- 前端算法
- 算法复杂度
- 动态规划
- 贪心
- 二分查找
- 704. 二分查找">704. 二分查找
- 278. 第一个错误的版本">278. 第一个错误的版本
- 35. 搜索插入位置">35. 搜索插入位置
- 剑指 Offer II 006. 排序数组中两个数字之和">剑指 Offer II 006. 排序数组中两个数字之和
- 剑指 Offer II 069. 山峰数组的顶部">剑指 Offer II 069. 山峰数组的顶部
- 374. 猜数字大小">374. 猜数字大小
- 69. x 的平方根">69. x 的平方根
- 剑指 Offer 11. 旋转数组的最小数字">剑指 Offer 11. 旋转数组的最小数字
- 剑指 Offer 51. 数组中的逆序对">剑指 Offer 51. 数组中的逆序对
- 回溯
- 链表
- 203. 移除链表元素">203. 移除链表元素
- 206. 反转链表">206. 反转链表
- 剑指 Offer 35. 复杂链表的复制">剑指 Offer 35. 复杂链表的复制
- 21. 合并两个有序链表">21. 合并两个有序链表
- 141. 环形链表">141. 环形链表
- 142. 环形链表 II">142. 环形链表 II
- 160. 相交链表">160. 相交链表
- BM2 链表内指定区间反转
- BM3 链表中的节点每k个一组翻转
- 剑指 Offer 22. 链表中倒数第k个节点">剑指 Offer 22. 链表中倒数第k个节点
- 剑指 Offer II 021. 删除链表的倒数第 n 个结点">剑指 Offer II 021. 删除链表的倒数第 n 个结点
- 剑指 Offer II 025. 链表中的两数相加">剑指 Offer II 025. 链表中的两数相加
- 剑指 Offer II 027. 回文链表">剑指 Offer II 027. 回文链表
- 剑指 Offer II 077. 链表排序">剑指 Offer II 077. 链表排序
- 328. 奇偶链表">328. 奇偶链表
- BM16 删除有序链表中重复的元素-II
- 二叉树
- 二叉树的前序遍历
- 94. 二叉树的中序遍历">94. 二叉树的中序遍历
- 二叉树的后序遍历
- 102. 二叉树的层序遍历">102. 二叉树的层序遍历
- 103. 二叉树的锯齿形层序遍历">103. 二叉树的锯齿形层序遍历
- 104. 二叉树的最大深度">104. 二叉树的最大深度
- 230. 二叉搜索树中第K小的元素">230. 二叉搜索树中第K小的元素
- 236. 二叉树的最近公共祖先">236. 二叉树的最近公共祖先
- 129. 求根节点到叶节点数字之和">129. 求根节点到叶节点数字之和
- 101. 对称二叉树">101. 对称二叉树
- 98. 验证二叉搜索树">98. 验证二叉搜索树
- 105. 从前序与中序遍历序列构造二叉树">105. 从前序与中序遍历序列构造二叉树
- 226. 翻转二叉树(镜像)">226. 翻转二叉树(镜像)
- 617. 合并二叉树">617. 合并二叉树
- 110. 平衡二叉树">110. 平衡二叉树
- 437. 路径总和 III">437. 路径总和 III
- 剑指 Offer 34. 二叉树中和为某一值的路径">剑指 Offer 34. 二叉树中和为某一值的路径
- 538. 把二叉搜索树转换为累加树">538. 把二叉搜索树转换为累加树
- 114. 二叉树展开为链表">114. 二叉树展开为链表
- 剑指 Offer 36. 二叉搜索树与双向链表">剑指 Offer 36. 二叉搜索树与双向链表
- 235. 二叉搜索树的最近公共祖先">235. 二叉搜索树的最近公共祖先
- BM35 判断是不是完全二叉树
- 栈和堆列
- 剑指 Offer 09. 用两个栈实现队列">剑指 Offer 09. 用两个栈实现队列
- 剑指 Offer 30. 包含min函数的栈">剑指 Offer 30. 包含min函数的栈
- 剑指 Offer 59 - I. 滑动窗口的最大值">剑指 Offer 59 - I. 滑动窗口的最大值
- 20. 有效的括号">20. 有效的括号
- 394. 字符串解码">394. 字符串解码
- 215. 数组中的第K个最大元素">215. 数组中的第K个最大元素
- 剑指 Offer 31. 栈的压入、弹出序列">剑指 Offer 31. 栈的压入、弹出序列
- 剑指 Offer 40. 最小的k个数">剑指 Offer 40. 最小的k个数
- 字符串
- 双指针
- 哈希表
- 模拟
前端算法
算法复杂度
console.time();for (let a = 0; a <= 1000; a++) {for (let b = 0; b <=1000; b++) {for (let c = 0; c <= 1000; c++) {if (a + b + c === 1000 && Math.pow(a,2) + Math.pow(b,2) === Math.pow(c,2)) {console.log(`${a}平方 + ${b}平方 = ${c}平方 `)}}}}console.timeEnd()//输出//0平方 + 500平方 = 500平方//200平方 + 375平方 = 425平方//375平方 + 200平方 = 425平方//500平方 + 0平方 = 500平方//default: 742.633ms
console.time();for (let a = 0; a <= 1000; a++) {for (let b = 0; b <=1000; b++) {let c = 1000 - a - b;if (Math.pow(a,2) + Math.pow(b,2) === Math.pow(c,2)) {console.log(`${a}平方 + ${b}平方 = ${c}平方 `)}}}console.timeEnd()//default: 11.982ms
可以看出少了一个for循环时间消耗少了不少。
一个优秀的算法应该占用较少的内存空间和时间去完成需求。评价算法的好坏我们需要将时间占用和空间占用量化,称为时间和空间复杂度分析。
时间复杂度:看作是一个代码的执行时间根据数据规模增长的趋势。执行次数与执行参数息息相关,如果一个问题的规模是n,解决这个问题的某一算法所需要的时间复杂度是T(n)。
T(n) = O(f(n)) //大O表示法,f(n)指明某个算法耗时与数据增长量之间的关系。
常见的时间复杂度:
- 常数阶:O(1)。T(n) = O(1)。表示无论n的规模如何增长,它的执行时间基本是不变的。
- 线性阶:O(n),T(n) = O(n)。代表数据量增大几倍,耗时也增长几倍。比如遍历。
- 平方阶:O(n2),T(n) = O(n2)。代表数据量增大n倍,耗时也增长n的平方倍。比如两层循环。
- 立方阶:O(n3),T(n) = O(n3)。代表数据量增大n倍,耗时也增长n的立方倍。比如三层循环。
- 对数阶:O(logn),T(n) = O(logn)。代表数据量增大n倍,耗时增大logn倍。比如二分查找,n以倍数的规模递减。
- 线性对数阶:O(nlogn),T(n) = O(nlogn)。代表数据量增大n倍,耗时增大nlogn倍。
- 指数阶:O(2n)。代表数据量增大n倍,耗时增大2n倍。
计算时间复杂度:
- 基本操作:即只有常数项,认为这个时间复杂度就是O(1)
- 顺序结构:时间复杂度按加法计算
- 循环结构:按乘法计算
- 分支结构:取最大值
只需取最高次项即可。
优劣:O(1)<O(logn)<O(n)<O(nlogn)<O(n2)<O(n3)<O(2n)
空间复杂度:指一个算法在执行过程中临时占用存储空间大小的度量。
S(n) = O(f(n))
通常来讲,只要算法不涉及到动态的空间,比如递归,栈,空间复杂度通常为O(1)。
算法的空间复杂度并不是实际占用的空间,而是计算整个算法的辅助空间单元(变量)的个数,与问题规模无关,主要看新开辟的变量个数。
动态规划
70. 爬楼梯
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
方法一:动态规划
我们用 f(x) 表示爬到第 x 级台阶的方案数,考虑最后一步可能跨了一级台阶,也可能跨了两级台阶,所以我们可以列出如下式子:
f(x) = f(x - 1) + f(x - 2)
它意味着爬到第 x 级台阶的方案数是爬到第 x - 1 级台阶的方案数和爬到第 x - 2 级台阶的方案数的和。很好理解,因为每次只能爬 1 级或 2 级,所以 f(x) 只能从 f(x−1) 和 f(x−2) 转移过来,而这里要统计方案总数,我们就需要对这两项的贡献求和。
以上是动态规划的转移方程,下面我们来讨论边界条件。我们是从第 0 级开始爬的,所以从第 0 级爬到第 0 级我们可以看作只有一种方案,即 f(0) = 1;从第 0 级到第 1 级也只有一种方案,即爬一级,f(1) = 1。这两个作为边界条件就可以继续向后推导出第 n 级的正确结果。我们不妨写几项来验证一下,根据转移方程得到 f(2) = 2,f(3) = 3,f(4) = 5,……,我们把这些情况都枚举出来,发现计算的结果是正确的。
我们不难通过转移方程和边界条件给出一个时间复杂度和空间复杂度都是 O(n) 的实现,但是由于这里的 f(x) 只和 f(x - 1) 与 f(x - 2) 有关,所以我们可以用「滚动数组思想」把空间复杂度优化成 O(1)。下面的代码中给出的就是这种实现。
var climbStairs = function(n) {let p = 0, q = 0, r = 1;for (let i = 1; i <= n; ++i) {p = q;q = r;r = p + q;}return r;};// 或者var climbStairs = function(n) {let dp = [];dp[0] = 0,dp[1] = 1,dp[2] = 2;for(let i = 3;i <= n;i++){dp[i] = dp[i-2] + dp[i-1];}return dp[n];};
198. 打家劫舍
你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
给定一个代表每个房屋存放金额的非负整数数组,计算你不触动警报装置的情况下 ,一夜之内能够偷窃到的最高金额。
该问题是非常典型的、入门的动态规划问题。很多算法书上的都采用类似的例子来开始介绍动态规划。
设计动态规划的三个步骤
- 将问题分解成最优子问题;
- 用递归的方式将问题表述成最优子问题的解;
- 自底向上的将递归转化成迭代;(递归是自顶向下)
最优子问题
对于连续的 n 栋房子:H1,H2,H3……Hn ,小偷挑选要偷的房子,且不能偷相邻的两栋房子,方案无非两种:
方案一:挑选的房子中包含最后一栋;
方案二:挑选的房子中不包含最后一栋;
获得的最大收益的最终方案,一定在这两种方案中产生,用代码表述就是:
最优结果 = Math.max(方案一最优结果,方案二最优结果)
子问题的递归表述
var robTo = function (nums, lastIndex) {if (lastIndex === 0) {return nums[0];}// 方案一,包含最后一栋房子,则应该丢弃倒数第二栋房子let sum1 = robTo(nums, lastIndex - 2) + nums[lastIndex];// 方案二,不包含最后一栋房子,那么方案二的结果就是到偷到 lastIndex-1 为止的最优结果let sum2 = robTo(nums, lastIndex - 1);return Math.max(sum1, sum2);};
将问题表述成最优子问题的解后,这个问题就解决了:
var rob = function(nums) {return robTo(nums, nums.length - 1);};
递归转迭代
到上一步为止,该问题就已经解决了。但是递归的方式性能太差,中间有太多重复的计算,所以还需要最后一步:将 自顶向下 的递归,转化成 自底向上 的迭代。
var rob = function(nums) {if (nums.length === 0) {return 0;}if (nums.length === 1) {return nums[0];}// 仍然用两个变量来存储方案一和方案二的最优结果// 不同的是,这次从0开始,lastIndex 取最小值 1let sum1 = nums[0];let sum2 = nums[1];// 然后通过迭代不断增大 lastIndex,过程中维护新的sum1,sum2,直到数组末尾for (let lastIndex=2; lastIndex<nums.length; lastIndex++) {let tmp = sum1;// 此时的方案一就是上一步中的方案二,// 但要求的是最优解,所以要判断前一步的 sum1 和 sum2 哪个更大if (sum2 > sum1) {sum1 = sum2;}// sum2 是包含最后一栋房子的方案,// 每向后增加一栋房子,就是前一步的 sum1(不包含 lastIndex - 1 )// 加上当前 lastIndex 栋房子的金钱sum2 = tmp + nums[lastIndex];}return sum1 > sum2 ? sum1 : sum2;};
再复杂的动态规划问题,都可以通过这三步来解决。难点在于第一步,即将问题分解成最优子问题。找到了最优子问题,问题就解决了一大半。第二步不过是将第一步的思路用递归代码表述出来;至于第三步递归转迭代,毕竟有递归的基本逻辑可以参考,多加练习可以较熟练的掌握。
221. 最大正方形
在一个由 '0' 和 '1' 组成的二维矩阵内,找到只包含 '1' 的最大正方形,并返回其面积。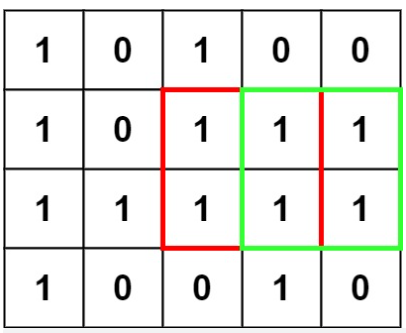
方法一:暴力法
由于正方形的面积等于边长的平方,因此要找到最大正方形的面积,首先需要找到最大正方形的边长,然后计算最大边长的平方即可。
暴力法是最简单直观的做法,具体做法如下:
遍历矩阵中的每个元素,每次遇到 1,则将该元素作为正方形的左上角;
确定正方形的左上角后,根据左上角所在的行和列计算可能的最大正方形的边长(正方形的范围不能超出矩阵的行数和列数),在该边长范围内寻找只包含 1 的最大正方形;
每次在下方新增一行以及在右方新增一列,判断新增的行和列是否满足所有元素都是 1。
var maximalSquare = function(matrix) {if(matrix.length == 0 || matrix[0].length == 0) return 0;let maxSide = 0, rows = matrix.length, columns = matrix[0].length;for(let i = 0; i < rows; i++) {for (let j = 0; j < columns; j++) {if(matrix[i][j] == '1') {//遇到一个1作为正方形左上角maxSide = Math.max(maxSide,1);//计算可能的最大正方形边长(取行列最小值)let currentMaxSide = Math.min(rows - i, columns - j);for(let k = 1; k < currentMaxSide; k++) {//判断新增的一行一列是否均为1let flag = true;if(matrix[i + k][j + k] == '0') break; //元素的对角for(let m = 0; m < k; m++) {if(matrix[i+k][j+m] == '0' || matrix[i + m][j+k] == '0') {flag = false;break;}}if(flag) {maxSide = Math.max(maxSide,k + 1)}else break;}}}}let maxSquare = maxSide * maxSide;return maxSquare};
方法二:动态规划
方法一虽然直观,但是时间复杂度太高,有没有办法降低时间复杂度呢?
可以使用动态规划降低时间复杂度。我们用 dp(i,j) 表示以 (i,j) 为右下角,且只包含 1 的正方形的边长最大值。如果我们能计算出所有 dp(i,j) 的值,那么其中的最大值即为矩阵中只包含 1 的正方形的边长最大值,其平方即为最大正方形的面积。
那么如何计算 dp 中的每个元素值呢?对于每个位置 (i,j),检查在矩阵中该位置的值:
- 如果该位置的值是 0,则 dp(i,j)=0,因为当前位置不可能在由 1 组成的正方形中;
- 如果该位置的值是 1,则 dp(i,j) 的值由其上方、左方和左上方的三个相邻位置的 dp 值决定。具体而言,当前位置的元素值等于三个相邻位置的元素中的最小值加 1,状态转移方程如下:
dp(i,j)=min(dp(i−1,j),dp(i−1,j−1),dp(i,j−1))+1
此外,还需要考虑边界条件。如果 i 和 j 中至少有一个为 0,则以位置 (i,j) 为右下角的最大正方形的边长只能是 1,因此dp(i,j)=1。
以下用一个例子具体说明。原始矩阵如下。
0 1 1 1 0
1 1 1 1 0
0 1 1 1 1
0 1 1 1 1
0 0 1 1 1
对应的 dp 值如下。
0 1 1 1 0
1 1 2 2 0
0 1 2 3 1
0 1 2 3 2
0 0 1 2 3
var maximalSquare = function (matrix) {if (matrix.length == 0 || matrix[0].length == 0) return 0;let maxSide = 0, rows = matrix.length, columns = matrix[0].length;let dp = new Array(rows).fill(0).map(() => new Array(columns).fill(0));for(let i = 0; i < rows; i++) {for(let j = 0; j < columns; j++) {if(matrix[i][j] == '0') continue;dp[i][j] = Math.min(dp[i - 1]?.[j] || 0,dp[i][j - 1] || 0,dp[i - 1]?.[j - 1] || 0) + 1;maxSide = Math.max(maxSide,dp[i][j]);}}return maxSide*maxSide}
322. 零钱兑换
给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。
计算并返回可以凑成总金额所需的最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。
你可以认为每种硬币的数量是无限的
我们采用自下而上的方式进行思考。仍定义F(i) 为组成金额 i 所需最少的硬币数量,假设在计算 F(i) 之前,我们已经计算出 F(0) − F(i−1) 的答案。 则 F(i) 对应的转移方程应为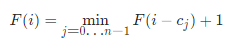
其中 cj代表的是第 j 枚硬币的面值,即我们枚举最后一枚硬币面额是i-cj这个金额的状态 F(i-cj) 转移过来,再算上枚举的这枚硬币数量 1 的贡献,由于要硬币数量最少,所以F(i) 为前面能转移过来的状态的最小值加上枚举的硬币数量 1 。
例子1:假设
coins = [1, 2, 5], amount = 11
则,当 i==0 时无法用硬币组成,为 0 。当 i<0 时,忽略 F(i)
F(i) 最小硬币数量
F(0) 0 //金额为0不能由硬币组成
F(1) 1 //F(1)=min(F(1-1),F(1-2),F(1-5))+1=1
F(2) 1 //F(2)=min(F(2-1),F(2-2),F(2-5))+1=1
F(3) 2 //F(3)=min(F(3-1),F(3-2),F(3-5))+1=2
F(4) 2 //F(4)=min(F(4-1),F(4-2),F(4-5))+1=2
… …
F(11) 3 //F(11)=min(F(11-1),F(11-2),F(11-5))+1=3
我们可以看到问题的答案是通过子问题的最优解得到的。
const coinChange = (coins, amount) => {let dp = new Array(amount + 1).fill(Infinity)dp[0] = 0for (let coin of coins) {for (let i = coin; i <= amount; i++) {dp[i] = Math.min(dp[i], dp[i - coin] + 1)}}return dp[amount] === Infinity ? -1 : dp[amount]}
62. 不同路径

一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。
问总共有多少条不同的路径?
方法:动态规划。
思路:假设走到(i,j)的路径数量为f(i,j),其中i和j的范围分别是[0,m-1],[0,n-1]。
由于一次只能往右或下走一步,所以要走到(i,j),要么从(i-1,j)往下,要么从(j,j-1)往右,所以可以写出动态规划转移方程:f(i,j) = f(i-1,j) + f(i,j-1)。(画格子一步一步推算)
注意:如果i=0或j=0,并不是满足要求的状态,为了方便代码编写,我们将所有的f(0,j)和f(i,0)都设置为边界条件,值均为1,因为走到那些格子只有一条路径。
初始条件f(0,0)=1,最终答案即为f(m-1,n-1)。
var uniquePaths = function(m, n) {const f = new Array(m).fill(0).map(() => new Array(n).fill(0));for(let i = 0; i < m; i++) {f[i][0] = 1;}for(let j = 0; j < n; j++) {f[0][j] = 1;}for(let i = 1; i < m; i++) {for(let j = 1; j<n; j++) {f[i][j] = f[i-1][j] + f[i][j-1];}}return f[m-1][n-1]};
// 66.斐波那契数列function fibonacci(n) {if (n <= 2) return 1;return fibonacci(n-2) + fibonacci(n-1)}// 67.跳台阶// 一只青蛙一次可以跳上1级台阶,也可以跳上2级。求该青蛙跳上一个 n 级的台阶总共有多少种跳法(先后次序不同算不同的结果)。// 试几个例子发现这是斐波那契数列// 简单的动态规划问题:把大的问题拆分成多个小的问题// 首先明确返回能确定的条件:// 1. number为1时只有一种方案// 2. number为2时有两种方案,分别为:练跳两个一阶、一次跳一个两阶// 3. number为3时,可以返回为 jump(1) + jump(2)// function jump(number) {// if (number == 1) return 1// if (number == 2) return 2// return jump(number - 1) + jump(number - 2)// }function jumpFloor(n) {const results = [];results[1] = 1;results[2] = 2;if(number>2){for(var i=3;i<=number;i++){results[i]=results[i-1]+results[i-2];}}return results[number];}
最长公共子序列(二)
题目主要信息:
- 找到两个字符串的最长公共子序列,子序列不要求位置在原串中连续
- 仅存在一个最长公共子序列,不需要去重
- 最长公共子序列为空需要返回”-1”,而不是空序列,最后要变换
方法一:动态规划+递归获取(推荐使用)
知识点:动态规划
动态规划算法的基本思想是:将待求解的问题分解成若干个相互联系的子问题,先求解子问题,然后从这些子问题的解得到原问题的解;对于重复出现的子问题,只在第一次遇到的时候对它进行求解,并把答案保存起来,让以后再次遇到时直接引用答案,不必重新求解。动态规划算法将问题的解决方案视为一系列决策的结果
思路:
题目要求获取最长公共子序列,我们肯定要先知道最长到底是多长,因此肯定要先求最长公共子序列的长度,然后根据这个长度获取这个子序列。(注意:子序列不是子串,子串要求所有字符必须连续,子序列不要求连续,只要求相对位置不变)
具体做法:
- step 1:优先检查特殊情况。
- step 2:获取最长公共子序列的长度可以使用动态规划,我们以dp[i][j]表示在s1中以i结尾,s2中以j结尾的字符串的最长公共子序列长度。
- step 3:遍历两个字符串的所有位置,开始状态转移:若是i位与j位的字符相等,则该问题可以变成1+dp[i−1][j−1],即到此处为止最长公共子序列长度由前面的结果加1。
- step 4:若是不相等,说明到此处为止的子串,最后一位不可能同时属于最长公共子序列,毕竟它们都不相同,因此我们考虑换成两个子问题,dp[i][j−1]或者dp[i−1][j],我们取较大的一个就可以了,由此感觉可以用递归解决。
- step 5:但是递归的复杂度过高,重复计算了很多低层次的部分,因此可以用动态规划,从前往后加,由此形成一个表,表从位置1开始往后相加,正好符合动态规划的转移特征。
- step 6:因为最后要返回该序列,而不是长度,所以在构造表的同时要以另一个二维矩阵记录上面状态转移时选择的方向,我们用1表示来自左上方,2表示来自左边,3表示来自上边。
- step 7:获取这个序列的时候,根据从最后一位开始,根据记录的方向,不断递归往前组装字符,只有来自左上的时候才添加本级字符,因为这种情况是动态规划中两个字符相等的情况,字符相等才可用。
图示:
function LCS( s1 , s2 ) {// write code here// 动态规划// 状态:f[i][j]表示以text1第i个结尾text2第j个结尾的的公共子串;// 状态转移方程: 当text1[i] === text2[j]时:f[i][j] = f[i-1][j-1] + text[i];// 当text1[i] !=== text2[j]时;f[i][j] = max{dp[i-1][j], dp[i][j-1]};const l1 = s1.length;const l2 = s2.length;const dp = new Array(l1).fill(0).map(() => new Array(l2).fill(''));let max = '';for (let i=0; i<l1; i++) {for (let j=0; j<l2; j++) {if (s1[i] === s2[j]) {dp[i][j] = (i===0 || j===0) ? s1[i]: dp[i-1][j-1]+ s1[i];} else {const tempS1 = i===0 ? '' : dp[i-1][j];const tempS2 = j===0 ? '' : dp[i][j-1];if (i===1) tempS1dp[i][j] = tempS1.length > tempS2.length ? tempS1 : tempS2;}max = dp[i][j].length > max.length ? dp[i][j] : max}}return max.length ? max : -1;}
最长公共子串
给定两个字符串str1和str2,输出两个字符串的最长公共子串
题目保证str1和str2的最长公共子串存在且唯一。
具体做法:
- step 1:我们可以用dp[i][j]表示在str1中以第i个字符结尾在str2中以第j个字符结尾时的公共子串长度,
- step 2:遍历两个字符串填充dp数组,转移方程为:如果遍历到的该位两个字符相等,则此时长度等于两个前一位长度+1,dp[i][j]=dp[i−1][j−1]+1,如果遍历到该位时两个字符不相等,则置为0,因为这是子串,必须连续相等,断开要重新开始。
- step 3:每次更新dp[i][j]后,我们维护最大值,并更新该子串结束位置。
- step 4:最后根据最大值结束位置即可截取出子串。
function LCS( str1 , str2 ) {let dp = new Array(str1.length+1).fill(0).map(() => new Array(str2.length+1).fill(0));let max = 0;const map = new Map()for(let i = 1;i<=str1.length;i++){for(let j = 1;j<=str2.length;j++){if(str1[i-1] === str2[j-1]){dp[i][j] = dp[i - 1][j - 1] + 1max = Math.max(max,dp[i][j])if(!map.has(max)) map.set(max,i) //避免重复}}}let startIndex = map.get(max) - max;let endIndex = map.get(max) ;return str1.substring(startIndex,endIndex) //截取字符串}
不同路径的数目(一)
一个机器人在m×n大小的地图的左上角(起点)。
机器人每次可以向下或向右移动。机器人要到达地图的右下角(终点)。
可以有多少种不同的路径从起点走到终点?
假设机器人站在点(i,j)处,其可以从(i-1,j)向下移动一行走到,也可以从(i,j-1)向右移动一步走到。因此到达位置(i,j)出路径的数目等于到达位置(i-1,j)的路径数目 与达到(i,j-1)的路径数目之和。我们假设dp[i,j]表示到达点(i,j)的路径数目,那么dp[i,j] = dp[i-1,j]+dp[i,j-1]。我们新建一个二维表格dp,计算dp里面每一个值,最后返回目标位置的dp即可。
初始化,第一行和第一列的dp值全部为1,这些位置可以确定只有一条路径。表格的其他位置,根据转移方程,进行填充即可。
function uniquePaths(m, n) {let dp = new Array(4).fill(0).map(() => {return new Array(5).fill('')})// 第一行初始化,只有一条路径for (let i = 0; i < 5; i++) {dp[0][i] = 1}// 第一列初始化,只有一条路径for (let i = 0; i < 4; i++) {dp[i][0] = 1}for (let i = 1; i < m; i++) {for (let j = 1; j < n; j++) {dp[i][j] = dp[i-1][j] + dp[i][j-1]}}return dp[m-1][n-1]}
矩阵的最小路径和
给定一个 n * m 的矩阵 a,从左上角开始每次只能向右或者向下走,最后到达右下角的位置,路径上所有的数字累加起来就是路径和,输出所有的路径中最小的路径和。
function minPathSum( matrix ) {const n = matrix.length, m = matrix[0].length;// dp[i][j] = dp[i-1][j] + dp[i][j-1]let dp = new Array(n).fill(0).map(() => { return new Array(m).fill('')} )dp[0][0] = matrix[0][0]for (let i = 1; i < m; i++) {dp[0][i] = dp[0][i-1] + matrix[0][i]}for (let i = 1; i < n; i++) {dp[i][0] = dp[i-1][0] + matrix[i][0]}for (let i = 1; i < n; i++) {for (let j = 1; j < m; j++) {dp[i][j] = matrix[i][j] + Math.min(dp[i-1][j],dp[i][j-1])}}return dp[n-1][m-1]}
把数字翻译成字符串
思路:
对于普通数组1-9,译码方式只有一种,但是对于11-19,21-26,译码方式有可选择的两种方案,因此我们使用动态规划将两种方案累计。
具体做法:
- step 1:用辅助数组dp表示前i个数的译码方法有多少种。
- step 2:对于一个数,我们可以直接译码它,也可以将其与前面的1或者2组合起来译码:如果直接译码,则dp[i]=dp[i−1];如果组合译码,则dp[i]=dp[i−2]。
- step 3:对于只有一种译码方式的,选上种dp[i−1]即可,对于满足两种译码方式(10,20不能)则是dp[i−1]+dp[i−2]
step 4:依次相加,最后的dp[length]即为所求答案。
function solve( nums ) {// write code herelet len = nums.length;let dp = new Array(len);//dp[i]表示在 当前i位置上有多少种译码的可能。dp[0] = 1;for(let i = 1;i<len;i++){let twoN = parseInt(nums.slice(i-1,i+1));if(i === len - 1 && nums[i] == 0 && twoN > 26){dp[i] = 0;}else if(nums[i] == 0 || twoN > 26 || nums[i-1] == 0){dp[i] = dp[i-1];}else{dp[i] = i>= 2 ? dp[i-1] + dp[i-2] : dp[i-1] + 1;}}return dp[len - 1];}
兑换零钱(一)
给定数组arr,arr中所有的值都为正整数且不重复。每个值代表一种面值的货币,每种面值的货币可以使用任意张,再给定一个aim,代表要找的钱数,求组成aim的最少货币数。
如果无解,请返回-1。
思路:
这类涉及状态转移的题目,可以考虑动态规划。
具体做法:step 1:可以用dp[i]表示要凑出i元钱需要最小的货币数。
- step 2:一开始都设置为最大值aim+1,因此货币最小1元,即货币数不会超过aim.
- step 3:初始化dp[0]=0。
- step 4:后续遍历1元到aim元,枚举每种面值的货币都可能组成的情况,取每次的最小值即可,转移方程为dp[i]=min(dp[i],dp[i−arr[j]]+1).
- step 5:最后比较dp[aim]的值是否超过aim,如果超过说明无解,否则返回即可。
贪心
剑指 Offer 14- I. 剪绳子
给你一根长度为 n 的绳子,请把绳子剪成整数长度的 m 段(m、n都是整数,n>1并且m>1),每段绳子的长度记为 k[0],k[1]…k[m-1] 。请问 k[0]k[1]…k[m-1] 可能的最大乘积是多少?例如,当绳子的长度是8时,我们把它剪成长度分别为2、3、3的三段,此时得到的最大乘积是18。
方法一:动态规划
我们想要求长度为n的绳子剪掉后的最大乘积,可以从前面比n小的绳子转移而来
用一个dp数组记录从0到n长度的绳子剪掉后的最大乘积,也就是dp[i]表示长度为i的绳子剪成m段后的最大乘积,初始化dp[2] = 1
我们先把绳子剪掉第一段(长度为j),如果只剪掉长度为1,对最后的乘积无任何增益,所以从长度为2开始剪
剪了第一段后,剩下(i - j)长度可以剪也可以不剪。如果不剪的话长度乘积即为j (i - j);如果剪的话长度乘积即为j dp[i - j]。取两者最大值max(j (i - j), j dp[i - j])
第一段长度j可以取的区间为[2,i),*对所有j不同的情况取最大值,因此最终dp[i]的转移方程为
dp[i] = max(dp[i], max(j (i - j), j dp[i - j]))
最后返回dp[n]即可
let cuttingRope = function(n) {let dp = new Array(n + 1).fill(0);dp[2] = 1;//如果只剪掉长度为1,对最后结果无增益,所以长度为2开始剪for(let i = 2; i <= n; i++) {for(let j = 1; j < i; j++) {//剪了第一段后,剩下i-j长度可以剪或不剪;不剪长度乘积为j*(i-j);如果剪的话长度乘积即为j * dp[i - j]。取两者最大值let bigger = Math.max(j * (i-j), j * dp[i - j]);//对于同一个i,内层循环对不同的j都还会拿到一个max,所以每次内循环都要更新maxdp[i] = Math.max(dp[i],bigger);}}return dp[n];}
方法二:贪心算法
核心思路是:尽可能把绳子分成 长度为3的小段,这样乘积最大。
步骤如下:
如果 n === 4,返回4
如果 n > 4,分成尽可能多的长度为3的小段,每次循环长度n减去3,乘积res乘以3;最后返回时乘以小于等于4的最后一小段
var cuttingRope = function(n) {if(n < 4) return n - 1;let result = 1;while(n > 4) {result *= 3;n -=3;}return result * n;};
55. 跳跃游戏
给定一个非负整数数组 nums ,你最初位于数组的 第一个下标 。
数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个下标。
方法:贪心
设想一下对于数组中的任意一个位置y,我们如何判断他是否可以到达,根据题目描述,只要存在一个位置x,它本身可以到达,并且它跳跃的最大长度为x+nums[x],这个值大于等于y,那么y也可以到达。我们可以遍历数组中的每一个位置,并实时维护最远可以到达的位置。对于当前遍历到的位置x,如果他在最远可以已到达的范围内,那么我们就可以从起点通过若干次跳跃到达该位置,因此我们可以用x+nums[x]更新最远可以到达的位置。在遍历的过程中,如果最远可以到达的位置大于等于数组中的最后一个位置,那就说明最后一个位置可达,我们就可以直接返回 True 作为答案。反之,如果在遍历结束后,最后一个位置仍然不可达,我们就返回 False 作为答案。
//1. 使用一个变量保存当前可到达的最大位置//2. 时刻更新最大位置//3. 可达位置大于数组长度返回truelet canJump = function(nums) {let n = nums.length;let rightmost = 0;for(let i = 0; i < n; i++) {// 如果i比rightMost大说明中间有位置到不了了if(i <= rightmost) { //可以到达的位置rightmost = Math.max(rightmost, i + nums[i]);if(rightmost >= n-1) {return true;}}}return false;}
134. 加油站
在一条环路上有 n 个加油站,其中第 i 个加油站有汽油 gas[i] 升。
你有一辆油箱容量无限的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。
给定两个整数数组 gas 和 cost ,如果你可以绕环路行驶一周,则返回出发时加油站的编号,否则返回 -1 。如果存在解,则保证它是唯一的。
思路:首先判断总油量是否小于总油耗,如果是则肯定不能走一圈。如果否,那肯定能跑一圈。接下来就是循环数组,从第一个站开始,计算每一站剩余的油量,如果油量为负了,就以这个站为起点重新计算。如果到达某一个点为负,说明起点到这个点中间的所有站点都不能到达该点,因为到中间的每个站的油量肯定大于等于0,从中间某站开始的话油量初始为0。
let canCompleteCircuit = function(gas,cost) {let totalGas = 0;let totalCost = 0;for(let i = 0; i < gas.length; i++) {totalCost += cost[i];totalGas += gas[i];}if(totalGas < totalCost) { return -1};let currentGas = 0;let start = 0;for(let i = 0; i < gas.length; i++) {currentGas = currentGas - cost[i] + gas[i];//如果到达下一站的时候油量为负数 就以这个站为起点 重新计算if(currentGas < 0) {currentGas = 0;start = i + 1;}}return start;}
二分查找
704. 二分查找
给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。
输入: nums = [-1,0,3,5,9,12], target = 9输出: 4解释: 9 出现在 nums 中并且下标为 4
答案:
// (版本一)左闭右闭区间var search = function(nums, target) {let l = 0, r = nums.length - 1;while(l <= r) {let mid = Math.floor(l + (r - l) / 2);if(nums[mid] == target) return mid;if(nums[mid] > target) r = mid - 1;if(nums[mid] < target) l = mid + 1}return -1};// (版本二)左闭右开区间 用l<r的话,r为nums.length,然后就要更新为mid,因为右开区间取不到midvar search = function(nums, target) {let l = 0, r = nums.length;// 区间 [l, r)while(l < r) {let mid = (l + r) >> 1;if(nums[mid] === target) return mid;let isSmall = nums[mid] < target;l = isSmall ? mid + 1 : l;// 所以 mid 不会被取到r = isSmall ? r : mid;}return -1;};
278. 第一个错误的版本
你是产品经理,目前正在带领一个团队开发新的产品。不幸的是,你的产品的最新版本没有通过质量检测。由于每个版本都是基于之前的版本开发的,所以错误的版本之后的所有版本都是错的。
假设你有 n 个版本 [1, 2, …, n],你想找出导致之后所有版本出错的第一个错误的版本。
你可以通过调用 bool isBadVersion(version) 接口来判断版本号 version 是否在单元测试中出错。实现一个函数来查找第一个错误的版本。你应该尽量减少对调用 API 的次数。
var solution = function(isBadVersion) {/*** @param {integer} n Total versions* @return {integer} The first bad version*/return function(n) {let left = 1, right = n;while (left < right) { // 循环直至区间左右端点相同const mid = Math.floor(left + (right - left) / 2); // 防止计算时溢出if (isBadVersion(mid)) {right = mid; // 答案在区间 [left, mid] 中} else {left = mid + 1; // 答案在区间 [mid+1, right] 中}}// 此时有 left == right,区间缩为一个点,即为答案return left;};};
35. 搜索插入位置
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
请必须使用时间复杂度为 O(log n) 的算法。
var searchInsert = function(nums, target) {let l = 0,r = nums.length - 1while(l<=r) {let mid = (l+r) >> 1;if(target>nums[mid]){l = mid + 1;} else{r = mid -1;}}return l};
剑指 Offer II 006. 排序数组中两个数字之和
给定一个已按照 升序排列 的整数数组 numbers ,请你从数组中找出两个数满足相加之和等于目标数 target 。
函数应该以长度为 2 的整数数组的形式返回这两个数的下标值。numbers 的下标 从 0 开始计数 ,所以答案数组应当满足 0 <= answer[0] < answer[1] < numbers.length 。
假设数组中存在且只存在一对符合条件的数字,同时一个数字不能使用两次。
var twoSum1 = function(numbers, target) {//从数组第一个元素开始,用二分查找函数判断后面的元素是否为target-numbers[i]for (let i = 0; i < numbers.length; i++) {const x = numbers[i]const index = binarySearch(numbers, i + 1, numbers.length - 1, target - x)if (index != -1) {return [i, index]}}return []};//定义二分查找的函数var binarySearch = function(number, left, right, target) {while (left <= right) {const mid = left + Math.floor((right - left) / 2)if (target == number[mid]) {return mid;} else if (target < number[mid]) {right = mid - 1} else {left = mid + 1}}return -1}
剑指 Offer II 069. 山峰数组的顶部
符合下列属性的数组 arr 称为 山峰数组(山脉数组) :
arr.length >= 3
存在 i(0 < i < arr.length - 1)使得:
arr[0] < arr[1] < … arr[i-1] < arr[i]
arr[i] > arr[i+1] > … > arr[arr.length - 1]
给定由整数组成的山峰数组 arr ,返回任何满足 arr[0] < arr[1] < … arr[i - 1] < arr[i] > arr[i + 1] > … > arr[arr.length - 1] 的下标 i ,即山峰顶部。
var peakIndexInMountainArray = function(arr) {let l = 0,r = arr.length - 1,ans = Math.max(...arr)while(l <= r) {let mid = (l + r) >> 1;if(arr[mid]==ans) return mid;if(arr[mid] < arr[mid+1]) {l = mid + 1} else {r = mid - 1}}return -1}
也可以用遍历的方法:
var peakIndexInMountainArray = function(arr) {for(let i = 0; i < arr.length; i++) {if(arr[i] > arr[i+1]) {return i}}};
374. 猜数字大小
猜数字游戏的规则如下:
每轮游戏,我都会从 1 到 n 随机选择一个数字。 请你猜选出的是哪个数字。
如果你猜错了,我会告诉你,你猜测的数字比我选出的数字是大了还是小了。
你可以通过调用一个预先定义好的接口 int guess(int num) 来获取猜测结果,返回值一共有 3 种可能的情况(-1,1 或 0):
-1:我选出的数字比你猜的数字小 pick < num
1:我选出的数字比你猜的数字大 pick > num
0:我选出的数字和你猜的数字一样。恭喜!你猜对了!pick == num
返回我选出的数字。
var guessNumber = function(n) {let l = 1, r = n;while(l <= r) {let mid = Math.floor((l + r)/2);if(guess(mid) === 0) {return mid;} else if (guess(mid) === 1){l = mid + 1;} else {r = mid - 1}}};
69. x 的平方根
给你一个非负整数x,计算并返回x的平方根 。
由于返回类型是整数,结果只保留整数部分 ,小数部分将被舍去 。
注意:不允许使用任何内置指数函数和算符,例如 pow(x, 0.5) 或者 x ** 0.5 。
var mySqrt = function(x) {let l = 1, r= x;while(l<=r) {let mid = Math.floor((l+r)/2);if(mid*mid == x) return mid;if(mid*mid > x) {r = mid - 1} else {l = mid + 1}}return l - 1};
剑指 Offer 11. 旋转数组的最小数字
把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。
给你一个可能存在 重复 元素值的数组 numbers ,它原来是一个升序排列的数组,并按上述情形进行了一次旋转。请返回旋转数组的最小元素。例如,数组 [3,4,5,1,2] 为 [1,2,3,4,5] 的一次旋转,该数组的最小值为 1。
var minArray = function(numbers) {let left = 0, right = numbers.length-1;while(left < right) {let mid = Math.floor((left+right)/2);if(numbers[mid] === numbers[right]) {//因为有可能有重复数字,来缩小范围right--}else if(numbers[mid] < numbers[right]) {//mid有可能是最小值right = mid} else {left = mid + 1;}}return numbers[left]};
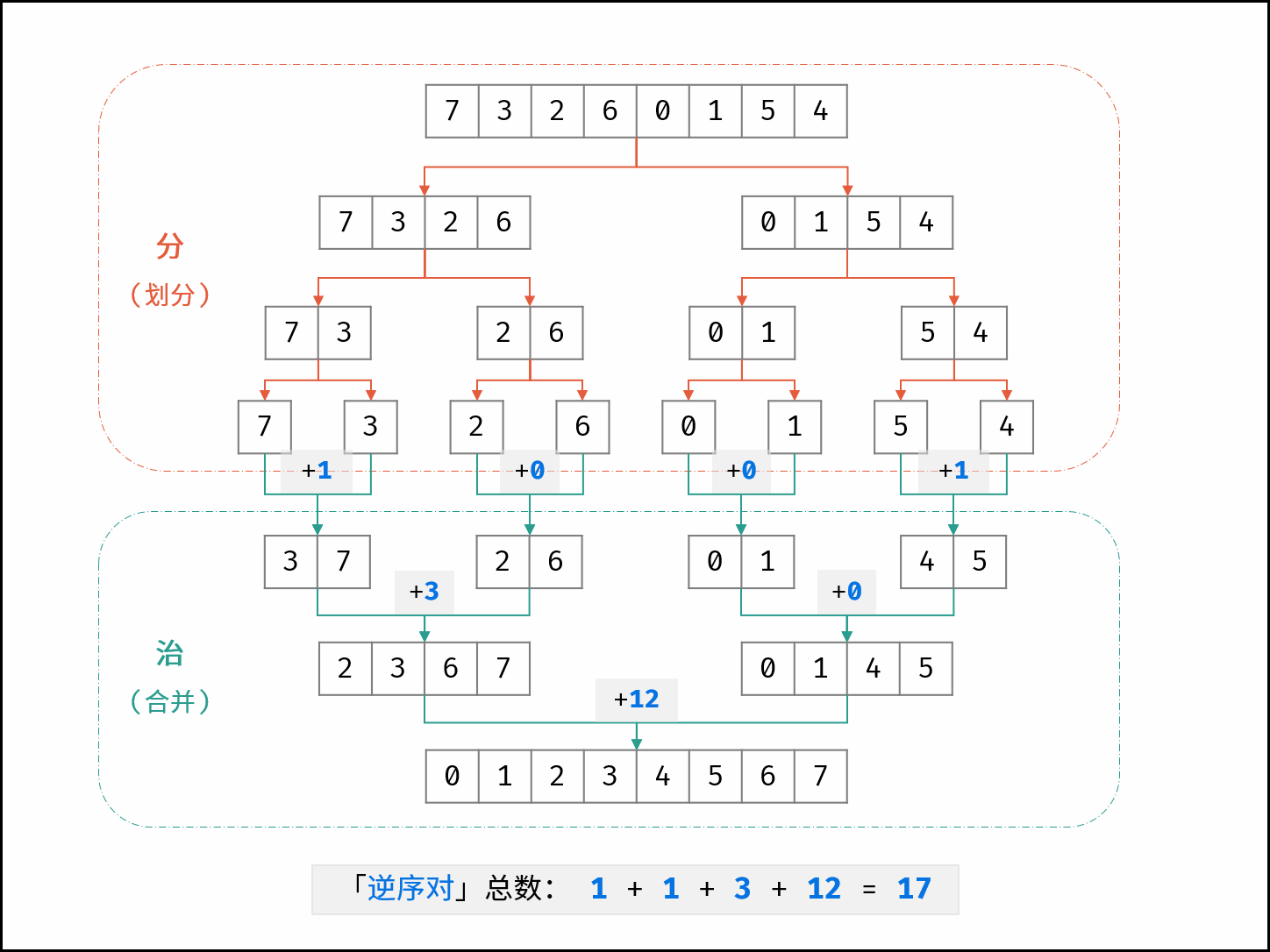
剑指 Offer 51. 数组中的逆序对
在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。输入一个数组,求出这个数组中的逆序对的总数。
「归并排序」与「逆序对」是息息相关的。归并排序体现了 “分而治之” 的算法思想,具体为:
- 分: 不断将数组从中点位置划分开(即二分法),将整个数组的排序问题转化为子数组的排序问题;
- 治: 划分到子数组长度为 1 时,开始向上合并,不断将 较短排序数组 合并为 较长排序数组,直至合并至原数组时完成排序;
合并阶段 本质上是 合并两个排序数组 的过程,而每当遇到 左子数组当前元素 > 右子数组当前元素 时,意味着 「左子数组当前元素 至 末尾元素」 与 「右子数组当前元素」 构成了若干 「逆序对」 。
如下图所示,为数组 [7,3,2,6,0,1,5,4] 的归并排序与逆序对统计过程。
var reversePairs = function (nums) {let count = 0;// 如果数组中只有1个元素或者为空,则不存在逆序对if (nums.length < 2) return count;const mergeSort = (front, behind) => {// 如果前后指针相遇,则归并区间只剩下一个元素了if (front == behind) return [nums[front]];let mid = front + ((behind - front) >> 1);// 规则让左半部分不包含中心元素 右半部分包含中心元素let left = mergeSort(front, mid);let right = mergeSort(mid + 1, behind);let temp = new Array(behind - front + 1).fill(0);// 合并有三个指针let cur = 0,l = 0,r = 0;while (l < left.length && r < right.length) {// 如果右边元素大于左边元素,将左边元素放到结果数组中if (right[r] >= left[l]) temp[cur++] = left[l++];else {temp[cur++] = right[r++];// 如果左边元素大于右边元素,那就出现了序列对了// 由于左右两边都是有序的,左边当前元素及之后的元素都会跟右边构建逆序对count += left.length - l;}}while (l < left.length) temp[cur++] = left[l++];while (r < right.length) temp[cur++] = right[r++];return temp;};// 左闭右闭区间mergeSort(0, nums.length - 1);return count;};
回溯
什么是回溯法
回溯法也可以叫做回溯搜索法,它是一种搜索的方式。
回溯是递归的副产品,只要有递归就会有回溯。
所以以下讲解中,回溯函数也就是递归函数,指的都是一个函数。
回溯法的效率
回溯法的性能如何呢,这里要和大家说清楚了,虽然回溯法很难,很不好理解,但是回溯法并不是什么高效的算法。
因为回溯的本质是穷举,穷举所有可能,然后选出我们想要的答案,如果想让回溯法高效一些,可以加一些剪枝的操作,但也改不了回溯法就是穷举的本质。
那么既然回溯法并不高效为什么还要用它呢?
因为没得选,一些问题能暴力搜出来就不错了,撑死了再剪枝一下,还没有更高效的解法。
此时大家应该好奇了,都什么问题,这么牛逼,只能暴力搜索。
回溯法解决的问题
回溯法,一般可以解决如下几种问题:
- 组合问题:N个数里面按一定规则找出k个数的集合
- 切割问题:一个字符串按一定规则有几种切割方式
- 子集问题:一个N个数的集合里有多少符合条件的子集
- 排列问题:N个数按一定规则全排列,有几种排列方式
- 棋盘问题:N皇后,解数独等等
相信大家看着这些之后会发现,每个问题,都不简单!
另外,会有一些同学可能分不清什么是组合,什么是排列?
组合是不强调元素顺序的,排列是强调元素顺序。
例如:{1, 2} 和 {2, 1} 在组合上,就是一个集合,因为不强调顺序,而要是排列的话,{1, 2} 和 {2, 1} 就是两个集合了。
记住组合无序,排列有序,就可以了。
如何理解回溯法
回溯法解决的问题都可以抽象为树形结构,是的,我指的是所有回溯法的问题都可以抽象为树形结构!
因为回溯法解决的都是在集合中递归查找子集,集合的大小就构成了树的宽度,递归的深度,都构成的树的深度。
递归就要有终止条件,所以必然是一棵高度有限的树(N叉树)。
这块可能初学者还不太理解,后面的回溯算法解决的所有题目中,我都会强调这一点并画图举相应的例子,现在有一个印象就行。
回溯法模板
- 回溯函数模板返回值以及参数
在回溯算法中,我的习惯是函数起名字为backtracking,这个起名大家随意。
回溯算法中函数返回值一般为void。
再来看一下参数,因为回溯算法需要的参数可不像二叉树递归的时候那么容易一次性确定下来,所以一般是先写逻辑,然后需要什么参数,就填什么参数。
但后面的回溯题目的讲解中,为了方便大家理解,我在一开始就帮大家把参数确定下来。
回溯函数伪代码如下:
void backtracking(参数)
- 回溯函数终止条件
什么时候达到了终止条件,树中就可以看出,一般来说搜到叶子节点了,也就找到了满足条件的一条答案,把这个答案存放起来,并结束本层递归。
所以回溯函数终止条件伪代码如下:
if (终止条件) { 存放结果; return; }
- 回溯搜索的遍历过程
在上面我们提到了,回溯法一般是在集合中递归搜索,集合的大小构成了树的宽度,递归的深度构成的树的深度。
如图:

注意图中,我特意举例集合大小和孩子的数量是相等的!
回溯函数遍历过程伪代码如下:
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) { 处理节点; backtracking(路径,选择列表); // 递归 回溯,撤销处理结果 }
for循环就是遍历集合区间,可以理解一个节点有多少个孩子,这个for循环就执行多少次。
backtracking这里自己调用自己,实现递归。
大家可以从图中看出for循环可以理解是横向遍历,backtracking(递归)就是纵向遍历,这样就把这棵树全遍历完了,一般来说,搜索叶子节点就是找的其中一个结果了。
分析完过程,回溯算法模板框架如下:
void backtracking(参数) { if (终止条件) { 存放结果; return; } for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) { 处理节点; backtracking(路径,选择列表); // 递归 回溯,撤销处理结果 } }
这份模板很重要,后面做回溯法的题目都靠它了!
如果从来没有学过回溯算法的录友们,看到这里会有点懵,后面开始讲解具体题目的时候就会好一些了,已经做过回溯法题目的录友,看到这里应该会感同身受了。
78. 子集
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
如果把 子集问题、组合问题、分割问题都抽象为一棵树的话,那么组合问题和分割问题都是收集树的叶子节点,而子集问题是找树的所有节点!
其实子集也是一种组合问题,因为它的集合是无序的,子集{1,2} 和 子集{2,1}是一样的。
那么既然是无序,取过的元素不会重复取,写回溯算法的时候,for就要从startIndex开始,而不是从0开始!
有同学问了,什么时候for可以从0开始呢?
求排列问题的时候,就要从0开始,因为集合是有序的,{1, 2} 和{2, 1}是两个集合,排列问题我们后续的文章就会讲到的。
以示例中nums = [1,2,3]为例把求子集抽象为树型结构,如下:

从图中红线部分,可以看出遍历这个树的时候,把所有节点都记录下来,就是要求的子集集合。
回溯三部曲
- 递归函数参数
全局变量数组path为子集收集元素,二维数组result存放子集组合。
递归函数参数在上面讲到了,需要startIndex。
递归终止条件
从图中可以看出:

剩余集合为空的时候,就是叶子节点。
那么什么时候剩余集合为空呢?
就是startIndex已经大于数组的长度了,就终止了,因为没有元素可取了,代码如下:
if (startIndex >= nums.size()) {return;}
其实可以不需要加终止条件,因为startIndex >= nums.size(),本层for循环本来也结束了。
- 单层搜索逻辑
求取子集问题,不需要任何剪枝!因为子集就是要遍历整棵树。
代码如下
var subsets = function (nums) {let res = [];const backtrack = (index, path) => {// 把当前路径加入结果r中res.push(path.slice()); //用slice是返回新数组for (let i = index; i < nums.length; i++) {// 选择这个数path.push(nums[i]);// 基于选这个数,继续递归,传入的是i+1,不是index+1backtrack(i + 1, path);// 撤销选这个数path.pop();}};backtrack(0, []);return res;};
46. 全排列
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案
方法一:回溯

思路和算法
回溯三部曲
- 递归函数参数
首先排列是有序的,也就是说 [1,2] 和 [2,1] 是两个集合,这和之前分析的子集以及组合所不同的地方。
可以看出元素1在[1,2]中已经使用过了,但是在[2,1]中还要再使用一次1,所以处理排列问题就不用使用startIndex了。
但排列问题需要一个used数组,标记已经选择的元素,如图橘黄色部分所示:
- 递归终止条件
可以看出叶子节点,就是收割结果的地方。
那么什么时候,算是到达叶子节点呢?
当收集元素的数组path的大小达到和nums数组一样大的时候,说明找到了一个全排列,也表示到达了叶子节点。
- 单层搜索的逻辑
因为排列问题,每次都要从头开始搜索,例如元素1在[1,2]中已经使用过了,但是在[2,1]中还要再使用一次1。
而used数组,其实就是记录此时path里都有哪些元素使用了,一个排列里一个元素只能使用一次。
var permute = function(nums) {const res = [], path = [];backtracking(nums, nums.length, []);return res;function backtracking(n, k, used) {if(path.length === k) {res.push(Array.from(path));return;}for (let i = 0; i < k; i++ ) {if(used[i]) continue;path.push(n[i]);used[i] = true; // 同支backtracking(n, k, used);path.pop();used[i] = false;}}};
39. 组合总和
给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。
candidates 中的 同一个 数字可以 无限制重复被选取 。如果至少一个数字的被选数量不同,则两种组合是不同的。
对于给定的输入,保证和为 target 的不同组合数少于 150 个。

- 递归函数参数
这里依旧使用result存放结果集,path存放符合条件的结果。还要定义sum变量统计单一结果path里的总和,其实这个sum也可以不用,用target做相应减法也行,最后target为0就说明找到符合的结果。还需设置startindex来控制for循环的起始位置,对于组合问题,什么时候需要startindex呢,比如一个集合求组和,例如:77.组合,216.组合总和III。如果是多个集合取组合,各个集合之间相互不影响,那么就不用startIndex,例如:17.电话号码的字母组合。注意以上我只是说求组合的情况,如果是排列问题,又是另一套分析的套路。
- 递归终止条件
从叶子节点可以清晰看到,终止只有两种情况,sum大于target和sum等于target。sum等于target的时候,需要收集结果。
- 单层搜索的逻辑
单层for循环依旧是从startindex开始,搜索cndidates集合。
剪枝优化
对于sum已经大于target的情况,其实是依然进入了下一层递归,只是下一层递归结束判断的时候,会判断sum > target的话就返回。
其实如果已经知道下一层的sum会大于target,就没有必要进入下一层递归了。
那么可以在for循环的搜索范围上做做文章了。
对总集合排序之后,如果下一层的sum(就是本层的 sum + candidates[i])已经大于target,就可以结束本轮for循环的遍历。

var combinationSum = function(candidates, target) {const res = [], path = [];candidates.sort(); // 排序backtracking(0, 0);return res;function backtracking(j, sum) {if (sum > target) return;if (sum === target) {res.push(Array.from(path));return;}for(let i = j; i < candidates.length; i++ ) {const n = candidates[i];if(n > target - sum) continue;path.push(n);sum += n;backtracking(i, sum);path.pop();sum -= n;}}};
131. 分割回文串
给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是 回文串 。返回 s 所有可能的分割方案。
回文串 是正着读和反着读都一样的字符串。

- 递归函数参数
全局变量数组path存放切割后回文的子串,二维数组result存放结果集。 (这两个参数可以放到函数参数里)
本题递归函数参数还需要startIndex,因为切割过的地方,不能重复切割,和组合问题也是保持一致的。
- 递归函数终止条件
从树形结构的图中可以看出:切割线切到了字符串最后面,说明找到了一种切割方法,此时就是本层递归的终止终止条件。
那么在代码里什么是切割线呢?
在处理组合问题的时候,递归参数需要传入startIndex,表示下一轮递归遍历的起始位置,这个startIndex就是切割线。
- 单层搜索的逻辑
来看看在递归循环,中如何截取子串呢?
在for (int i = startIndex; i < s.size(); i++)循环中,我们 定义了起始位置startIndex,那么 [startIndex, i] 就是要截取的子串。
首先判断这个子串是不是回文,如果是回文,就加入在path中,path用来记录切割过的回文子串。注意切割过的位置,不能重复切割,所以,backtracking(s, i + 1); 传入下一层的起始位置为i + 1。
判断回文子串
最后我们看一下回文子串要如何判断了,判断一个字符串是否是回文。
可以使用双指针法,一个指针从前向后,一个指针从后先前,如果前后指针所指向的元素是相等的,就是回文字符串了。
const isPalindrome = (s, l, r) => {for (let i = l, j = r; i < j; i++, j--) {if(s[i] !== s[j]) return false;}return true;}var partition = function(s) {const res = [], path = [], len = s.length;backtracking(0);return res;function backtracking(i) {if(i >= len) {res.push(Array.from(path));return;}for(let j = i; j < len; j++) {if(!isPalindrome(s, i, j)) continue;path.push(s.substr(i, j - i + 1));backtracking(j + 1);path.pop();}}};
79. 单词搜索
给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
思路与算法
设函数check(i, j, k) 表示判断以网格的 (i, j) 位置出发,能否搜索到单词 word[k..],其中 word[k..] 表示字符串 word 从第 k 个字符开始的后缀子串。如果能搜索到,则返回 true,反之返回 false。函数 check(i,j,k) 的执行步骤如下:
- 如果 board[i][j] != s[k],当前字符不匹配,直接返回 false。
- 如果当前已经访问到字符串的末尾,且对应字符依然匹配,此时直接返回 true。
- 否则,遍历当前位置的所有相邻位置。如果从某个相邻位置出发,能够搜索到子串 word[k+1..],则返回 true,否则返回 false。
这样,我们对每一个位置 (i,j) 都调用函数 check(i,j,0) 进行检查:只要有一处返回 true,就说明网格中能够找到相应的单词,否则说明不能找到。
为了防止重复遍历相同的位置,需要额外维护一个与 board 等大的 visited 数组,用于标识每个位置是否被访问过。每次遍历相邻位置时,需要跳过已经被访问的位置。
var exist = function(board, word) {const h = board.length, w = board[0].length;const directions = [[0, 1], [0, -1], [1, 0], [-1, 0]];const visited = new Array(h);for (let i = 0; i < visited.length; ++i) {visited[i] = new Array(w).fill(false);}const check = (i, j, s, k) => {if (board[i][j] != s.charAt(k)) {return false;} else if (k == s.length - 1) {return true;}visited[i][j] = true;let result = false;for (const [dx, dy] of directions) {let newi = i + dx, newj = j + dy;if (newi >= 0 && newi < h && newj >= 0 && newj < w) {if (!visited[newi][newj]) {const flag = check(newi, newj, s, k + 1);if (flag) {result = true;break;}}}}visited[i][j] = false;return result;}for (let i = 0; i < h; i++) {for (let j = 0; j < w; j++) {const flag = check(i, j, word, 0);if (flag) {return true;}}}return false;};
链表
203. 移除链表元素
给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
思路:先声明一个虚拟的头节点,将其next指向head,然后遍历,再返回ret.next。
var removeElements = function(head, val) {const ret = new ListNode(0, head);let cur = ret;while(cur.next) {if(cur.next.val === val) {cur.next = cur.next.next;} else{cur = cur.next;}}return ret.next;};
206. 反转链表
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
好理解的双指针
- 定义两个指针: pre 和 cur ;pre 在前 cur 在后。
- 每次让 pre 的 next 指向 cur ,实现一次局部反转
- 局部反转完成之后,pre 和 cur 同时往前移动一个位置
- 循环上述过程,直至 pre 到达链表尾部
let reverseList = function(head) {//如果没有或者只有一个元素就返回自身if(!head || !head.next) return head;let temp = null, pre = null, cur = head;while(cur) {temp = cur.next;cur.next = pre;pre = cur;cur = temp;}return pre}
剑指 Offer 35. 复杂链表的复制
请实现 copyRandomList 函数,复制一个复杂链表。在复杂链表中,每个节点除了有一个 next 指针指向下一个节点,还有一个 random 指针指向链表中的任意节点或者 null。

思路:
方法:迭代 + 节点拆分
我们首先将该链表中每一个节点拆分为两个相连的节点,例如对于链表 A→B→C,我们可以将其拆分为 A→A′→B→B′→C→C′ 。对于任意一个原节点 S,其拷贝节点 S’即为其后继节点。这样,我们可以直接找到每一个拷贝节点 S’的随机指针应当指向的节点,即为其原节点 S 的随机指针指向的节点 T 的后继节点 T’ 。需要注意原节点的随机指针可能为空,我们需要特别判断这种情况。当我们完成了拷贝节点的随机指针的赋值,我们只需要将这个链表按照原节点与拷贝节点的种类进行拆分即可,只需要遍历一次。同样需要注意最后一个拷贝节点的后继节点为空,我们需要特别判断这种情况。

var copyRandomList = function(head) {if (head === null) {return null;}for (let node = head; node !== null; node = node.next.next) {const nodeNew = new Node(node.val, node.next, null); //创建s'节点node.next = nodeNew; //链接s和s'}for (let node = head; node !== null; node = node.next.next) {const nodeNew = node.next; //取得s’nodeNew.random = (node.random !== null) ? node.random.next : null; //取得node.random.next,也就是T’}const headNew = head.next;for (let node = head; node !== null; node = node.next) { //遍历所有节点const nodeNew = node.next; //cnode.next = node.next.next;nodeNew.next = (nodeNew.next !== null) ? nodeNew.next.next : null;}return headNew;};
21. 合并两个有序链表
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
方法一:递归
我们可以如下递归地定义两个链表里的 merge 操作(忽略边界情况,比如空链表等):

也就是说,两个链表头部值较小的一个节点与剩下元素的 merge 操作结果合并。
如果 l1 或者 l2 一开始就是空链表 ,那么没有任何操作需要合并,所以我们只需要返回非空链表。否则,我们要判断 l1 和 l2 哪一个链表的头节点的值更小,然后递归地决定下一个添加到结果里的节点。如果两个链表有一个为空,递归结束。
var mergeTwoLists = function(l1, l2) {if (l1 === null) {return l2;} else if (l2 === null) {return l1;} else if (l1.val < l2.val) {l1.next = mergeTwoLists(l1.next, l2);return l1;} else {l2.next = mergeTwoLists(l1, l2.next);return l2;}};
方法二:迭代
我们可以用迭代的方法来实现上述算法。当 l1 和 l2 都不是空链表时,判断 l1 和 l2 哪一个链表的头节点的值更小,将较小值的节点添加到结果里,当一个节点被添加到结果里之后,将对应链表中的节点向后移一位。
首先,我们设定一个哨兵节点 prehead ,这可以在最后让我们比较容易地返回合并后的链表。我们维护一个 prev 指针,我们需要做的是调整它的 next 指针。然后,我们重复以下过程,直到 l1 或者 l2 指向了 null :如果 l1 当前节点的值小于等于 l2 ,我们就把 l1 当前的节点接在 prev 节点的后面同时将 l1 指针往后移一位。否则,我们对 l2 做同样的操作。不管我们将哪一个元素接在了后面,我们都需要把 prev 向后移一位。
在循环终止的时候, l1 和 l2 至多有一个是非空的。由于输入的两个链表都是有序的,所以不管哪个链表是非空的,它包含的所有元素都比前面已经合并链表中的所有元素都要大。这意味着我们只需要简单地将非空链表接在合并链表的后面,并返回合并链表即可。
var mergeTwoLists = function(l1, l2) {const prehead = new ListNode(-1);let prev = prehead;while (l1 != null && l2 != null) {if (l1.val <= l2.val) {prev.next = l1;l1 = l1.next;} else {prev.next = l2;l2 = l2.next;}prev = prev.next;}// 合并后 l1 和 l2 最多只有一个还未被合并完,我们直接将链表末尾指向未合并完的链表即可prev.next = l1 === null ? l2 : l1;return prehead.next;};
141. 环形链表
给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos 不作为参数进行传递 。仅仅是为了标识链表的实际情况。
如果链表中存在环 ,则返回 true 。 否则,返回 false 。
方法1:哈希表或set
思路:准备一个map或者set,然后循环链表,每次遍历到一个节点的时候,判断当前节点是否在map中存在,如果不存在就把当前节点加入map中,如果存在的话说明之前访问过此节点,也就说明了这条链表有环。
复杂度分析:时间复杂度O(n),n是链表的数量,最差的情况下每个节点都要遍历。空间复杂度O(n),n是存储遍历过的节点的map或者set
var hasCycle = (head) => {let map = new Map();while (head) {if (map.has(head)) return true;//如果当前节点在map中存在就说明有环map.set(head, true);//否则就加入maphead = head.next;//迭代节点}return false;//循环完成发现没有重复节点,说明没环};
方法2:快慢指针
思路:准备两个指针fast和slow,循环链表,slow指针初始也指向head,每次循环向前走一步,fast指针初始指向head,每次循环向前两步,如果没有环,则快指针会抵达终点,如果有环,那么快指针会追上慢指针
复杂度:时间复杂度O(n),空间复杂度O(1)
var hasCycle = function (head) {//设置快慢指针let slow = head;let fast = head;//如果没有环,则快指针会抵达终点,否则继续移动双指针while (fast && fast.next) {slow = slow.next;fast = fast.next.next;//快慢指针相遇,说明含有环if (slow == fast) {return true;}}return false;};
142. 环形链表 II
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
不允许修改 链表。
方法1:同上题。
var detectCycle = function(head) {let map = new Map();while (head) {if (map.has(head)) return head;//如果当前节点在map中存在就说明有环map.set(head, true);//否则就加入maphead = head.next;//迭代节点}return null;//循环完成发现没有重复节点,说明没环};
160. 相交链表
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
题目数据 保证 整个链式结构中不存在环。注意,函数返回结果后,链表必须保持其原始结构 。
方法一:哈希集合
判断两个链表是否相交,可以使用哈希集合存储链表节点。
首先遍历链表 headA,并将链表 headA 中的每个节点加入哈希集合中。然后遍历链表 headB,对于遍历到的每个节点,判断该节点是否在哈希集合中:
var getIntersectionNode = function(headA, headB) {const visited = new Set();let temp = headA;while (temp !== null) {visited.add(temp);temp = temp.next;}temp = headB;while (temp !== null) {if (visited.has(temp)) {return temp;}temp = temp.next;}return null;};
- 时间复杂度:O(m+n),其中 m 和 n 是分别是链表 headA 和 headB 的长度。需要遍历两个链表各一次。
- 空间复杂度:O(m),其中 m 是链表 headA 的长度。需要使用哈希集合存储链表 headA 中的全部节点。
方法2:双指针
思路:用双指针pA 、pB循环俩个链表,链表A循环结束就循环链表B,链表B循环结束就循环链表A,当pA == pB时就是交点,因为两个指针移动的步数一样
复杂度:时间复杂度O(m+n),m、n分别是两个链表的长度。空间复杂度O(1)
var getIntersectionNode = function(headA, headB) {if (headA === null || headB === null) {return null;}let pA = headA, pB = headB;while (pA !== pB) {pA = pA === null ? headB : pA.next;//链表A循环结束就循环链表BpB = pB === null ? headA : pB.next;//链表B循环结束就循环链表A}return pA;//当pA == pB时就是交点};
BM2 链表内指定区间反转
将一个节点数为 size 链表 m 位置到 n 位置之间的区间反转,要求时间复杂度 O(n),空间复杂度 O(1)。

function reverse(head) {let pre = null;let cur = head;let next = head;while(cur) {next = cur.next;cur.next = pre;pre = cur;cur = next;}return pre;}function reverseBetween( head , m , n ) {// write code hereif(m === n) return head;//设置虚拟头节点let dummyNode = new ListNode(-1);dummyNode.next = head;let pre = dummyNode;//到left的前一个节点for(let i = 0; i < m -1; i++) {pre = pre.next}//到right节点let rightNode = prefor(let i = 0; i < n-m+1; i++) {rightNode = rightNode.next}//截取一个子链表let leftNode = pre.next;let cur = rightNode.next;//切断连接pre.next = null;rightNode.next = null;//反转局部链表reverse(leftNode);//接回原来的链表pre.next = rightNode;leftNode.next = cur;return dummyNode.next}
BM3 链表中的节点每k个一组翻转
递归
大致过程可以分解为
1、找到待翻转的k个节点(注意:若剩余数量小于 k 的话,则不需要反转,因此直接返回待翻转部分的头结点即可)。
2、对其进行翻转。并返回翻转后的头结点(注意:翻转为左闭又开区间,尾结点其实就是下一次的头结点)。
3、对下一轮 k 个节点也进行翻转操作。
4、将上一轮翻转后的尾结点指向下一轮翻转后的头节点,即将每一轮翻转的k的节点连接起来。
function reverse(head,tail) {let pre = null, cur = head, next = null;while(cur !== tail) {next = cur.next;cur.next = pre;pre = cur;cur = next;}return pre}function reverseKGroup( head , k ) {// write code hereif(head === null || head.next === null) return head;let tail = head;for(let i = 0; i < k; i++) {//剩余数量小于k的话,则不需要反转。if(tail === null) {return head}tail = tail.next;}// 反转前 k 个元素let newHead = reverse(head,tail);//下一轮的开始的地方就是tailhead.next = reverseKGroup(tail,k)return newHead}
剑指 Offer 22. 链表中倒数第k个节点
输入一个链表,输出该链表中倒数第k个节点。为了符合大多数人的习惯,本题从1开始计数,即链表的尾节点是倒数第1个节点。
例如,一个链表有 6 个节点,从头节点开始,它们的值依次是 1、2、3、4、5、6。这个链表的倒数第 3 个节点是值为 4 的节点。
方法一:顺序查找
思路与算法
最简单直接的方法即为顺序查找,假设当前链表的长度为 n,则我们知道链表的倒数第 k 个节点即为正数第 n−k 个节点,此时我们只需要顺序遍历到链表的第 n−k 个节点即为倒数第 k 个节点。
我们首先求出链表的长度 n,然后顺序遍历到链表的第 n−k 个节点返回即可。
var getKthFromEnd = function(head, k) {let node = head, n = 0;while (node) {node = node.next;n++;}node = head;for (let i = 0; i < n - k; i++) {node = node.next;}return node;};
- 时间复杂度:O(n),其中 n 为链表的长度。需要两次遍历。
- 空间复杂度:O(1)。
方法二:双指针
思路与算法
快慢指针的思想。我们将第一个指针 fast 指向链表的第 k + 1 个节点,第二个指针 slow 指向链表的第一个节点,此时指针 fast 与 slow 二者之间刚好间隔 k 个节点。此时两个指针同步向后走,当第一个指针 fast 走到链表的尾部空节点时,则此时 slow 指针刚好指向链表的倒数第k个节点。
我们首先将 fast 指向链表的头节点,然后向后走 k 步,则此时 fast 指针刚好指向链表的第 k+1 个节点。
我们首先将 slow 指向链表的头节点,同时 slow 与 fast 同步向后走,当 fast 指针指向链表的尾部空节点时,则此时返回 slow 所指向的节点即可。
var getKthFromEnd = function(head, k) {let fast = head, slow = head;while (fast && k > 0) {[fast, k] = [fast.next, k - 1];}while (fast) {[fast, slow] = [fast.next, slow.next];}return slow;};
- 时间复杂度:O(n),其中 n为链表的长度。我们使用快慢指针,只需要一次遍历即可,复杂度为 O(n)。
- 空间复杂度:O(1)。
剑指 Offer II 021. 删除链表的倒数第 n 个结点
给定一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
var removeNthFromEnd = function(head, n) {if(head === null || n === 0) return head;let fast = head, slow = head,cur = head;while (fast && n > 0 ) {[fast, n] = [fast.next, n - 1];}if(fast === null) return head.next;while (fast!==null && fast.next !== null) {[fast, slow] = [fast.next, slow.next];}slow.next = slow.next.nextreturn cur;};
剑指 Offer II 025. 链表中的两数相加
给定两个 非空链表 l1和 l2 来代表两个非负整数。数字最高位位于链表开始位置。它们的每个节点只存储一位数字。将这两数相加会返回一个新的链表。
可以假设除了数字 0 之外,这两个数字都不会以零开头。
- 将两个链表分别反转
- 反转之后的链表的头节点表示个位数,尾节点表示最高位;从两个链表的头节点开始相加,就相当于从整数的个位数开始相加
- 要注意进位,如果两个整数的个位数相加的和超过10,就会往十位数产生一个进位,在下一步做十位数相加时就要把这个进位考虑进去
var reverseList = function (head) {if (head == null || head.next == null) {return head;}let cur = reverseList(head.next);head.next.next = head;head.next = null;return cur;};var addTwoNumbers = function (l1, l2) {l1 = reverseList(l1);l2 = reverseList(l2);const addReversed = (l1, l2) => {let dummy = new ListNode(0);let sumNode = dummy;let carry = 0;while (l1 != null || l2 != null) {let sum = (l1 == null ? 0 : l1.val) + (l2 == null ? 0 : l2.val) + carry;if (sum >= 10) {carry = 1;sum -= 10;} else {carry = 0;}let newNode = new ListNode(sum);sumNode.next = newNode;sumNode = sumNode.next;l1 = l1 == null ? null : l1.next;l2 = l2 == null ? null : l2.next;}if (carry > 0) {sumNode.next = new ListNode(carry);}return dummy.next;};let reverseHead = addReversed(l1, l2);return reverseList(reverseHead);};
剑指 Offer II 027. 回文链表
给定一个链表的 头节点 head ,请判断其是否为回文链表。
如果一个链表是回文,那么链表节点序列从前往后看和从后往前看是相同的。
方法一:将值复制到数组中后用双指针法
思路:如果你还不太熟悉链表,下面有关于列表的概要讲述。
有两种常用的列表实现,分别为数组列表和链表。如果我们想在列表中存储值,它们是如何实现的呢?
- 数组列表底层是使用数组存储值,我们可以通过索引在 O(1) 的时间访问列表任何位置的值,这是由基于内存寻址的方式。
- 链表存储的是称为节点的对象,每个节点保存一个值和指向下一个节点的指针。访问某个特定索引的节点需要 O(n) 的时间,因为要通过指针获取到下一个位置的节点。
确定数组列表是否回文很简单,我们可以使用双指针法来比较两端的元素,并向中间移动。一个指针从起点向中间移动,另一个指针从终点向中间移动。这需要 O(n) 的时间,因为访问每个元素的时间是 O(1),而有 n 个元素要访问。
然而同样的方法在链表上操作并不简单,因为不论是正向访问还是反向访问都不是 O(1)。而将链表的值复制到数组列表中是 O(n),因此最简单的方法就是将链表的值复制到数组列表中,再使用双指针法判断。
算法一共为两个步骤:
- 复制链表值到数组列表中。
- 使用双指针法判断是否为回文。
第一步,我们需要遍历链表将值复制到数组列表中。我们用 currentNode 指向当前节点。每次迭代向数组添加 currentNode.val,并更新 currentNode = currentNode.next,当 currentNode = null 时停止循环。
执行第二步的最佳方法取决于你使用的语言。在 Python 中,很容易构造一个列表的反向副本,也很容易比较两个列表。而在其他语言中,就没有那么简单。因此最好使用双指针法来检查是否为回文。我们在起点放置一个指针,在结尾放置一个指针,每一次迭代判断两个指针指向的元素是否相同,若不同,返回 false;相同则将两个指针向内移动,并继续判断,直到两个指针相遇。
在编码的过程中,注意我们比较的是节点值的大小,而不是节点本身。正确的比较方式是:node_1.val == node_2.val,而 node_1 == node_2 是错误的。
var isPalindrome = function(head) {const vals = [];while (head !== null) {vals.push(head.val);head = head.next;}for (let i = 0, j = vals.length - 1; i < j; ++i, --j) {if (vals[i] !== vals[j]) {return false;}}return true;};
方法二:快慢指针
思路:避免使用 O(n) 额外空间的方法就是改变输入。
我们可以将链表的后半部分反转(修改链表结构),然后将前半部分和后半部分进行比较。比较完成后我们应该将链表恢复原样。虽然不需要恢复也能通过测试用例,但是使用该函数的人通常不希望链表结构被更改。
该方法虽然可以将空间复杂度降到O(1),但是在并发环境下,该方法也有缺点。在并发环境下,函数运行时需要锁定其他线程或进程对链表的访问,因为在函数执行过程中链表会被修改。
整个流程可以分为以下五个步骤:
- 找到前半部分链表的尾节点。
- 反转后半部分链表。
- 判断是否回文。
- 恢复链表。
- 返回结果。
执行步骤一,我们可以计算链表节点的数量,然后遍历链表找到前半部分的尾节点。
我们也可以使用快慢指针在一次遍历中找到:慢指针一次走一步,快指针一次走两步,快慢指针同时出发。当快指针移动到链表的末尾时,慢指针恰好到链表的中间。通过慢指针将链表分为两部分。
若链表有奇数个节点,则中间的节点应该看作是前半部分。
步骤二可以使用「206. 反转链表」问题中的解决方法来反转链表的后半部分。
步骤三比较两个部分的值,当后半部分到达末尾则比较完成,可以忽略计数情况中的中间节点。
步骤四与步骤二使用的函数相同,再反转一次恢复链表本身。
const reverseList = (head) => {let prev = null;let curr = head;while (curr !== null) {let nextTemp = curr.next;curr.next = prev;prev = curr;curr = nextTemp;}return prev;}const endOfFirstHalf = (head) => {let fast = head;let slow = head;while (fast.next !== null && fast.next.next !== null) {fast = fast.next.next;slow = slow.next;}return slow;}var isPalindrome = function(head) {if (head == null) return true;// 找到前半部分链表的尾节点并反转后半部分链表const firstHalfEnd = endOfFirstHalf(head);const secondHalfStart = reverseList(firstHalfEnd.next);// 判断是否回文let p1 = head;let p2 = secondHalfStart;let result = true;while (result && p2 != null) {if (p1.val != p2.val) result = false;p1 = p1.next;p2 = p2.next;}// 还原链表并返回结果firstHalfEnd.next = reverseList(secondHalfStart);return result;};
剑指 Offer II 077. 链表排序
算法思想一:辅助数组
主要通过辅助数组实现链表的排序
1、遍历链表并将链表结点存储到数组 tmp 中
2、通过对 tmp 进行排序,实现链表结点的排序
3、构建新链表结点 result,遍历数组 tmp ,拼接新的返回链表
function sortInList( head ) {// write code herelet arr = [];while(head) {arr.push(head.val);head = head.next}arr.sort((a,b) => a-b);let head1 = new ListNode(arr[0])let cur = head1;let i = 1;while(i < arr.length) {cur.next = new ListNode(arr[i]);cur = cur.nexti++;}return head1}
算法思想二:归并排序(递归)
解题思路:
主要通过递归实现链表归并排序,有以下两个环节:
1、分割 cut 环节: 找到当前链表中点,并从中点将链表断开(以便在下次递归 cut 时,链表片段拥有正确边界);
使用 fast,slow 快慢双指针法,奇数个节点找到中点,偶数个节点找到中心左边的节点。
找到中点 slow 后,执行 slow.next = None 将链表切断。
递归分割时,输入当前链表左端点 head 和中心节点 slow 的下一个节点 tmp(因为链表是从 slow 切断的)。
cut 递归终止条件: 当head.next == None时,说明只有一个节点了,直接返回此节点
2、合并 merge 环节: 将两个排序链表合并,转化为一个排序链表。
双指针法合并,建立辅助ListNode h 作为头部。
设置两指针 left, right 分别指向两链表头部,比较两指针处节点值大小,由小到大加入合并链表头部,指针交替前进,直至添加完两个链表。
返回辅助ListNode h 作为头部的下个节点 h.next。
时间复杂度 O(l + r),l, r 分别代表两个链表长度。
3、特殊情况,当题目输入的 head == None 时,直接返回None。
图解:

// 归并排序var sortList = function (head) {if (!head || head.next === null) return head;// 使用快慢指针找到中间节点let slow = head,fast = head.next;while (fast !== null && fast.next !== null) {slow = slow.next;fast = fast.next.next;}// 将链表分成两半并返回后半部分链表的头节点let newList = slow.next;slow.next = null;// 对前后两个链表进行排序let left = sortList(head);let right = sortList(newList);// 将排序好的两个有序链表合并为一个链表let res = new ListNode(-1);let nHead = res;// 合并链表只需要调整指针的指向// 两个链表哪个节点的值小就先指向它while (left !== null && right !== null) {if (left.val < right.val) {nHead.next = left;left = left.next;} else {nHead.next = right;right = right.next;}nHead = nHead.next;}nHead.next = left === null ? right : left;return res.next;};
328. 奇偶链表
给定单链表的头节点 head ,将所有索引为奇数的节点和索引为偶数的节点分别组合在一起,然后返回重新排序的列表。
第一个节点的索引被认为是 奇数 , 第二个节点的索引为 偶数 ,以此类推。
请注意,偶数组和奇数组内部的相对顺序应该与输入时保持一致。
你必须在 O(1) 的额外空间复杂度和 O(n) 的时间复杂度下解决这个问题。
var oddEvenList = function(head) {if (head === null) {return head;}let evenHead = head.next;let odd = head, even = evenHead;while (even !== null && even.next !== null) {odd.next = even.next;odd = odd.next;even.next = odd.next;even = even.next;}odd.next = evenHead;return head;};
BM16 删除有序链表中重复的元素-II
给出一个升序排序的链表,删除链表中的所有重复出现的元素,只保留原链表中只出现一次的元素。
思路:
这是一个升序链表,重复的节点都连在一起,我们就可以很轻易地比较到重复的节点,然后将所有的连续相同的节点都跳过,连接不相同的第一个节点。
//遇到相邻两个节点值相同if(cur.next.val == cur.next.next.val){let temp = cur.next.val;//将所有相同的都跳过while (cur.next != null && cur.next.val == temp)cur.next = cur.next.next;}
具体做法:
- step 1:给链表前加上表头,方便可能的话删除第一个节点。
let dummyNode = new ListNode(-1);//在链表前加一个表头dummyNode.next = head;
- step 2:遍历链表,每次比较相邻两个节点,如果遇到了两个相邻节点相同,则新开内循环将这一段所有的相同都遍历过去。
- step 3:在step 2中这一连串相同的节点前的节点直接连上后续第一个不相同值的节点。
- step 4:返回时去掉添加的表头。
function deleteDuplicates(head) {// write code hereif (head == null) return head;const dummyNode = new ListNode(-1);dummyNode.next = head;let cur = dummyNode;while (cur.next && cur.next.next) {if (cur.next.val === cur.next.next.val) {const temp = cur.next.val;while (cur.next && cur.next.val === temp) {cur.next = cur.next.next;}} else {cur = cur.next;}}return dummyNode.next;}
二叉树
二叉树的前序遍历
给你二叉树的根节点 root ,返回它节点值的 前序 遍历。
思路:
什么是二叉树的前序遍历?简单来说就是“根左右”,展开来说就是对于一颗二叉树优先访问其根节点,然后访问它的左子树,等左子树全部访问完了再访问其右子树,而对于子树也按照之前的访问方式,直到到达叶子节点。
从上述前序遍历的解释中我们不难发现,它存在递归的子问题:每次访问一个节点之后,它的左子树是一个要前序遍历的子问题,它的右子树同样是一个要前序遍历的子问题。那我们可以用递归处理:
终止条件: 当子问题到达叶子节点后,后一个不管左右都是空,因此遇到空节点就返回。
返回值:每次处理完子问题后,就是将子问题访问过的元素返回,依次存入了数组中。
本级任务:每个子问题优先访问这棵子树的根节点,然后递归进入左子树和右子树。 因此处理的时候,过程就是:
- step 1:准备数组用来记录遍历到的节点值。
- step 2:从根节点开始进入递归,遇到空节点就返回,否则将该节点值加入数组。
- step 3:依次进入左右子树进行递归。
var preorderTraversal = function(root) {const res = [];const inorder = (root) => {if (!root) {return;}res.push(root.val);inorder(root.left);inorder(root.right);}inorder(root);return res;};
迭代法:
// 入栈 右 -> 左// 出栈 中 -> 左 -> 右var preorderTraversal = function(root, res = []) {if(!root) return res;const stack = [root];let cur = null;while(stack.length) {cur = stack.pop();res.push(cur.val);cur.right && stack.push(cur.right);cur.left && stack.push(cur.left);}return res;};
94. 二叉树的中序遍历
方法一:递归
首先我们需要了解什么是二叉树的中序遍历:按照访问左子树——根节点——右子树的方式遍历这棵树,而在访问左子树或者右子树的时候我们按照同样的方式遍历,直到遍历完整棵树。因此整个遍历过程天然具有递归的性质,我们可以直接用递归函数来模拟这一过程。
定义 inorder(root) 表示当前遍历到 root 节点的答案,那么按照定义,我们只要递归调用 inorder(root.left) 来遍历 root 节点的左子树,然后将 root 节点的值加入答案,再递归调用inorder(root.right) 来遍历 root 节点的右子树即可,递归终止的条件为碰到空节点。
var inorderTraversal = function(root) {const res = [];const inorder = (root) => {if (!root) {return;}inorder(root.left);res.push(root.val);inorder(root.right);}inorder(root);return res;};
复杂度分析
时间复杂度:O(n),其中 n 为二叉树节点的个数。二叉树的遍历中每个节点会被访问一次且只会被访问一次。
空间复杂度:O(n)。空间复杂度取决于递归的栈深度,而栈深度在二叉树为一条链的情况下会达到 O(n) 的级别。
方法二:迭代
方法一的递归函数我们也可以用迭代的方式实现,两种方式是等价的,区别在于递归的时候隐式地维护了一个栈,而我们在迭代的时候需要显式地将这个栈模拟出来,其他都相同,具体实现可以看下面的代码。
var inorderTraversal = function(root) {const res = [];const stk = [];while (root || stk.length) {while (root) {stk.push(root);root = root.left;}root = stk.pop();res.push(root.val);root = root.right;}return res;};
复杂度分析
时间复杂度:O(n),其中 n 为二叉树节点的个数。二叉树的遍历中每个节点会被访问一次且只会被访问一次。
空间复杂度:O(n)。空间复杂度取决于栈深度,而栈深度在二叉树为一条链的情况下会达到 O(n) 的级别。
二叉树的后序遍历
//递归var postorderTraversal = function(root) {const res = [];const inorder = (root) => {if (!root) {return;}inorder(root.left);inorder(root.right);res.push(root.val);}inorder(root);return res;};//迭代// 入栈 左 -> 右// 出栈 中 -> 右 -> 左 结果翻转var postorderTraversal = function(root, res = []) {if (!root) return res;const stack = [root];let cur = null;do {cur = stack.pop();res.push(cur.val);cur.left && stack.push(cur.left);cur.right && stack.push(cur.right);} while(stack.length);return res.reverse();};
102. 二叉树的层序遍历
给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。
方法一:广度优先搜索
定义一个队列 queue 来存放节点
遍历队列,挨个节点从头部取出
记录取出的节点的数值 val,如果有左右节点再加入队列,供下一次遍历使用
最后队列长度为 0 即遍历结束
var levelOrder = function(root) {//二叉树的层序遍历let res=[],queue=[];queue.push(root);if(root === null){return res;}while(queue.length !== 0){// 记录当前层级节点数let length=queue.length;//存放每一层的节点let curLevel=[];for(let i=0;i<length;i++){let node=queue.shift();curLevel.push(node.val);// 存放当前层下一层的节点node.left&&queue.push(node.left);node.right&&queue.push(node.right);}//把每一层的结果放到结果数组res.push(curLevel);}return res;};
复杂度分析
记树上所有节点的个数为 n。
时间复杂度:每个点进队出队各一次,故渐进时间复杂度为 O(n)。
空间复杂度:队列中元素的个数不超过 n 个,故渐进空间复杂度为 O(n)。
103. 二叉树的锯齿形层序遍历
给你二叉树的根节点 root ,返回其节点值的 锯齿形层序遍历 。(即先从左往右,再从右往左进行下一层遍历,以此类推,层与层之间交替进行)。
思路:
方法一:广度优先遍历
此题是「102. 二叉树的层序遍历」的变种,最后输出的要求有所变化,要求我们按层数的奇偶来决定每一层的输出顺序。规定二叉树的根节点为第 0 层,如果当前层数是偶数,从左至右输出当前层的节点值,否则,从右至左输出当前层的节点值。
我们依然可以沿用第 102 题的思想,修改广度优先搜索,对树进行逐层遍历,用队列维护当前层的所有元素,当队列不为空的时候,求得当前队列的长度 size,每次从队列中取出 size 个元素进行拓展,然后进行下一次迭代。
为了满足题目要求的返回值为「先从左往右,再从右往左」交替输出的锯齿形,我们可以利用「双端队列」的数据结构来维护当前层节点值输出的顺序。
双端队列是一个可以在队列任意一端插入元素的队列。在广度优先搜索遍历当前层节点拓展下一层节点的时候我们仍然从左往右按顺序拓展,但是对当前层节点的存储我们维护一个变量 isOrderLeft 记录是从左至右还是从右至左的:
- 如果从左至右,我们每次将被遍历到的元素插入至双端队列的末尾。
- 如果从右至左,我们每次将被遍历到的元素插入至双端队列的头部。
当遍历结束的时候我们就得到了答案数组。
var zigzagLevelOrder = function(root) {if (!root) {return [];}const ans = [];const nodeQueue = [root];let isOrderLeft = true;while (nodeQueue.length) {let levelList = [];const size = nodeQueue.length;for (let i = 0; i < size; ++i) {const node = nodeQueue.shift();if (isOrderLeft) {levelList.push(node.val);} else {levelList.unshift(node.val);}if (node.left !== null) {nodeQueue.push(node.left);}if (node.right !== null) {nodeQueue.push(node.right);}}ans.push(levelList);isOrderLeft = !isOrderLeft;}return ans;};
104. 二叉树的最大深度
给定一个二叉树,找出其最大深度。
二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
说明: 叶子节点是指没有子节点的节点。
示例:
给定二叉树 [3,9,20,null,null,15,7],返回它的最大深度 3 。
var maxDepth = function (root) {if (root == null) return 0;let queue = [];queue.push(root);let ans = 0;while (queue.length) {let size = queue.length;for (let i = 0; i < size; i++) {// 队头出队列let node = queue.shift();if (node.left) queue.push(node.left);if (node.right) queue.push(node.right);}ans += 1;}return ans;};
230. 二叉搜索树中第K小的元素
给定一个二叉搜索树的根节点 root ,和一个整数 k ,请你设计一个算法查找其中第 k 个最小元素(从 1 开始计数)。
var kthSmallest = function(root, k) {let res = [];let min = (root) => {if(root !== null) {min(root.left);res.push(root.val);min(root.right);}}min(root);return res[k-1]};
236. 二叉树的最近公共祖先
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
思路:
对于根节点 root,p、q 的分布,有两种可能:
- p、q 分居 root 的左右子树,则 LCA 为 root。
- p、q 存在于 root 的同一侧子树中,就变成规模小一点的相同问题。
定义递归函数
递归函数:返回当前子树中 p 和 q 的 LCA。如果没有 LCA,就返回 null。
从根节点 root 开始往下递归遍历……
如果遍历到 p 或 q,比方说 p,则 LCA 要么是当前的 p(q 在 p 的子树中),要么是 p 之上的节点(q 不在 p 的子树中),不可能是 p 之下的节点,不用继续往下走,返回当前的 p。
当遍历到 null 节点,空树不存在 p 和 q,没有 LCA,返回 null。
当遍历的节点 root 不是 p 或 q 或 null,则递归搜寻 root 的左右子树:
如果左右子树的递归都有结果,说明 p 和 q 分居 root 的左右子树,返回 root。
如果只是一个子树递归调用有结果,说明 p 和 q 都在这个子树,返回该子树递归结果。
如果两个子树递归结果都为 null,说明 p 和 q 都不在这俩子树中,返回 null。
const lowestCommonAncestor = (root, p, q) => {if (root == null) { // 遇到null,返回null 没有LCAreturn null;}if (root == q || root == p) { // 遇到p或q,直接返回当前节点return root;}// 非null 非q 非p,则递归左右子树const left = lowestCommonAncestor(root.left, p, q);const right = lowestCommonAncestor(root.right, p, q);// 根据递归的结果,决定谁是LCAif (left && right) {return root;}if (left == null) {return right;}return left;};
129. 求根节点到叶节点数字之和
给你一个二叉树的根节点 root ,树中每个节点都存放有一个 0 到 9 之间的数字。
每条从根节点到叶节点的路径都代表一个数字:
例如,从根节点到叶节点的路径 1 -> 2 -> 3 表示数字 123 。
计算从根节点到叶节点生成的 所有数字之和 。
叶节点 是指没有子节点的节点。
var sumNumbers = function(root) {let res = 0;function dfs(root,temp) {if(!root) return;temp += root.val;if((!root.left) && (!root.right)) res += Number(temp);dfs(root.left,temp);dfs(root.right,temp);}dfs(root,'');return res;}
101. 对称二叉树
给你一个二叉树的根节点 root , 检查它是否轴对称。
方法一:递归
该问题可以转化为:两个树在什么情况下互为镜像?
如果同时满足下面的条件,两个树互为镜像:
- 它们的两个根结点具有相同的值
- 每个树的右子树都与另一个树的左子树镜像对称
我们可以实现这样一个递归函数,通过「同步移动」两个指针的方法来遍历这棵树,p 指针和 q 指针一开始都指向这棵树的根,随后 p 右移时,q 左移,p 左移时,q 右移。每次检查当前 p 和 q 节点的值是否相等,如果相等再判断左右子树是否对称。
const check = (p,q) => {if (!p && !q) return true;if(!p || !q) return false;return p.val === q.val && check(p.left, q.right) && check(p.right, q.left)}var isSymmetric = function(root) {return check(root,root);}
98. 验证二叉搜索树
给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。
方法一: 递归
const helper = (root, lower, upper) => {if (root === null) {return true;}if (root.val <= lower || root.val >= upper) {return false;}return helper(root.left, lower, root.val) && helper(root.right, root.val, upper);}var isValidBST = function(root) {return helper(root, -Infinity, Infinity);};
方法二:中序遍历
二叉搜索树「中序遍历」得到的值构成的序列一定是升序的,这启示我们在中序遍历的时候实时检查当前节点的值是否大于前一个中序遍历到的节点的值即可。如果均大于说明这个序列是升序的,整棵树是二叉搜索树,否则不是,下面的代码我们使用栈来模拟中序遍历的过程。
var isValidBST = function(root) {let stack = [];let inorder = -Infinity;while (stack.length || root !== null) {while (root !== null) {stack.push(root);root = root.left;}root = stack.pop();// 如果中序遍历得到的节点的值小于等于前一个 inorder,说明不是二叉搜索树if (root.val <= inorder) {return false;}inorder = root.val;root = root.right;}return true;};
105. 从前序与中序遍历序列构造二叉树
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。
前序遍历为先找根节点,再遍历左节点,然后遍历右节点。中序遍历先遍历左节点,然后根节点,最后遍历右节点。
以题中例子为例,preorder = [3,9,20,15,7], inorder = [9,3,15,20,7]。
根节点为preorder[0] = 3; inorder中inorder[1] = 3;所以inorder中 i < 1的都为左节点,i > 1的都为右节点。
那么可得左节点个数为 i - 0 = i,右节点个数为inorder.length - i - 1。
根据以上结果,我们可以获得preorder中,1 ~ i为左节点,i ~ inorder.length为右节点。
根据这个规律,我们可以分割二叉树,将问题转为分别找左子树和右子树的根结点。
var buildTree = function(preorder, inorder) {if(preorder.length === 0 || inorder.length === 0) {return null;}// 根据前序数组的第一个元素,就可以确定根节点const root = new TreeNode(preorder[0]);for(let i = 0;i < inorder.length; i++) {// 用preorder[0]去中序数组中查找对应的元素if(preorder[0] == inorder[i]) {// 将前序数组分成左右两半,注意从索引1开始。const pre_left = preorder.slice(1, i + 1);const pre_right = preorder.slice(i + 1, preorder.length);// 将中序数组分成左右两半const in_left = inorder.slice(0, i);const in_right = inorder.slice(i + 1, inorder.length);// 之后递归的处理前序数组的左边部分和中序数组的左边部分root.left = buildTree(pre_left,in_left);// 递归处理前序数组右边部分和中序数组右边部分root.right = buildTree(pre_right,in_right);return root;}}};
226. 翻转二叉树(镜像)
给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。
这是一道很经典的二叉树问题。显然,我们从根节点开始,递归地对树进行遍历,并从叶子节点先开始翻转。如果当前遍历到的节点 root 的左右两棵子树都已经翻转,那么我们只需要交换两棵子树的位置,即可完成以 root 为根节点的整棵子树的翻转。
var invertTree = function(root) {if (root === null) {return null;}const left = invertTree(root.left);const right = invertTree(root.right);root.left = right;root.right = left;return root;};
复杂度分析
时间复杂度:O(N),其中 N 为二叉树节点的数目。我们会遍历二叉树中的每一个节点,对每个节点而言,我们在常数时间内交换其两棵子树。
空间复杂度:O(N)。使用的空间由递归栈的深度决定,它等于当前节点在二叉树中的高度。在平均情况下,二叉树的高度与节点个数为对数关系,即 O(logN)。而在最坏情况下,树形成链状,空间复杂度为 O(N)。
617. 合并二叉树
给你两棵二叉树: root1 和 root2 。
想象一下,当你将其中一棵覆盖到另一棵之上时,两棵树上的一些节点将会重叠(而另一些不会)。你需要将这两棵树合并成一棵新二叉树。合并的规则是:如果两个节点重叠,那么将这两个节点的值相加作为合并后节点的新值;否则,不为 null 的节点将直接作为新二叉树的节点。
返回合并后的二叉树。
注意: 合并过程必须从两个树的根节点开始。
var mergeTrees = function(root1, root2) {if(root1 == null) return root2;else if(root2 == null) return root1;else {let root = new TreeNode(root1.val+root2.val);root.left = mergeTrees(root1.left,root2.left);root.right = mergeTrees(root1.right,root2.right);return root}};
110. 平衡二叉树
给定一个二叉树,判断它是否是高度平衡的二叉树。
本题中,一棵高度平衡二叉树定义为:
一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1 。
var isBalanced = function (root) {// 声明一个变量保存平衡状态let isBalanced = true// 从根结点开始递归遍历function checkBanlance(node, level) {// 如果节点为空直接返回levelif (node === null) return level// 递归遍历左节点,获取其level值,检查是否平衡let left = checkBanlance(node.left, level + 1)// 如果平衡状态为false直接返回if (!isBalanced) {return left}// 递归遍历右节点,获取其level值,检查是否平衡let right = checkBanlance(node.right, level + 1)// 如果平衡状态为false直接返回if (!isBalanced) {return right}// 检测左右level平衡是否超过1,超过1更改平衡状态if (Math.abs(left - right) > 1) isBalanced = false// 返回最大的level值return Math.max(left, right)}checkBanlance(root, 0)return isBalanced};//解2function IsBalanced_Solution(pRoot){// write code here//题目特别提示空树是平衡二叉树//递归思想,对每一棵子树进行高度遍历,高度差不超过1,如果有一层超过则返回false//考察基础算法:求二叉树深度,递归(后序遍历)if(pRoot === null) {return true}if(Math.abs(depth(pRoot.left)-depth(pRoot.right))>1) {return false} //判断左右子树的深度差值return IsBalanced_Solution(pRoot.left) && IsBalanced_Solution(pRoot.right) //递归判断左右子树是否为平衡二叉树}function depth(node){if(node === null) {return 0}let left = depth(node.left)let right = depth(node.right)return Math.max(left,right)+1}
437. 路径总和 III
给定一个二叉树的根节点 root ,和一个整数 targetSum ,求该二叉树里节点值之和等于 targetSum 的 路径 的数目。
路径 不需要从根节点开始,也不需要在叶子节点结束,但是路径方向必须是向下的(只能从父节点到子节点)。
由于路径不一定是从根节点开始,也不一定在叶子节点结束,所以需要分别从每个节点出发做一次 pathSum。 pathSum 内部做的是根据传入的节点,统计有多少路径满足 targetSum。
var pathSum = function(root, targetSum) {if (!root) {return 0}let ans = 0function dfs (node, need) {if (!node) {return}if (need - node.val === 0) {ans ++}dfs(node.left, need - node.val)dfs(node.right, need - node.val)}dfs(root, targetSum)ans += pathSum(root.left, targetSum)ans += pathSum(root.right, targetSum)return ans};
剑指 Offer 34. 二叉树中和为某一值的路径
给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点 路径总和等于给定目标和的路径。
叶子节点 是指没有子节点的节点。
var pathSum = function(root, sum) {if(root === null) return []let ans = [];let dfs = (node, values, total) => {if(node == null) return false;total = total + node.valvalues = [...values, node.val]if(total === sum && node.left == null && node.right == null) {ans.push(values)return values}dfs(node.left,[...values],total)dfs(node.right,[...values],total)}dfs(root, [], 0)}
538. 把二叉搜索树转换为累加树
给出二叉 搜索 树的根节点,该树的节点值各不相同,请你将其转换为累加树(Greater Sum Tree),使每个节点 node 的新值等于原树中大于或等于 node.val 的值之和。
- 访问每个节点时,时刻维护变量 sum,保存「比当前节点值大的所有节点值的和」。
- 二叉搜索树的中序遍历,访问的节点值是递增的。
- 如果先访问右子树,反向的中序遍历,访问的节点值是递减的,之前访问的节点值都比当前的大,每次累加给 sum 即可。
- 对于每一个节点,先递归它的右子树,里面的节点值都比当前节点值大。
- 再 “处理” 当前节点,sum 累加上当前节点值,并更新当前节点值
- 再递归它的左子树,新访问的节点值比之前的都小,sum 保存着「比当前节点大的所有节点值的和」,累加上当前节点值,更新当前节点值。
const convertBST = (root) => {let sum = 0;const inOrder = (root) => {if (root == null) { // 遍历到null节点,开始返回return;}inOrder(root.right); // 先进入右子树sum += root.val; // 节点值累加给sumroot.val = sum; // 累加的结果,赋给root.valinOrder(root.left); // 然后才进入左子树};inOrder(root); // 递归的入口,从根节点开始return root;}
114. 二叉树展开为链表
给你二叉树的根结点 root ,请你将它展开为一个单链表:
展开后的单链表应该同样使用 TreeNode ,其中 right 子指针指向链表中下一个结点,而左子指针始终为 null 。
展开后的单链表应该与二叉树 先序遍历 顺序相同。
方法一:前序遍历
将二叉树展开为单链表之后,单链表中的节点顺序即为二叉树的前序遍历访问各节点的顺序。因此,可以对二叉树进行前序遍历,获得各节点被访问到的顺序。由于将二叉树展开为链表之后会破坏二叉树的结构,因此在前序遍历结束之后更新每个节点的左右子节点的信息,将二叉树展开为单链表。
var flatten = function(root) {const list = [];preorderTraversal(root, list);const size = list.length;for (let i = 1; i < size; i++) {const prev = list[i - 1], curr = list[i];prev.left = null;prev.right = curr;}};const preorderTraversal = (root, list) => {if (root != null) {list.push(root);preorderTraversal(root.left, list);preorderTraversal(root.right, list);}}
剑指 Offer 36. 二叉搜索树与双向链表
输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的循环双向链表。要求不能创建任何新的节点,只能调整树中节点指针的指向。
解题思路
中序遍历 + 回溯
本文解法基于性质:二叉搜索树的中序遍历为 递增序列 。
将 二叉搜索树 转换成一个 “排序的循环双向链表”
考虑使用 中序遍历 访问树的各节点 cur ;并在访问每个节点时构建 cur 和前驱节点 pre 的引用指向;中序遍历完成后,最后构建头节点和尾节点的引用指向即可。
终止条件: 当节点 cur 为空,代表越过叶节点,直接返回;
递归左子树,即 dfs(cur.left) ;
构建链表:
当 pre 为空时: 代表正在访问链表头节点,记为 head ;
当 pre 不为空时: 修改双向节点引用,即 pre.right = cur , cur.left = pre ;
保存 cur : 把 pre 指针移回 cur,然后继续遍历右子树去了
递归右子树,即 dfs(cur.right) ;
最后,再将链表头部 head 和尾部 pre 修改一下彼此的双向指向即可
var treeToDoublyList = function(root) {if(!root) return null;let pre, head;const dfs = (cur) => {if(!cur) return;// 中序遍历,先递归左子树dfs(cur.left);// 如果前置指针空了,那么是头结点if(!pre) {head = cur;} else {pre.right = cur;}// cur 的前置指针指向 precur.left = pre;// 遍历完,把 pre 指针移回 cur,然后继续遍历右子树去了pre = cur;dfs(cur.right);}dfs(root);head.left = pre;pre.right = head;return head;};
235. 二叉搜索树的最近公共祖先
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
思路:分为三种情况,1.root节点大于p并且大于q,说明p和q都在root的左子树, 2.root节点小于p并且小于q,说明p和q都在root的右子树,3.其他情况比如root等于p或q,说明root就是公共祖先,前两种情况直接递归左右子树,第3种情况直接返回root
var lowestCommonAncestor = function(root, p, q) {// 使用递归的方法// 1. 使用给定的递归函数lowestCommonAncestor// 2. 确定递归终止条件if(root === null) {return root;}if(root.val>p.val&&root.val>q.val) {// 向左子树查询let left = lowestCommonAncestor(root.left,p,q);return left !== null&&left;}if(root.val<p.val&&root.val<q.val) {// 向右子树查询let right = lowestCommonAncestor(root.right,p,q);return right !== null&&right;}return root;};
BM35 判断是不是完全二叉树
给定一个二叉树,确定他是否是一个完全二叉树。
完全二叉树的定义:若二叉树的深度为 h,除第 h 层外,其它各层的结点数都达到最大个数,第 h 层所有的叶子结点都连续集中在最左边,这就是完全二叉树。(第 h 层可能包含 [1~2h] 个节点)
思路:将每层的节点以层序遍历的方式全部放入队列中(包括null) 如果是完全二叉树,在我们取出节点的时候,应该是直到整棵树遍历完毕才会遇到null。 所以当我们按层序遍历的方式,遇到null,但是队列中仍然存在节点,则代表不是完全二叉树;否则,是完全二叉树。
function isCompleteTree( root ) {// write code herelet rootArr = new Array();rootArr.push(root);let end = false;while(rootArr.length) {const node = rootArr.shift();if(!node) {end = true;}else {if(rootArr.length && end) return false;rootArr.push(node.left);rootArr.push(node.right);}}return true;}
栈和堆列
剑指 Offer 09. 用两个栈实现队列
用两个栈实现一个队列。队列的声明如下,请实现它的两个函数 appendTail 和 deleteHead ,分别完成在队列尾部插入整数和在队列头部删除整数的功能。(若队列中没有元素,deleteHead 操作返回 -1 )
var CQueue = function() {this.stack1 = [];this.stack2 = [];};/*** @param {number} value* @return {void}*/CQueue.prototype.appendTail = function(value) {this.stack1.push(value)};/*** @return {number}*/CQueue.prototype.deleteHead = function() {//如果stack2没有元素则执行下面,否则直接popif(!this.stack2.length) {//stack1也没有元素就返回-1if(!this.stack1.length) {return -1;}while(this.stack1.length) {this.stack2.push(this.stack1.pop())}}return this.stack2.pop()};
剑指 Offer 30. 包含min函数的栈
定义栈的数据结构,请在该类型中实现一个能够得到栈的最小元素的 min 函数在该栈中,调用 min、push 及 pop 的时间复杂度都是 O(1)。
方法一:辅助栈
对于栈来说,如果一个元素 a 在入栈时,栈里有其它的元素 b, c, d,那么无论这个栈在之后经历了什么操作,只要 a 在栈中,b, c, d 就一定在栈中,因为在 a 被弹出之前,b, c, d 不会被弹出。
因此,在操作过程中的任意一个时刻,只要栈顶的元素是 a,那么我们就可以确定栈里面现在的元素一定是 a, b, c, d。
那么,我们可以在每个元素 a 入栈时把当前栈的最小值 m 存储起来。在这之后无论何时,如果栈顶元素是 a,我们就可以直接返回存储的最小值 m。
算法
按照上面的思路,我们只需要设计一个数据结构,使得每个元素 a 与其相应的最小值 m 时刻保持一一对应。因此我们可以使用一个辅助栈,与元素栈同步插入与删除,用于存储与每个元素对应的最小值。
当一个元素要入栈时,我们取当前辅助栈的栈顶存储的最小值,与当前元素比较得出最小值,将这个最小值插入辅助栈中;
当一个元素要出栈时,我们把辅助栈的栈顶元素也一并弹出;
在任意一个时刻,栈内元素的最小值就存储在辅助栈的栈顶元素中。
var MinStack = function() {this.x_stack = [];this.min_stack = [Infinity]; //这里需要指定为Infinity};MinStack.prototype.push = function(x) {this.x_stack.push(x);this.min_stack.push(Math.min(this.min_stack[this.min_stack.length - 1], x));};MinStack.prototype.pop = function() {this.x_stack.pop();this.min_stack.pop();};MinStack.prototype.top = function() {return this.x_stack[this.x_stack.length - 1];};MinStack.prototype.min = function() {return this.min_stack[this.min_stack.length - 1];};
时间复杂度:对于题目中的所有操作,时间复杂度均为 O(1)。因为栈的插入、删除与读取操作都是 O(1),我们定义的每个操作最多调用栈操作两次。
空间复杂度:O(n),其中 n 为总操作数。最坏情况下,我们会连续插入 n 个元素,此时两个栈占用的空间为 O(n)。
剑指 Offer 59 - I. 滑动窗口的最大值
给定一个数组 nums 和滑动窗口的大小 k,请找出所有滑动窗口里的最大值。
前言
对于每个滑动窗口,我们可以使用 O(k) 的时间遍历其中的每一个元素,找出其中的最大值。对于长度为 n 的数组 nums 而言,窗口的数量为 n−k+1,因此该算法的时间复杂度为 O((n−k+1)k)=O(nk),会超出时间限制,因此我们需要进行一些优化。
思路
max存储最大值;queue(两端开口的队列)存储滑动窗口最大值和随窗口滑动等待上位的可能的最大值[注:存储的都是下标]。queue:[滑动窗口最大值下标,等待上位的若干个可能成为最大值的下标],queue[0]默认就是最大值的下标。
情况1:滑动窗口大小为0,return null;
情况2:滑动窗口大小为1,return num;
情况3:滑动窗口的大小>=2,仔细分类,随i指针滑动,queue中存储的是下标,当指针i与最大值下标queue[0]超过滑动窗口大小size,最大值queue[0]出队,然后指针i滑动到i >= size - 1,开始有滑动窗口,max开始赋值,最复杂的情况就是窗口滑动过程中,对于最大值,和可能成为最大值的数的下标的存储与否。a.当指针i的值大于队里最大值queue[0],指针i成为滑动窗口可能的最大值,那后面等待上位的可能最大值也没机会上位了,就清空queue,i入队成为最大值queue[0];b.当指针i的值小于等于队里最大值queue[0],由于不知道随窗口滑动后面的值,该i有机会上位的,需要加入队尾,不过需要跟原队尾比较(队尾是队内最小值,唯一机会是等前面的随窗口滑动被移出队列而成为最大值上位),比原队尾大,就原队尾没机会上位移出去。
function maxInWindows(num, size) {// write code hereif (size === 0) {return []}if (size === 1) {return num}let queue = [0]let max = []for (let i = 1; i < num.length; i++) {//queue中存储的是下标,当指针与最大值下标超过size,自动出队if ((i - queue[0]) >= size) {queue.shift()}//指针到的值大于队里最大值,清空,指针最大值入队if (num[i] > num[queue[0]]) {queue = []queue.push(i)} else {//指针的值小于队里最大值,当大于队尾,则队尾出队(队尾是队内最小值,唯一机会是等前面的随窗口滑动被移出队列而成为最大值上位)while (queue.length > 0 && num[i] > num[queue[queue.length-1]]) {queue.pop()}//指针到的值小于队里最大值,且小于等于队尾,加入队尾行列,等机会上位queue.push(i)}//根据窗口大小,当指针下标大于等于size-1时,才开始最大值输入,指针每移动一次,一个最大值if (i >= size - 1) {max.push(num[queue[0]])}}return max}
20. 有效的括号
给定一个只包括 ‘(‘,’)’,’{‘,’}’,’[‘,’]’ 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
左括号必须用相同类型的右括号闭合。
左括号必须以正确的顺序闭合。
// 解法一let isValid = function(s) {let stack = [], length = s.length;if(length % 2) return false;for(let item of s){switch(item){case "{":case "[":case "(":stack.push(item);break;case "}":if(stack.pop() !== "{") return false;break;case "]":if(stack.pop() !== "[") return false;break;case ")":if(stack.pop() !== "(") return false;break;}}return !stack.length;};// 解法二var isValid = function(s) {s = s.split('');let sl = s.length;if (sl % 2) return false;let map = new Map([[')', '('], [']', '['], ['}', '{']]);let stack = [];for(let i of s){if (map.get(i)) {if (stack[stack.length - 1] !== map.get(i)) return false;else stack.pop();} else {stack.push(i);}}return !stack.length;};
394. 字符串解码
给定一个经过编码的字符串,返回它解码后的字符串。
编码规则为: k[encoded_string],表示其中方括号内部的 encoded_string 正好重复 k 次。注意 k 保证为正整数。
你可以认为输入字符串总是有效的;输入字符串中没有额外的空格,且输入的方括号总是符合格式要求的。
此外,你可以认为原始数据不包含数字,所有的数字只表示重复的次数 k ,例如不会出现像 3a 或 2[4] 的输入。
const decodeString = (s) => {let numStack = []; // 存倍数的栈let strStack = []; // 存待拼接的str的栈let num = 0; // 倍数的“搬运工”let result = ''; // 字符串的“搬运工”for (const char of s) { // 逐字符扫描if (!isNaN(char)) { // 遇到数字num = num * 10 + Number(char); // 算出倍数 可能不是个位数} else if (char == '[') { // 遇到 [strStack.push(result); // result串入栈result = ''; // 入栈后清零numStack.push(num); // 倍数num进入栈等待num = 0; // 入栈后清零} else if (char == ']') { // 遇到 ],两个栈的栈顶出栈let repeatTimes = numStack.pop(); // 获取拷贝次数result = strStack.pop() + result.repeat(repeatTimes); // 构建子串} else {result += char; // 遇到字母,追加给result串}}return result;};
215. 数组中的第K个最大元素
给定整数数组 nums 和整数 k,请返回数组中第 **k** 个最大的元素。
var findKthLargest = function(nums, k) {return nums.sort(function(a,b) {return b-a})[k-1]};
快速排序的分区方法:
const findKthLargest = (nums, k) => {const n = nums.length;const quick = (l, r) => {if (l > r) return;//递归终止条件let random = Math.floor(Math.random() * (r - l + 1)) + l; //随机选取一个索引swap(nums, random, r); //将它和位置r的元素交换,让nums[r]作为基准元素//对基准元素进行partitionlet pivotIndex = partition(nums, l, r);//进行partition之后,基准元素左边的元素都小于它 右边的元素都大于它//如果partition之后,这个基准元素的位置pivotIndex正好是n-k 则找大了第k大的数//如果n-k<pivotIndex,则在pivotIndex的左边递归查找//如果n-k>pivotIndex,则在pivotIndex的右边递归查找if (n - k < pivotIndex) {quick(l, pivotIndex - 1);} else {quick(pivotIndex + 1, r);}};quick(0, n - 1);//函数开始传入的left=0,right= n - 1return nums[n - k]; //最后找到了正确的位置 也就是n-k等于pivotIndex 这个位置的元素就是第k大的数};function partition(nums, left, right) {let pivot = nums[right]; //最右边的元素为基准let pivotIndex = left; //pivotIndex初始化为leftfor (let i = left; i < right; i++) { //遍历left到right-1的元素if (nums[i] < pivot) { //如果当前元素比基准元素小swap(nums, i, pivotIndex); //把它交换到pivotIndex的位置pivotIndex++; //pivotIndex往前移动一步}}swap(nums, right, pivotIndex); //最后交换pivotIndex和rightreturn pivotIndex; //返回pivotIndex}function swap(nums, p, q) {//交换数组中的两个元素const temp = nums[p];nums[p] = nums[q];nums[q] = temp;}
剑指 Offer 31. 栈的压入、弹出序列
输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否为该栈的弹出顺序。假设压入栈的所有数字均不相等。例如,序列 {1,2,3,4,5} 是某栈的压栈序列,序列 {4,5,3,2,1} 是该压栈序列对应的一个弹出序列,但 {4,3,5,1,2} 就不可能是该压栈序列的弹出序列。
辅助栈
考虑借用一个辅助栈 stack,模拟 压入 / 弹出操作的排列。根据是否模拟成功,即可得到结果。
关键逻辑
入栈操作: 按照压栈序列的顺序执行。
出栈操作: 每次入栈后,循环判断 “栈顶元素 === 弹出序列的当前元素” 是否成立,将符合弹出序列顺序的栈顶元素全部弹出。
由于题目规定 栈的所有数字均不相等 ,因此在循环入栈中,每个元素出栈的位置的可能性是唯一的(若有重复数字,则具有多个可出栈的位置)。因而,在遇到 “栈顶元素 === 弹出序列的当前元素” 就应立即执行出栈。
算法流程:
遍历压栈序列: 各元素记为 val ;
元素 val 入栈;
循环出栈:判断栈顶与“弹出序列”当前指针对应的元素是否一样,若 stack 的栈顶元素 === 弹出序列元素 popped[i] ,则执行出栈操作且 “弹出序列”当前指针往后移一位 i++ ;
返回值: 若 stack 为空,则此弹出序列合法。
var validateStackSequences = function(pushed, popped) {let i = 0, stack = [];for(let val of pushed) {stack.push(val);// 判断 模拟栈的栈顶元素 是否跟 popped 数组此时要弹出的元素相等,相等的话模拟栈就弹出,popped 数组对应 i 指针向后移动一位while(stack.length && stack[stack.length - 1] === popped[i]) {stack.pop();i += 1;}}// 如果在 pushed 数组全部元素都压入模拟栈后,模拟栈元素没随着 popped 清空,那么弹出序列对不上,返回 falsereturn !stack.length;};
剑指 Offer 40. 最小的k个数
输入整数数组 arr ,找出其中最小的 k 个数。例如,输入4、5、1、6、2、7、3、8这8个数字,则最小的4个数字是1、2、3、4。
function GetLeastNumbers_Solution(input, k){// write code herereturn input.sort(function(a,b) {return a-b}).slice(0,k)}
字符串
BM83 字符串变形
比如”Hello World”变形后就变成了”wORLD hELLO”。
function trans(s, n){//write code herelet s1 = s.split(' ').reverse().join(' ')let s2 = ''for (let i of s1) {if (i === i.toLowerCase()) {i = i.toUpperCase()s2 += i}else if (i === i.toUpperCase()) {i = i.toLowerCase()s2 += i}}return s2}
14. 最长公共前缀
编写一个函数来查找字符串数组中的最长公共前缀。
如果不存在公共前缀,返回空字符串 ""。
const longestCommonPrefix = function (str) {if (str.length === 1) return str[0];const lens = str.map(str => str.length); // 字符长度数组const minLen = Math.min(...lens) //最短长度const minStr = str[lens.indexOf(minLen)] //最短字符let i = 0, prefix = '';while (i < minLen) { //以最短长度为基准if (str.some(str => str[i] !== minStr[i])) {break}prefix += minStr[i]i++}return prefix};
468. 验证IP地址
var validIPAddress = function(IP) {const arr4 = IP.split(".");const arr6 = IP.split(":");if (arr4.length === 4) {if (arr4.every(part => (part.match(/^0$|^([1-9]\d{0,2})$/) && part < 256) )) {return "IPv4";}} else if (arr6.length === 8) {if (arr6.every(part => part.match(/^[0-9a-fA-F]{1,4}$/))) {return "IPv6";}}return "Neither";};//我的function solve(IP) {if (IP.indexOf('.') !== -1) {let a = 0;let s = IP.split('.');for (let i of s) {if(i.length === 0) return 'Neither';if (i.length !== 1) {if (i[0] === '0') return 'Neither'}if (Number(i)>=0 && Number(i)<=255) a++;}if (a === 4) return 'IPv4'else {return 'Neither'}}else if (IP.indexOf(':') !== -1) {let s = IP.split(':');let a = 0for (let i of s) {if (i.length === 0) return 'Neither';if(/^[A-Fa-f0-9]{1,4}$/.test(i) === true) {a++}}if (a === 8) return 'IPv6'else {return 'Neither'}}}
双指针
88. 合并两个有序数组
双指针,注意边界条件。
var merge = function (nums1, m, nums2, n) {let p0 = 0,p1 = 0;let arr = [];while (p0 < m || p1 < n) {if (p1 === n) {arr.push(nums1[p0++]);} else if (p0 === m) {arr.push(nums2[p1++]);} else {if (nums1[p0] <= nums2[p1]) {arr.push(nums1[p0++]);} else if (nums1[p0] > nums2[p1]) {arr.push(nums2[p1++]);}}}return nums1.forEach((item,index)=>nums1[index] = arr[index]);};
125. 验证回文串
给定一个字符串,验证它是否是回文串,只考虑字母和数字字符,可以忽略字母的大小写。
说明:本题中,我们将空字符串定义为有效的回文串。
var isPalindrome = function(s) {s = s.replace(/[^a-z^A-Z^0-9]/g, "").toLowerCase();let p1 = 0,p2 = s.length - 1;while(p1<Math.floor(s.length / 2)) {if(s[p1] === s[p2]) {p1++;p2--} else {return false}}return true};
剑指 Offer II 074. 合并区间
以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] 。请你合并所有重叠的区间,并返回一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间。
function merge(intervals) {let arr = []let j = 0;//对数组里的数组的第一个数排序intervals.sort((a,b) => a.start-b.start)//第一个while循环是使数组全部元素都能得到比较while (j < intervals.length) {let left = intervals[j].startlet right = intervals[j].end//第二个循环是使数组得到一个局部最大值与最小值,用left与right表示while (j < intervals.length - 1 && right >= intervals[j+1].start) {right = Math.max(right, intervals[j + 1].end)j++}//将局部最大值最小值作为一个数组压入一个数组里面arr.push(new Interval(left,right))j++}return arr}
3. 无重复字符的最长子串
给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。
滑动窗口 + 哈希表
整体思路就是左指针不动,右指针在没遇到重复字符时一直往右移动,如果遇到重复字符了就重新开始记录,即左指针移动到最近出现的一个重复字符处,重新开始记录。
- 滑动窗口用来记录最长不出现重复字符的子串的区间
- 哈希表用来记录每个字符最后(最新)出现的索引
如何判断是否有字符出现重复?
维护一个map,右指针右移时不断对遇到的字符进行记录,每次右移前都 map.has() 判断是否重复
注意
不是说遇到重复字符,左指针就无脑移动到第一个重复字符的右边,如果不先判断右指针目前所指向的当前重复字符的上一次出现位置是否在左指针右边的话,会使得记录出现错误,左右指针之间不是最长无重复子串,而是在左右指针之间会出现重复的
如果还是不了解,可以看下面例子
abba
- right = 0,首先遇到 a,没重复,long 更新为 1,同时 map.set(‘a’, 0);
- right = 1,遇到 b,没重复,long 更新为 2,同时 map.set(‘b’, 1);
- right = 2,遇到 b,重复了,同时判定 b 上一次出现位置是 1,大于等于 left,所以对 left 进行更新,更新成 2
- right = 3,遇到 a,重复了,同时判定 a 上一次出现位置是 0,此时注意,如果没有判断 0 是否 大于等于 left 这一步 会发生什么?
- 如果直接让 left 更新成 a 上一次出现位置 0 再加 1 的话,此时 left 变成 1,但很明显看出 [left, right) 区间即 [1, 3) 内有重复的 b,不符合!
- 所以得加上 map.get(s[right]) >= left 这个判定条件,右指针目前所指向的当前重复字符的上一次出现位置在左指针右边,保证滑动窗口左边界在遇到重复字符时一直能及时更新到最新状态,而不是用之前的旧状态,而导致[left, right) 区间出现重复
var lengthOfLongestSubstring = function(s) {let left = 0;let long = 0;const map = new Map(), len = s.length;for(let right = 0; right < len; right++){// 遇到重复字符时还要判定 该重复字符的上一次出现位置是否在 滑动窗口左边界 left 的右边if(map.has(s[right]) && map.get(s[right]) >= left){left = map.get(s[right]) + 1; // 都满足,则更新,更新到最近出现的那个重复字符,它的上一个索引的右边}long = Math.max(long, right - left + 1); // 比较滑动窗口大小与 long 的长度map.set(s[right], right); // 无论有没有重复,每次遍历都要更新字符的出现位置}return long;};
BM92 最长无重复子数组
给定一个长度为n的数组arr,返回arr的最长无重复元素子数组的长度,无重复指的是所有数字都不相同。
子数组是连续的,比如[1,3,5,7,9]的子数组有[1,3],[3,5,7]等等,但是[1,3,7]不是子数组
/*** 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可** @param arr int整型一维数组 the array* @return int整型*//*** 解法一:滑动窗口(reduce累加器)* 此题与leetcode 003 题类似* 思路:* (1)先判断数组 arr 的长度,如果 arr.length <= 1 直接返回 arr.length* (2)使用数组的 reduce 累加器,滑动窗口过程处理(详细过程看以下代码)* (3)返回最长无重复子数组的长度 maxLen* 时间复杂度:O(n),n 代表数组长度,reduce 会将数组遍历一遍* 空间复杂度:O(1)*/export function maxLength(arr: number[]): number {if (arr.length <= 1) return arr.lengthlet maxLen = 0arr.reduce((total, value) => {const index = total.indexOf(value)// push 到 total 尾部total.push(value)if (index === -1) {// 如果该数字没有在 total 中出现过,获取目前为止滑动窗口的最大值maxLen = Math.max(total.length, maxLen)} else {// 如果该数字有在 total 中出现过,则剔除掉 total 中 0 ~ index 的字符total = total.slice(index + 1)}return total}, [])return maxLen}/*** 解法二:滑动窗口(双指针&哈希)* 思路:* (1)先判断数组 arr 的长度,如果 arr.length <= 1 直接返回 arr.length* (2)窗口左右界都从数组首部开始,每次窗口优先右移右界,并统计进入窗口的元素的出现频率。* (3)一旦右界元素出现频率大于1,就需要右移左界直到窗口内不再重复,将左边的元素移除窗口的时候* 同时需要将它在哈希表中的频率减1,保证哈希表中的频率都是窗口内的频率。* (4)每轮循环维护最长子串的长度 maxLen* 时间复杂度:O(n),外循环窗口右界从数组首右移到数组尾,内循环窗口左界同样如此,因此复杂度为O(n + n) = O(n)* 空间复杂度:O(n),最坏情况整个数组都是不重复的,哈希表的长度就是数组长度*/export function maxLength(arr: number[]): number {if (arr.length <= 1) return arr.lengthlet maxLen = 0const map = new Map()// 设置窗口左右边界for (let left = 0, right = 0; right < arr.length; right++) {if (map.has(arr[right])) {// 窗口右移进入哈希表统计次数map.set(arr[right], map.get(arr[right]) + 1)} else {map.set(arr[right], 1)}// 出现次数大于1,则窗口内有重复while (map.get(arr[right]) > 1) {// 窗口左移,同时减去该数字出现的次数map.set(arr[left], map.get(arr[left++]) - 1)}maxLen = Math.max(maxLen, right - left + 1)}return maxLen}
11. 盛最多水的容器
给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。
找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
返回容器可以储存的最大水量。
思路:用双指针i,j循环height数,i,j对应高度较小的那个先向内移动,不断计算面积,更新最大面积
复杂度:时间复杂度O(n),n是数组height的长度,遍历一次。空间复杂度O(1)
var maxArea = function(height) {let max = 0;for (let i = 0, j = height.length - 1; i < j;) {//双指针i,j循环height数组//i,j较小的那个先向内移动 如果高的指针先移动,那肯定不如当前的面积大const minHeight = height[i] < height[j] ? height[i++] : height[j--];const area = (j - i + 1) * minHeight;//计算面积max = Math.max(max, area);//更新最大面积}return max;};
42. 接雨水
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
知识点:双指针
双指针指的是在遍历对象的过程中,不是普通的使用单个指针进行访问,而是使用两个指针(特殊情况甚至可以多个),两个指针或是同方向访问两个链表、或是同方向访问一个链表(快慢指针)、或是相反方向扫描(对撞指针),从而达到我们需要的目的。
思路:
我们都知道水桶的短板问题,控制水桶水量的是最短的一条板子。这道题也是类似,我们可以将整个图看成一个水桶,两边就是水桶的板,中间比较低的部分就是水桶的底,由较短的边控制水桶的最高水量。但是水桶中可能出现更高的边,比如上图第四列,它比水桶边还要高,那这种情况下它是不是将一个水桶分割成了两个水桶,而中间的那条边就是两个水桶的边。
有了这个思想,解决这道题就容易了,因为我们这里的水桶有两个边,因此可以考虑使用对撞双指针往中间靠。
具体做法:
- step 1:检查数组是否为空的特殊情况
- step 2:准备双指针,分别指向数组首尾元素,代表最初的两个边界
- step 3:指针往中间遍历,遇到更低柱子就是底,用较短的边界减去底就是这一列的接水量,遇到更高的柱子就是新的边界,更新边界大小。
//双指针//某一列能接的雨水量。取决于 左边最高和右边最高中较小的那个减去当前列的高度function maxWater( arr ) {let leftMax=0,rightMax=0;let left=0,right=arr.length-1;let res=0;while(left<right){leftMax=Math.max(leftMax,arr[left]);//每开始一个循环就要更新最大值rightMax=Math.max(rightMax,arr[right]);if(arr[left]<arr[right]){//left<right可以推出leftMax<rightMaxres+=leftMax-arr[left];//雨水等于较小的那个Max减去当前高度left++;}else{res+=rightMax-arr[right];//此时较小的那个就是rightMaxright--;}}return res;}
76. 最小覆盖子串
给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 "" 。
方法一:滑动窗口
本问题要求我们返回字符串 s 中包含字符串 t 的全部字符的最小窗口。我们称包含 t 的全部字母的窗口为「可行」窗口。
我们可以用滑动窗口的思想解决这个问题。在滑动窗口类型的问题中都会有两个指针,一个用于「延伸」现有窗口的 r 指针,和一个用于「收缩」窗口的 l 指针。在任意时刻,只有一个指针运动,而另一个保持静止。我们在 s 上滑动窗口,通过移动 r 指针不断扩张窗口。当窗口包含 t 全部所需的字符后,如果能收缩,我们就收缩窗口直到得到最小窗口。

如何判断当前的窗口包含所有 t 所需的字符呢?我们可以用一个哈希表表示 t 中所有的字符以及它们的个数,用一个哈希表动态维护窗口中所有的字符以及它们的个数,如果这个动态表中包含 t 的哈希表中的所有字符,并且对应的个数都不小于 t 的哈希表中各个字符的个数,那么当前的窗口是「可行」的。
function minWindow( S , T ) {// write code herelet l = 0, r = 0;let lent = T.length;let lens = S.length;//用一个map存储需要的字符数,可能有重复字符所以要先判断有没有,有就加一const map = new Map();for(let i = 0;i<lent;i++){map.set(T[i],map.has(T[i]) ? map.get(T[i])+1 : 1);}let len = map.size;let res = '';//不断移动右指针while(r<lens){//取得当前元素const nowc = S[r];//如果map里有就将map对应元素减一if(map.has(nowc)){map.set(nowc,map.get(nowc)-1);//因为可能有重复字符(xxx->x:3),所以要判断这一字符是否取完,取完就将len减一,size没变if(map.get(nowc)==0){len--;}}//如果len为0说明取得t中所有字符while(len === 0){//每次移动左指针,取得包含所有字符的子串let newstr = S.slice(l,r+1);//如果没有结果或者结果的长度大于子串的长度,则用子串覆盖成为新结果if(!res || res.length > newstr.length) res = newstr;//当前左指针元素let nowl = S[l];//如果左指针移动过程中map里有对应元素if(map.has(nowl)){//将map对应元素加1map.set(nowl,map.get(nowl)+1);//并更新lenif(map.get(nowl)===1){len++;}}//移动左指针,寻找最小的子串,因为可能出现重复元素l++;}//当前元素不在map中则继续移动右指针r++;}return res;}
哈希表
1. 两数之和
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
var twoSum = function(nums, target) {for(let i = 0; i < nums.length; i++) {for(let j = i + 1; j < nums.length; j++) {if(nums[i] + nums[j] == target) {return [i,j]}}}};
解题思路
知识点:
map对象中存放的是{key,value}键值对;
has(key)方法判断map中是否存在key,返回boolen值;
get(key)方法返回map中的value值;
解题过程:
1.用map来存放{数组元素值,坐标}这样的键值对
2.运用逆向解法,即用target减去数组中的某个元素,然后来判断map中是否有相同的值,若有则存在满足条件的答案,返回两个坐标即可;若没有,则保存{数组中某个元素值,对应的坐标}到map对象中。依次遍历即可判断是否有满足条件的两个元素。
var twoSum = function(nums, target) {map = new Map()for(let i = 0; i < nums.length; i++) {x = target - nums[i]if(map.has(x)) {return [map.get(x),i]}map.set(nums[i],i)}};
剑指 Offer II 070. 排序数组中只出现一次的数字
给定一个只包含整数的有序数组 nums ,每个元素都会出现两次,唯有一个数只会出现一次,请找出这个唯一的数字。
var singleNonDuplicate = function(array) {let map = new Map();let num = 0;for (let i = 0; i < array.length; i++) {if (map.has(array[i])) {map.set(array[i],map.get(array[i])+1)} else {map.set(array[i],1)}}map.forEach((value, key)=>{if (value === 1) {num = key}})return num};
缺失的第一个正整数
方法一:哈希表
给定一个未排序的整数数组nums,请你找出其中没有出现的最小的正整数
- step 1:构建一个哈希表,用于记录数组中出现的数字。
- step 2:从1开始,遍历到n,查询哈希表中是否有这个数字,如果没有,说明它就是数组缺失的第一个正整数,即找到。
- step 3:如果遍历到最后都在哈希表中出现过了,那缺失的就是n+1.
- 时间复杂度:O(n),第一次遍历数组,为O(n),第二次最坏从1遍历到n,为O(n)
- 空间复杂度:O(n),哈希表记录n个不重复的元素,长度为n
function minNumberDisappeared( nums ) {// write code herelet map = new Map();for (let i = 0; i < nums.length; i++) {map.set(nums[i],1)};let res = 1;while (map.has(res)) res++return res}
方法二:原地哈希(扩展思路)
思路:
前面提到了数组要么缺失1~n中的某个数字,要么缺失n+1,而数组正好有下标0~n−1可以对应数字1~n,因此只要数字1~n中某个数字出现,我们就可以将对应下标的值做一个标记,最后没有被标记的下标就是缺失的值。
具体做法:
- step 1:我们可以先遍历数组将所有的负数都修改成n+1。
- step 2:然后再遍历数组,每当遇到一个元素绝对值不超过n时,则表示这个元素是1~n中出现的元素,我们可以将这个数值对应的下标里的元素改成负数,相当于每个出现过的正整数,我们把与它值相等的下标都指向一个负数,这就是类似哈希表的实现原理的操作。
- step 3:最后遍历数组的时候碰到的第一个非负数,它的下标就是没有出现的第一个正整数,因为它在之前的过程中没有被修改,说明它这个下标对应的正整数没有出现过。
- 时间复杂度:O(n)
- 空间复杂度:O(1)

var firstMissingPositive = function(nums) {let n = nums.lengthfor(let i = 0; i < n; i++) {if(nums[i] <= 0) {nums[i] = n + 1}};for(let i = 0; i < n; i++) {if(Math.abs(nums[i]) <= n) {//如果遇到重复的数字,它对应索引加一的元素有可能已经被改为负值,所以再加个绝对值nums[Math.abs(nums[i])-1] = -Math.abs(nums[Math.abs(nums[i])-1]);}}console.log(nums)for(let i = 0; i < n; i++) {if(nums[i] > 0) {return i+1}}return n+1};
15. 三数之和
给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?请你找出所有和为 0 且不重复的三元组。
思路
- 首先对数组进行排序,排序后固定一个数 nums[i],再使用左右指针指向 nums[i]后面的两端,数字分别为 nums[L] 和 nums[R],计算三个数的和 sum 判断是否满足为 0,满足则添加进结果集
- 如果 nums[i]大于 0,则三数之和必然无法等于 0,结束循环
- 如果 nums[i] == nums[i−1],则说明该数字重复,会导致结果重复,所以应该跳过
- 当 sum == 0 时,nums[L] == nums[L+1] 则会导致结果重复,应该跳过,L++
当 sum == 0 时,nums[R] == nums[R−1] 则会导致结果重复,应该跳过,R—R−−
时间复杂度:O(n2),n 为数组长度
var threeSum = function(nums) {let ans = [];const len = nums.length;if(nums == null || len < 3) return ans;nums.sort((a, b) => a - b); // 排序for (let i = 0; i < len ; i++) {if(nums[i] > 0) break; // 如果当前数字大于0,则三数之和一定大于0,所以结束循环if(i > 0 && nums[i] == nums[i-1]) continue; // 去重let L = i+1;let R = len-1;while(L < R){const sum = nums[i] + nums[L] + nums[R];if(sum == 0){ans.push([nums[i],nums[L],nums[R]]);while (L<R && nums[L] == nums[L+1]) L++; // 去重while (L<R && nums[R] == nums[R-1]) R--; // 去重L++;R--;}else if (sum < 0) L++;else if (sum > 0) R--;}}return ans;};
模拟
BM97 旋转数组
一个数组A中存有 n 个整数,在不允许使用另外数组的前提下,将每个整数循环向右移 M( M >=0)个位置,即将A中的数据由(A0 A1 ……AN-1 )变换为(AN-M …… AN-1 A0 A1 ……AN-M-1 )(最后 M 个数循环移至最前面的 M 个位置)。如果需要考虑程序移动数据的次数尽量少,要如何设计移动的方法?
function solve( n , m , a ) {// write code herem = m%nreturn a.slice(n-m).concat(a.slice(0,n-m))}
54. 螺旋矩阵
具体做法:
- step 1:首先排除特殊情况,即矩阵为空的情况。
- step 2:设置矩阵的四个边界值,开始准备螺旋遍历矩阵,遍历的截止点是左右边界或者上下边界重合。
- step 3:首先对最上面一排从左到右进行遍历输出,到达最右边后第一排就输出完了,上边界相应就往下一行,要判断上下边界是否相遇相交。
- step 4:然后输出到了右边,正好就对最右边一列从上到下输出,到底后最右边一列已经输出完了,右边界就相应往左一列,要判断左右边界是否相遇相交。
- step 5:然后对最下面一排从右到左进行遍历输出,到达最左边后最下一排就输出完了,下边界相应就往上一行,要判断上下边界是否相遇相交。
- step 6:然后输出到了左边,正好就对最左边一列从下到上输出,到顶后最左边一列已经输出完了,左边界就相应往右一列,要判断左右边界是否相遇相交。
- step 7:重复上述3-6步骤直到循环结束。
function spiralOrder(matrix) {const res = []if (matrix.length === 0) return reslet left = 0let right = matrix[0].length - 1let up = 0let down = matrix.length - 1while (left <= right && up <= down) {for (let i = left; i <= right; i++) res.push(matrix[up][i])// 收缩上边界up++if (up > down) breakfor (let i = up; i <= down; i++) res.push(matrix[i][right])// 收缩右边界right--if (left > right) breakfor (let i = right; i >= left; i--) res.push(matrix[down][i])// 收缩下边界down--if (up > down) breakfor (let i = down; i >= up; i--) res.push(matrix[i][left])// 收缩左边界left++if (left > right) break}return res}
面试题 01.07. 旋转矩阵
- 通过观察我们可以知道
顺时针旋转90°就是将原本的第i行换到倒数第i列的位置 - 我们可以使用一个辅助数组
tmp来完成 - 时间复杂度On^2 ,空间复杂度On^2
function rotateMatrix( mat , n ) {let tmp = []let k = nwhile(k--){tmp.push([])}for(let i = n - 1 ; i >= 0 ; i--){for(let j = 0 ; j < n ; j++){tmp[j].push(mat[i][j])}}return tmp}
var rotate = function(matrix) {// 时间复杂度O(n^2) 空间复杂度O(1)// 做法: 先沿着对角线翻转,然后沿着水平线翻转const n = matrix.length;function swap(arr, [i, j], [m, n]) {const temp = arr[i][j];arr[i][j] = arr[m][n];arr[m][n] = temp;}for (let i = 0; i < n - 1; i++) {for (let j = 0; j < n - i; j++) {swap(matrix, [i, j], [n - j - 1, n - i - 1]);}}for (let i = 0; i < n / 2; i++) {for (let j = 0; j < n; j++) {swap(matrix, [i, j], [n - i - 1, j]);}}};

若有收获,就点个赞吧
0 人点赞
