- 现实生活中图数据过大,单机难以处理,需要分布在多个节点上计算。负载均衡指多个计算节点上分配的计算任务的比重,主要由partition方法来决定。
- partition按照切分方式来分,有两种主流方法,分别是边分割和点分割。边分割指将图的顶点划分成若干份分配到计算节点上,一个计算节点上的本地顶点所连接的非本地顶点作为副本存储在该计算节点上,被切割的是边。点分割指将图的边划分成若干份分配到计算节点中,每条边连接的顶点也存储在该计算节点上,被切割的是顶点。
partiton优化方法的目的只有load balance和减少Mirror数量,减少Mirror数量可以同时reduce capacity requirement & reduce communication,但是优化的主要目的是减少communication。
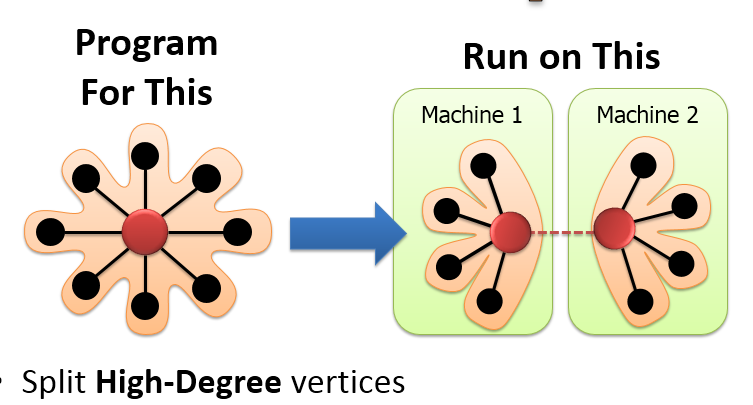
由于高度顶点的边很多,采用edge-cut会造成更多的Mirror,并且会造成严重的负载不均衡以及很高的锁抢占的开销,以及会带来很高的网络传输的开销。采用vertex-cut会将高度顶点切分成多个Mirror顶点,所有的顶点被并行的执行,来防止顶点执行负载不均衡。
- 但是对于低度顶点来说,采用edge-cut即将顶点及其所有邻居顶点划分到一个分区并不会造成负载不均衡,反而可以提升locality,减少Mirror数量,降低网络通信。
- Pregel提出哈希边分割算法。每个顶点都有一个唯一的ID,根据hash(ID) mod N 来决定每个顶点在哪个partition的,N是partition总数,每个partition都包含顶点和该顶点的出边。(边分割)
- 首先,GraphLab使用一些分区算法(例如ParMetis)将初始的数据图分区为k个原子文件,k远大于机器的数目。原子文件的链接关系以及各个原子文件放置的位置被记录在一个索引文件(Atom Index)中。再将这k个原子文件分配到各个节点上(例如使用比较低级的Hash算法),即完成了数据图到机器的分区工作。对于某条边。GraphLab将其唯一部署在某一台机器上,而对边关联的顶点进行多份存储,解决了边数据量大的问题。(点分割)reduce capacity requirement & reduce communication
- Graphchi将图中所有顶点按id由小到大划分成几个区间(interval),然后每个区间对应一个shard用来存放该区间内所有顶点的入边(边先按目的点排序再按源点排序),这样就完成了图的划分。图算法执行时将各个interval及对应shard中的入边(memory shard)和聚集其他shard中的出边(sliding shard)载入内存进行处理。因为是连续存放,连续读取调入主存,大大降低了I/O开销。data movement(边分割)
- 在ForeGraph中,顶点被划分为P个intervals,并进一步划分为P·Q个sub-intervals。边也按其源顶点和目的顶点划分。与Graphchi等以前需要在(子)blocks中对所有边进行排序的系统不同,ForeGraph只需要将顶点和边按照索引号分配给相应的(子)intervals和(子)blocks。这种实现可以显著减少预处理的时间消耗。,可以轻松应用于动态图算法。
- Linear Deterministic Greedy partitioning (LDG) 在分割的时候将邻居结点放置在一起,以减少edge-cut。它采用贪心算法将一个结点放置在包含其邻居最多的子图中,同时保证每个子图的结点负载均衡。(边分割)reduce capacity requirement & reduce communication
- 针对社交网络或者网页这类符合幂律分布的图数据(natural graph),少数顶点连接着大量边。
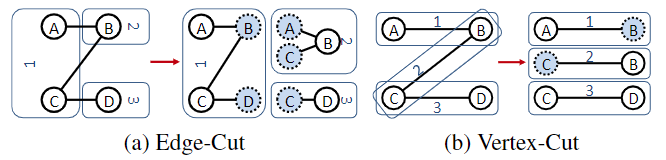
- 边分割算法会同步大量边的信息到这些少数顶点所在分区,从而导致计算分布不平衡,单个机器计算任务过重。点分割的方法只需要同步边所连接顶点的信息到边所在分区,不存在这个问题。load-balance
- 边分割算法需要在本地存储更多顶点副本,而点分割存储的副本数明显较少。reduce capacity requirement & reduce communication
- 点分割算法在图分布式计算中的应用最先由powergraph提出。
- 随机分配分割法得到的子图局部性很差,例如哈希函数随机分配(Pregel和GraphLab)和powergraph提出的第一种partition方法—点分割随机分配。为了提高子图局部性,提出了第二种partition方法—贪婪协同边分配(Greedy Vertex-Cuts),新加进来的边,它的某个顶点已经存在于某台机器上,就将该边分到对应的机器上,比如在1号机器上已经存在AB这条边,2号机器上已经存在BC这条边,那么当一条新的边AD在要加进来时,发现A顶点已经在1号机器上,所以就将该边放置到1号机器上。如果再来一条边BE,发向两台机器上都存有B顶点,这时候贪婪策略会选择机器中分配的边最少的机器进行分配。reduce capacity requirement & reduce communication
- GAP采用深度学习方法来进行图分区。作者定义了一个可微分损失函数使跨分区的edge cut最小化,并反向传播以优化未来参数。与每张图都重新优化的baseline不同,GAP能进行泛化。因为GAP在联合优化分区损失函数的同时学习图表示,所以可很容易地针对各种图结构进行调整。(边分割)reduce capacity requirement & reduce communication
- powerlyra对于高度顶点,采用vertex-cut,切分成若干个Mirror顶点。利用Mirror顶点减少了高度顶点计算任务繁重的问题,并且采用vertex-cut划分策略产生很少一部分的Mirror。但是PowerLyra的作者发现,在幂律图的情况下,单单只采用vertex-cut的划分策略对于低度顶点来说会产生更多的Mirror。但是低度顶点的度很少,它希望顶点计算尽量在本地执行。所以PowerLyra就采用了一种Hybrid 切分策略,对于高度顶点采用vertex-cut的策略,对于低度顶点采用edge-cut的切分方式。(点分割和边分割混合)reduce capacity requirement & reduce communication

若有收获,就点个赞吧
0 人点赞
