摘要&关键词
摘要:[目的/意义]对目前常见的多要素评价中指标权重的确定方法进行系统梳理,为相关研究人员在进行具体问题评价时的指标权重确定方法的合理选择提供参考。[方法/过程]通过对几种常见的主观赋权法、客观赋权法以及主客观综合集成赋权法中具体确定指标权重方法的基本原理与思想、具体应用案例进行深入调研,分析总结其优缺点以及适用范围。[结果/结论]迄今还没有一种完全通用和普适的指标权重确定方法,不同指标权重确定方法的原理与指导思想不同,因而其适用范围也有所差异,在进行实际问题评价时,要依据评估对象的特点合理选择赋权方法,以提高综合评价的准确性和有效性。
关键词:多要素评价;指标权重;赋权方法
1 引言
指标权重的确定是多要素综合评价中的关键环节,权重确定的是否合理将直接影响评价结果的可靠性和有效性。迄今为止,国内外学者围绕多要素评价中指标权重的确定方法开展了大量研究,并取得了丰硕的研究成果。
综观国内外的研究可以发现,指标权重确定的方法多种多样,但归纳起来大致可分为三大类,分别是主观赋权法、客观赋权法以及主客观综合集成赋权法。其中,主观赋权法多是依赖于专家的知识经验进行主观判断来确定指标权重,客观赋权法主要是依靠样本数据分析计算出权重,而主客观综合集成赋权法是基于主、客观赋权法各自的不足和优势,将两者所得的权重综合集成。不同赋权方法的原理思想不同,导致所依赖的理论模型、原始数据、对数据的处理方式等都会存在差异,从而使最终的权重分配也产生很大的差异。因此,不同的指标体系要根据自身特点选择其所适合的权重确定方法,这样才能使其指标的权重分配比较合理。
2 常见的主观赋权法
一般地,主观赋权法在确定权重时主要依据决策者和专家的知识经验或偏好,将各指标按重要程度进行比较、分配权值或计算得出其权重,其认为权重的实质是评价指标对于评价目标相对重要程度的量化体现。此类方法的主观随意性比较强,但指标权重大小的排序基本与评价对象的实际情况相符合。目前比较常用的主观赋权方法可归为4类:专家估测法、层次分析法、二项系数法、环比评分法。
2.1 专家估测法
专家估测法是由相关领域专家依据自身的经验知识,主观判断各指标的重要性,指标最终的权重分配值可直接由K个专家独立给出的权重值的平均得出1,或者利用频数统计法来确定权重,即对于每个指标,将其K个权重分配值按照一定的组距进行分组,计算每组内权重的频数,频数最大的分组的组中值就是相应指标的最终权重值2。
早在1986年F. Shands等3就将专家估测法用于教师绩效评价体系的指标权重确定,通过问卷的形式将评判指标提交给数位领域专家进行两轮打分来分配权重,最终得到的绩效评价模型在学校的实际应用中取得了较好的效果。近两年我国学者刘璐等4在供热系统节能评价的指标权重确定中也使用了该方法,通过多位领域专家给出的权重系数的平均值确定出各指标权重,并分别与层次分析法和变异系数法的综合评价结果进行对比,结果显示专家估测法与实际系统运行情况最相符,这主要是由于热源系统在运行中存在很多现实影响因素,而专家们会相对周全考虑这些因素从而更合理地分配权重。
专家估测法的优点主要体现在3个方面:一是充分利用专家的经验知识,能根据专家经验综合全面考虑各种外界影响因素,方法的可靠性较高;二是指标权重的计算以传统的描述性统计为主,如求解均值和统计频数,简单直接;三是不受是否有样本数据的限制,能对大量非技术性无法定量分析的指标做出概率性估计。该方法也存在一定的缺陷:一是权重的分配完全受专家经验知识的影响,不同的专家组成可能就会产生不同的评价结果,存在很大程度的主观随意性;二是当指标较多时,不易保证判断思维过程的一致性,较难做到一定会客观合理。
从总体上来说,该方法的适用范围很广,适用于指标数量适中的各种评价体系,特别是对于那些没有样本数据、难以建立数学模型的实际问题,比较行之有效。
2.2 层次分析法
层次分析法的基本思想是把复杂问题的各指标按相互间的从属关系分解为若干个有序的递阶层次结构,每层内部指标请领域专家根据一定的比值标度进行两两比较,将主观判断量化形成判断矩阵,再利用数学方法计算每层判断矩阵中各指标相对于上一层的权重值,最后进行层次总排序,计算出全部指标相对于总目标的权重系数5。目前关于判断矩阵中指标权重系数的计算方法有20多种,包括特征向量法、最小二乘法、方根法、线性规划法等,不同方法所确定的指标权重排序存在一定差异。
层次分析法被广泛应用于各评价体系的指标权重确定中。例如,早在上世纪R. Shen等6就利用该方法对产业中劳动力强度进行评价,通过将数十位领域专家对指标相对重要性的量化评判进行综合得到判断矩阵,再利用特征向量法计算出指标权重,并通过了一致性检验,所构建的评价模型在实际应用中取得了较好的效果。我国学者楚存坤等7将其运用于定性指标为主的高校图书馆学科服务模式的三级评价指标体系中,也取得了较好的评价效果。
层次分析法的优点主要体现在3个方面:一是把决策者依据主观经验知识的定性判断定量化,将定性分析与定量分析有机结合起来,充分发挥了两者的优势,一方面蕴含着决策者的逻辑判断和理论分析,另一方面又通过客观的推演与精确计算,使决策过程具有很强的科学性,从而使得决策结果具有较高的可信度;二是将复杂评价问题进行层次化分解,形成递阶的层次结构,使复杂问题的评价更清晰、明确、有层次;三是不受是否有样本数据的限制,能解决传统最优化技术无法处理的实际问题。但是该方法也具有一定的局限性,一是指标权重的确定主要依赖于专家经验知识,专家选择的不同很可能会导致权重分配结果的差异,具有主观随意性和不确定性;二是层次分析法的判断矩阵很容易出现严重不一致的情况,当同一层的指标很多,并且由于九级比值标度法很难准确掌握,决策者很容易做出矛盾且混乱的相对重要性判断。针对这一问题,马农乐等8提出利用三级标度法来替代九级标度法构建判断矩阵,更容易衡量指标间的重要程度,且无需一致性检验;但是这样做的结果使得各指标的权重分布较集中,很容易出现多个指标权重难以区分的情况。
总的来说,层次分析法的适用范围很广,特别适用于缺乏样本数据且评价目标结构复杂,以及领域专家对指标相对重要性大小程度有较为清晰认识的指标数量适中的评价体系。
2.3 二项系数法
二项系数法9的基本思想是先由K个专家独立对n个指标的重要性进行两两比较,经过复式循环比以及统计处理得到代表优先次序的各指标的指标值,再根据指标值的大小将指标按照从中间向两边的顺序依次排开,形成指标优先级序列,对序列中的指标重新按从左到右的顺序进行编号得到指标序列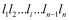 ,从而根据二项系数的原理,第
,从而根据二项系数的原理,第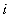 个指标的权重分配值为
个指标的权重分配值为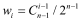 。
。
二项系数法用于指标权重的确定最初是由中国学者程明熙9于1983年提出的,后续主要在国内得到了较广泛的应用,如早期赵书立10将该方法用于实验室设备投资的多指标评价中,先通过数位专家对各指标打分的平均情况确定指标优先级,再根据二项展开式系数求出各指标的权重,最终得到的最优评价结果为高校决策者在设备投资方面提供了可靠的依据。近几年,刘富强等11将其用于抽蓄工程开挖工期影响因素的指标权重确定上,由于抽蓄工程影响因素众多,难以主观具体量化因素间的相对权重值,因此依靠领域专家直接评判指标优先级,再利用二项系数计算出权重,最终的影响因素评价结果与利用熵权法的评价结果一致。
二项系数法的优点主要有4方面:一是将定性分析与定量计算有机结合,将主观经验知识定量化,增加了评价过程的科学性和条理性;二是不需要对指标的重要性大小进行具体量化,只需要判断指标间的相对大小情况,专家判断相对容易,不会产生矛盾且混乱的判断;三是采用二项展开式进行权重计算,方法简单易操作;四是不受是否有样本数据的限制,能解决传统最优化技术无法处理的实际问题。但该方法也存在一定的缺陷:一是权重的确定主要依赖于专家经验知识的主观判断,存在随机性和不确定性;二是在利用二项系数公式计算不同优先级的指标权重时会出现权重相同的情况,在指标优先级序列中左右对称的两指标计算出的权重值会相同,与实际情况会产生一定的偏差;三是该方法只注重指标重要性的级别次序,而不关注指标间相对重要性的差异程度,权重分配会存在偏差。
总的来说,该方法对是否有样本数据没有限制,适用范围较广,尤其适用于那些缺乏先例,缺乏定量赋权经验的指标数量适中的多因素评价问题。
2.4 环比评分法
环比评分法12的基本思想是依据专家经验知识,将指标依次与相邻下一个指标进行重要性比较,综合多个专家的判断确定相邻指标间的重要性比值,再以最后一项指标为基准,逆向计算出各指标的对比权,并进一步做归一化处理得到各指标权重。
环比评分法最早是由中国学者陆明生12于1986年提出的,并在国内外得到了较广泛的应用。例如陈志刚等13将该方法用于上海市创新型城市阶段的评价中,依靠专家确定出评价指标间的环比值,再进行修正归一化处理得到指标权重,最终的评价结果与上海市当时的实际发展相符。J. Xie等14在评价公路应急预案时也采用了该方法,先由专家自上而下对指标两两比较确定其重要度,再进行基准化和归一化处理得到权重,评价结果与现实选择相符,体现了方法的有效性。
环比评分法的优点主要体现在4方面:一是将定性判断与定量计算有机结合,使评价过程更具条理性和科学性;二是专家所需确定的指标重要性评价值数量较少,赋值过程相对简单;三是单向依次确定指标相对重要度,不容易产生判断上的矛盾,也不需要进行层次分析法中的一致性检验,能有效解决复杂决策问题;四是不受是否有样本数据的限制,能解决传统最优化技术无法处理的实际问题。但该方法也存在一定的缺陷:一是对专家知识的要求较高,需要专家对评判指标的重要性有很清晰的认识并能对每对相邻指标进行精准的量化比较,否则很容易使整个指标体系的权重分配产生较大偏差;二是权重的确定主要依赖于主观经验知识,具有较大的不确定性和主观随意性。
总的来说,该方法对是否有样本数据无限制,适用范围较广,特别适用于能够对相邻评价指标的相对重要性做出较为准确的定量判断的各种评价问题中。
3 常见的客观赋权法
客观赋权法是依赖一定的数学理论,完全基于对指标实际数据的定量分析而确定指标权重的方法,保证了权重的绝对客观性,对样本数据有较高的要求。但客观赋权法忽略了人的经验等主观信息,有可能会出现权重分配结果与实际情况相悖的现象,且依赖于实际业务领域,缺乏通用性。目前主要的客观赋权法有:变异系数法、基于主成分分析与因子分析的多元统计法、向量相似度法、灰色关联度法、熵值法、粗糙集法以及神经网络法。
3.1 变异系数法
变异系数法的思想原理是通过计算各指标实测数据的差异程度来确定指标权重的大小,指标内部数据差异性较大,则该指标对评价对象的区分作用越大,其权重分配值也就越大15。变异系数法确定权重所依据的数学理论主要包括标准差和离差最大化两种,即通过各指标内部数据的标准差(最大离差)的计算与归一化处理,得到各指标权重分配。
变异系数法被广泛应用于指标体系的赋权中,例如早期时光新等16将该方法用于小流域治理效益的评价中,通过指标样本数据的无量纲化处理以及数据标准差的计算,归一化处理得到指标权重,依赖此评价模型所得到的评价结果能客观反映实际情况。近几年H. Zheng等17将其用于风电场经济运行评价指标的权重确定中,先对近十几年风电场实际运行和监测情况大量样本数据的一致性、无量纲化处理,再通过计算各指标数据的标准差确定出权重,并根据对三种风电场的评价比较,验证了评价体系的有效性。
变异系数法的优点体现在3方面:一是指标权重的计算方式比较简单,方便实用;二是充分利用样本数据,客观体现了各指标分辨能力的大小,保证了指标权重的绝对客观性;三是该方法对评价指标的数量没有限制,适用范围较广。但是,该方法也存在一定的缺陷:一是评价结果与数据样本的选择有很大相关性,不同的数据样本可能会产生不同的权重分配结果,当样本容量很小且不具有普遍性时,方法的精度会很低;二是对于样本数据中的异常值没有解决能力,如果有异常值出现,该方法在权重的确定上就会存在很大误差;三是它不能反映指标内在的联系,只是对每个指标单独进行分析判断;四是纯粹进行客观计算,不能体现决策者对指标重要性的理解。
因此,该方法适用于评价指标间的独立性较强,指标的样本数据具有普遍性、相对完整且样本量较大,样本数据中没有异常值的综合评价。
3.2 多元统计法
多元统计法是指利用多元统计分析来对样本数据进行计算从而确定指标权重的方法,包括主成分分析法和因子分析法两种。
3.2.1 主成分分析法
主成分分析法18的基本原理是利用降维的思想,依据指标的方差贡献率将一组具有一定相关性的指标转化为另一组不相关的少数几个综合性指标,即主成分,并进一步归一化处理得到各指标的权重。
主成分分析法自出现以来得到了广泛应用,例如早期我国学者金星日等19将该方法用于工业企业经济效益综合评价中,通过对延边通用厂1990-1995年的主要经济效益指标的样本数据的标准化处理以及主成分分析,得到4个主成分以及各指标权重以确定评价模型,最终的评价结果与用理想解法评价一致。近两年,B. Prado等20在评定德国明纳斯城市的气候变量情况时使用了该方法,通过对2008-2012年相关样本数据的主成分分析,得到以一个主成分来解释总体变量的评价模型,评价结果与实际情况相符。
主成分分析法的优点主要体现在3方面:一是其用较少的独立性指标来替代较多的相关性指标,解决了指标间信息重叠的问题,简化了指标结构;二是指标权重是依赖客观数据,由各主成分的方差贡献率计算确定的,避免了主观因素影响,较为客观合理;三是对指标数量和样本数量没有具体限制,适用范围广泛。但该方法也存在四点缺陷:一是指标权重的计算过程较为复杂,权重确定的结果与样本的选择有很大相关性;二是损失了一定的样本数据信息,有些具有现实意义的指标在该方法中可能会被剔除,与实际情况产生偏差;三是其假定指标间都是线性关系,实际问题中很多非线性关系的指标体系使用该方法时会产生偏差;四是纯粹依赖客观数据确定权重,忽略了主观经验知识,评价结果可能产生与实际情况相悖的现象。
总的来说,主成分分析法适用于样本数据相对完整并具有代表性,指标间存在一定相关关系且指标间基本为线性关系的复杂评价体系中的指标权重确定。
3.2.2 因子分析法
因子分析法21的基本思想与主成分分析法类似,也是将具有相关性的指标转化为少数几个不相关的指标,再根据各因子的方差贡献率确定指标权重。所不同的是,主成分分析法是将原始指标进行线性组合,而因子分析法将原始指标拆分成共同具有的公共因子以及每个指标所特有的特殊因子来线性表示,因子表示具有更明确的实际意义。
因子分析法被广泛应用于各类综合评价问题中,尤其是对社会经济领域相关问题的评价分析。如早期我国学者万建强等22将该方法用于上市公司经营业绩评价中,通过对建材行业有代表性的13家上市公司的1999年年报数据进行标准化处理以及因子分析,取前4个具有解释意义的相互独立的综合因子代替原来的11个指标进行综合评价,评价结果与各企业的实际经济排名一致。近两年,A. Bai等23将其用于国家经济排名评估中,使用货币基金组织数据集对20个国家的15个经济指标进行因子分析,用3个综合因子来解释和代表所有指标并进行综合评价,最终计算出的排名与世界排名所提供的几乎一致,证实了该方法的可行性。
因子分析法在指标权重确定上的优缺点与主成分分析法类似,但因子的个数小于原指标个数,而主成分的个数可与原指标数相等,因而因子分析法的缺失信息一般比主成分分析法要多,其精确度一般比不上主成分分析法,计算过程也更为复杂,且因子分析法严格要求评价体系的指标间要存在相关关系。不过,因子分析法能很明确地解释原指标的具体内容,能解释指标间相关的原因,能对指标内容有更深层次的认识。
总的来说,因子分析法比较适用于需要对社会经济现象等相关评价对象进行较为深层次分析,且指标间存在很大关联性、有大量具有代表性的完整数据样本的复杂评价问题。
3.3 向量相似度法
向量相似度法24的基本原理是利用每个指标的样本数据组成的特征向量与所有指标的理想值组成的参考向量求解相似度,由向量相似度大小来反映各指标对系统发挥最佳效能的贡献度,并将其归一化处理得到各指标权重。
向量相似度法用于指标权重的确定最初是由我国学者焦利明等24提出的,后续在国内被很多学者应用于综合评价中。例如,焦利明等25利用该方法对防空旅团系统效能进行评估,抽取了6组具有代表性的样本数据,对数据进行无量纲化处理,并计算出各指标数据向量与标准化后的理想参考向量的相似度,进一步归一化处理得到各指标权重,对系统效能进行了有效的评估。谢平等26利用其对湖泊富营养化进行评价,以全国30个湖泊的实测水质资料为数据样本,将各评价指标的样本数据组成的向量与各级指标的理想参考向量进行无量纲化处理,并计算向量相似度,归一化处理得到指标权重,评价结果与之前利用模糊方法、随机方法等的评价结果高度一致。
向量相似度法的优点主要体现在3方面:一是计算简单易操作,将指标数据向量与所有指标的理想值组成的向量进行相似度计算,巧妙利用了所有指标组成的理想参考向量经过无量纲化后变为全部元素值为1的单位向量,就与同一指标的理想值与该指标的数据求解相似度是一样的,减少了计算次数;二是结果易理解,方法考虑到与最优方案间的关系,实用性强;三是充分利用样本数据,没有人为因素的干扰,客观性强;四是对指标数量和样本量没有具体限制,适用范围较广。但同时该方法也存在一定的缺陷:一是方法的精度会受数据样本的影响,样本容量很小且不具有代表性时,该方法评价结果的精度就很低;二是方法不能解决指标间的相关性所造成的信息重复问题,容易造成部分相关指标的权重因重复计算而变大的现象;三是纯粹利用客观数据进行权重计算,忽略了主观经验知识,可能会产生与实际相悖的情况。
总的来说,该方法比较适用于有适量的、较为完整的样本数据,且样本数据具有典型性和代表性,评价指标间较为独立的综合评价体系。
3.4 灰色关联度法
灰色关联度法27的基本思想是将数据对比与几何曲线变化趋势相结合来计算权重,即利用各方案与最优方案间的关联度大小来确定指标权重。该方法具体通过各方案与理想方案的灰色关联判断矩阵及关联系数,计算出各指标对整个系统发挥最优效能的贡献度,并进一步归一化处理得到指标权重。
灰色关联度分析法被广泛应用于很多学科领域的实际决策问题中。早在20世纪80年代我国学者马峙英等28就将该方法用于棉花品种的评价中,以1986年黄河流域棉花抗病区的7个棉花品种的性状数据为样本,对数据进行无量纲化处理,再计算出各品种与理想品种间的灰色关联系数,归一化处理得各指标权重,最终得到的评价结果与模糊综合评判的结果一致。后来,C.Ho29把其用于银行经营绩效的评价中,数据样本为三家台湾银行的财务文件,采用与马峙英等28求解的类似步骤计算出指标权重,并据此建立评价模型对三家银行进行评价,评价结果与财务报表的分析结果一致,说明了方法的有效性。
灰色关联度分析法的优点主要体现在4个方面:一是方法的计算过程相对简便,考虑到与理想决策方案之间的关系,结果直观易理解;二是无需大量样本,只需少量具有代表性的数据样本即可,且对指标数量无限制;三是方法具有一定的容错能力,因为关联度计算时用到的是两极最大差与最小差,使某些由于数据部分缺失或人为误差所导致的数据不准确问题得以弱化,使分析结果相对合理;四是依靠样本数据进行权重计算,避免了人为因素的干扰,客观性强。该方法也存在一定的缺陷:一是在计算灰色关联系数时的分辨系数值是人为主观决定的,不存在固定标准,取值的不同会影响最终的权重分配,使可信度降低;二是方法的准确性会受样本的影响,样本选择的不同可能会导致最终评判结果的差异;三是方法不能解决指标间相关所造成的信息重叠问题;四是没有考虑主观经验知识,评价结果可能会与实际情况相悖。
总的来说,该方法适用范围较广,对指标数量和样本数量无限制,比较适用于样本数据较为完备、样本具有代表性和典型性且指标间相对独立的综合评价体系。
3.5 熵值法
熵值法30的基本思想是从指标的无序程度,即指标熵的角度来反映指标对评价对象的区分程度,某指标的熵值越小,该指标的样本数据就越有序,样本数据间的差异就越大,对评价对象的区分能力也越大,相应的权重也就越大。该方法首先根据熵值函数求出每个指标的熵值,再将熵值归一化转化为指标权重。
熵值法自提出以来,被广泛应用于很多领域问题的评价中。例如,早期朱顺泉等31将该方法用于对上市公司财务状况的评价,以2000年的《中国证券报》中20家公司的15个评价指标数据为样本,先对数据进行无量纲化处理,再计算各指标的熵值并进一步归一化处理得指标权重,经过简单加权得各公司的综合评价值,评价结果合理。后来,A.Gorgij等32在对地下水质的评估中也使用了该方法,在2016年对伊朗阿扎沙赫平原的21个地下水样品进行了水质抽样评价,通过类似的熵值法计算步骤,计算出各指标权重,并进一步利用综合评价模型评定各样本的水质等级,评价结果与空间自相关系数的评价一致。
熵值法在确定指标权重时存在3方面的优点:一是方法的计算过程相对简单,从指标对评价对象的区分程度角度来确定指标权重,结果直观易理解,方法实用性强;二是完全依赖样本数据进行权重计算,避免了主观因素的干扰,客观性强;三是方法对指标数量没有限制,适用范围较广。但该方法也存在三点不足:一是方法的精度会受数据样本的影响,不同的样本选择可能会产生不同的权重分配结果,且对样本数据的完备性以及样本量有较高要求;二是不能反映指标间的相关关系,不能解决信息重叠问题;三是不能体现决策者对各指标重要性的理解,在一定程度上可能会产生与事实相悖的情况。
因此,该方法比较适用于样本量较大、样本数据信息完备且具有普遍性的指标间相对独立的综合评价体系。
3.6 粗糙集法
粗糙集法33用于指标权重确定的基本思想是先按体系内所有指标对评价对象进行原始分类,每次约简一个指标,考虑约简后的对象分类与原始分类相比的变化程度,指标重要性与变化程度成正比。粗糙集中属性(指标)重要度的概念可归结为代数表示的定义与信息表示的定义两种,进一步按指标的等价关系、优势关系和容差关系的思想衍生出多种细分赋权方法。从指标等价关系、优势关系、容差关系角度出发的粗糙集赋权法的区别主要在于对象分类所依据的标准不同,等价关系是将所有评价对象按等价思想进行划分,而优势关系是将评价对象按在条件属性集上的优势程度进行划分,容差关系则是根据对象间的差异度进行划分。等价关系要求待处理的数据为离散型,优势关系中的数据则可以是连续型,而容差关系主要用于处理样本数据有缺失的情况。
粗糙集法被广泛应用于各类评价问题的指标权重确定中,例如,IP.WC等34将该方法用于水质量的评价中,以汉江流域1992-1997年4、5月的水质实测数据为条件属性集的样本,以各时间段各指标数值的等权加总平均数为决策属性,先将样本数据离散化处理,再基于等价关系的代数粗糙集方法对各指标重要度进行计算,并归一化处理得指标权重,最终计算出的各时间段水质综合评价等级与实际情况相符。邹斌等35利用其对华东地区能源消费进行评价,以2011年中国能源统计年鉴中华东8省(市)各能源消费数据为样本,进行属性集上的优势类划分(无需对样本数据离散化处理),并根据代数属性重要性定义求出各指标权重,评价结果与灰色关联度赋权法的结果较为一致,合理可靠。
粗糙集法在指标赋权上的优势主要体现在5个方面:一是能处理的数据类型广泛,包括离散型数据和连续型数据,对连续型数据的有效处理减少了因数据离散化所造成的信息损失问题;二是具有较强的容错能力,能处理缺失型样本数据,有效解决了数据缺失下的赋权问题;三是信息表示的重要度能弥补代数表示的重要度中指标权重值可能为0的缺陷,提高了方法的精度;四是方法对指标数量没有限制,适用范围广;五是完全依赖客观数据进行权重计算,避免了主观因素的干扰。但该方法也存在一定的缺陷:一是方法的精度会受数据样本的影响,不同的样本选择可能会产生不同的决策结果;二是不能解决指标间相关所造成的信息重叠问题;三是不需要先验信息的客观赋权,计算结果可能会与决策者的理解相悖。
总的来说,粗糙集法在客观赋权方法里是应用范围最广的,适用于数据样本具有一定普遍性,且样本量较大的指标间相对独立的多属性决策问题。
3.7 神经网络法
神经网络法中最常用的是BP神经网络算法,赋权的基本思想36是根据一定的学习机制,对大量数据样本进行非线性的并行学习训练,具体是根据误差的精度要求对输出数据与已知样本输出数据差值的不断迭代调整,得到符合要求的输入层到隐含层间的连接权矩阵,将每个输入层节点到所有隐含层节点连接权的绝对值求和并归一化处理得到指标权重。
神经网络法目前被越来越多地用于指标权重的确定中,例如,早期J. Ch等37将该方法用于电子政务网站的评价中,以宁波市20个电子政务网站的相关数据作为训练样本(以11个评价指标和专家的评价结果为具体样本数据),训练计算得各指标权重,并将评估模型用于另外10个电子政务网站的评价中,评价结果与专家评估较为一致。后来, S. Silva等38将该方法用于特级初榨橄榄油稳定性的评估中,训练样本由黑暗和光明条件存储下的18种特级初榨橄榄油组成(包括11个评判指标和实验数据所得的评价结果),训练计算得各指标权重,将评估模型用于训练样本之外的10组橄榄油稳定性评估中,评估结果与实验显示的测试分类的一致性大于90%,表明该方法有较高的准确性。
神经网络法的优点主要体现在3个方面:一是其能处理非线性的复杂系统评价问题,并且能进行动态评估,对体系分析处理的功能强大;二是通过对样本的学习训练,能够获得经实际检验是合理、科学且符合实际的指标相对重要性信息,保证了指标权重的客观性和实用性;三是对评价指标的数量没有限制,应用范围很广。但该方法也存在一定的缺陷:一是其完全建立在训练样本基础上,就对样本的要求很高,训练样本要具有正确性且面广量大(主要强调样本的覆盖类型广,量并非越大越好),才能保证结果的可靠;一定程度上忽略了主观经验知识,评估结果可能会与决策者的主观偏好相悖。
总之,神经网络法对于复杂系统的评价问题具有很强的处理能力,比较适用于样本数据量较多且涵盖面较广,指标间相对独立的各类复杂体系的指标权重确定问题中。
4 常见的综合集成赋权法
综合集成赋权法是依据不同的偏好系数将主观赋权法和客观赋权法相结合来确定指标权重的综合方法。基于主观赋权法中对专家经验知识与决策者主观意向的信息体现,以及基于客观赋权法中对指标与评价对象间内在联系的信息表现,综合集成赋权法通过一定的数学运算将两者有效结合起来,达到了优势互补的效果。目前依据不同原理的综合集成赋权方法有多种形式,但大致可将其归为4类,分别是基于加法或乘法合成归一化的综合集成赋权法、基于离差平方和的综合集成赋权法、基于博弈论的综合集成赋权法、基于目标最优化的综合集成赋权方法。
基于加法或乘法合成归一化的综合集成赋权方法是直接将主、客观赋权法所得的指标权重以同等偏好的形式直接相加或相乘,并进行归一化处理得到各指标的综合权重。例如,L. Yang等39在供应链风险评估中,利用该方法对层次分析法确定的主观权重与变异系数法确定的客观权重等权相乘,再归一化处理得各指标综合权重,评估结果具有较高的精度。
基于离差平方和的综合集成赋权法是从决策方案的区分有利性角度,来求解能使决策方案的综合评价值尽可能分散,即各方案综合评价值间的总离差平方和最大的主客观权重分配系数。例如,B. Meng等40将该方法用于银行信用风险评估中,根据主客观赋权法对不同对象评价值的整体离差平方和最大化原则,计算出主客观权重的最优调整系数,归一化得各指标综合权重,评价结果相比主、客观单一赋权法具有较高的准确性。
基于博弈论的综合集成赋权法是在主客观的不同权重之间寻求妥协或一致,尽可能保持主客观权重的原始信息,求解与主客观权重离差极小化的权重分配系数。例如,C. Lu等41在教育信息化发展水平的评估中,利用该方法的思想将层次分析法确定的指标主观权重与变异系数法确定的客观权重进行计算分配权重系数,并归一化处理得到各指标的综合集成权重,该模型在对苏州11个地区学校的教育信息化发展水平的评价中取得了较好的效果。
基于目标最优化的综合集成赋权法是基于综合决策结果最优的原则来求解主客观权重系数分配,包括综合目标值最大、与负理想解的偏离程度最大两种具体求解方法。例如,J. Yan等42在学习型城市的评估中,将专家估测法得到的指标主观权重与熵值法得到的客观权重根据总体综合评价值的最大化原则,计算分配出主、客观权重系数,并依据此模型对四个学习型城市进行了较准确的评价。
总之,各种综合赋权法都有一定的理论依据,并通过线性方程组、矩阵运算等数学思想来进行具体求解,有些方法集成计算简单,而有些则给评估过程带来了较大的计算量,但各方法间没有绝对的好坏程度之分,并且目前实际应用中对于何种评估问题选择何种综合赋权方法还没有一致性结论。另外,综合赋权法与主、客观赋权法相比,得到的评价结果相对更加科学、合理,但也可能存在较大的随机性偏差,导致结果与实际情况不符,其不能完全取代单一赋权法,在实际问题研究中选择赋权方法时要有一个理性的认识。
5 结论
本文重点分析了常见的主观赋权法、客观赋权法以及主客观综合赋权法中具体权重计算方法的基本思想和原理,对各种方法的优缺点进行了比较分析,并分别理出了各方法的适用范围。研究发现每种赋权方法考虑问题的侧重点都有所不同,在权重计算上都具有一定的优势与缺陷,相应的适用范围也存在较大的差异。因此,在进行多要素评价指标赋权方法的选择时,要理性认识和把握各方法的优缺点,并且要具体问题具体分析,根据评价对象和问题的实际特点,如是否具有数据样本、样本是否具有代表性、指标间是否存在相关关系等选择合适的赋权方法,这样才能保证评价结果的相对科学和合理性。
稿件与作者信息
作者信息
刘秋艳
Liu Qiuyan
中国科学院兰州文献情报中心 兰州 730000
Lanzhou Library of Chinese Academy of Science, Lanzhou 730000
中国科学院大学 北京 100049
University of Chinese Academy of Science, Beijing 100049
本文贡献:负责资料收集、分析和论文撰写。
作者简介:硕士研究生。
吴新年
Wu Xinnian
中国科学院兰州文献情报中心 兰州 730000
Lanzhou Library of Chinese Academy of Science, Lanzhou 730000
本文贡献:提出论文选题和思路,修订完善论文。
通讯邮箱:wuxn@lzb.ac.cn
作者简介:研究员,博士,硕士生导师。
出版历史
出版时间: 2017年12月25日 (版本2)

若有收获,就点个赞吧
0 人点赞
