0.Abstract
图卷积网络(GCN)在过去三年中引起了极大的关注。与其他深度学习模式相比,GCN的高性能硬件加速同样重要,但更具挑战性。由于真实世界图的大尺寸、高稀疏性和不规则非零分布,数据局部性差和冗余计算会产生障碍。
在本文中,我们提出了一种新的用于GCN推理的硬件加速器,称为I-GCN,它显著改善了数据局部性并减少了不必要的计算。该机制是一种新的在线图重构算法,我们称之为islandization。该算法发现具有强内部连接但弱外部连接的节点簇。孤岛化进程产生了两大好处。首先,通过处理孤岛而不是单个节点,可以实现更好的片内数据重用和更少的片外内存访问。其次,由于可以重用岛中公共/共享邻居的聚合,因此冗余计算更少。图岛的并行搜索、识别和利用都是在增量管道中运行时纯在硬件中处理的。这是在没有任何图形数据预处理或GCN模型结构调整的情况下完成的。实验结果表明,I-GCN可以显著减少片外访问并剪除38%的聚合操作,从而在CPU、GPU和现有技术GCN加速器上分别实现平均5549×403×和5.7×的性能加速。
1.Introduction
卷积神经网络(CNN)[26]和递归神经网络(RNN)[33]等传统深度学习范式已被证明非常有效,但主要用于使用欧几里得数据的应用[15、16、42、44]。然而,许多其他应用要求数据点之间的关系保持不变,因此必须使用非欧几里得数据结构,例如图[10、32、36、46、49、56]。为了满足这一需求,提出了图神经网络[6、11、25、50]。图卷积网络(GCN)是一种GNN,由于其从图数据中提取潜在信息的独特能力,在过去三年中引起了极大的关注。GCN的实际应用包括预测级联电网故障[32]、电子商务[49]等[10、36]。在这些应用程序中部署GCN通常会对延迟和吞吐量造成严格限制。为了满足日益严格的性能要求,迫切需要为全球通信网络设计高性能硬件加速器[14,48]。现实世界中的图往往具有大尺寸、高稀疏性和极不平衡的非零分布;因此,现有方法(如稀疏CNN[19、23、52])的直接应用已被报道不足[2、17、27、45]。我们简要讨论了GCN加速器中使用的两种主要图聚合方法的性能挑战:
- 在基于 PULL 的聚合节点是按顺序计算的,但是对于每个节点: 同时收集(即拉)邻居特征进行聚合。Pull 方法的优点是,由于节点是按顺序处理的,所以一个小的缓冲区足以容纳聚合结果。换句话说,它对结果矩阵有很好的重用性。然而,主要的问题是访问特征矩阵的数据局部性差。考虑到现实世界中图的邻接矩阵通常是非常稀疏和不平衡的,相应邻居特征的并行提取就是随机且不合并的。因为特征矩阵可能太大而无法装入片上存储器,需要反复进行不规则的片外数据访问,这个过程受到片外带宽的限制。HyGCN [48]使用 PULL 方法。虽然使用了数据感知稀疏消除硬件来减少片外数据访问,但仍需要多次访问特征矩阵。需要HBM(高带宽内存)以避免硬件不足。
- 在基于 PUSH 的聚合节点并行计算,但节点的特征数据按顺序分布(即推送)到它们的邻居进行聚合。这避免了访问特征矩阵时的不规则性,但本质上将负担转移到了结果矩阵。假设节点的聚合是按顺序处理的,则需要一个大缓冲区来保存部分结果。如果节点太多,部分结果缓冲区无法放入片内存储器,导致频繁的片外访问和带宽饱和。此外,邻接矩阵中非零的幂律分布会导致严重的工作负载不平衡。AWB-GCN [14]实践了 PUSH 方法,并使用运行时工作负载自动调优体系结构来有效地解决工作负载不平衡问题。然而,它并没有解决结果矩阵的不规则和随机访问的数据局部性问题,这可能是 GNN 处理中最关键的问题,特别是对于大型图。
显然,关键问题是邻接矩阵的不规则性(即非零分布) ,这导致在访问特征矩阵或结果矩阵时数据重用不足。因此,最近的一个趋势是依靠离线预处理来重组邻接矩阵,以改善数据的局部性,例如在 Rubik [8]和 GraphACT [51]中。隐式假设是,图结构(即邻接矩阵)在推理时是固定的,因此在关键路径中可以忽略图重构的巨大开销。然而,情况并非总是如此,因为现实世界的图经常更新(例如,进化图)或动态生成(例如,归纳图)。当在线处理时,高额的重构开销,例如 Rubik 和 GraphACT 中的秒数,是不可容忍的。此外,虽然 Rubik 和 GraphACT 都考虑到了在聚合过程中共享邻居的计算重用的可能性,但是它们复杂的基于软件的重排序算法引入了显著的延迟,只有在离线处理时才是可行的。
在本文中,我们提出了一种新的硬件加速器,称为I-GCN,它实现了一种新的在线图重构算法-孤岛化,可以显著改善数据局部性并减少GCN推理加速的冗余计算。具体来说,I-GCN的岛屿定位器模块在运行时能够检测hub节点(即高度节点),找到它们的邻居,然后将这些邻居节点用作迭代探索和定位岛屿的起点。Islands是一组节点,具有强大的内部连接,但没有外部连接,只有hub连接。注意,岛屿通常(但并非总是)具有实用语义:在社交网络中,它们可能对应于在同一研究所工作的人;在引文网络中,它们可能对应于同一系列会议中发表的论文。确定孤岛并不明显,尤其是在典型的(巨大和稀疏)邻接矩阵中。
图1给出了 I-GCN 的概述。(i)岛屿定位器: 在识别出岛屿后,邻接矩阵的非零点高度聚集-hubs和islands的非零点分别形成 L 形和反对角线。(ii)岛屿消费者: 利用hub和island信息,岛屿消费者以细粒度的流水线方式进行聚合和组合。跳过冗余聚合。这个过程一直持续,直到所有节点都被确定为hubs或islands。孤岛化的好处有两个方面: (1)改善片上数据的局部性。通过聚类,可以将对特征和结果矩阵的访问限制在更小的工作集中(即图1中的每个L形和孤岛)。这大大提高了片上数据的重用性,并避免了大量的片外访问。(减少冗余计算。集群之后,集群中的节点倾向于共享大部分公共邻居。在 GCN 聚合过程中,不需要对每个邻居进行重复计算,而是将公共邻居的聚合信息作为一个整体进行分布和重用,避免了对公共邻居进行重复的聚合计算。这种邻居共享信息在原始邻接矩阵中大部分是不明确的,但在孤岛化之后就变得清晰了(见图1中的节点1∼4)。总之,孤岛化解决了“拉”和“推”两种方式的局部性问题。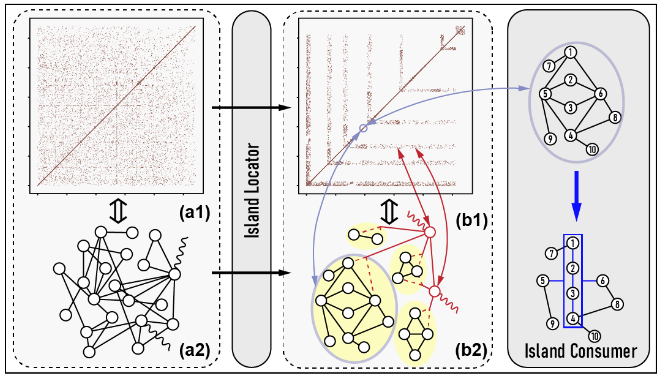
据我们所知,这是第一个解决 GCN 加速的基本数据局部性问题,并通过在线的基于硬件的图重构有效地跳过冗余聚合的工作。这篇论文做出了如下贡献:

若有收获,就点个赞吧
0 人点赞
