图划分
目标:将图划分为几个包含差不多相等的顶点个数的部分,并且这些部分之间的边数目尽可能地小。(若是有权重的 ,则是各个划分内部的权重和差不多相等,各划分之间的权重尽可能小)
k路划分:
可以不断地执行二路划分 递归的执行 logk 次:例如要求 4 个,那么递归执行 log4 即两次二分,那么就变成了四块。
METIS工作原理: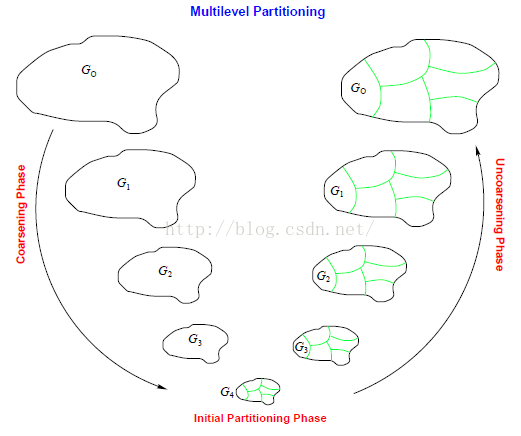
Coarsening Phase
多个节点合成一个节点,有以下几点要注意:
节点的权值为合成的结点的总个数
为保持连通性,新的边为原来的并集
边的权值为并起来的边的个数之和
两种方法:
1.随机匹配,匹配上的点合成一个节点
2.有高度连接的点合成一个点
第二种方法适用于 VLSI 因为其中可能有很多连接紧密的节点。
第一种方法:
一个匹配是 maximal 的,为如果图中任何一个没被选入匹配的边的至少一个端点被匹配了。也即不能有这样的两个邻接点,他们都没被选中,这样的话这个匹配就不是 maximal 匹配
maximal 匹配中,拥有最大的边的数目的是 maximum 匹配
显然,计算 maximum 匹配要比普通的 maximal 匹配消耗的多。
G0 若是 maximal 的,则 Gi 仍是 maximal 的
Random Matching:
随机的访问图上的点,如果遇到一个没有被 match 的点,那我们就随机的找一个这样的点的邻接点,如果存在这样的一个邻接点 v,我们就将边 (u,v) 加入 match,表示 u 和 v match 了,如果没有这样的一个点,那么 u 就保持 unmatched。复杂度为 O(|E|)。因为每次都是合并两个点,所以最多减少一半的点,所以这一轮过后不可能少于原图的一半的点的数目
Partitioning Phase
目的:划分成两个差不多大小的顶点集合(weight 差不多),以及 edge-cut 尽可能小(两个集合间边个数或权值之和尽可能小)
此时的图已经尽可能小了(点的数目小于 100 个)
Kernighan-Lin Algorithm (KL):
首先将图分为两半 A 和 B,定义 gain gv(对于v来说) 为,对 v 的邻接点 u,若 u 和 v 属于不同分区,将(u,v)其权重加起来,减去顶点属于同一分区的(u,v)权重之和。如果 gv 是正的,则将 v 移动到另一个区域中,并且将 edge-cut 减小 gv。如果 gv 是负数,则移动到另一边并且 edge-cut 加上这个负数的绝对值(理解为减去这个负数)。
如果 v 从一边移动到了另一边,要更新 v 的邻接节点的 gain 值。
给出这样的一个定义,KL 算法不断地从较大的一边中选出 gain 最大的 v 并将其移动到另外一边。在移动 v后,标记它那么同一个迭代中不会再考虑它,它的邻接节点被 update,在一个迭代内:原始的 KL 算法会一直移动直到所有节点都被动过了,现在论文给出的算法是 x 次移动之后 edge-cut 就不会再降低了,反而可能会增加(gv是负数的情况),设置 x 为 50 次(即一个迭代 50 次交换)
Uncoarsening Phase
在从 Gi+1 变为 Gi 的过程中,由于 Gi 更加精细了,所以可以有更好的划分方式,基本思想是从 A 和 B 之间选择两个子集合,交换他们能得到更少的 edge-cut。
Kernighan-Lin Refinement:
首先,将 Gi+1 的划分作为 Gi 的划分(因为他已经是一个好划分了),KL 算法将用 3~5 个迭代让它变成一个更好的划分。
在这种情况下,只有一小部份的顶点交换才能让他更好,更多的其他的交换只会让他更差,所以一个迭代内还是只交换 50 次。
KL 算法此时的复杂度取决于将顶点插入合适的数据结构的时间。也就是即使我们减少了交换顶点的数量,总体的时间复杂度也并不会大幅的下降。
METIS主要的特性:
首先,METIS具有高质量的划分结果,据称比通常的谱聚类(spectral clustering)要精确10%-50%。其中Chaco支持谱聚类算法。其次,METIS执行效率非常高,比常见的划分算方法快1-2个数量级。百万级顶点的图几秒钟之内就可以切分为256个类。最后,METIS具有很低的注入元(fill-in ),从而降低了存储负载和计算量。
METIS存在的问题:
没有考虑网络拓扑和带宽信息
搜索空间很大,图很多,规模很大的时候很难做并行化,运行时间较长

若有收获,就点个赞吧
0 人点赞
