0.Abstract
大规模图形处理的性能面临着一些挑战,包括局部性差、缺乏可扩展性、随机访问模式和严重的数据冲突。FPGA的一些特性使其成为加速各种应用的一个有前途的解决方案。例如,片上块RAM可以为随机数据访问提供高吞吐量。然而,单个FPGA芯片上的大规模处理受到有限的片内内存资源和片外带宽的限制。使用多FPGA架构可以在一定程度上缓解这些问题,同时应考虑数据分区和通信方案,以确保局部性并减少数据冲突。本文提出了基于多FPGA架构的大规模图形处理框架ForeGraph。在ForeGraph中,每个FPGA板仅将整个图形的一个分区存储在片外存储器中。减少了分区上的通信。顶点和边缘按顺序加载到FPGA芯片上并进行处理。在我们的调度方案下,每个FPGA芯片并行执行图形处理,没有冲突。我们还分析了系统参数对前置图性能的影响。我们在Xilinx Virtex UltraScale XCVU190芯片上的实验结果表明,在Twitter图(14亿条边)上执行PageRank时,ForeGraph的性能比最先进的基于FPGA的大规模图形处理系统高出4.54倍。在我们的设计中,平均吞吐量超过900 MTEPS,比以前的工作大2.03倍。
1.介绍
随着对数据分析需求的不断增长,发现数据之间关系的大规模图形处理在许多领域得到越来越多的关注[1]。以前的工作已经提供了大规模的图形处理系统,包括基于CPU的[2、3、4、5、6、7、8、9、10、11、12、13]、基于GPU的[14、15]、基于FPGA的[16、17、18、19、20、21、22、23]和新兴系统[24]。
正如本文所强调的,大规模图形处理的关键问题是提供高带宽的数据访问[25,26]。然而,大规模图的一些特性给充分利用带宽带来了挑战。这些挑战包括:(1)局部性差。图表示实体之间的非结构化关系,因此一个小分区可以访问整个图。较差的局部性导致频繁的全局数据访问,而在最先进的计算平台中,只有局部数据访问将具有较大的带宽。(2) 缺乏可扩展性。在大规模图形处理中,通过分区进行通信会导致大量通信。因此,很难设计一个可扩展到较大图形的系统。(3) 随机数据访问模式。两个相邻顶点的数据访问模式可能非常不同。图的这种非结构化特征随机化了图数据访问模式。(4) 严重的数据冲突。来自不同分区的顶点可能同时读取/写入同一顶点,从而导致严重冲突。此外,不可预测的数据访问模式为避免冲突带来了巨大挑战。为了提供高带宽和设计高性能的大规模图形处理系统,需要仔细考虑这四个挑战。
为了应对这些挑战,在以前的工作中已经设计了许多解决方案,其中大多数主要集中在充分利用带宽上。GraphChi[4]将一个大型图划分为几个intervals,并将shards作为顶点和边的分区。在分区方案的基础上,通过轮流访问每个分区来确保局部性。之前的一些工作[10、18、4、23]也对数据进行了排序,以消除图形数据访问的随机性和冲突。然而,需要计算执行前排序数据的预处理开销,尤其是当图形在运行时可能发生动态变化时。与CPU和GPU相比,片上BRAM具有随机访问特性,可以在FPGA上实现高吞吐量的随机数据访问。然而,一个FPGA芯片的片上BRAM的大小远小于大型图形的典型大小。因此,使用多FPGA架构是提供更大片上BRAM资源的一种有前途的方法。然而,大多数基于FPGA的系统设计用于一块FPGA板[23]或需要全局可访问内存[18],对于较大图形的可扩展性较差。
为了提供一个基于多 FPGA 架构的高性能大规模图形处理系统,我们设计了 ForeGraph。我们把图划分成小的分区并且把每个分区部署到一个FPGA板,以确保数据访问的局部性。通过最小化不同 FPGA 板之间的通信开销,使 ForeGraph 可扩展到大型图形。为了避免随机数据访问,顶点和边按顺序加载到 FPGA 芯片上。每个分区被进一步划分为更小的分区,并被分配给 FPGA 芯片上不同的处理单元(PE) ,从而消除了冲突。这种多 FPGA 结构可以提供足够的片内 BRAM 资源和片外带宽,对于提高基于 FPGA 的大规模图形处理系统的性能至关重要。具体而言,本文做出了以下贡献。
- 可扩展的多FPGA图形处理。多FPGA架构提供了具有随机访问特性的大型片上BRAM资源和足够的图形数据访问片外带宽。数据分配给每个FPGA板,而不是存储在全局可访问内存中(例如[18]中的共享顶点内存)(第3.2节和第3.3节)。此外,电路板之间的通信开销最小化(第3.4节)。这两种技术使我们的系统可以扩展到更大的图形预处理开销低。顶点和边根据其索引划分为分区(第3.5节)。数据不需要在每个分区内排序,因此预处理的开销减少了(从O(m log m)到O(m),m表示边的数量)。在我们的分区方案下,确保了局部性,并消除了冲突充分利用片外带宽。
- 我们尽量减少单板上的数据传输,以充分利用片外带宽。我们在第4节中采用了几种优化技术。例如,我们压缩顶点索引,仅使用4个字节来表示边(源顶点和目标顶点分别为2个字节),即使图中有数百万个顶点.
- 广泛的实验。我们进行了综合实验,以评估第6节中的性能。在五个图上的实验结果表明,ForeGraph可以在具有数十亿条边的图上执行图算法。ForeGraph的性能比最先进的基于FPGA的系统高出5.89倍,平均吞吐量比以前的工作大2.03倍。
本文的剩余部分组织如下.第2部分介绍了大规模图形处理和相关系统的背景信息。ForeGraph 的整个架构如第3节所示。第4节介绍了一些充分利用片外带宽的优化方法。第5节和第6节从理论和实验角度分析和介绍了前向图ForeGraph的性能。我们最后在第7节对本文进行总结。
2.背景和相关工作
在这一部分中,我们介绍了图处理模型的背景信息。然后,我们将介绍以往基于 FPGA 的大规模图形处理系统。本文中使用的标记如表1所示。
2.1 图处理模型
设 V 和 E 表示图 G 中的顶点集和边集,G = (V,E)上的计算任务是计算 V 和 E 的更新值。我们假设每条边都是有向的,无向图可以通过在每条有向边上加一条相反的边来实现。
Gather-Apply-Scatter:当更新 V 的值时,更新将从源顶点传播到目标顶点。它将更新划分为三个阶段。在 Gather 阶段,顶点从入边的源顶点接收值。然后,在 Apply 阶段计算更新后的值。然后,更新的值被传播到出边的目标顶点。GAS 模型可以以迭代的形式执行。在每次迭代中,每个边都被访问一次,以便将更新从源顶点传播到目标顶点。图1(b)说明了 GAS 模型的三个阶段。
以顶点为中心和以边为中心:如GAS模型中所述,更新通过边从顶点传播到顶点。因此,边的访问顺序区分不同的模型,包括以顶点为中心(VC)模型[6]和以边为中心(EC)模型[12]。在VC模型中,顶点将值发送到所有出边的目标顶点(或者从所有入边的源顶点收集值)。相反,在EC模型中,所有边都是顺序访问的,而源/目标顶点的访问序列是无序的。VC和EC模型都已在以前的系统中实现,并取得了良好的性能。图1(c)显示了VC和EC模型的示例。
基于Interval-shard的分区:图划分是一种广泛使用的方法,它可以确保图数据访问的局部性。GraphChi[4]使用了基于Interval-shard的分区模型。图中的顶点和边被划分为P个Intervals(顶点集)和shards(边集)。后来的系统[10,11]根据源顶点和目标顶点的intervals,将边一步划分为P2块。例如,Bx→y包含从Ix链接到Iy的所有边。图1(d)显示了基于Interval-shard的分区模型的示例。
基于这些模型,以迭代的形式执行计算任务。在每次迭代中,所有块最多访问一次。更新从源顶点传播到目标顶点。算法1显示了使用这些模型的宽度优先搜索(BFS)的伪代码。开始时,根顶点的深度设置为零,其他顶点的深度是无限的。在每次迭代中,边都会被依次访问(请注意,算法1中没有指定边的访问顺序,我们将在实现中解释ForeGraph中的详细顺序)。相应目标顶点的深度将根据源顶点的深度进行修改。通过修改传播代码,这种算法可以很容易地转换为其他图算法。
2.2 基于FPGA的图形处理系统
现场可编程门阵列(FPGA)已被证明是一种很有前途的解决方案,以往的工作已经提供了基于 FPGA 的大规模图形处理系统[16,27,17,18,19,20,21,22,23]。这些系统大多数都是针对单个 FPGA 芯片设计的。其中一些系统只专注于特定的算法,比如广度优先搜索(bFS)或者网页排名(pageRank)。还有许多通用的系统可以应用于不同的图算法,包括 GraphStep [20]、 GraphGen [21]和 GraphOps [22]。GraphStep 和 GraphGen 是将 VC 模型应用于 FPGA 的两个系统。GraphOps 提供了一个模块化的硬件库,用于为图分析算法构造加速器。Shijie 等[23]提出了一种基于 EC 模型的行冲突最小化系统。然而,所有这些系统上的图的大小受到 FPGA 板上的内存资源的限制。
还有一些系统是基于多 FPGA 架构的。Betkaoui 等[17]提出了一种在 Convey HC-1机器上的 BFS 解决方案,该方案由4块 FPGA 板组成。然而,该系统很难应用于其他图算法。FPGP [18]提供了一个大规模的图形处理框架,可以使用共享顶点存储器(SVM)将其扩展为多 FPGA 架构。然而,由于所有 FPGA 板都需要连接到SVM,因此系统的性能和可扩展性受到SVM带宽的限制。
3.系统结构
在本节中,我们将讨论 ForeGraph 的系统架构。详细介绍了 ForeGraph 中的数据分配和处理流程,以及互连方案和分区方案。
3.1 总体架构
ForeGraph 的总体架构如图2左侧所示。ForeGraph 由几块 FPGA 板组成。在每个电路板上,都有一个 FPGA芯片来执行处理逻辑,还有一个片外存储器来存储图形数据。所有电路板通过互连连接。这种互连可以通过总线(例如 PCI-e)、定向光纤连接或其他可用结构来实现。图2右侧显示了详细的处理逻辑。该逻辑包括一个互连控制器、一个片外存储控制器、一个数据控制器、一个调度器和几个处理元件(PE)。
- 互连控制器。FPGA 板之间的数据传输由互连控制器控制。
- 片外存储控制器。片外存储器的数据读/写由片外存储控制器来安排。控制器可以通过使用现有的 IP 核心生成器来实现(例如 Xilinx Vivado 中的内存接口生成器)。在执行图算法时,加载到处理元件的数据都通过该控制器从片外存储器取得。
- 数据控制器。数据控制器连接片外存储控制器和互连控制器。在板间传输数据时,对存储器地址和目标板 ID 进行打包和计算。
- 处理单元(PEs)。PE 是在 FPGA 板上执行图算法的核心逻辑。正如在2.1节中提到的,利用相应的边将更新从源顶点传播到目的顶点。因此,每个 PE 分别包含存储源顶点和目的顶点的源缓冲区和目的缓冲区。源缓冲区和终止缓冲区都是使用通用的双端口 BRAM 实现的。还有另一个边缓冲区存储从片外存储器加载的边**。**边在更新时从片外存储器按顺序加载。顶点和边都被发送到处理逻辑,计算结果并写入目的缓冲区。不同的图算法只在处理逻辑上有所不同。当目的缓冲区中所有顶点的更新完成后,结果将被写入片外存储器,新的顶点和边将被加载到这些缓冲区中。假设片外存储器的带宽约为每板10 GB/s,处理逻辑以200 MHz左右的频率运行。我们使用8个字节来表示一条边(源顶点和目标顶点分别为4个字节)。基于单个PE(200 MHz×8字节=1.6 GB/s)的吞吐量远小于片外存储带宽的事实,使用多个PE可以充分利用片外存储带宽。
- 调度器。调度器连接片外存储控制器和PEs中的数据缓冲器。当从片外存储器加载顶点和边时,调度程序将数据发送到相应的PEs。第3.2节详细解释了不同PEs中的数据分配。
3.2 片外存储器中的数据分配
在 ForeGraph 中图被分为intervals(I)和shards(S)。每个intervals及其相应的shards被分配给 FPGA 板上的片外存储器。例如,在由 P 个 FPGA 板组成的 ForeGraph 系统中,I1和 S1存储在第一个 FPGA 板上。S1由 P 块组成,即 B1→1~BP→1。每个块负责使用不同的源intervals更新 I1。这些源intervals存储在其他 FPGA 板中,并在运行时依次加载到第一个板上。
考虑到一个芯片中有多个 PE,而且每个 PE 包含两个使用 BRAM 的独占顶点缓冲区,随着图大小的不断增长,芯片内存资源不足以存储一个interval。在 ForeGraph 中,我们采用了图3右侧所示+6的两级图分区方案。以第一个interval I1为例,在这个两级图划分方案中,I1进一步划分为 Q 个sub-intervals,SI1,1~SI1,Q 相应地,块 B1→1进一步划分为 Q2个sub-blocks,SB1→1,1→1~SB1→1,Q→Q。每个sub-block负责使用源sub-intervals更新目的sub-intervals。
在执行图算法时,不同的源sub-intervals被加载到不同的 PE 中,而这些 PE 中的目的sub-intervals是相同的。这些 PE 使用相应的sub-blocks更新目的sub-intervals。图3左侧显示了在 ForeGraph 中执行图算法时的数据分配示例。SI1,1~SIK,1分别加载到 PE1~PEK,在所有 PEs 中sub-interval都是 SI1,1。相应sub-blocks中的边加载到每个 PE 的边缓冲区。当所有 PE 完成 SI1,1的更新时,ForeGraph 将替换片外存储器中未使用的sub-intervals,因为 PE 中的sub-intervals可以继续执行图算法。
其他板上的intervals依次加载到本地片外存储器。例如,第一板的处理流程: 使用 I1和 B1→1更新 I1→从第二板加载 I2→用 I2和 B2→1更新 I1→在第一板上丢弃I2,等等。3.3 片上数据替换流
当使用一个interval更新另一个interval时,将访问所有Q2 个sub-blocks。然而,一次只处理K个sub-intervals。因此,ForeGraph计划如何用片外存储器中的sub-intervals替换片上的sub-intervals。图4显示了两种不同替换策略的示例。将一个interval划分为四个sub-intervals,并在芯片上实现两个PEs。
在destination first replacement(DFR)策略中,当两个PE完成更新相同的目的sub-interval时,ForeGraph将其写入片外存储器,并用另一个sub-interval替换它(图4(a)中的步骤1至步骤8)。在使用两个PE中的源sub-intervals更新所有sub-intervals后,ForeGraph将其替换为其他新的sub-intervals(图4(a)中的步骤4到步骤5)。当B1→1中的所有边都被访问之后,将加载其他intervals,ForeGraph将使用这些intervals作为源intervals重复前面的步骤(图4(b)中的步骤9)。
在source first replacement(SFR)策略中,将替换源sub-intervals而不是目的sub-intervals(图4(b)中的步骤1至步骤2、步骤3至步骤4、步骤5至步骤6、步骤7至步骤8)。当一个sub-interval被所有sub-intervals更新时,ForeGraph将其替换为一个新的sub-interval(图4(b)中的步骤2至步骤3、步骤4至步骤5、步骤6至步骤7)。类似地,将加载其他intervals,并在B1→1中的所有边都被访问之后重复前面的步骤(图4(b)中的步骤9)。
DFR和SFR对片外存储器读或写的数据量不同。在DFR和SFR中,都需要处理所有Q2sub-blocks(或sub-intervals pairs)。由于一个芯片上有K个PE,我们需要Q2/K步来完成一个sub-block的更新。例如,在图4中,一个芯片上有K=2个PEs,一个interval中有Q=4个sub-intervals,总共有8(=42/2)步。在DFR中,目的sub-interval(在所有PE中相同)需要写入片外存储器,并且在每个步骤后加载一个新的sub-interval。因此,DFR中目的sub-intervals的读写时间均为Q2/K。此外,所有Q个源sub-intervals需要加载一次。因此,读取/写入的sub-intervals数分别为(Q+Q2/K)和Q2/K。在SFR中,每个步骤后都需要替换所有K个PE中的源sub-intervals。因此,源sub-intervals的读取时间为(Q2=Q2/K×K)。此外,在SFR中,所有目的sub-intervals都需要读/写一次,这导致sub-intervals的读/写次数增加了Q次。根据分析,在SFR中,从片外存储器读取/写入的sub-intervals数分别为(Q+Q2)和Q。
从表2中我们可以看到,DFR 的优势在于sub-intervals的读取时间,而 SFR 的写入时间较少(我们假设1 < K < Q)。让 Tr 和 Tw 表示一个sub-interval的平均读/写时间,公式(1)表示 DFR 优于 SFR 的情况.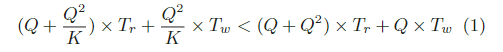
在ForeGraph中,数据存储在DRAM中(相同的读/写带宽,不同于非易失性存储器等其他新兴设备)。因此,可以公平地假设Tr=Tw。公式(1)可以简化为公式(2).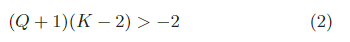
一般来说,一个芯片上有两个以上的PE,这导致(Q+1)(K−2) ≥ 0 > −2.因此,我们在ForeGraph中采用DFR,以最小化芯片和片外存储器之间的数据传输。3.4 Interconnection
许多以前的工作提出了诸如 Catapult 这样的 FPGA 之间的互连方案[28]。在 Catapult 中,多达48个 FPGA 在环形网络中使用 SerialLite III 链路连接。它在每个连接上提供2 × 766MB/s 的峰值理论带宽。每个连接的延迟约为400 ns。ForeGraph 采用Catapult 中的互连方案。在第6节中,我们模拟了网络消耗,并将其与其他网络结构(例如网格、总线等)进行了比较。
与像Pregel[6]这样将消息(来自源顶点的更新值)传输到其他计算节点的分布式系统相比,我们在 ForeGraph 中本地组合消息并更新顶点。只更新传输顶点的值,我们最小化了数据传输量,因此ForeGraph可以适用到更大的图。3.5 Index-based Partitioning
在ForeGraph中,顶点被划分为P个intervals,并进一步划分为P·Q个sub-intervals。边也按其源顶点和目的顶点划分。与Graphchi[4]等以前需要在(子)blocks中对所有边进行排序的系统不同,ForeGraph只需要将顶点和边分配给相应的(子)intervals和(子)blocks。这种实现可以显著减少预处理的时间消耗。
在划分之前,我们确定P和Q。然后使用哈希函数将所有顶点分配到相应的sub-intervals。例如,v1、v1+n/PQ、v1+2·n/PQ等被分配给SI1,1(这种分区方法可以平衡每个block的大小,如表8所示)。边也以这种方式划分,无需排序。我们通过使用基于索引的分区方案(m表示边数),将预处理开销从O(m log m)减少到O(m)。这种基于索引的分区的另一个优点是,它可以轻松应用于动态图算法。以前的系统需要在更新之前对所有边进行排序,因此当图的结构发生变化(例如插入/删除边)时,需要重新进行整个预处理。在ForeGraph中,这样的开销可以避免,因为不需要(子)block中的边顺序。4.系统优化
基于第三节中多 FPGA 的设计,我们介绍了三种优化方法,以减少数据传输量,充分利用 FPGA 板上的 PE。4.1 顶点索引压缩
顶点和边都存储在片外存储器中,因此压缩这些数据可以显著提高 ForeGraph 的性能。在 ForeGraph 中,我们需要存储每个顶点以及每条边的源/目的顶点的值。每个顶点值的存储空间与专用算法相关(例如 BFS 中每个顶点的深度为8位)。这些数据的压缩不在本文讨论的范围之内。每个边的存储空间是顶点索引大小的两倍。例如,在由4200万个顶点组成的 Twitter [29]图中,我们需要 log2(42 × 106) = 25位来表示该图中的一个顶点。当图包含超过40亿(= 232)个顶点时,顶点索引的长度甚至可以超过32位。
sub-blocks中边的源/目标顶点都在相同的sub-interval内。我们可以使用sub-block索引作为顶点索引的前缀。例如,假设图中有100个sub-intervals,我们按常数步长(100)将顶点划分为一个sub-interval。这样,SI1包括 v1,v101,v201… 在这个sub-intervals中,我们使用1作为前缀,SI1中的所有顶点可以根据sub-intervals中的位置进行索引(例如 v101是 SI1中的第二个顶点)。因此,顶点的索引不超过 n/100(一个sub-intervals中的顶点数)。
图5显示了使用顶点索引压缩方法在 DRAM 中的数据分配。每个sub-block以其sub-block索引开始,然后是压缩的边索引。在 ForeGraph 实现中,我们使用2 Bytes (16位)来表示顶点索引。因此,在一个sub-interval中有少于216 = 65536个顶点。4.2 Shuffling Edges
如3.3节所述,芯片上的 K 个 PE 使用 K 个连续sub-blocks更新一个sub-interval。如图5所示,PE 的使用效率很低。连续的边将只发送到一个 PE,因为源顶点在相同的sub-interval。然而,PE 每个时钟周期只能更新一条边。与此同时,其他 PE 在这种情况下处于空闲状态。为了解决这个问题,我们在这些 K sub-blocks中对边进行shuffle。
图6显示了一个为什么shuffling边可以充分利用所有PE的示例。在图6中,有两个PE,四条边被分配给它们。片外存储器的带宽提供了每个周期向FPGA芯片加载两个边的吞吐量。如果sub-block中的边是连续顺序的,则需要三个时钟周期才能完成更新,因为在第一个和第三个时钟周期中只处理一条边。然而,如果边被shuffle,它只需要两个时钟周期,并且在每个周期中处理两个边。
基于这种shuffle方法,我们提出了边shuffling方法,如图7所示。对K个连续sub-blocks中的边进行shuffle。DRAM中的K个连续边位于不同的sub-blocks中,因此它们被发送到不同的PE。如果sub-blocks的大小不同,ForeGraph使用NULL边填充空白位置(图7中的灰色块)。我们采用DFR,因此当所有PE完成更新时,替换目的sub-interval。图8显示了Bx→y中sub-blocks的访问顺序示例。 将K个连续sub-intervals加载到芯片以更新所有sub-intervals。加载sub-intervals后,加载shuffle之后的边并将其调度到每个PE。4.3 跳过无用blocks
在算法1中,在一次迭代中访问所有blocks中的边。然而,以前的工作[30,31]表明,在像BFS这样的算法中,只有一些顶点在一次迭代中更新。如果顶点未更新,则其相邻顶点将不会在下一次迭代中更新。因此,我们不必访问其输出边。
基于这样的观察,如果某些边的源顶点在之前的迭代中没有更新,我们可以跳过这些边。此外,如果在一次迭代中一个(子)interval中的所有顶点都没有更新,则在下一次迭代中不需要访问该(子)interval中具有源顶点的(子)blocks中的输出边。这样,我们可以从片外存储器加载更少的边,并跳过不需要传输的(子)blocks。在ForeGraph中的实现中,我们使用位图[31]中的一位来表示当前sub-interval是否在迭代中更新。

若有收获,就点个赞吧
0 人点赞
