什么是机器学习
机器学习是指在不直接针对问题进行编程的情况下,赋予计算机学习能力的一个研究领域。
机器学习方法整体流程
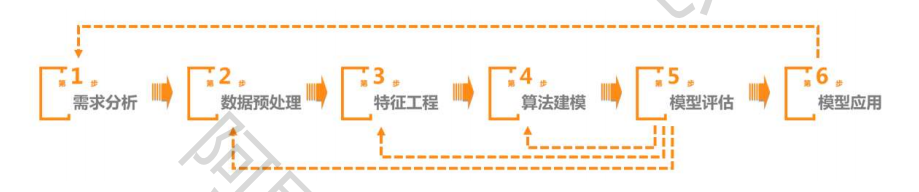
需求分析
需求分析需要确定机器学习项目的具体需求,包括:
- 场景分析
- 数据收集
- 数据探查
- 算法选择
数据预处理
- 数据清洗:针对原始数据,对出现的噪声进行处理
- 异常值处理:删除、分箱,对数据进行平滑
- 缺失值:统计值、固定值、最接近记录值填充
数据变换
常见的变换方法:
- 使用简单函数进行变换
- 数据规范化
- 连续值离散化
特征工程
基于原始数据创建新的特征的过程,一般情况下结合业务,利用数学方法在原有特征的基础上,进行新增、转换等,使特征更适合于机器学习的需要。
模型训练
使用已有的数据输入到选定的模型(算法),调整其参数,使模型的性能和效率可以接受。
模型评估
从不同维度去评估模型,具体的评价维度依赖于模型的类型和模型的应用场景。
机器学习算法分类
根据学习方式分类
- 监督式学习:学习样本中有结果标记
- 无监督学习:学习样本中无结果标记
- 半监督学习:学习样本中有部分结果标记
监督式机器学习
分类
通过已有数据集(训练集)的学习,得到一个目标函数F(模型),把每个属性集x映射到目标属性y(类),且y必须是离散的(若y为连续的,则属于回归算法)。通过对已知类别训练集的分析,从中发现分类规则,以此预测新数据的类别。
例:已有部分用户是否会购买电脑的记录,据此去建模,来预测某个新用户是否购买。即分成两类:购买和不购买。
回归
回归是处理两个或两个以上变量之间互相依赖的定量关系的一种统计方法和技术,变量之间的关系并非确定的韩束关系,通过一定的概率分布来描述。
线性回归
在回归分析中,如果自变量和因变量之间存在着线性关系,则被称作线性回归。如果只有一个因变量一个自变量,则被称为一元线性回归,如果有一个因变量多个自闭哪里,则被称作多元回归。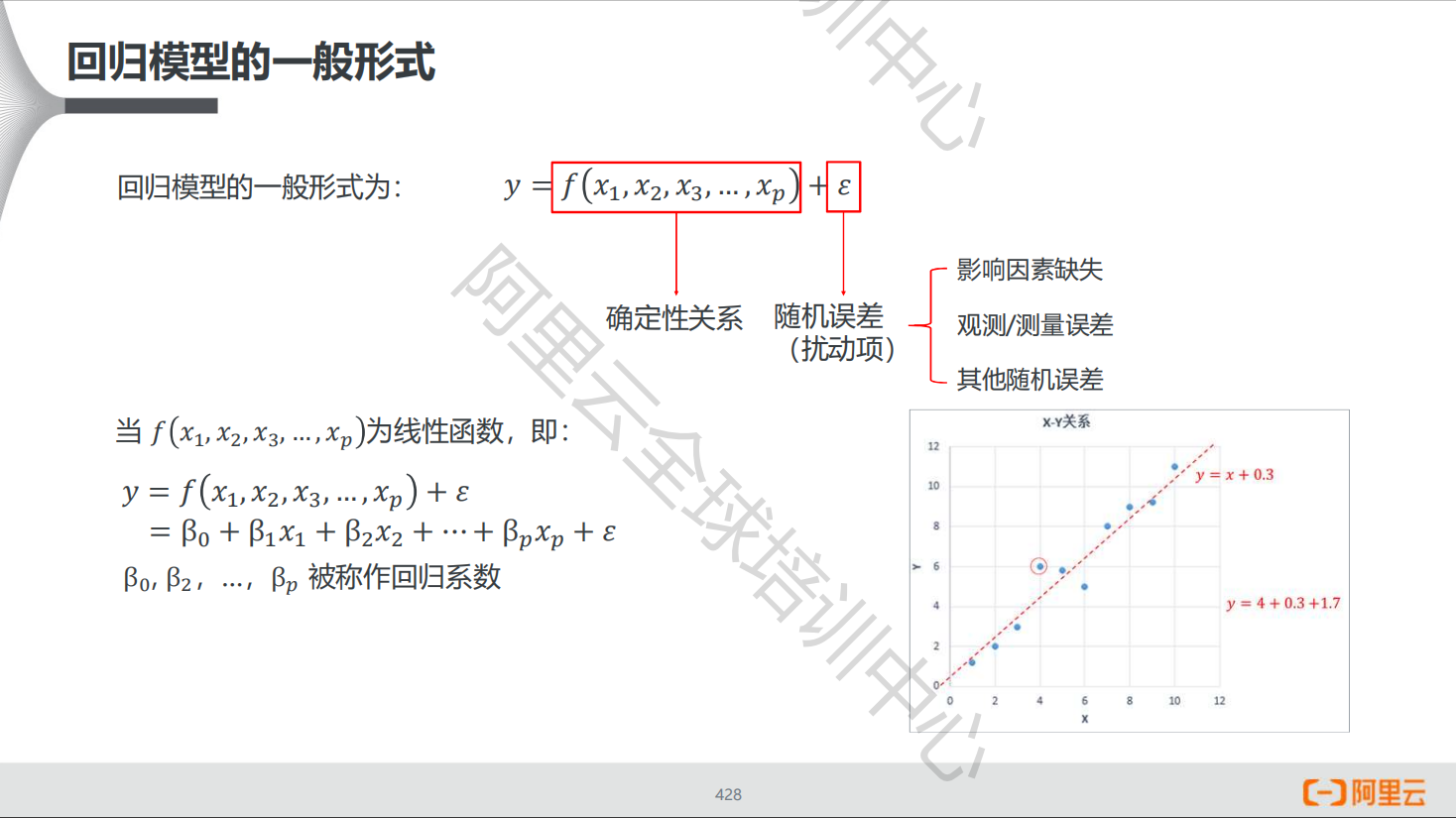
回归模型的特点
回归模型的优点有:
- 模型简单,建模和应用都比较容易
- 有坚实的统计理论支撑
- 定量分析各变量之间的关系
- 模型预测结果可以通过误差分析精确了解
回归模型的缺点:
- 假设条件比较多且相对严格
- 变量选择对模型影响较大
KNN(K近邻)


决策树算法
定义
以事例为基础的归纳学习算法,着眼于从一组无次序,无规则的事例中推导出决策的分类规则,由于这种决策分支图形很像一棵树的枝干,故称决策树。
决策树的构建流程
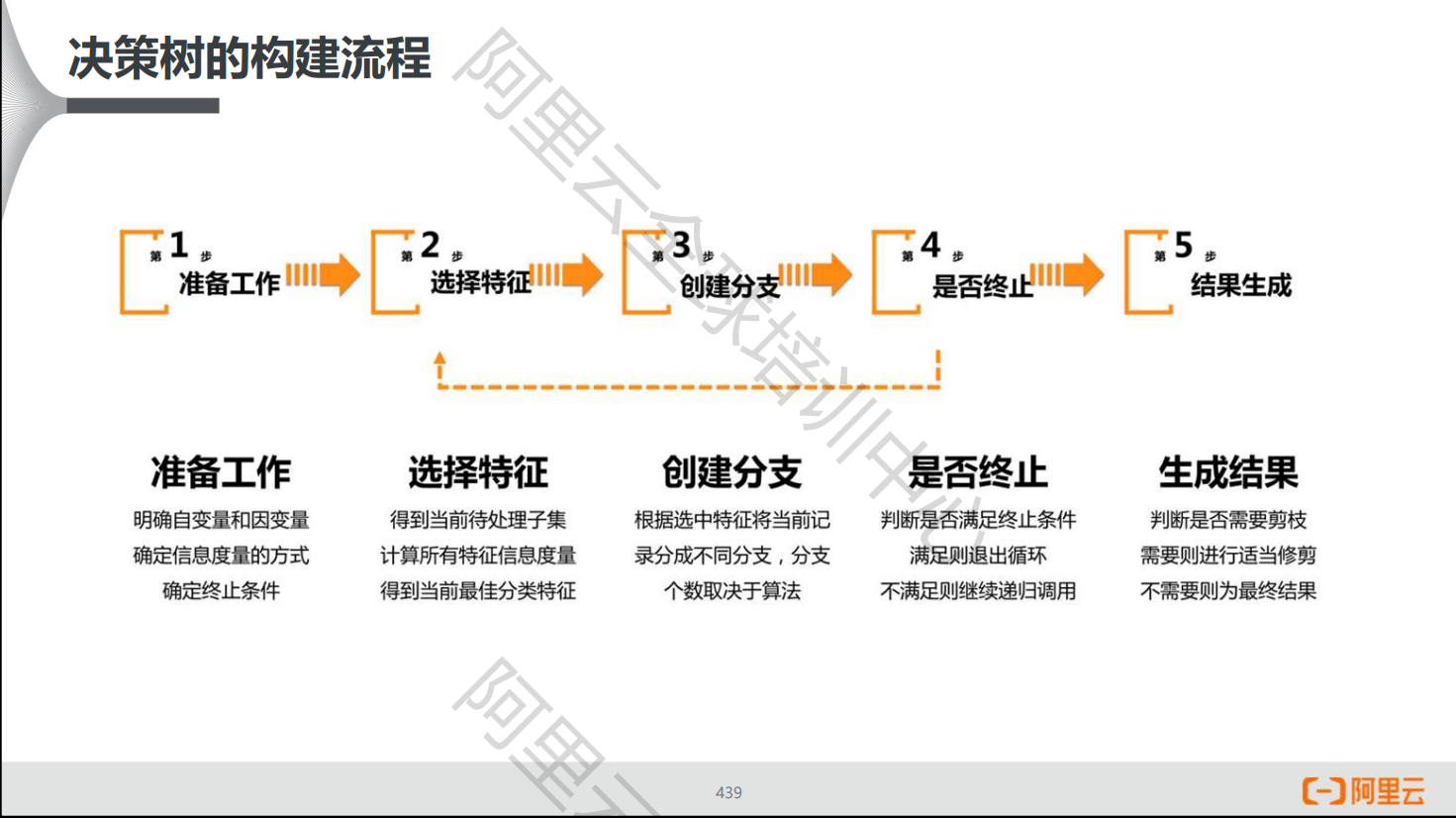
决策树的相关概念
- 观察数据,明确自变量和因变量
- 明确信息度量方式:信息增益
- 明确分支终止条件
信息熵

信息增益
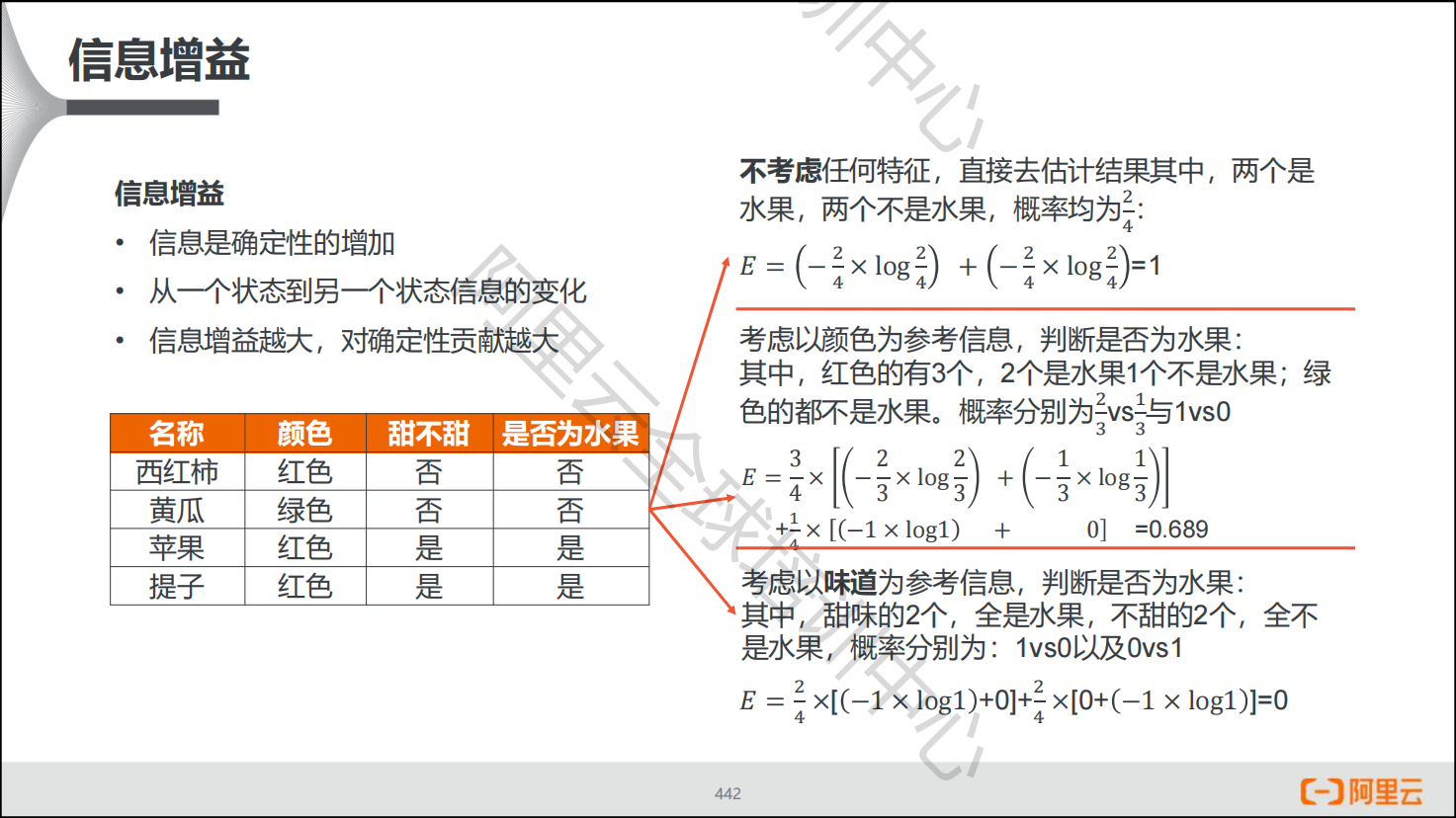
实例
- 第一级特征选择,计算整体的熵
ID3系列算法

分类回归树CART

无监督机器学习
聚类的定义
聚类是指从无标签的数据中,找出某种结构。换言之,将在某些方面比较相似的成员组织到组中,整体数据最终会被分成多个不同的组别。其中,同一个组内的成员相似,不同组内的成员相异。
关联规则的定义
关联规则是反映事物与事物间相互的依存关系和关联性。如果两个或多个事物间存在一定的关联关系,则其中一个事物能够通过其他事物预测到。最常见的场景就是购物篮分析,通过分析顾客购物篮中的不同商品之间的关系,来分析顾客的购买习惯,经典案例就是啤酒与尿布。
K-Means算法

K-means算法的优缺点

Apriori算法
https://blog.csdn.net/zhazhayaonuli/article/details/53322541

若有收获,就点个赞吧
0 人点赞
