https://juejin.cn/post/6949035394147024933
robots 协议?
urllib模块
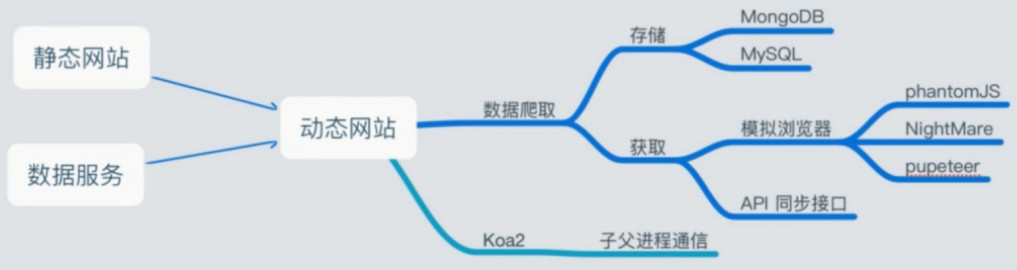
爬虫是什么
- 爬虫是一种自动化程序或脚本,根据设定的数据爬取索引系统地爬取 Web 网页,整个过程称为 Web
- 数据采集 Crawling
- 爬取 Spidering
- 爬虫是自动获取网页内容的程序,是搜索引擎的重要组成部分
- 搜索引擎优化很大程度上就是针对爬虫而做的优化
robots 协议
robots.txt
- 一个文本文件,robots.txt 是一个协议,而不是一个命令;
- robots.txt 是爬虫要查看的第一个文件
- 告诉爬虫服务器上什么文件是可以查看的,搜索机器人按照该文件中的内容来确定访问的范围
Puppeteer
API

cheerio
const express = require('express')const request = require('request')const cheerio = require('cheerio')const app = express()app.get('/', (req, res) => {request('https://www.lulongwen.com', (err, res, body) => {if (err) return// 当前 $ 拿到的是整个 body的选择器$ = cheerio.load(body)res.json({"data": $('header li').length})})})app.listen(3000)
豆瓣 API
- 解决 104
?apikey=0b2bdeda43b5688921839c8ecb20399bhttp://api.douban.com/v2/movie/in_theaters?apikey=0b2bdeda43b5688921839c8ecb20399b
获取用户的浏览器信息
少用 iframe,API接口是趋势

若有收获,就点个赞吧
0 人点赞
