MMAP
mmap是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系,函数原型如下 void mmap(void addr, size_t length, int prot, int flags, int fd, off_t offset);
实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用read,write等系统调用函数。如下图所示
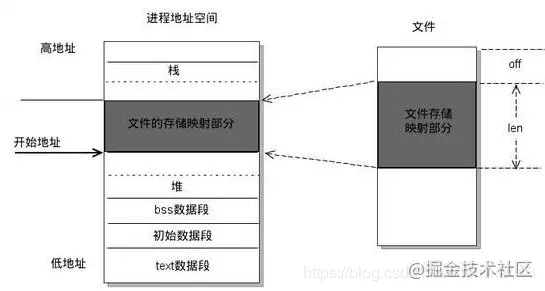
mmap除了可以减少read,write等系统调用以外,还可以减少内存的拷贝次数,比如在read调用时,一个完整的流程是操作系统读磁盘文件到页缓存,再从页缓存将数据拷贝到read传递的buffer里,而如果使用mmap之后,操作系统只需要将磁盘读到页缓存,然后用户就可以直接通过指针的方式操作mmap映射的内存,减少了从内核态到用户态的数据拷贝。
映射只不过是映射到虚拟内存,不用担心映射的文件太大。
每个进程的4G内存空间只是虚拟内存空间,每次访问内存空间的某个地址,都需要把地址翻译为实际物理内存地址
所有进程共享同一物理内存,每个进程只把自己目前需要的虚拟内存空间映射并存储到物理内存上。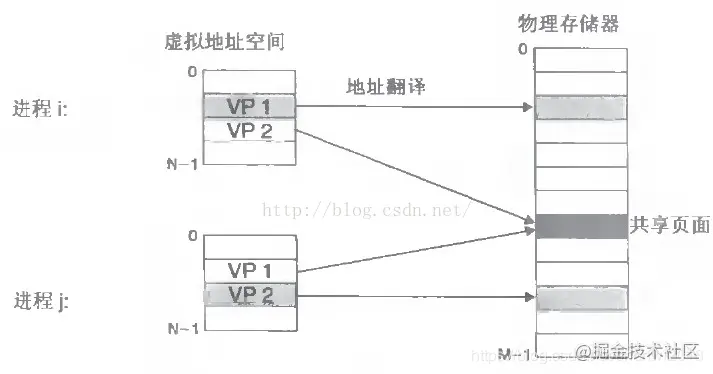
进程与内存
当我们创建一个进程时,我们知道进程有以下特点:
1. 每个进程都有自己独立的4G内存空间,各个进程的内存空间具有类似的结构
2. 一个新进程建立的时候,将会建立起自己的内存空间,此进程的数据,代码等从磁盘拷贝到自己的进程空间,哪些数据在哪里,都由进程控制表中的task_struct记录,task_struct中记录中一条链表,记录中内存空间的分配情况,哪些地址有数据,哪些地址无数据,哪些可读,哪些可写,都可以通过这个链表记录
3. 每个进程已经分配的内存空间,都与对应的磁盘空间映射
那么问题来了:
计算机明明没有那么多内存(n个进程的话就需要n*4G)内存
建立一个进程,就要把磁盘上的程序文件拷贝到进程对应的内存中去,对于一个程序对应的多个进程这种情况,浪费内存!
所以,实际上:
- 每个进程的4G内存空间只是虚拟内存空间,每次访问内存空间的某个地址,都需要把地址翻译为实际物理内存地址
2. 所有进程共享同一物理内存,每个进程只把自己目前需要的虚拟内存空间映射并存储到物理内存上。
3. 进程要知道哪些内存地址上的数据在物理内存上,哪些不在,还有在物理内存上的哪里,需要用页表来记录
4.页表的每一个表项分两部分,第一部分记录此页是否在物理内存上,第二部分记录物理内存页的地址(如果在的话)
5. 当进程访问某个虚拟地址,去看页表,如果发现对应的数据不在物理内存中,则缺页异常
6.缺页异常的处理过程,就是把进程需要的数据从磁盘上拷贝到物理内存中,如果内存已经满了,没有空地方了,那就找一个页覆盖,当然如果被覆盖的页曾经被修改过,需要将此页写回磁盘
[
](https://blog.csdn.net/fengxinlinux/article/details/52071766)
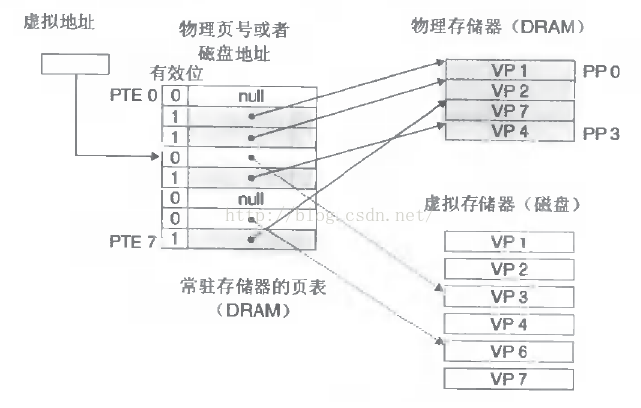
可以认为虚拟空间都被映射到了磁盘空间中,并且由页表记录映射位置,当访问到某个地址的时候,通过页表中的有效位,可以得知此数据是否在内存中,如果不是,则通过缺页异常,将磁盘对应的数据拷贝到内存中,如果没有空闲内存,则选择牺牲页面,替换其他页面。
事实上,在每个进程创建加载时,内核只是为进程“创建”了虚拟内存的布局,具体就是初始化进程控制表中内存相关的链表,实际上并不立即就把虚拟内存对应位置的程序数据和代码(比如.text .data段)拷贝到物理内存中,只是建立好虚拟内存和磁盘文件之间的映射就好(叫做存储器映射),等到运行到对应的程序时,才会通过缺页异常,来拷贝数据。还有进程运行过程中,要动态分配内存,比如malloc时,也只是分配了虚拟内存,即为这块虚拟内存对应的页表项做相应设置,当进程真正访问到此数据时,才引发缺页异常。
[
](https://blog.csdn.net/fengxinlinux/article/details/52071766)
应用虚拟内存机制有很多优点:
1.既然每个进程的内存空间都是一致而且固定的,所以链接器在链接可执行文件时,可以设定内存地址,而不用去管这些数据最终实际的内存地址,这是有独立内存空间的好处
2.当不同的进程使用同样的代码时,比如库文件中的代码,物理内存中可以只存储一份这样的代码,不同的进程只需要把自己的虚拟内存映射过去就可以了,节省内存
3.在程序需要分配连续的内存空间的时候,只需要在虚拟内存空间分配连续空间,而不需要实际物理内存的连续空间,可以利用碎片
[
](https://blog.csdn.net/fengxinlinux/article/details/52071766)
MMAP 与 Read/Write 区别
内核会为每个文件单独维护一个page cache,用户进程对于文件的大多数读写操作会直接作用到page cache上,内核会选择在适当的时候将page cache中的内容写到磁盘上(当然我们可以手工fsync控制回写),这样可以大大减少磁盘的访问次数,从而提高性能。Page cache是linux内核文件访问过程中很重要的数据结构,page cache中会保存用户进程访问过得该文件的内容,这些内容以页为单位保存在内存中,当用户需要访问文件中的某个偏移量上的数据时,内核会以偏移量为索引,找到相应的内存页,如果该页没有读入内存,则需要访问磁盘读取数据。为了提高页得查询速度同时节省page cache数据结构占用的内存,linux内核使用树来保存page cache中的页。
read/write系统调用会有以下的操作:
- 访问文件,这涉及到用户态到内核态的转换
- 读取硬盘文件中的对应数据,内核会采用预读的方式,比如我们需要访问100字节,内核实际会将按照4KB(内存页的大小)存储在page cache中
- 将read中需要的数据,从page cache中拷贝到用户缓冲区中
page cache 不在用户缓冲区? 用户缓冲区和
整个过程还是比较艰辛的,基本上涉及到用户内核态的切换,还有就是数据拷贝接下来继续说mmap吧,mmap系统调用是将硬盘文件映射到用户内存中,说的底层一些是将page cache中的页直接映射到用户进程地址空间中,从而进程可以直接访问自身地址空间的虚拟地址来访问page cache中的页,这样会并涉及page cache到用户缓冲区之间的拷贝,mmap系统调用与read/write调用的区别在于:
- mmap只需要一次系统调用,后续操作不需要系统调用
- 访问的数据不需要在page cache和用户缓冲区之间拷贝

连续的内存页不够了,内核线程在分配连续的内存页的时候就会触发。
https://juejin.cn/post/6844903855235268615#heading-3
https://blog.csdn.net/fengxinlinux/article/details/52071766

若有收获,就点个赞吧
0 人点赞
