大数据概述
- 大数据的特征:海量、高增长率、多样化
- 大数据的处理思路:分而治之
- 云计算与大数据:云计算提供基础设施,大数据则是在其上运行的应用
- 大数据的4V:体量巨大(Volume)、种类繁多(Variety)、价值密度低(Value)、处理速度快(Velocity)
开源大数据平台Hadoop

HDFS文件系统
分布式文件系统
- 适合海量数据批处理和存储
- 一次性写入,多次读取
- 保证数据一致性
- 多副本存储
MapReduce
MR的五个阶段,Split-Map-Combine-Shuffle/Sort-Reduce。
Hive
基于Hadoop的数据仓库工具,可用于构建离线数仓。
HBase

Spark
用于大数据量下的迭代式计算
- Spark SQL:提供了类SQL的查询,返回Spark-Dataframe。
- Mllib:提供机器学习的各种模型和调优。
- Spark Streaming:流式计算,主要用于处理线上实时时序数据。
- GraphX:提供基于图的算法。
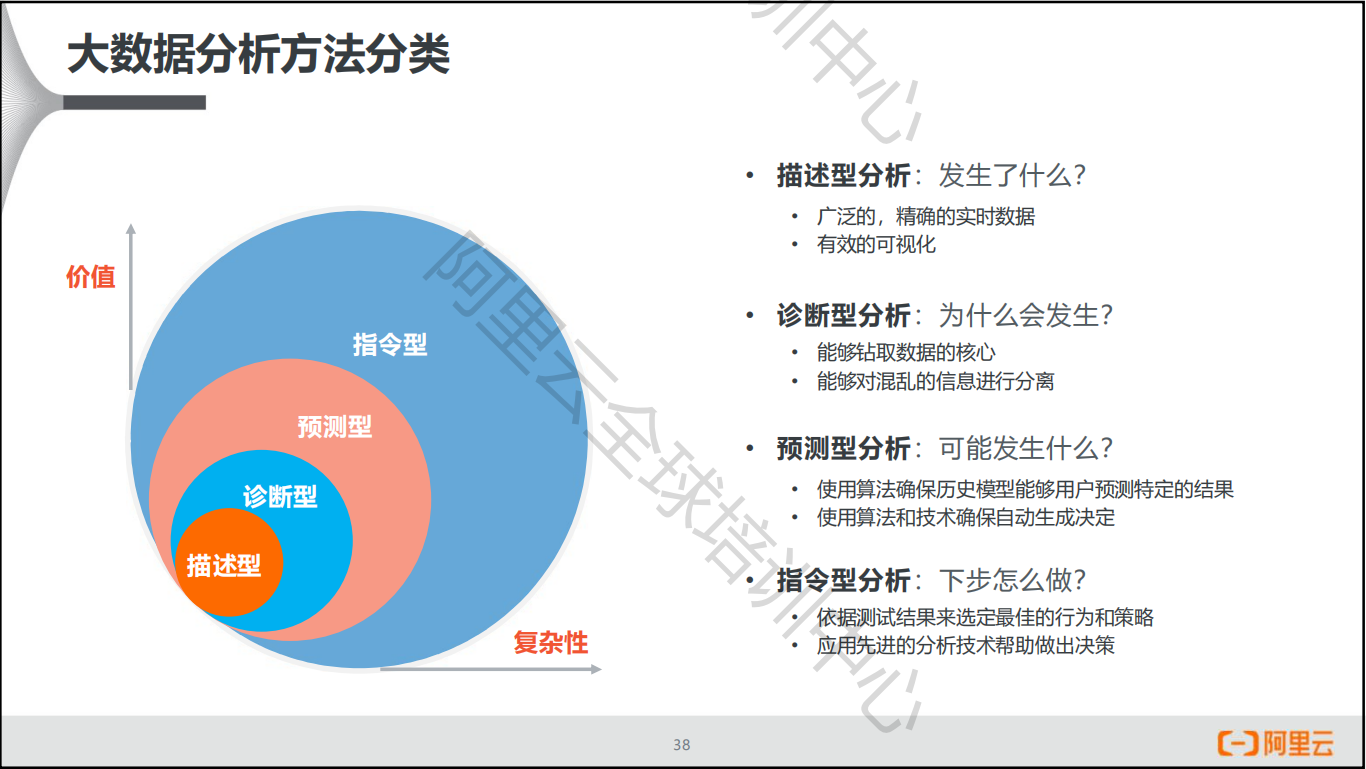
大数据分析概述
概念
基于商业目的,有目的的进行收集、整理、加工和分析数据,提炼有价值信息的过程。
分析方法分类
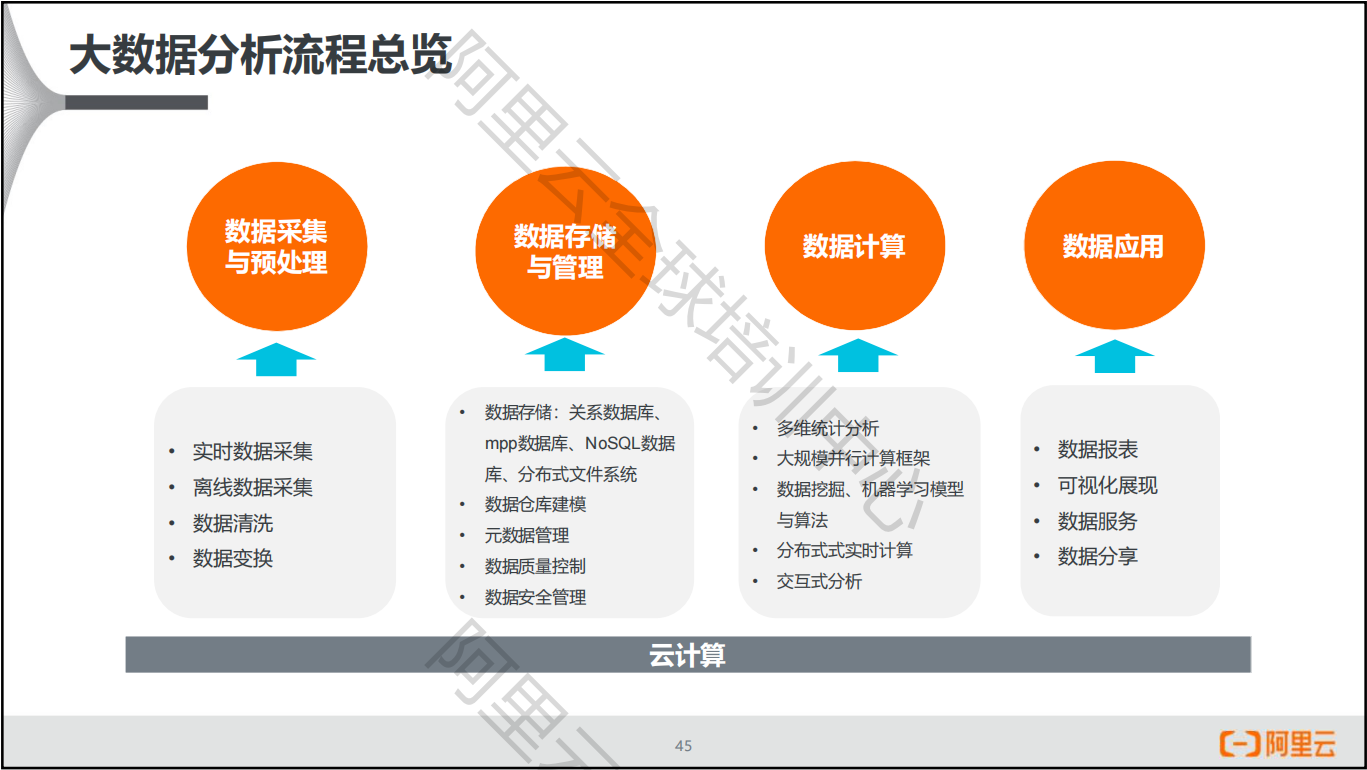
大数据分析的流程
大数据采集技术
- WEB端:基于爬虫/API获取的日志
- APP端:基于采集SDK/埋点获取的日志
- 传感器:物联网测量值转化为数字信号
- 数据库:源业务系统数据同步
- 第三方数据
数据清洗
针对原始数据,对出现的噪声进行修复、平滑或者剔除
噪声数据处理
- 异常值:箱线图、Tukey’s Test等
- 删除、当做缺失值、忽略
- 分箱发:箱均匀、箱中位数或箱边界、平滑数据
- 缺失值
- 统计值填充:均值、众数、中位数
- 固定值填充
- 最接近记录值填充:与该样本最接近的相同字段值
- 模型拟合补充:填充回归或其他模型预测值
- 插值填充:建立插值韩束,如拉格朗日插值法、牛顿插值法等
大数据存储
- 单硬盘存储:使用一块硬盘存储数据
- 磁盘阵列(RAID):在单机上使用多块硬盘均匀存储数据
- 分布式存储:使用多台机器基于网络连接存储数据
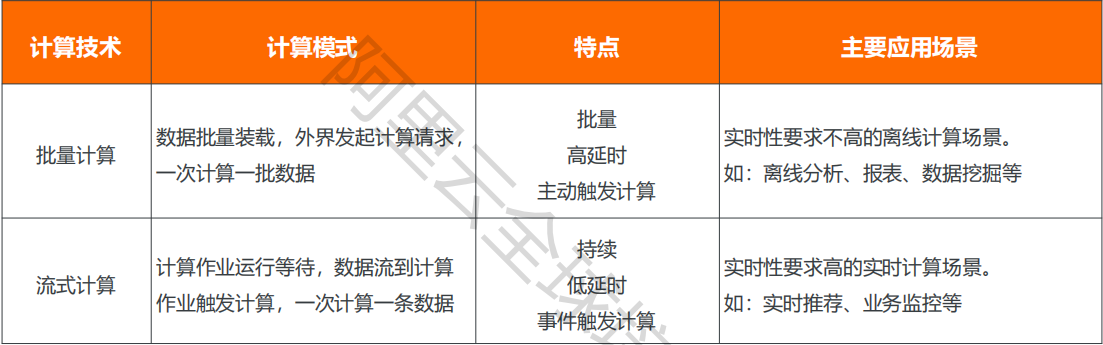
大数据计算
大数据可视化
Quick BI、Tableau、QlikView
大数据分析的技术工具与统计基础
- 数据库系统的构成:支持数据库运行的软、硬件环境;数据库;数据库管理系统;用户
- 数据库设计的三范式
- 1NF:原子性
- 2NF:唯一性
- 3NF:独立性
关系模型
- 关系:一张二维表,每个关系有一个关系名
- 元组:水平方向的行
- 属性:垂直方向的列
- 域:属性的取值范围
- 主键:是指表中的某些属性可以唯一的确定一个元组
- 外键:用于与其他表关联的某些属性
- 约束:主键约束、外键约束、唯一性约束、检查约束、缺省约束
数据仓库
面向主体的、集成的、随着时间变化的、用于管理决策支持的数据集合。
数据仓库的特点
- 面向主题:基于某个明确主体,仅需要与该主题相关的数据
- 集成:从不同的数据源采集数据到同一个数据源,一致的命名约定、格式和编码结构
- 随时间变化:关键数据隐式或显式地基于时间变化,可以研究趋势和变化
- 不可改变:只读,定期刷新。数据仓库的数据反映的是一段相当长的时间内历史数据的内容。
数据仓库模型
常见会分为星型模型和雪花模型
- 星型模型:维度表只和事实表关联
- 雪花模型:相当于将星型模型的大维度表拆成小维度表,满足规范化设计,但实际应用中很少见,数仓中可接受一定的冗余存在。
ETL流程
抽取(Extract)-清洗(Transform)-加载(Load)-转换-规则
OLTP与OLAP
OLTP:在线交易处理系统
- 主要记录事务的更新、插入、删除。
- 查询更简单,更短
- 经常更新
- 规范化表(3NF)
- 数据处理可能会在中间失败,可能会影响数据完整性
OLAP:在线分析处理系统
- OLAP数据库存储OLTP输出的历史数据
- 允许用户执行复杂查询
- 即使数据处理失败也不会损害数据完整性
- OLAP执行的任务花费时间更多
- OLAP事务较少,且不会符合3NF
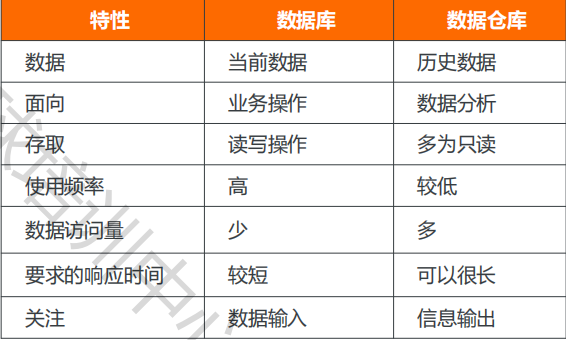
数据库与数据仓库的区别
- 数据库是面向事务的设计,数据仓库是面向主体设计的
- 数据库尽量避免冗余,数据仓库有意引入冗余
- 数据库为捕获数据而设计,数据库为分析数据而设计
大数据分析所需的统计知识框架
- 基本概念:总体/样本、参数/统计量、变量、频率/概率
- 数据的概括性度量
- 集中趋势:众数、中位数、平均数、分位数
- 离散趋势:方差/标准差、极差、四分位差、变异系数
- 常见的概率分布
- 离散型分布:二项分布、泊松分布
- 连续型分布:正态分布、均匀分布、指数分布
- 假设检验:p-value、两类错误、置信区间
基本概念
- 总体与样本:总体是考察对象的全体,样本是观测或调查的一部分个体
- 随机变量:设
 为某随机现象的样本空间,称定义在
为某随机现象的样本空间,称定义在 上的实值函数
上的实值函数 为随机变量
为随机变量 - 随机变量的类型:离散型与连续型
- 若随机变量可能取值的个数为有限个或可列个,则称X为离散随机变量
- 若随机变量X的可能取值充满某个区间[a,b],则称X为连续随机变量
- 频率与概率:概率是某一事件发生的可能性,频率是通过实验得出的概率的估计值
- 概率的基本性质:
- 非负性:对任意事件,概率总是分布在[0,1]的区间内
- 正则性:事件不同情况发生概率的总和等于1
- 可列可加性:互斥事件的概率满足加法式
- 概率分布:用于表述随机变量取值的概率规律
- 概率分布函数:设X为一个随机变量,对任意实数x,称
 为X的分布函数
为X的分布函数
数据的概括性度量
通常从两个角度了解数据的状况
集中趋势:用来描述一组数据向某一中心值靠拢集中的程度。主要包括以下测量值
- 平均数:算术平均数、几何平均数、调和平均数、加权众数
- 中位数:将一组数据按一定顺序排列后,处于中间位置上的变量值
- 分位数:衡量数据位置的测定指标,主要包括上四分位数、下四分位数
离散趋势:反映变量远离集中趋势测量值的程度,主要包括以下测量值
- 极差:一组数据最大值和最小值的差,容易受极端值影响
- 四分位差:上四分位置和下四分位值的差,反映50%数据的离散程度
- 方差与标准差:反映一个数据与本组数据平均值相比相差的数值
- 变异系数:原始数据标准差和原始数据平均数的比,常用来比较两组不同数据的离散程度
常见的概率分布
常见的离散型分布:
- 二项分布
- 泊松分布
常见的连续型分布:
- 正态分布
- 均匀分布
- 指数分布
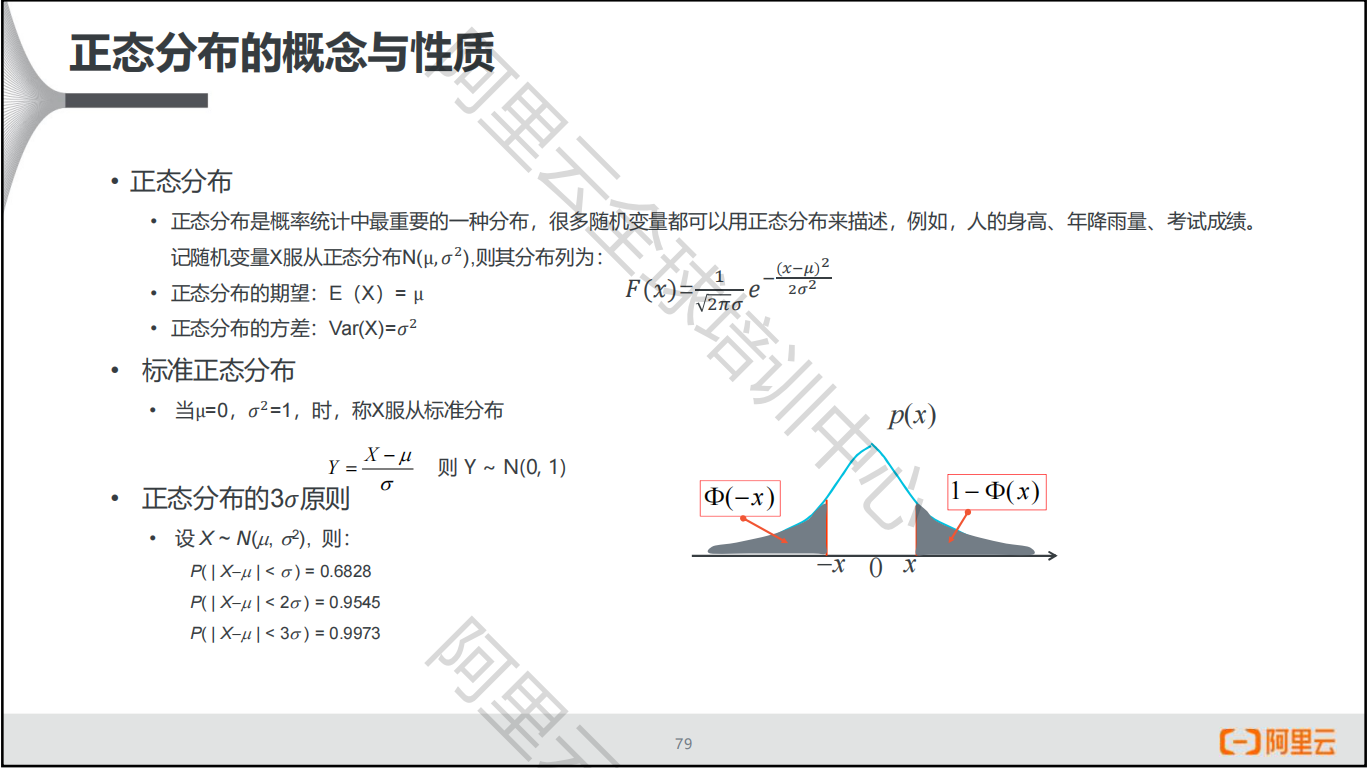
正态分布的概念与性质
假设检验
根据样本的信息检验关于总体的某个假设是否正确,这类问题称作假设检验问题。
- 有两个假设,一个叫原假设、另一个叫备择假设,检验过程从假设原假设是正确的开始。
- P-value是一种在原假设为真的前提下出现观察样本以及更极端情况的概率,也叫显著性水平
- 置信区间为在某显著性水平下,样本总体某个参数的可接受范围
- 在任何的检验中,有两类错误。第一类是原假设正确却拒绝它,第二类错误是当原假设不正确时却未能拒绝

若有收获,就点个赞吧
0 人点赞
