是因为它没有以任何一个卫视为依托,同时被人民日报点赞为“最懂年轻人的晚会”—— Bilibili(B站)。12月31日当晚观看晚会直播的观众超过8000万人,6天之中回顾视频的播放量达6700万次,网友发送的弹幕多达84.5万条,直接把B站这场“惊艳的’跨次元’晚会”跨年推向各大热搜讨论榜首。
媒体争相报道转评说:10年前以二次元文化起家的视频平台B站已经顺利“出圈”;“补课”成观众在前两分钟刷得频率最高的弹幕;相比各大卫视跨年屡见不鲜的内容,运用大数据分析技术——靠B站用户过去一年的点击和弹幕拼凑出来的节目单,犹如一股清流惊艳四方,俘获年轻人无数。
B站成长路径
早期来B站的原住民主要是被不加广告的海量番剧所吸引,伴随内容从向音乐、舞蹈、游戏、番剧、科技、生活、娱乐、鬼畜、时尚等15个分区延伸,B站在“二次元文化自留地”的身份下,转变衍生出7000多个文化圈层的泛文化社区。总的来说,通过社区生态输出青年文化才是B站的理想,也是B站能够留存用户的土壤。
1. 主流圈子从二次元、游戏过渡生活与娱乐
变化是在2014年5月发生的,“游戏”区累积播放量首次超过“番剧”,之后曾有短暂的交错上位。但在2016年3月之后,游戏区就牢牢占据首位,二次元主导的时代则渐行渐远。之后“生活”、“娱乐”和“影视”区的累计播放量也依次超过“番剧”区。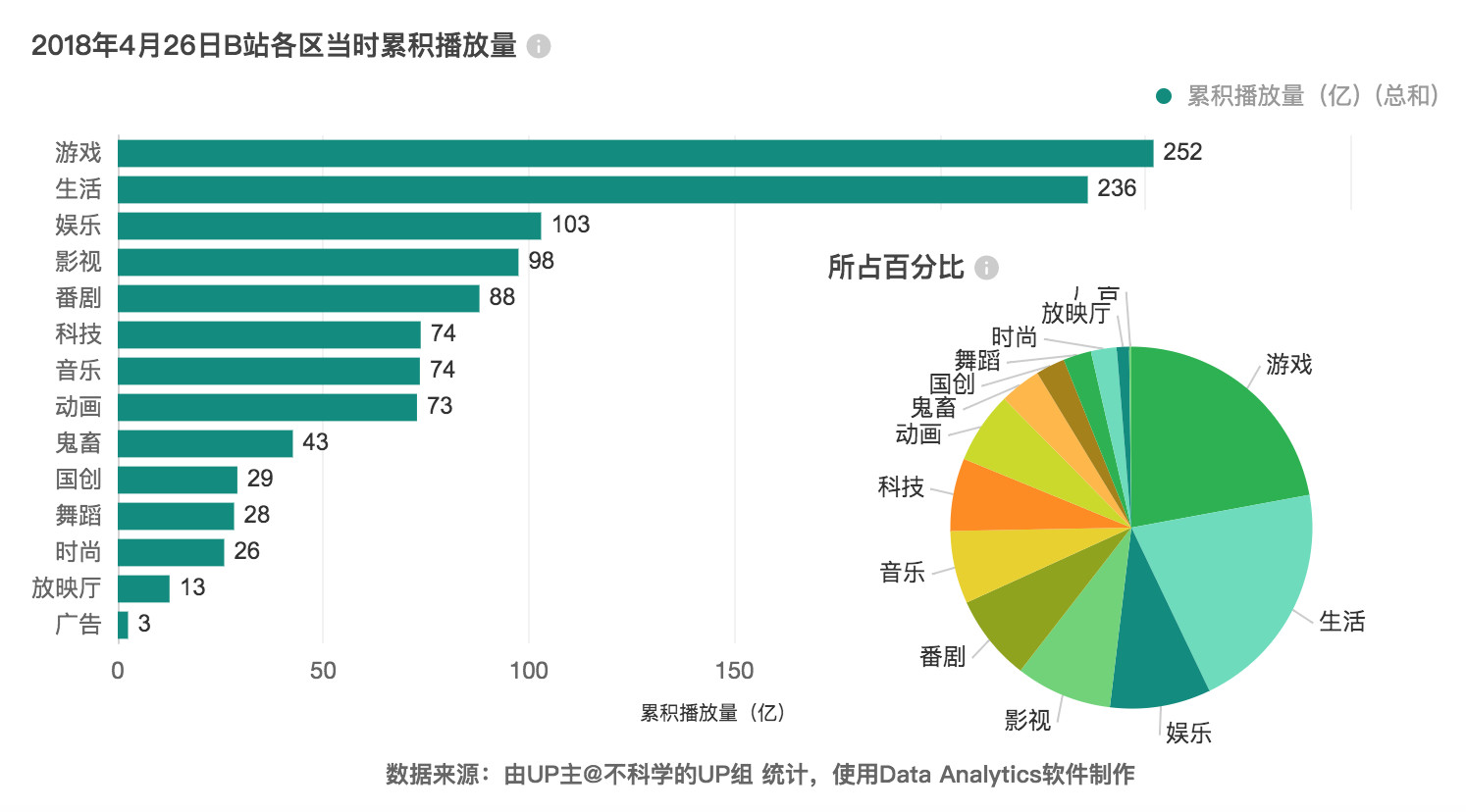
2. 原创生活类视频最能打榜
统计完各二级分区30天内上传(2月10日至3月11日)综合评分TOP20的视频。我们发现,“生活”的头部视频最能打榜,不管是播放量还是弹幕数都远远甩开其他频道。这一定程度上佐证了B站的出圈,另外鬼畜、游戏、动画分别排在生活区之后。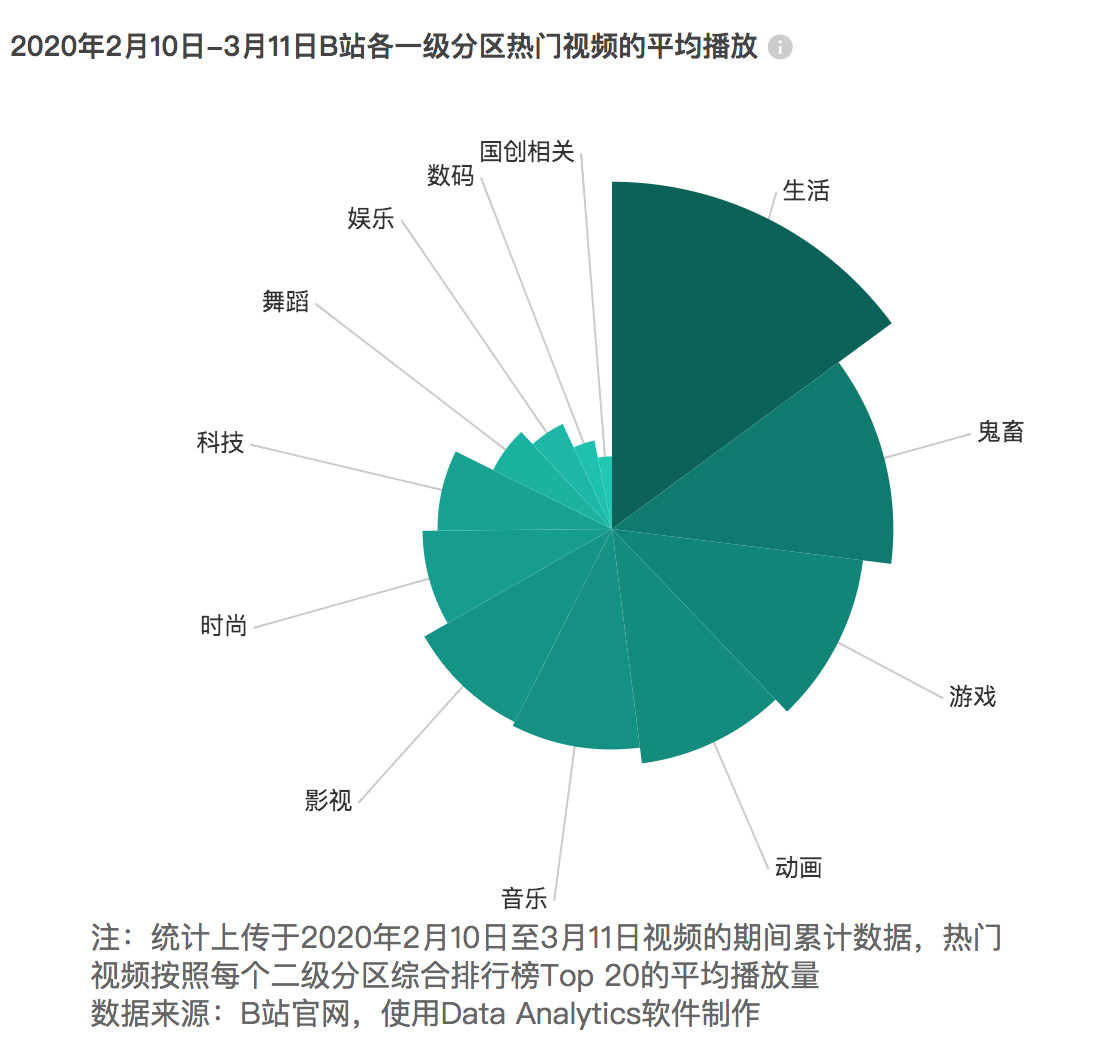
3. 生活、游戏、鬼畜—B站三大主力
在B站公布的2019年百大UP主名单中,有35位来自于生活区,紧跟在生活区后面的是游戏区和鬼畜区。我们简单算了下,这三个分区合计占去了百大UP主中的7成。所以也可以说,生活、游戏和鬼畜,撑起了B站人气的大半壁江山
对于想要了解年轻人到底在干嘛的我们,那些对人气UP榜单贡献大幅上涨的分区更值得关注,它们代表年轻人的精神追求变化方向。从以上数据可得出,B站群众对视频的热爱可以归纳为四大主流:
- 围观生活,生活区贡献了最多的高人气视频,而百大UP主视频中最常出现的“日常”“生活”“吃货”“试吃”“吃播”等标签;
- 云游戏,单机游戏和电子竞技都是百大UP主热门视频的主要集散地,而“单机”“游戏”“网络游戏”“绝地求生”“吃鸡”在百大UP主的视频中也很有存在感;
- 欢乐调侃,这表现在搞笑与鬼畜调教两个分区所贡献的大量人气视频,也有不少明星在这里重新出道。
- 涨姿势,趣味科普人文、影视杂谈等表现出色的分区,多少都是满足了大家涨姿势的需求。
B站如何鼓励内容创造者
B站在形式上和日本的动画弹幕网站相似,在内容产出上和美国的YouTobe相似。但是其内核用户体验是带有情感连结的垂直化社区网站,在B站总会找到你想要的内容。 这份良性的、纯粹的弹幕文化并非一朝一夕习得,而是来自B站长期沉淀的社区土壤和内容生态。
因为UP主既是B站最忠诚的用户,也是内容生产的主力军,他们为B站提供了90%的PUGV内容(Professional User Generated Video,专业用户制作的视频),这些原创或自制的多元化内容,吸引更多用户来互动和讨论,而粉丝对作品的喜爱让UP主产生成就感,激励着更多UP主持续创作更优质的内容,从而形成充满创意、良性循环的生态闭环。

B战对用户的重视和对UP主的宠爱,国内恐怕找不出第二家。从2018年携8名UP主共赴纳斯达克参与敲钟仪式,到推出“激励计划”完善创作者生态,再到BILIBILI POWER UP,B站不仅做到充分尊重用户,更为优秀创作者搭建了一个能够施展才华的舞台。
兴趣是许多年轻人玩B站的初心,强烈的热爱和纯粹的表达欲让同好(有共同兴趣爱好的人)为爱发电,一起分享爱好、欢乐和感动。所以相比其他视频平台,UP主的视频体验更好,内容信息量更密集。兴趣和热爱驱使很多人不计时间、不求回报的来创作,一条3-5分钟的短片,二次创作需要选曲、搜集伴奏、填词、扒谱、调音、混音、压制等流程,最快也要10天才能打磨完成。
B站起步于文化社区,尊重、保护、扶植多元文化的创作者,哔哩一方面注重鼓励UP主提供更多优质内容 ,首先,开放投硬币、充电等方式使UP主得到奖励,使UP主获得认同达到自我实现的需求与一定的经济利益。UP主的优质创作是B站保持高用户粘性的正循环,一方面产出好内容,一方面让创作者产生成就感,促进UP主产出好内容的动力
B站的数字化营销
1. 借助数据,做产品;借助数据,做决策
当B站一个二级分类的内容流量达到一定程度,就会为其开辟独立分区,数码和纪录片就是从科技区拆分出来的,现在的生活、游戏、鬼畜、音乐、舞蹈、数码、时尚、国创等20种分区,都是在ACG基础上不断演化而来。而且其中三个是巨幅流量所在。
文章开头提到的“出圈晚会” 12月31日当晚观看晚会直播的观众超过8000万人,6天之中回顾视频的播放量达6700万次,网友发送的弹幕多达84.5万条,其嘉宾邀请、选品和节目内容,皆出自这一年来每一个专区的点击量、关注度。受欢迎必然是符合预期的。
2. 内容营销方式上需做好品效合一
去年以来,视频平台广告收益受“寒冬”影响而降低的背后,是营销策略的整体转变——规模化投放已不再经济适用,有限资源将涌向具有高品效的平台与KOL。基于社区认同感、深度内容连接与相似价值理念而形成的强用户黏性,也让B站的UP主承载着用户更深层的精神寄托。强用户黏性所带来的“种草力”,是B站各区打通商业变现路径的重要优势。
对于UP主而言,遵循社区的深度内容调性、维系与用户间的强纽带是商业化的前提。对于用户而言,对UP主的强认同感与优质内容的作用使之自发产生了更高的互动量,不仅在于弹幕交流、评论区“课代表”划重点,还有对于品牌方的直接反馈,而这些互动都将反哺以UP主真实的数据。
在未来企业的数字化营销方式上,需基于用户喜好融入其话语体系当中,在内容上找到用户共鸣点,满足圈层用户的文化需求。通过一些圈层化的信息传递或体验互动,进行精准化营销,从而触达有价值的年轻目标用户,让年轻人为品牌年轻化赋能。
3. 美妆、零售等特定行业需善于捕捉B站社区内容趋势
B站一贯保持着对于年轻用户群体的关注,以及对社区的高度敏感。这使B站善于捕捉社区内蓬勃生长的内容趋势,并通过平台的扶持扩大某一品类优势。
比如时尚区,包括宝剑嫂在内的26万时尚区UP主共同激活了B站时尚类内容的生态活力。平台数据显示,他们为B站投稿了163万时尚类视频,带来106亿总播放量与7亿总互动量,创造了超过25万个时尚相关TAG。B站极强的包容性让美妆、产品评测、时尚穿搭、潮流、健身与开箱等内容都找到了生根的土壤。
除此以外,B站也开通直播与电商相关业务,企业可以与UP主从受众的共同兴趣、爱好和人际关系等角度来展开合作,进行极有价值的口碑营销的同时,还能直接打通电商购买的渠道。
小结
一个永远不加贴片广告的B站加上一场出圈的跨年晚会,让B站的出圈已越来越常态化地发生在B站圈层之间。作为Z时代的精神兴趣家园,B站难免会面临商业化的道路,最近陆续布局电竞、发展影业、推出付费大会员等一系列动作即可说明问题。但B站却始终还是在维度用户增长的同时,保持着社区调性,从而继续巩固着下一代文化乐园承诺。
对传统企业的数字化营销来说,未来我们更应该关注年轻人的需求变化,而B站已然成为了一个观察年轻人的入口。在洞察年轻人需求的同时,企业也需要通过数据分析,站在年轻人的角度为他们提供更有价值的服务与体验,只有这样,企业才能把握住Z时代的趋势与变化,从而帮助企业提高业绩。

若有收获,就点个赞吧
0 人点赞
