- https://www.yuque.com/liujiexing/akwwoh/26367275?sorter=filename&order=asc">https://www.yuque.com/liujiexing/akwwoh/26367275?sorter=filename&order=asc
- 1、索引的数据机构
- 2、InnoDB数据存储结构
- 3、索引的创建与设计原则
- 4、性能分析工具的使用
- 测试发现:设置global的方式对当前session的long_query_time失效。对新连接的客户端有效。所以可以一并
执行下述语句
mysql > set global long_query_time = 1;
mysql> show global variables like ‘%long_query_time%’;
mysql> set long_query_time=1;
mysql> show variables like ‘%long_query_time%’; - 4.5、查询SQL 执行成本:SHOW PROFILE
- 4.6、分析查询语句:EXPLA IN
- 5、索引的优化与查询优化
- 6、数据库的设计规范
- 7、数据库其它调优策略
https://www.yuque.com/liujiexing/akwwoh/26367275?sorter=filename&order=asc
1、索引的数据机构
1、为什么使用索引
2、索引及其优缺点
1、索引概述
2、优点
3、缺点
1、消耗时间,随着数据量的增加,耗费的时间也会增加
2、占用内存空间
3、降低更新表的速度
3、InnoDB中索引的推演
1页 16KB
1、索引之前的查找
1.1、在一个页中的查找
1.2、在很多页中查找
2、设计索引
2.1、一个简单的索引设计方案
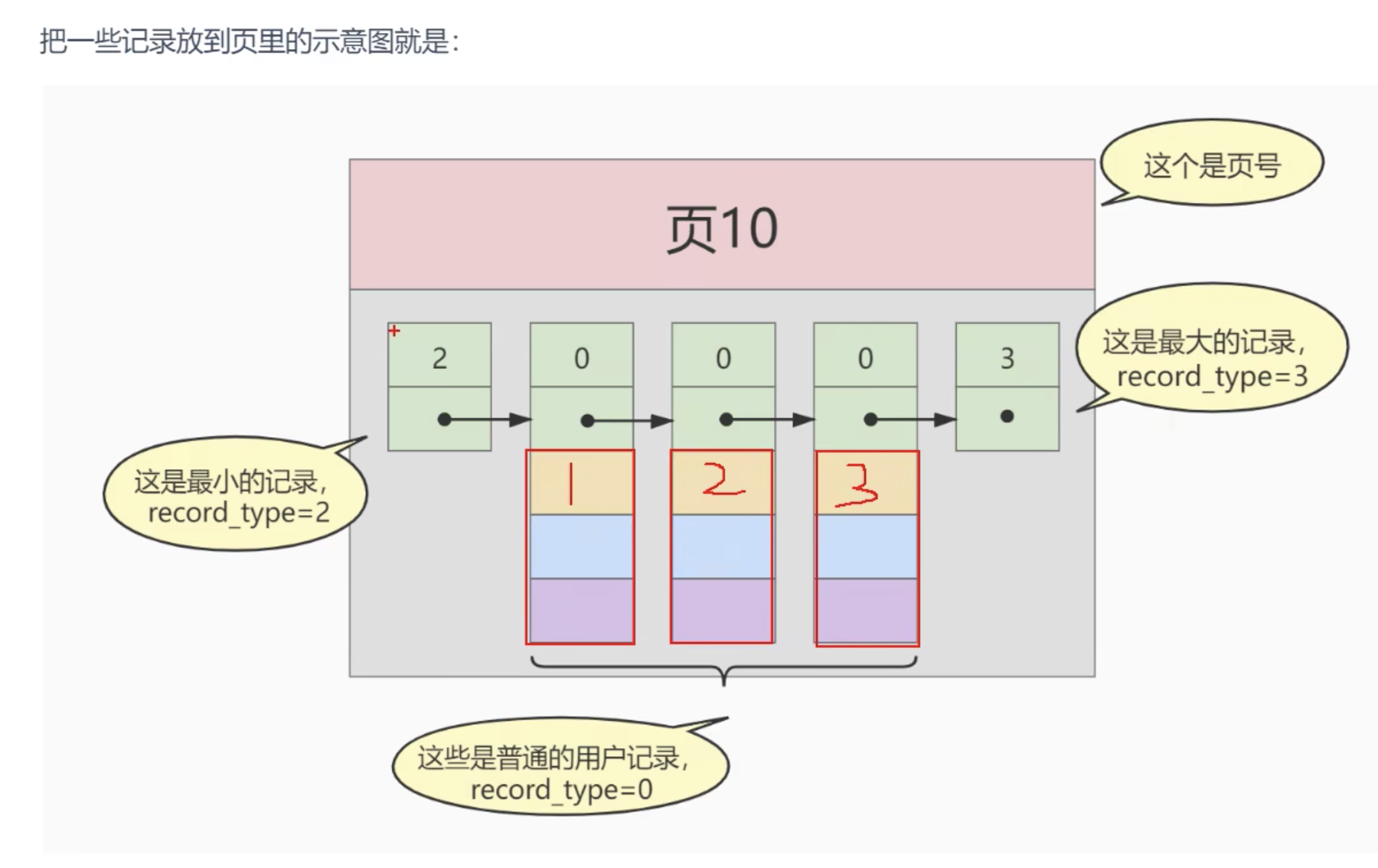

2.2、InnoDB中的索引方案
1、迭代1次
2、迭代2次
3、迭代3次
4、B+Tree
3、常见索引概念
3.1聚簇索引
3.2 二级索引(辅助索引、非聚簇索引)
3.3 联合索引
4、InnoDB的B+树索引的注意事项
4.1根页面万年不动窝
4.2 内节点中目录记录的唯一
4.3 一个页面最少存储2条记录
4、MyISAM中的索引方案
1、MyISAM索引的原理
2、MyISAM与InnoDB对比
3、关于行格式
5、索引的代价
6、MySQL数据结构选择的合理性
6.1全表遍历
6.2Hash结构
6.3 二叉搜索树
6.4 AVL树
6.5 B-Tree
6.6 B+Tree
6.7 R树
6.8 小结
6.9 算法的时间复杂度
2、InnoDB数据存储结构
3、索引的创建与设计原则
4、性能分析工具的使用
4.1、数据库服务器优化的步骤
4.2、查询系统性能参数
Version:0.9 StartHTML:0000000105 EndHTML:0000008439 StartFragment:0000000141 EndFragment:0000008399
在MySQL中,可以使用 SHOW STATUS 语句查询一些MySQL数据库服务器的 性能参数 、 执行频率 。
SHOW STATUS语句语法如下:
SHOW [GLOBAL|SESSION] STATUS LIKE ‘参数’;
一些常用的性能参数如下:
• Connections:连接MySQL服务器的次数。
• Uptime:MySQL服务器的上 线时间。
• Slow_queries:慢查询的次数。
• Innodb_rows_read:Select查询返回的行数
• Innodb_rows_inserted:执行INSERT操作插入的行数
• Innodb_rows_updated:执行UPDATE操作更新的 行数
• Innodb_rows_deleted:执行DELETE操作删除的行数
• Com_select:查询操作的次数。
• Com_insert:插入操作的次数。对于批量插入的 INSERT 操作,只累加一次。
• Com_update:更新操作 的次数。
• Com_delete:删除操作的次数。
4.3、统计SQL的查询成本
然后再看下查询优化器的成本,实际上我们只需要检索一个页即可:
SHOW STATUS LIKE ‘last_query_cost’;
4.4、定位执行慢的SQL:慢查询日志
1. 开启slow_query_log
show variables like ‘%slow_query_log’;
set global slow_query_log=’ON’;
然后我们再来查看下慢查询日志是否开启,以及慢查询日志文件的位置:
show variables like ‘%slow_query_log%’;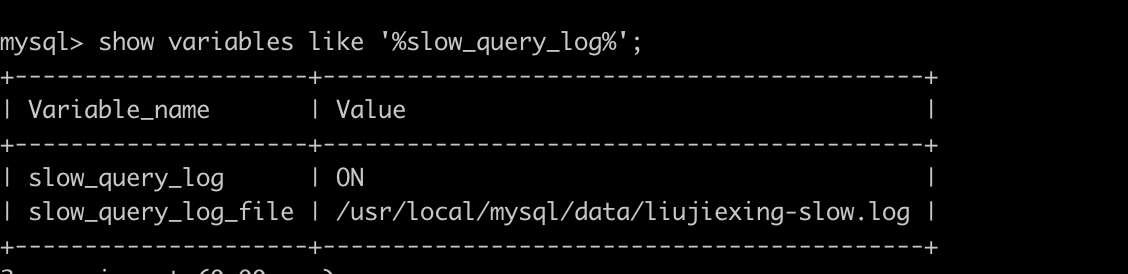
2、设置慢查询时间
show variables like ‘%long_query_time’;
测试发现:设置global的方式对当前session的long_query_time失效。对新连接的客户端有效。所以可以一并
执行下述语句
mysql > set global long_query_time = 1;
mysql> show global variables like ‘%long_query_time%’;
mysql> set long_query_time=1;
mysql> show variables like ‘%long_query_time%’;
3、查询慢sql
mysql> show global status like '%slow_queries%';+---------------+-------+| Variable_name | Value |+---------------+-------+| Slow_queries | 0 |+---------------+-------+1 row in set (0.00 sec)
4、慢查询日志分析工具:mysqldumpslow
[root@liujiexing ~]# mysqldumpslow --help
Usage: mysqldumpslow [ OPTS... ] [ LOGS... ]
Parse and summarize the MySQL slow query log. Options are
--verbose verbose
--debug debug
--help write this text to standard output
-v verbose
-d debug
-s ORDER what to sort by (al, at, ar, c, l, r, t), 'at' is default
al: average lock time
ar: average rows sent
at: average query time
c: count
l: lock time
r: rows sent
t: query time
-r reverse the sort order (largest last instead of first)
-t NUM just show the top n queries
-a don't abstract all numbers to N and strings to 'S'
-n NUM abstract numbers with at least n digits within names
-g PATTERN grep: only consider stmts that include this string
-h HOSTNAME hostname of db server for *-slow.log filename (can be wildcard),
default is '*', i.e. match all
-i NAME name of server instance (if using mysql.server startup script)
-l don't subtract lock time from total time
4.5、查询SQL 执行成本:SHOW PROFILE
4.6、分析查询语句:EXPLA IN
| 列名 | 描述 |
|---|---|
| id | 在一个大的查询语句中每个SELECT关键字都对应一个 唯一的id |
| select_type | SELECT关键字对应的那个查询的类型 |
| table | 表名 |
| partitions | 匹配的分区信息 |
| type | 针对单表的访问方法 |
| possible_keys | 可能用到的索引 |
| key | 实际上使用的索引 |
| key_len | 实际使用到的索引长度 |
| ref | 当使用索引列等值查询时,与索引列进行等值匹配的对象信息 |
| rows | 预估的需要读取的记录条数 |
| filtered | 某个表经过搜索条件过滤后剩余记录条数的百分比 |
| Extra | 一些额外的信息 |
1. table
不论我们的查询语句有多复杂,里边儿 包含了多少个表 ,到最后也是需要对每个表进行 单表访问 的,所 以MySQL规定EXPLAIN语句输出的每条记录都对应着某个单表的访问方法,该条记录的table列代表着该 表的表名(有时不是真实的表名字,可能是简称)。
2. id
id如果相同,可以认为是一组,从上往下顺序执行
在所有组中,id值越大,优先级越高,越先执行
关注点:id号每个号码,表示一趟独立的查询, 一个sql的查询趟数越少越好
5、索引的优化与查询优化
6、数据库的设计规范
7、数据库其它调优策略
7.1、数据库的调优的策略
7.2、优化MySQL服务器
7.3、优化数据库结构
7.4、大表优化
7.5、其它调优策略

若有收获,就点个赞吧
0 人点赞
