
环境配置:
安装python;
新建项目文件夹;
安装虚拟环境;(和项目绑定,可以使用pipenv或者virtualenvwrapper,这里的前提是这俩工具都要提前pip install,install完了就能使用了,老师这里使用的是pipenv,在项目文件夹下执行pipenv install)
pipenv shell进行激活虚拟环境【使用pip list可以看虚拟环境下的库】
使用pipenv install安装库
pipenv
pipenv简单命令
进入虚拟环境:pipenv shell退出虚拟环境命令:exit安装虚拟环境内的库:pipenv install卸载虚拟环境内的库:pipenv uninstall查看依赖包:pipenv graphpipenv --venv
第一个简单的flask小程序
fisher.py
from flask import Flaskapp = Flask(__name__)@app('/hello/')#路由的概念,这里的后面的/加上的话加不加/都能访问,如果是加上/之后,访问/hello的话会重定向到/hello/,唯一url的概念def hello():return "Hello,Juha"app.run(host='0.0.0.0',debug=True)#这里插入debug=True之后,修改代码不需要重启即可使用,如果为true了,只能127.0.0.1访问,也可以通过加入host参数指定IP能够访问,可以把host设置为'0.0.0.0',这里如果想改端口,使用port即可。
注册路由的方式,不止这里的装饰器【更优雅】@app(‘/hello’)可以。也可以通过app.add_url_rule(‘/hello’,view_func=hello)【如果基于类的视图就得用这个】。实际上。这里的装饰器也是调用了add_url_rule,为了优雅封装了起来。
如果开启了debug,一是影响性能,二是不安全。
因此需要使用配置文件。
可以在同目录下新建一个config.py的文件,flask要求参数名都是大写,如果不是,则会读取默认值。并且app.config的时候需要大写。
然后在此py中添加
app.config.from_object(‘config’)
app.run中修改:
app.run(host=’0.0.0.0’,debug=app.config[‘DEBUG’])
什么是if name ==’main‘:
必须是入口文件中才会调用。
生产环境中,入口文件是nginx+uwsgi。生产环境中的app.run不会执行的。
如果加了
if __name__ =='__main__':app.run()
就能够避免flask内置入口的启动,不和nginx冲突。
视图函数
视图函数和普通函数的不同。
视图函数会返回:
status
Content-Length
content-type【默认是text/html】
Server
Date
等信息
返回的是response对象。
flask有make_response对象
from flask import Flask,make_responseapp = Flask(__name__)app.config.from_object('config')# @app.route('/hello')def hello():headers = {'content-type':'text/plain'#这里指定不是html而是普通的文本,因此就会显示<html>>/html>,如果设置的是application/json,则会将内容解析会json返回。}response = make_response('<html></html>',404)#这里配置状态码会根据状态码显示访问/hello时显示什么内容,如果这里配置的是301,然后再在headers配置一个location的信息,那么就会重定向到那个地方。response.headers = headersreturn responseapp.add_url_rule('/hello',view_func=hello)app.run(host='0.0.0.0'
这里也是可以不使用flask的make_response对象,
return ‘’,301,headers也是可以的
搜索功能
来源:外部API
老师提供
关键字搜索:
http://t.yushu.im/v2/book/search?q={}&start={}&count={}
json搜索:
http://t.yushu.im/v2/book/isbn{isbn}
豆瓣API
https://api.douban.com/v2/book
访问频率是有控制地
搜索关键字
因为案例中既允许客户使用书名搜索,也允许使用isbn编号搜索,因此这里需要做一些判断。
对于入参,需要有关键字和页码,因此路由需要有两个入参
@app.route('/book/search/<q>/<page>')def search(q,page):isbn_or_key = 'key'#isbn有是13位纯数字的,也有是有-和10位数字组成的,需要判断一下if len(q)=='13' and q.isdigit();isbn_or_key='isbn'short_q = q.replace('-','')if '-' in q and len(short_q)==10 and short_q.isdigit():isbn_or_key='isbn'
但是视图函数这里,尽量简单一些,因此,需要把这些判断单独拿出去,例如拿到helper.py中。
helper.py:
def isbn_or_key(word):isbn_or_key = 'key'#isbn有是13位纯数字的,也有是有-和10位数字组成的,需要判断一下if len(word)==13 and word.isdigit():isbn_or_key='isbn'short_word = word.replace('-','')if '-' in word and len(short_word)==10 and short_word.isdigit():isbn_or_key='isbn'return isbn_or_key
然后主程序就简单很多了:
from flask import Flask,make_responsefrom helper import isbn_or_keyapp = Flask(__name__)app.config.from_object('config')@app.route('/book/search/<q>/<page>')def search(q,page):isbn_or_key = isbn_or_key(q)# app.add_url_rule('/hello',view_func=hello)app.run(host='0.0.0.0',debug=app.config['DEBUG'])
蓝图机制
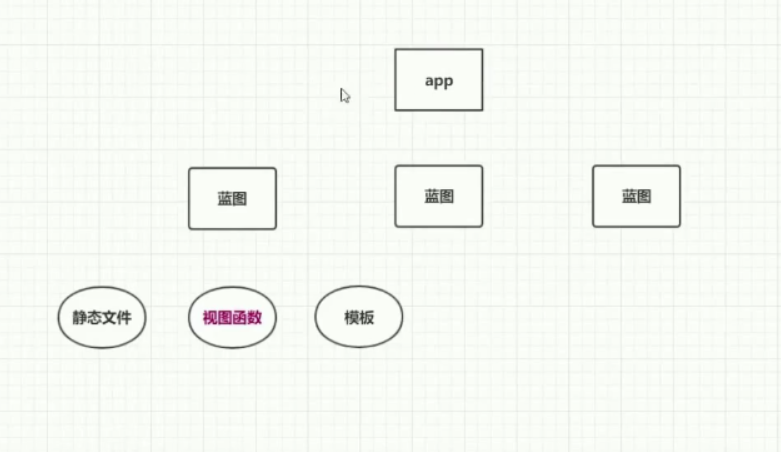
app是核心对象,类似一个插线板。
蓝图类似一个分线器,最终还是要注册到app上的。
终于,学了这么久终于能和老师一样有数据了。
我说咋回事,有俩参数,一个q一个page,如果只传q,一直是404…
前面这里的q和page是作为参数传递的。实际上的get请求一般是?q=xxx&page=xxx,想要实现这样的效果,需要引入flask的request的概念。
然后把路由里的/
/给去掉
@web.route('/book/search')
def search():
q = request.args['q']
page = request.args['page']
isbn_or_key = is_isbn_or_key(q)
if isbn_or_key == 'isbn':
result = YuShuBook.search_by_isbn(q)
else:
result = YuShuBook.search_by_keyword(q)
# 序列化
return jsonify(result)
这里的request.rgs对象是一个不可变字典,可以通过其to_dict()方法变为一个普通字典。
并且request本身是一个代理。【虽然不是很清楚,但是在测试的时候会用到】
WTForms参数验证
对于上面的q和page参数,需要验证一下
可以使用第三方的插件WTForms。需要先安装一下。
不仅可以通过WTForms的StringField和IntegerField验证输入的字符,并且可以通过validators的message参数输出错误信息(如果在视图函数中写了返回form.error)。并且,可以在validators中使用DataRequired()来指定传参不可为空。
这里的search_by_keyword实际上设计的并不好,count和start都是在类中手动设置的,没有把page这个变量给真正的使用起来。
可以把一些可能会改动的值,放在配置文件里面,这样改起来比改源代码要方便的多。
这里的count参数,老师单拉出来作为配置文件中的变量PER_PAGE,start参数使用了一个计算值(page-1)*per_page,这个计算值,最好是拿出来,于是YuShuBook的类就多了一个类方法。
@classmethod
def calculate_start(page):
return (page -1 )* current_app.config['PER_PAGE']
老师这里建了两个配置文件:
secure.py和setting.py
secure中保存一些机密信息,且生产和测试环境可能有些不一致的例如DEBUG=True。一般是不上传git的。
setting中的文件不涉及机密信息,并且测试和生产环境是一致的,并且可以上传到git中。
然后这里涉及到了current_app的对象,和request很像,是一个上下文的代理。
例如这里的配置文件,不需要把启动文件中的app进行导入,直接from flask import current_app,然后通过current_app.config[‘参数名’]即可获取到相应的配置文件中的参数。
我在这里遇到了一个问题,就是在YuShuBook类中的calculate的静态方法@staticmethod中,我弄成了@classmethod,结果导致了其被调用时出现了如下报错:
takes 1 positional argument but 2 were given
这里的staticmethod和classmethod抽空学习一下。
因为这里的每一次查询都是请求api,但是api请求是有次数限制的,如果请求过多,会导致封ip,想要解决这个问题,把已经查询到的数据存储起来会比较好。
目前这里的代码比较乱,现在整个libs文件夹,把一些自定义的文件扔进去。例如helper和myhttp。
flask启动mysql
创建数据库
创建数据库表三种模式:
databse first
model first
code first
code first
专注业务模型的设计,而不是专注数据库设计,简化了思维过程。
老师的观点:
数据库只是用来存储数据的,表关系应该由业务来决定。
MVC里的M,不仅是数据Model,也是业务Model。
orm(object-relational mapper)包:sqlalchemy
flask中也有Flask_SQLAlchemy,实际上也是从sqlalchemy来的,然后加了一些封装。
不过Flask_SQLAlchemy也需要安装【pipenv install flask-sqlalchemy.
在app目录下创建一个models的文件夹,然后创建book.py
from sqlalchemy import Column,Integer,String
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
class Book(db.Model):
id = Column(Integer,primary_key=True,autoincrement=True)
title = Column(String(50),nullable=False)
author = Column(String(30),default='佚名')
# 装订方式
binding = Column(String(20))
publisher = Column(String(20))
price = Column(String(20))
pages = Column(Integer)
pubdate = Column(String(20))
isbn = Column(String(15),nullable=False,unique=True)
summary = Column(String(1000))
image = Column(String(50))
def sample(self):
pass
然后去到app文件夹的init.py文件中注册一下model
from flask import Flask
from app.models.book import db
def create_app():
app = Flask(__name__)
app.config.from_object('app.secure')
app.config.from_object('app.setting')
register_blueprint(app)
# model和核心对象进行关联
db.init_app(app)
# 创建所有的数据库表
db.create_all(app=app)
return app
# 蓝图需要注册到视图函数上
def register_blueprint(app):
from app.web import web
app.register_blueprint(web)
然后还得在配置文件中把数据库的连接信息维护一下,这里我们在secure的文件中维护。这里格式是数据库+驱动+://账户:密码@host:port/数据库名。这里的cymysql需要pipenv install一下。
# 数据库 + 驱动
SQLALCHEMY_DATABAS= 'mysql+cymysql://xx:123@xx:3306/fisher'
我在运行的时候,出现了这么一行提示:
FSADeprecationWarning: SQLALCHEMY_TRACK_MODIFICATIONS adds significant overhead and will be disabled by default in the future. Set it to True or False to suppress this warning.
根据其提示,在配置文件中加上这么一行数据就OK了。
SQLALCHEMY_TRACK_MODIFICATIONS = True
此时,数据库中表就创建成功了。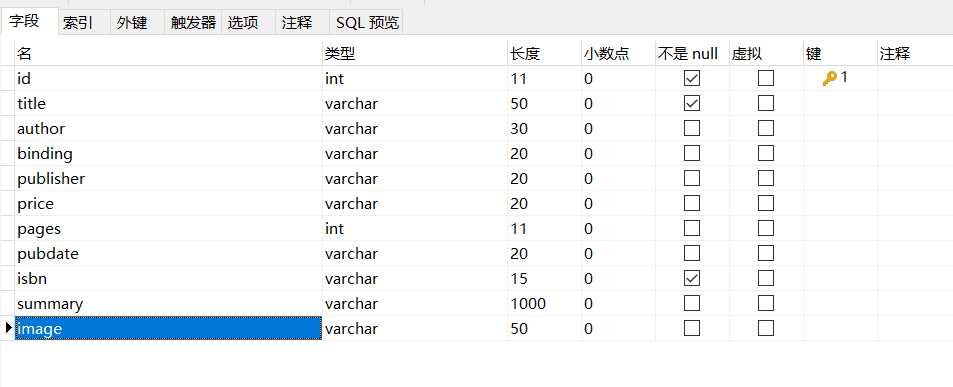
理解上下文的概念。
应用上下文AppContext和请求上下文RequestContext
AppContext封装了Flask核心对象,RequestContext封装了Request对象,然后这里使用了设计模式里的代理模式,利用了LocalProxy从而使current_app和request作为了代理。
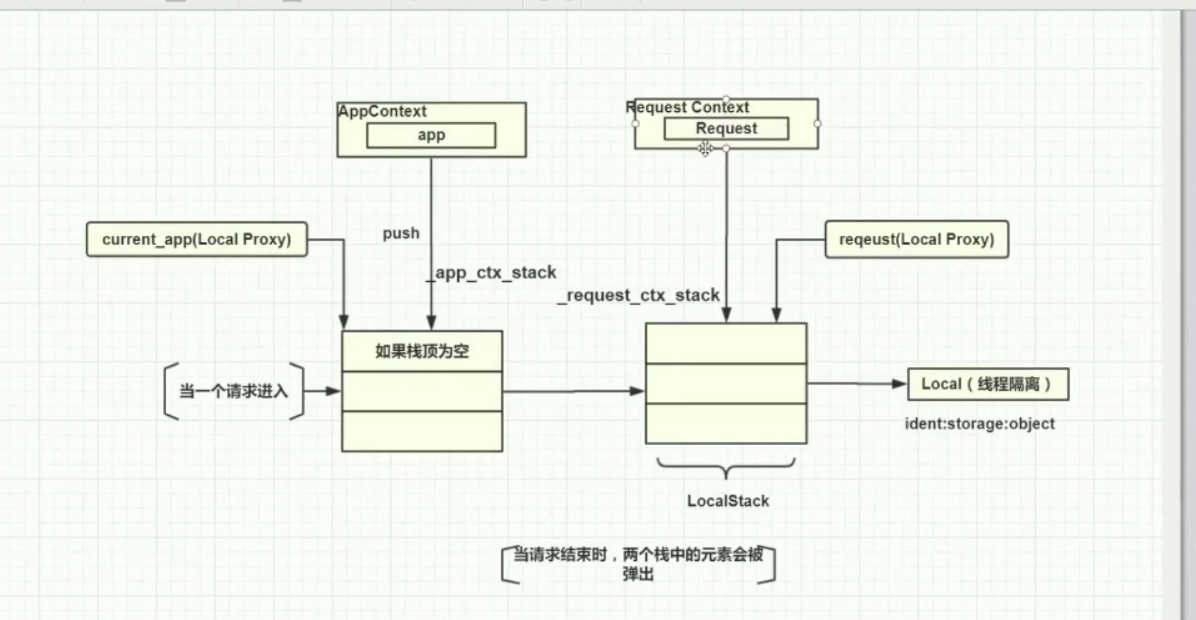
AppContext封装了app,RequestContext封装了Request。
当一个请求进来,flask会实例化一个RequestContext,信息在Request中;
把请求上下文推入(push)到栈LocalStack中,_request_sctx_stack实例化LocalStack。
但是在推入之前,会先检查_app_ctx_stack是否有数据,flask会做逻辑检测,如果_app_ctx_stack没有或和当前数据不一致,,会先推_app_ctx_stack
。并且这两个栈的元素就是新推的。current_app和request就是去这两个栈取栈顶元素。如果栈顶为空,就会出现unbound的状态。
手动入栈:
ctx = app.app_context()
ctx.push()
app_context(0返回的是Flask核心对象而不是上下文对象,其对应参数的_find_app返回的是top.app。
当请求结束之后,会从栈弹出。
上面的入栈完成后需要出栈:
ctx.pop()
编写单元测试或者离线应用的时候,就需要手动推入栈了。
with
简化入栈方法,使用with,with的实现关键是两个函数,enter**和exit**,只要一个对象实现了这俩函数,就可以使用with:
with app.app_context():
a = current_app
d = current_app.config['DEBUG']
实现了上下文协议的对象使用with。
上下文表达式必须要返回一个上下文管理器。
这里的上下文管理器就是AppContext。
以链接数据库管理为例,可以使用with。
数据库的连接:
链接数据库 — 查询 — 释放资源。
try finally也可以解决这个问题。
例如打开本地文件:
try:
f = open(r'D:\t.txt')
print(f.read(0)
finally:
f.close(0
使用with改写:
with open (r'D:\t.txt') as f:
print(f.read())
as后面的这个f,实际上是enter**方法返回的值,如果enter**没有返回值,则是None。
with里的执行顺序,举例描述:
class Myresource(object):
def __enter__(self):
print('Hi,welcome')
print("*"*8)
return self
def __exit__(self,exc_type,exc_value,b):
print("All done")
print("-"*8)
return True
def query(self):
print("query data")
print("="*8)
with Myresource() as resource:
resource.query()
这里的执行结果是:
Hi,welcome
********
query data
========
All done
--------
如果exit函数中不return或者是return false的话,如果下面发生了异常,会把异常抛出来,如果是true的话,异常则不会抛出来。

若有收获,就点个赞吧
0 人点赞
