1.背景
GNN:H(l+1)=σ(AH(l)W(l)),H是节点特征,W是MLP(多层感知机)权重,A是邻接矩阵。H(l+1)是下一层的节点特征。
A是稀疏矩阵,稀疏矩阵乘法(SpMM)通常是GNN计算性能的瓶颈,因为GPU的硬件架构和内存系统只针对密集矩阵进行了优化。
为了解决这一问题,论文作者提出了ES_SpMM, a sampling algorithm and codesigned SpMM kernel to speed GNN inference performance.
2.具体实现方法
a.图格式——CSR(压缩稀疏行)
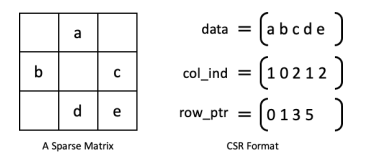
如上图,将稀疏矩阵变成3个数组,分别为记录非零数值的数组data,非零数值所在列索引的数组col_ind,每行非零数值的累加和(其中第一个元素为0,总共有row+1个元素)。这种格式具有高效性和简单性。
b.边采样
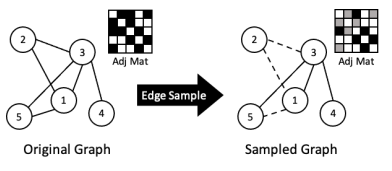
研究证明,适量的边丢失对GNN的影响较小(针对小型数据集,40%以下的边丢失准确率仍然接近基准线。针对大型数据集,则可以达到80%的边丢失率)。除此之外,边采样会导致更少的计算从而减少SpMM的运行时间。如上图所示,边采样后,邻接矩阵中非零元素减少了。
总时间开销由边采样时间开销和SpMM的运行时间组成。为了实现GNN的净加速,需要最大限度减少边采样时间开销。另外还需要在保证加速的同时保证准确率,因此还需要优化抽样选择策略。
i.减少采样时间
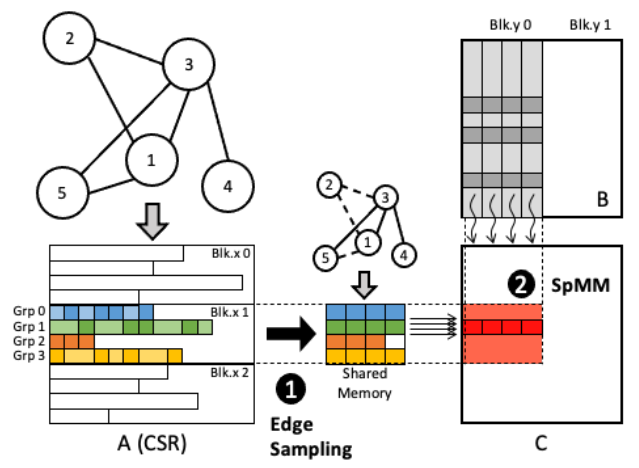
Cache-First Edge Sampling: 设置一个目标共享内存宽度S,对于A的每一行,至多S个非零值被提取到共享内存。如果某一行里非零数值的个数小于S,则整行非零数值都被提取到共享内存。这种方法可以改进缓存的局部性。每个线程块安排4~8个线程组,每个线程组安排32~128个线程,并保证每个线程块固定512个线程,这种方式可以为每个线程块使用不同的采样策略来精确计算。因为同一个线程块中的线程组共享同一个共享内存空间,每个共享内存块包含4~8行A的采样值,这样实现了针对多线程的局部性。这样采样任务就并行化为数千个线程,可以显著加速。
线程块和线程组我再查一下。
ii.抽样策略
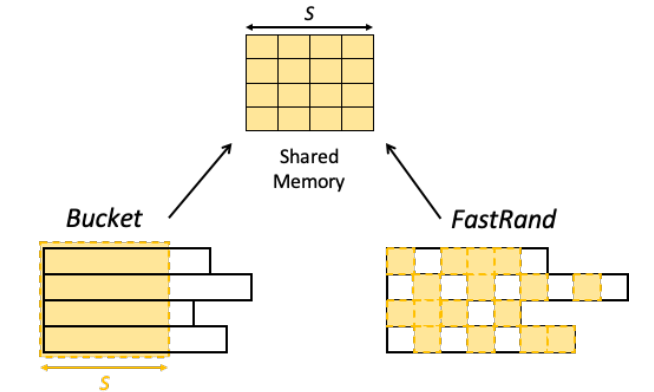
两种抽样策略:Bucket,FastRand
Bucket: 设置一个目标共享内存宽度S,对A的每一行选择前S个非零数值和对应的列索引。速度快,准确率低。
FastRand:使用哈希函数来计算。
sample_idx = (shmem_idx × P’ ) mod row_nnz
sample_idx:抽样后下标。
shmem_idx: 共享内存地址下标。
P’:一个质数,为了保证对A的每一行的整个非零数值范围都进行采样,它的值不能太小。
row_nnz:对应行的非零数值的个数。
速度稍慢,准确率高。
论文里没写,可以考虑两种混用,类似BIP这种。
arXiv2021_Accelerating SpMM Kernel with Cache-First Edge Sampling for Graph Neural Networks.pdf

若有收获,就点个赞吧
0 人点赞
