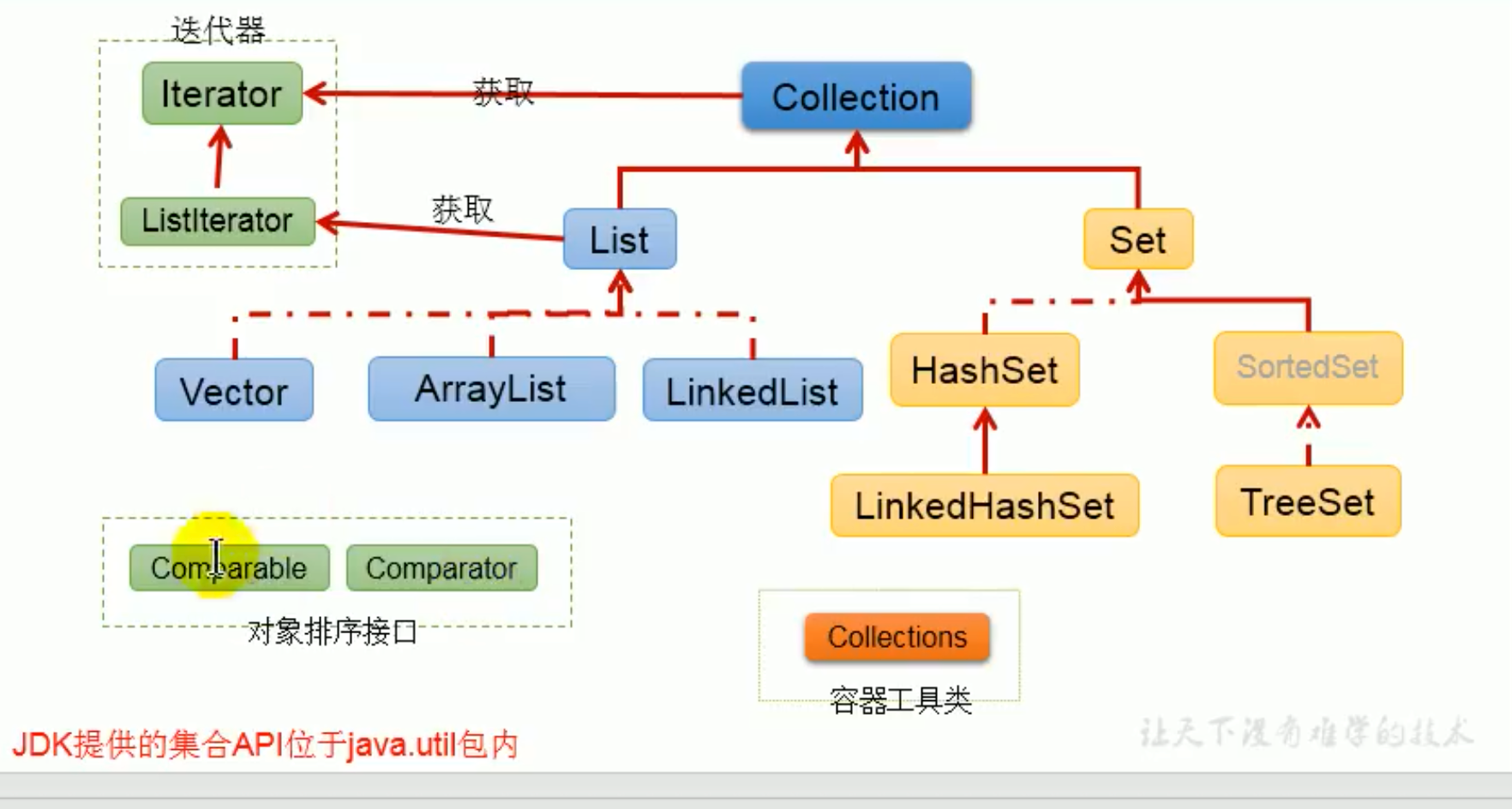
Java集合框架概述
说明
集合、数组都是对多个数据进行存储操作的结构,简称Java容器。都是属于内存存储。
数组的特点
一旦初始化后,长度就确定
初始化后类型就确定了



Collection接口方法
add(E e)
addAll(Collection<? extends E> c)
size() 最大值 nteger.MAX_VALUE
clear();
isEmpty();
contains();
如果此集合包含指定的元素,则返回true 。 更正式地说,当且仅当此集合包含至少一个元素e使得(o==null ? e==null : o.equals(e))时才返回tru
containsAll(Collection<?> c);
remove(Object o);
retainAll(Collection<?> c);
hashCode();
toArray()
iterator()
Iterator迭代器接口
JDK5.0增强for遍历集合
Collection子接口:List
说明
- 鉴于Java数组的局限性,通常使用 list代替数组
- List 集合类中元素有序、且可重复,集合中的每个元素都有对应的顺序索引
- List容器中的元素都对应一个整数型的序号记载在容器中的位置,可以根据序号的存取容器中的元素,
- JDK API 中List 接口实现类常用的有:ArrayList、LinkedList 和 Vector
三者ArrayList、LinkedList 和 Vector异同
同:实现了List接口,存储数据的特点相同:存储有序的,可以重复的数据
异:
- 出现的版本不同ArrayList,线程不安全,效率高; 底层使用transient Object[] elementData 数组
- Vector 线程安全,效率低; 底层使用 protected Object[] elementData 数组;
- LinkedList 对于频繁的插入、删除操作,使用此类效率比ArrayList高; 底层使用双向链表存储
ArrayList 源码分析
JDK7 源码
说明:
- 当超过底层数组长度(默认是10)则扩容,扩容为原来的1.5倍,同时需要将原有数组中的数据复制到新的数组中
所以在使用ArrayList时,建议使用带参的构造方法 new ArrayList<>(100); ```java // 创建一个为长度10的数组 public ArrayList() {
this(10);
}
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!! elementData[size++] = e; return true;}
private void ensureExplicitCapacity(int minCapacity) { modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity); }
<a name="mqCeK"></a>
### JDK8源码
<a name="wHmk2"></a>
#### 说明
1. new ArrayList() 底层Object[] _DEFAULTCAPACITY_EMPTY_ELEMENTDATA _= {};并没有创建长度
1. 第一次调用add()方法时,底层才创建默认长度为10的数组,并将数据添加到数组elementData 中
```java
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return <tt>true</tt> (as specified by {@link Collection#add})
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
/**
* Increases the capacity to ensure that it can hold at least the
* number of elements specified by the minimum capacity argument.
*
* @param minCapacity the desired minimum capacity
*/
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
LinkedList源码
双向链表结构
Collection子接口:Set
说明:Set接口:存储无序的、不可重复的数据
HashSet
说明: 线程不安全,可以存储null值
HashSet源码 存储使用的方式时 散列表以及 链表存储,

/**
源码分析
* Implements Map.put and related methods.
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
public static int hash(Object... values) {
return Arrays.hashCode(values);
}
public static int hashCode(Object a[]) {
if (a == null)
return 0;
int result = 1;
for (Object element : a)
result = 31 * result + (element == null ? 0 : element.hashCode());
return result;
}

Set要实现不可重复的要求
- 向Set中添加的数据,其所在的类一定要重写hashCode() 和 equals()
- 重写的hashCode() 和 equals()尽可能保持一致性:相等的对象必须具有相等的散列码
LinkedHashSet
说明:是HashSet的子类,遍历其内部数据时,可以按照添加的顺序遍历
对于频繁遍历,LinkedHashSet 比 HashSet效率高
TreeSet(数据结构 :二叉树 - 红黑树 结构)
说明:可以按照添加对象的指定属性,进行排序
- 添加的数据需要同一个类型的数据
- 两种排序方式:自然排序 和 定制排序(Comparator)
- 自然排序中,比较两个对象是否相同的标准为:compareTo() 返回为0 ,不再是equals().
- 定制排序中,比较两个对象是否相同的标准为:compare()返回0,不再是equals()

练习题
// User 需要重写 hashCode() 和 equals() 方法
public static void main(String[] args) {
HashSet set = new HashSet<>();
User user = new User("1001", "aa");
User user1 = new User("1002", "bb");
set.add(user);
set.add(user1);
user.name = "cc";
set.remove(user);
System.out.println(set);
set.add(new User("1001","cc"));
System.out.println(set);
set.add(new User("1001","aa"));
System.out.println(set);
}
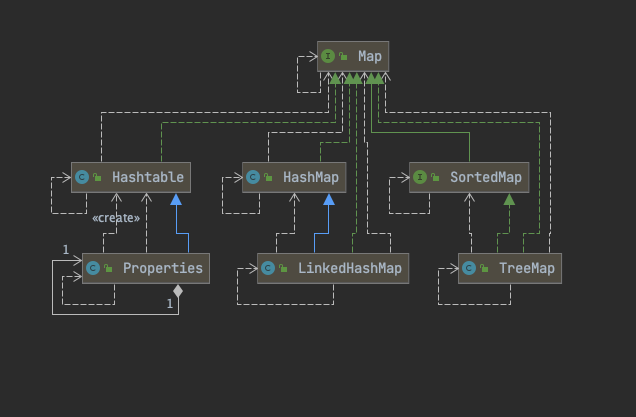
Map接口
说明 key - value 对的数据
对Map 的理解
key:无序的、不可重复的,使用Set存储所有的key —>key所在的类要重写equals() 和hashCode() (以HashMap 为例)
value:无序的、可重复的,使用Cllection存储所有的value —>value所在的类要重写equals()
一个键值对:key-value 构成一个Entry对象
Map中的entry:无序的、不可重复的,使用Set存储所有的entry
HashMap
说明:作为Map的主要实现类、线程不安全,效率高,key和value 可以存储为null
底层:
jdk7 之前: 数组+链表
jdk8 : 数组 + 链表+ 红黑树
底层原理分析⭐️
- HashMap hashMap = new HashMap();
- 在实例化以后,底层创建了长度16的一堆数组 Entry[] table.
- hashMap.put(key1,value1);
- 首先,调用key1所在类的hashCode()计算key1哈希值,此哈希值经过某种算法以后,得到在entry 数组中的存放位置
- 如果位置的数据为空,此时的key1 - value1 添加成功
- 如果此位置上的数据不为空,(意味着此位置存在一个或多个数据(链表形式存在),比较key1 和已经存在一个或者多个的哈希值)
- 如果key1的哈希值与已经存在的数据的哈希值都不同,此时key1-value1添加成功。
- 如果key1的哈希值和已经存在的某一个数据(key2-value2)的哈希值相同,继续比较:调用key1所在类的equals(key2)
- 如果equals()返回false,此时key1 - value1 添加成功
- 如果equals()返回true ,使用value1 替换 value2
- 在不断的添加过程中,会涉及扩容问题,默认的扩容方式,扩容为原来的2倍,并将原有的数据复制
- jdk8 相较于 jdk7在底层实现方面的不同
- new HashMap(): 底层没有创建一个长度16的数组
- jdk8 底层的数组是 : Node[], 而非Entry[]
- 首次调用put()方法时,底层创建长度为16的数组
- jdk7 底层结构只有:数组+链表 jdk8 中底层结构:数组+链表+红黑树,当数组的某一索引位置上的元素以链表形式存在的数据个数 > 8 且数组的长度 > 64 时,此时此索引位置上的所有数据改为使用红黑树存储。
内部名词解释
DEFAULT_INITIAL_CAPACITY : 默认初始容量 (16)
DEFAULT_LOAD_FACTOR :默认负载因子 (0.75)
MIN_TREEIFY_CAPACITY : 可以将 b 树化的最小表容量,就是链表中长度的最小值, 默认是64
threshold:扩容的临界值,= 容量 * 填充因子
TREEIFY_THRESHOLD : Bucket 中链表长度大于改默认值,转化为红黑树:默认是 8
为什么提前扩容
- 为了提前让链表尽可能少
LinkedHashMap
Hashtable
说明:线程安全,key和value 不能存储为null
Properties
处理配置文件 key 和value 都是String 类型
SortedMap
TreeMap
说明:保证按照添加的key- value 对进行排序,实现排序遍历,此时考虑的自然排序或定制排序;底层使用红黑树。
面试题
- HashMap 的底层实现原理
- HashMap 与 Hashtable 的异同?
- CurrentHashMap 与 Hashtable 的异同?
Collections工具类
常用方法
Collections.copy(dest, src);
Collections.reverse(list);Collections.shuffle(list);
Collections.sort(list);
Collections.sort(list, c);
Collections.swap(list, i, j);
Collections.frequency(c, o);
Collections.replaceAll(list, oldVal, newVal);

若有收获,就点个赞吧
0 人点赞
