介绍
Horizontal Pod Autoscaling(Pod横向自动扩容,HPA)属于一种Kubernetes资源对象。通过追踪分析指定RC控制的所有目标Pod的负载变化情况,来确定是否需要有针对性地调整目标Pod的副本数量,这是HPA的实现原理。
工作原理
Kubernetes中的某个Metrics Server(Heapster或自定义Metrics Server)持续采集所有Pod副本的指标数据。HPA控制器通过Metrics Server的API(Heapster的API或聚合API)获取数据,基于用户定义的扩缩容规则进行计算,得到目标Pod副本数量。当目标Pod副本数量与当前副本数量不同时,HPA控制器就向Pod的副本控制器(Deployment、RC或ReplicaSet)发起scale操作,调整Pod的副本数量,完成扩缩容操作。
Metrics Server
官方代码仓库地址:https://github.com/kubernetes-sigs/metrics-server
Depending on your cluster setup, you may also need to change flags passed to the Metrics Server container. Most useful flags:
- —kubelet-preferred-address-types - The priority of node address types used when determining an address for connecting to a particular node (default [Hostname,InternalDNS,InternalIP,ExternalDNS,ExternalIP])
- —kubelet-insecure-tls - Do not verify the CA of serving certificates presented by Kubelets. For testing purposes only.
- —requestheader-client-ca-file - Specify a root certificate bundle for verifying client certificates on incoming requests.
安装
# 下载清单$ wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.4.4/components.yaml# 修改args参数...130 containers:131 - args:132 - --cert-dir=/tmp133 - --secure-port=4443134 - --kubelet-insecure-tls135 - --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname136 - --kubelet-use-node-status-port137 image: willdockerhub/metrics-server:v0.4.4138 imagePullPolicy: IfNotPresent...# 应用$ kubectl apply -f components.yaml$ kubectl -n kube-system get pods$ kubectl top nodesNAME CPU(cores) CPU% MEMORY(bytes) MEMORY%m1 184m 2% 5961Mi 37%
指标采集
metric-server 只是负责数据的中转和聚合,是调用的 kubelet 的 api 接口获取的数据,cgroup文件中的值是监控数据的最终来源。
如:
mem usage
对于docker容器来讲,来源于/sys/fs/cgroup/memory/docker/[containerId]/memory.usage_in_bytes
对于pod来讲,来源于
/sys/fs/cgroup/memory/kubepods/besteffort/pod[podId]/memory.usage_in_bytes
或
/sys/fs/cgroup/memory/kubepods/burstable/pod[podId]/memory.usage_in_bytes
内存使用率 = memory.usage_in_bytes/memory.limit_in_bytes
Metrics 数据流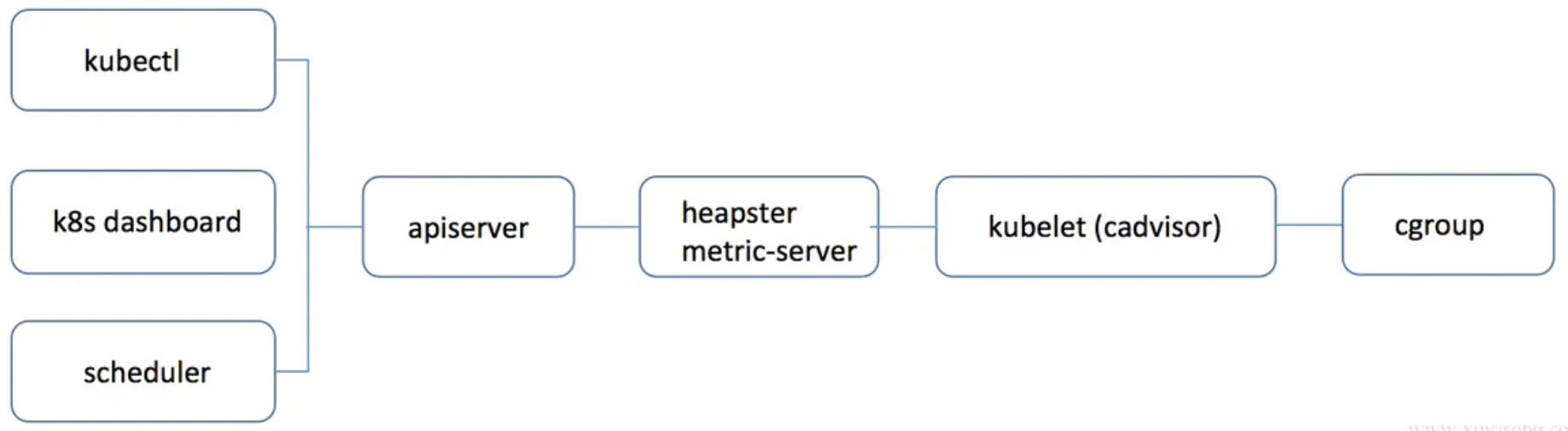
HPA 实践
资源清单(hpa-demo.yaml)
##要 HPA 生效,对应的 Pod 资源必须添加 requests 资源声明
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-demo
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
resources:
requests:
memory: 50Mi
cpu: 50m
应用
$ kubectl apply -f hpa-demo.yaml
$ kubectl get pods -l app=nginx
kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
hpa-demo-6b4467b546-hklvc 1/1 Running 0 7m2s 10.244.0.65 m1 <none> <none>
创建 HPA 资源对象
# 创建一个关联资源 hpa-demo 的 HPA,最小的 Pod 副本数为1,最大为10
$ kubectl autoscale deployment hpa-demo --cpu-percent=10 --min=1 --max=10
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-demo Deployment/hpa-demo <unknown>/10% 1 10 1 16s
# 查看已创建的 hpa 资源清单信息
$ kubectl get hpa hpa-demo -o yaml
验证
# 发起请求
$ kubectl run -it --image busybox test-hpa --restart=Never --rm /bin/sh
If you don't see a command prompt, try pressing enter.
/ # while true; do wget -q -O- http://10.244.0.65; done
# 查看到hpa已经开始工作
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-demo Deployment/hpa-demo 406%/10% 1 10 4 8m3s
# Pod副本数在增加
$ kubectl get pods -l app=nginx -w
NAME READY STATUS RESTARTS AGE
hpa-demo-6b4467b546-hklvc 1/1 Running 0 9m11s
hpa-demo-6b4467b546-qr76w 0/1 Pending 0 0s
hpa-demo-6b4467b546-qr76w 0/1 Pending 0 0s
hpa-demo-6b4467b546-bbgnw 0/1 Pending 0 0s
hpa-demo-6b4467b546-7whrp 0/1 Pending 0 0s
hpa-demo-6b4467b546-7whrp 0/1 Pending 0 0s
hpa-demo-6b4467b546-bbgnw 0/1 Pending 0 0s
hpa-demo-6b4467b546-qr76w 0/1 ContainerCreating 0 0s
hpa-demo-6b4467b546-7whrp 0/1 ContainerCreating 0 0s
# 资源 hpa-demo 的副本数量,副本数量已经从原来的1变成了10个
$ kubectl get deployment hpa-demo
NAME READY UP-TO-DATE AVAILABLE AGE
hpa-demo 10/10 10 10 17m
#当关闭 busybox 减少负载,一段时间后Pod副本数将恢复到原来数值
#缩放间隙:设置kube-controller-manager组件的--horizontal-pod-autoscaler-downscale-stabilization可指定在当前操作完成后,HPA必须等待多长时间才能执行另一次缩放操作。默认为5分钟。
查看 HPA 资源对象详细信息
$ kubectl describe hpa hpa-demo
Name: hpa-demo
Namespace: default
Labels: <none>
Annotations: <none>
CreationTimestamp: Fri, 19 Nov 2021 17:17:44 +0800
Reference: Deployment/hpa-demo
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): 40% (20m) / 10%
Min replicas: 1
Max replicas: 10
Deployment pods: 10 current / 10 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ScaleDownStabilized recent recommendations were higher than current one, applying the highest recent recommendation
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request)
ScalingLimited True TooManyReplicas the desired replica count is more than the maximum replica count
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 4m28s horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 4m13s horizontal-pod-autoscaler New size: 8; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 3m57s horizontal-pod-autoscaler New size: 10; reason: cpu resource utilization (percentage of request) above target

若有收获,就点个赞吧
0 人点赞
