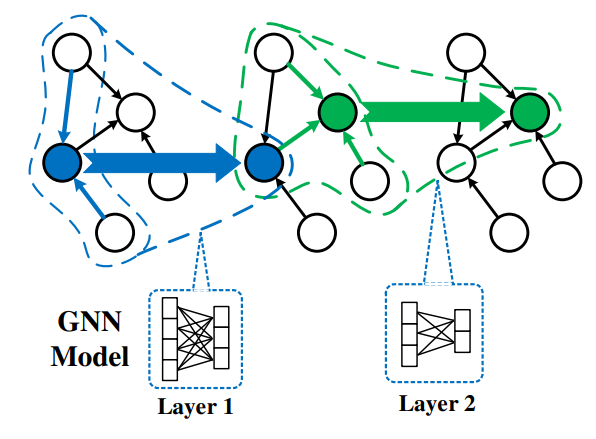
1.以顶点为中心的图迭代处理模型
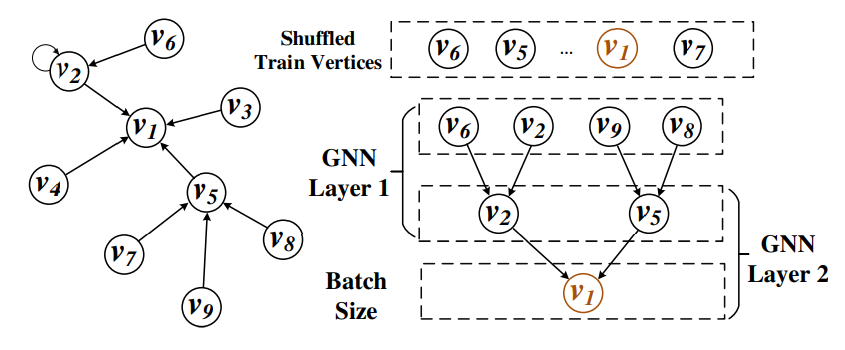
2.L-hop采样
3.图分割分布式训练策略(并行计算)
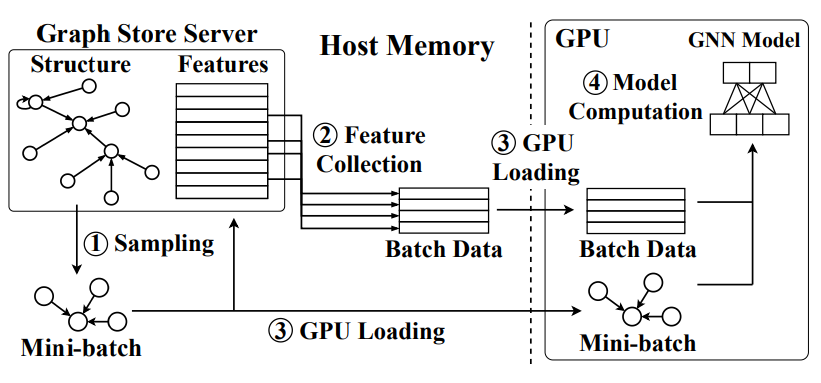
对于一个有N个GPU的机器,整个图会被划分为N个子图,子图经过采样后形成mini-batch.这些子图的结构信息和顶点特征数据一起存放在CPU共享内存中的一个全局图存储服务器里。N个独立的trainer在自己专用GPU上训练各自分配的mini-batch,使用复制的目标GNN模型,并且有一个自己的保留经常访问顶点特征的cache。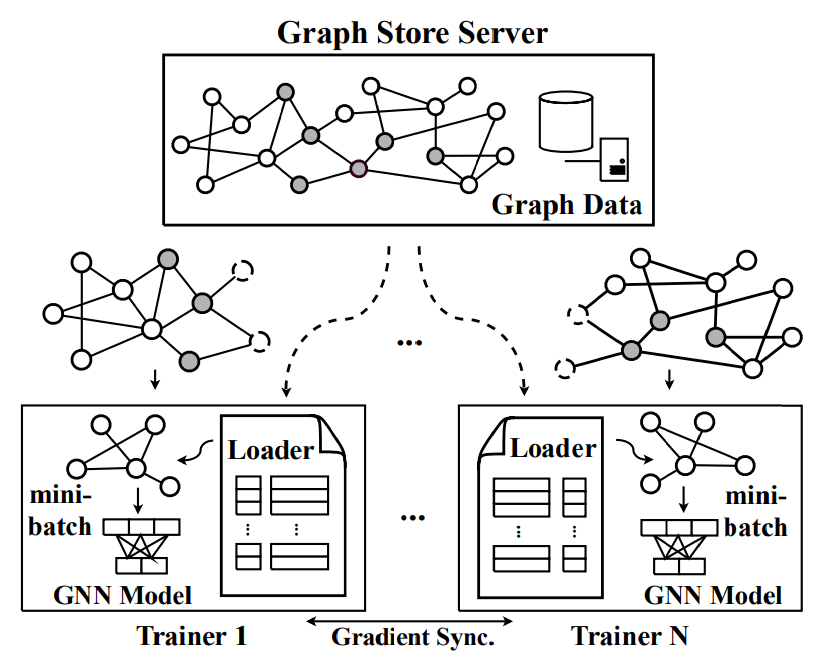
绿色代表本地cache中存有数据,黄色代表没有,需要从图存储服务器中加载。数据全部加载完成之后输入GNN模型中计算梯度,只有每次迭代结束之后Trainer才会和其他trainer之间同步梯度以更新模型参数,其他时间不进行交互。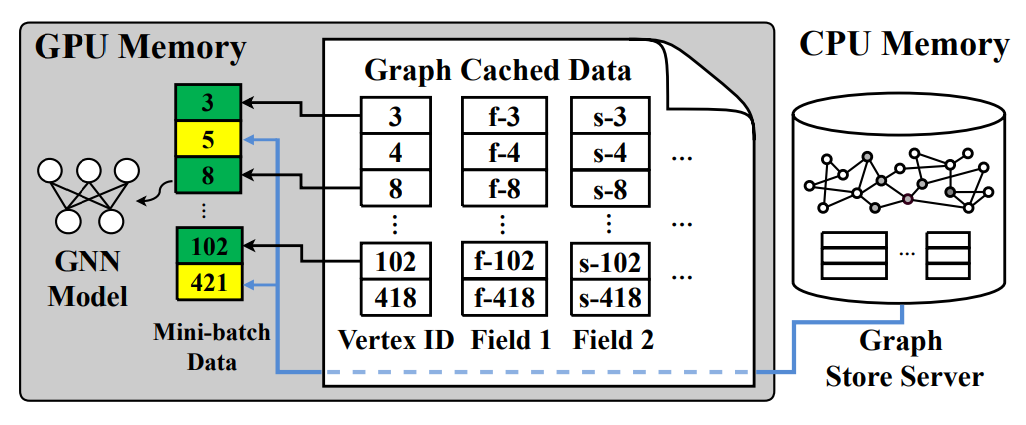
在不破坏算法性质的情况下,图采样过中需要访问被采样顶点的所有邻居顶点。PaGraph 根据图神经网络模型的层数,能确定采样获得的训练子图所需要的层数,即一个顶点最多可能访问的跳数信息。为了避免跨子图访问所带来的额外开销,PaGraph 根据跳数信息在传统图分割的基础上引入最少冗余顶点,来完全避免跨子图访问。
所有分区有相似数量的顶点。虚线是引入的冗余顶点。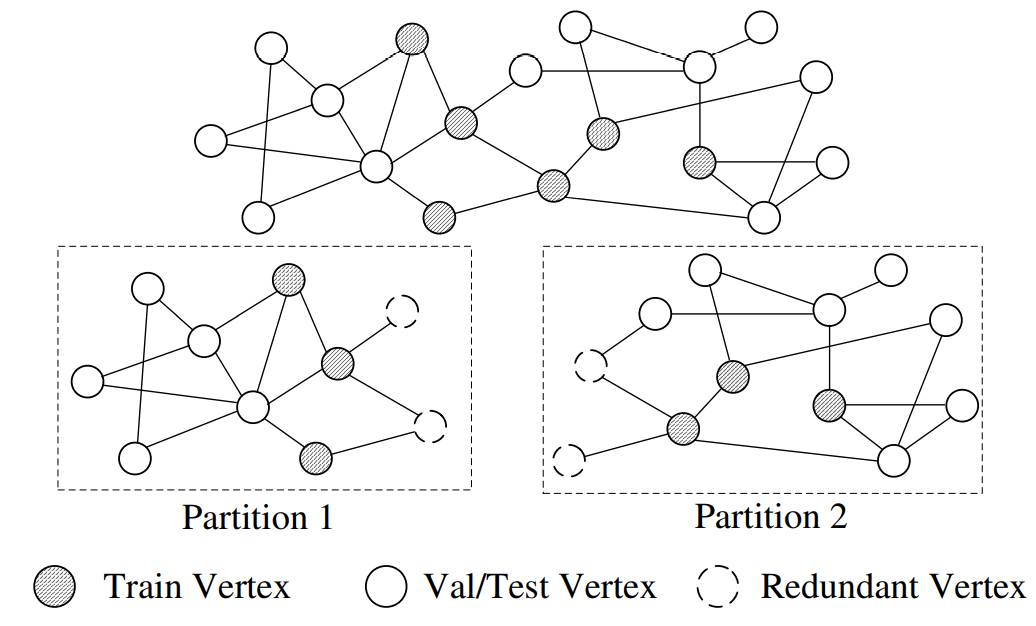
4.流水线化数据加载和模型计算
对于大规模图,GPU内存不可能完全按缓存所有的图数据,因此,数据加载阶段依然制约着GNN训练速度。GNN的训练过程中,不同轮次迭代之间的数据加载时间和模型计算时间几乎相同,因此,可以牺牲一部分缓存空间,在做当前 mini-batch 的模型计算时预加载后续mini-batch的数据,以此将数据加载过程隐藏在模型计算阶段中。
5.缓存策略
对于每个epoch,都需要随机打乱训练样本序列,这使得无法预测每个mini-batch中的顶点。邻居的选择也是随机的,这也无法预测。但是正是这种随机性,我们可以得知如果一个顶点的出度越高,那么他就越可能在epoch中被选中,所以在cache中直接选择高出度的顶点进行存储即可。
动态缓存策略不适合我们这种cache在GPU中的情况,因为GPU不能独立工作,必须把所有GPU上的计算集合起来由CPU启动,并且大多数GNN是轻量级的,所以GPU和CPU之间的图数据交换就成了无法忍受的开销。所以不能即时决定要放入cache中的内容,而是使用静态cache策略。
缓存的时机在第一轮迭代训练结束之后。在获得第一个训练子图结构时,Cacher 还没有缓存图数据,将完全从全局图存储服务中获取所需要的训练数据,并开始记录 GPU 的内存资源使用情况。在第一轮迭代训练完成后,PaGraph 在获得训练过程中 GPU 所需要的内存空间,并将剩余不被利用的GPU内存空间来作为缓存区域。PaGraph 根据当前工作子图的顶点出度,对顶点进行排序,并按照顶点出度从小到大的顺序依次将顶点数据缓存入 GPU 内存中,直至完全缓存或达到分配的缓存空间上限。在随后的每一步训练过程中,PaGraph 通过同时访问 GPU 缓存部分和 CPU 全局图存储服务来完成数据加载过程。
用哈希表实现快速缓存数据的查找。

若有收获,就点个赞吧
0 人点赞
