1. 正则表达式
1.1 什么是正则表达式?
简单的说,正则表达式就是为处理大量的煮饭吃而定义的一套规则和方法,
例如:假设”@”代表oldboy,”!”代表oldgirl。echo “@!” ==”oldboyoldgirl”
通过定义的这些特殊符号的辅助,系统管理员就可以快速过滤,替换或输出需要的字符串。
Linux正则表达式一般以行为单位处理的。
1.2 为什么要学正则表达式?
在企业工作中,我们每天做的linux运维工作中,时刻都会面对大量带有字符串的文本配置、
程序、命令输出及日志文件等,而我们经常会有迫切的需要,从大量的字符串内容中查找符合工作需要的特定的字符串。可以说 正则表达式就是为了过滤这样字符串的需求而生的!
例如: ifconfig的输出取IP
1.3 容易混淆的两个注意事项:
- 正则表达式应用非常广泛,存在于各种语言中,例如:php,python,java等。而我们所学的是linux系统运维工作中的正则表达式,即Linux正则表达式,最常应用正则表达式的命令就是
grep(egrep),sed,awk,换句话说Linux三剑客要想能工作的更高效,就一定离不开正则表达式的配合。
- 正则表达式和我们常用的通配符特殊字符是有本质区别的。
通配符例子: ls .log 这里的就是通配符(表示所有),不是正则表达式。
提示:
Linux正则表达式一般以行为单位处理。
1.4 基础正则第一波
- ^word 匹配以word开头的内容。
- word$ 匹配以word结尾的内容。
- ^$ 表示空行。
示例:
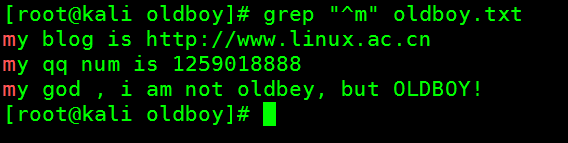
- 过滤出来以m开头的行
[root@kali oldboy]# grep "^m" oldboy.txt
my blog is http://www.linux.ac.cn
my qq num is 1259018888
my god , i am not oldbey, but OLDBOY!
- 过滤出来以n结尾的行
[root@kali oldboy]# grep "n$" oldboy.txt
my blog is http://www.linux.ac.cn

- 过滤出空行
[root@kali oldboy]# grep -n "^$" oldboy.txt
3:
8:
为了显示出空行的所在行,特加 -n参数把行号显示出来。
- 过滤掉空行
[root@kali oldboy]# grep -v "^$" oldboy.txt
I am oldboy teacher!
I teach linux.
I like babminton ball ,billiard ball and chinese chess!
my blog is http://www.linux.ac.cn
our site is http://www.etiantian.org
my qq num is 1259018888
not 1259018888.
my god , i am not oldbey, but OLDBOY!
1.5 基础正则第二波
- . 代表且只能代表任意一个字符。
- \ 例. 就只代表点本身,转义符号,让有着特殊身份意义的字符,脱掉马甲,还原原型。
- 重复0个或多个前面的一个字符,例o*,有1个o或多个oooooo
- . 匹配所有字符。延伸^.(以任意多个字符开头)。.*$(以任意多个字符结尾)。
示例:
- 匹配以点开头的字符
[root@kali oldboy]# grep -n "^." oldboy.txt
1:I am oldboy teacher!
2:I teach linux.
4:I like babminton ball ,billiard ball and chinese chess!
5:my blog is http://www.linux.ac.cn
6:our site is http://www.etiantian.org
7:my qq num is 1259018888
9:not 1259018888.
10:my god , i am not oldbey, but OLDBOY!
提示:第3行和第8行是空行,匹配以点开头的行不包括空行。
- 匹配所有(包括空行)
[root@kali oldboy]# grep -n ".*" oldboy.txt
1:I am oldboy teacher!
2:I teach linux.
3: admin
4:I like babminton ball ,billiard ball and chinese chess!
5:my blog is http://www.linux.ac.cn
6:our site is http://www.etiantian.org
7:my qq num is 1259018888
8:
9:not 1259018888.
10:my god , i am not oldbey, but OLDBOY!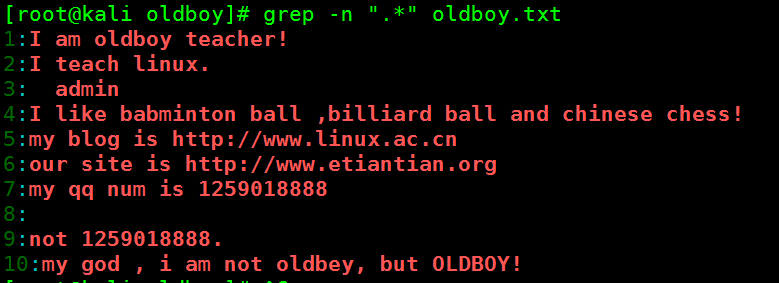
- 匹配以.结尾的行
[root@kali oldboy]# grep "\.$" oldboy.txt
I teach linux.
not 1259018888.
- 只输出匹配到的字符
[root@kali oldboy]# grep -no "c" oldboy.txt
1:c
2:c
4:c
4:c
5:c
5:c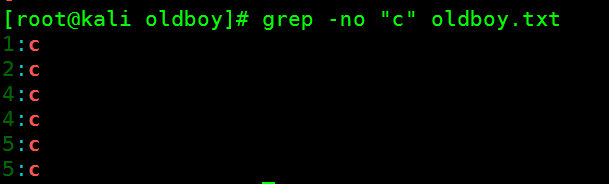
提示:
参数 -o ,仅把匹配到的字符给显示出来。
1.6 基础正则第三波
8)[abc] 匹配字符集合内的任意一个字符[a-zA-Z],[0-9]。
9)[^abc] 匹配不包含^后的任意一个字符的内容。
中括号里的^为取反,注意和中括号外面以…开头的区别。
10) a{n,m} 重复n到m次,前一个重复的字符。如果用egrep/sed -r 可以去掉斜线。
a{n,} 重复至少n次,前一个重复的字符。如果用egrep/sed -r 可以去掉斜线。
a{n} 重复n次,前一个重复的字符。如果用egrep/sed -r 可以去掉斜线。
a{,m} ?????centos5不能用,centos 6可以使用
注意:egrep(grep -E)或sed -r 过滤一般特殊字符可以不转义(不用\)。
示例:
- 过滤出包含有abc单个或多个字符行
[root@kali oldboy]# grep "[abc]" oldboy.txt
I am oldboy teacher!
I teach linux.
admin
I like babminton ball ,billiard ball and chinese chess!
my blog is http://www.linux.ac.cn
our site is http://www.etiantian.org
my god , i am not oldbey, but OLDBOY!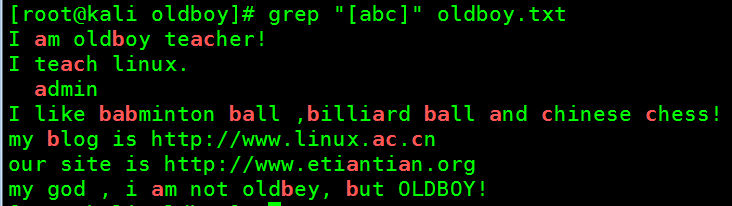
- 过滤出不包含abc字符的行
[root@kali oldboy]# grep "[^abc]" oldboy.txt
I am oldboy teacher!
I teach linux.
admin
I like babminton ball ,billiard ball and chinese chess!
my blog is http://www.linux.ac.cn
our site is http://www.etiantian.org
my qq num is 1259018888
not 1259018888.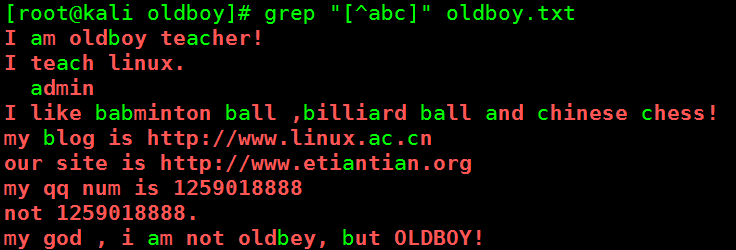
1.7 grep参数总结
1、-a 在二进制文件中,以文本的方式搜索数据
2、-c 计算找到“搜索字符串”的次数
3、-o 仅显示出匹配regexp的内容(用于统计出现在文中的次数)
4、-i 忽略大小写的不同,所以大小写都视为相同*
5、-n 匹配的内容在其行首显示行号*
6、-v 反向选择,即显示没有“搜索字符串”内容的那一行*
7、-E 扩充的grep,即egrep *
—color=auto 以特定颜色高亮显示匹配的关键字*
# 提示:-i -v 为常用参数。
1.8 扩展的正则表达式总结:
1)+重复一个或一个以上前面的字符
2)?重复0个或一个0前面的字符。
3)|用或的方式查找多个符合的字符串
4)()分组过滤,后向引用。
2. Linux正则表达式结合三剑客企业实战
2.1 取系统IP地址
a.
[root@kali oldboy]# ifconfig eth0|sed -n '2p'|sed 's#^.*dr:##g'|sed 's# B.*$##g'
192.168.52.129
b.
[root@kali oldboy]# ifconfig eth0|sed -ne '2s#^.*dr:##gp'|sed -n 's# Bc.*$##gp'
192.168.52.129
处理技巧:
匹配需要的目标(获取的字符串如上文的ip)前的字符串一般用以xx开头(^.)来匹配开头,
匹配的结尾写上实际的字符,
如: “^.addr:” 表达式就匹配 “ inet addr:”
而处理需要的目标后的内容一般在匹配的开头写上实际的字符,而结尾是用以xxx结尾(.$)来匹配。如:Bcast:.$部分表示匹配 “Bcast:10.0.0.255 Mask:255.255.255.0” 。
3. Linux三剑客之SED行天下
功能说明:Sed是Stream Editor(流编辑器)的缩写,是操作、过滤和转换文本内容的强大工具。常用功能有 增删改查,过滤,取行。
1.实验环境说明:
文件名称:person.txt
实验文本内容:
[root@kali oldboy]# cat person.txt
101,oldboy.CEO
102,zhangyao,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
实验目的:学会使用sed增删改查、过滤、取行。
3.1 增删改查
3.1.1 增
● a 追加文本到指定行后<br /> ● i 插入文本到指定行前
3.1.1.1 单行增加
[root@kali oldboy]#sed '2a 106,bingbing,CTO' person.txt
101,oldboy.CEO
102,zhangyao,CTO
106,bingbing,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
[root@kali oldboy]# sed '2i 106,bingbing,CTO' person.txt
101,oldboy.CEO
106,bingbing,CTO
102,zhangyao,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
3.1.1.2 多行增加
[root@kali oldboy]# sed '2a 106,bingbing,CEO\n107,weiwei,MM' person.txt
101,oldboy.CEO
102,zhangyao,CTO
106,bingbing,CEO
107,weiwei,MM
103,Alex,COO
104,yy,CFO
105,feixue,CIO
提示:蓝颜色的字体是通过命令增加进去的字符。
SED软件可以对单行或多行进行处理,如果在sed命令前面不指定地址范围,那么默认会匹配所有行。
用法:n1[,n2] {sed-commands}
地址用逗号分隔,n1,n2可以用数字、正则表达式、或二者组合表示。
例子:
10{sed-commands} 对第10行进行操作
10,20{sed-commands} 对10到20行进行操作,包括第10,20行
10,+20{sed-commands} 对10到30(10+20)行操作,包括第10,30行
1~2{sed-commands} 对1,3,5,7,…..行操作
10,${sed-commands} 对10到最后一行($代表最后一行)操作,包括第10行
/oldboy/{sed-commands} 对匹配oldboy的操作
/oldboy/,/Alex/{sed-commands} 对匹配oldboy的行到匹配Alex的行操作
/oldboy/,${sed-commands} 对匹配oldboy的行到最后一行操作
/oldboy/,10{sed-commands} 对匹配oldboy的行到第10行操作。(注意:如果前10行没有匹
配到oldboy,sed软件会显示10行以后匹配oldboy的行,如果有)
/oldboy/,+2{sed-commands} 对匹配oldboy的行到其后的2行操作
3.1.2 删
● d 删除指定的行
3.1.2.1 删除所有
[root@kali oldboy]# sed 'd' person.txt
[root@kali oldboy]#
3.1.2.2 删除第2行
[root@kali oldboy]# sed '2d' person.txt
101,oldboy.CEO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
3.1.2.3 删除第2行到第5行
[root@kali oldboy]# sed '2,5d' person.txt
101,oldboy.CEO
3.1.2.4 删除1,3,5行
[root@kali oldboy]# sed '1~2d' person.txt
102,zhangyao,CTO
104,yy,CFO
3.1.2.5 删除1到3行
[root@kali oldboy]# sed '1,+2d' person.txt
104,yy,CFO
105,feixue,CIO
3.1.2.6 删除带有oldboy字符串的行
[root@kali oldboy]# sed '/oldboy/d' person.txt
102,zhangyao,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
3.1.2.7 企业案例:打印机文件内容但不包含oldboy
[root@kali oldboy]# sed '/oldboy/d' person.txt
102,zhangyao,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
3.1.3 改
3.1.3.1 按行替换
● c 用新行取代旧行
3.1.3.2 把第二行换成 108,aliyun,CEO
[root@kali oldboy]# sed '2c 108,aliyun,CEO' person.txt
101,oldboy.CEO
108,aliyun,CEO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
3.1.3.3 文本替换
s: 单独使用→将每一行中第一处匹配的字符串进行替换 => sed命令
g: 每一行进行全部替换 => sed命令s的替换标志之一,非sed命令
-i : 修改文件内容 => sed软件的选项
例:把包含zhangyao的字符串替换成 xiaozhang
[root@kali oldboy]# sed 's#zhangyao#xiaozhang#g' person.txt
101,oldboy.CEO
102,xiaozhang,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
3.1.3.4 企业案例: 指定行修改配置文件
已知ssh配置文件sshd_config里面的Port 22字符串在第13行,请修改这一行的端口22 为65535
[root@kali oldboy]# cat -n sshd_config|grep "Port "
13 Port 22
[root@kali oldboy]# sed '13 s/Port 22/Port 65533/' sshd_config|grep "65533"
Port 65533
3.1.3.5 文件名修改
当前目录下有如下文件所示:
[root@kali oldboy]# ls *.jpg
stu_102999_1_finished.jpg stu_102999_3_finished.jpg stu_102999_5_finished.jpg
stu_102999_2_finished.jpg stu_102999_4_finished.jpg
要求用sed命令重命名,效果为stu_102999_1_finished.jpg ==> stu_102999_1.jpg,即删除文件名的
_finished
[root@kali test]# ls |sed -r 's#(^.*)_fin.*#mv & \1.jpg#g'
mv stu_102999_1_finished.jpg stu_102999_1.jpg
mv stu_102999_2_finished.jpg stu_102999_2.jpg
mv stu_102999_3_finished.jpg stu_102999_3.jpg
mv stu_102999_4_finished.jpg stu_102999_4.jpg
mv stu_102999_5_finished.jpg stu_102999_5.jpg
[root@kali test]# ls |sed -r 's#(^.*)_fin.*#mv & \1.jpg#g'|bash
[root@kali test]# ll
total 0
-rw-r—r— 1 root root 0 Aug 7 19:54 stu_102999_1.jpg
-rw-r—r— 1 root root 0 Aug 7 19:54 stu_102999_2.jpg
-rw-r—r— 1 root root 0 Aug 7 19:54 stu_102999_3.jpg
-rw-r—r— 1 root root 0 Aug 7 19:54 stu_102999_4.jpg
-rw-r—r— 1 root root 0 Aug 7 19:54 stu_102999_5.jpg
3.1.4 查
● p 输出指定内容,但默认会输出2次匹配的结果,因此使用n取消默认输出
3.1.4.1 按行查询
a、默认输出
[root@kali oldboy]# sed '2p' person.txt
101,oldboy.CEO
102,zhangyao,CTO
102,zhangyao,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
b、取消默认输出
[root@kali oldboy]# sed -n '2p' person.txt
102,zhangyao,CTO
c、输出所有行
[root@kali oldboy]# sed -n 'p' person.txt
101,oldboy.CEO
102,zhangyao,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
3.1.4.2 按字符串查询
a、包含CEO的行
[root@kali oldboy]# sed -n '/CEO/p' person.txt
101,oldboy.CEO
b、显示包含CEO的行到包含CFO的行
[root@kali oldboy]# sed -n '/CEO/,/CFO/p' person.txt
101,oldboy.CEO
102,zhangyao,CTO
103,Alex,COO
104,yy,CFO
3.1.4.3 混合查询
[root@kali oldboy]# sed -n '2,/CFO/p' person.txt
102,zhangyao,CTO
103,Alex,COO
104,yy,CFO
提示:指定查询第2行,但没有查询到,所以一直往下查。
[root@kali oldboy]# sed -n '/feixue/,2p' person.txt
105,feixue,CIO
提示:特殊情况,前两行没有匹配到feixue,就向后匹配,如果匹配到feixue就打印此行。

若有收获,就点个赞吧
0 人点赞
