什么是全文检索
- 数据分类:信息可以划分为两大类:结构化数据和非结构化数据
结构化数据:即行数据,存储在数据库里,可以用二维表结构来逻辑表达实现的数据,特点:固定格式、固定长度。
非结构化数据:指不定长或无固定格式的数据(结构化数据之外的一切数据)文本文件:txt excel ppt、电子邮件、社交媒体。
- 结构化数据搜索:常见的结构化数据就是数据库中的数据
在数据库中搜索很容易实现,通常都是使用SQL语句进行查询。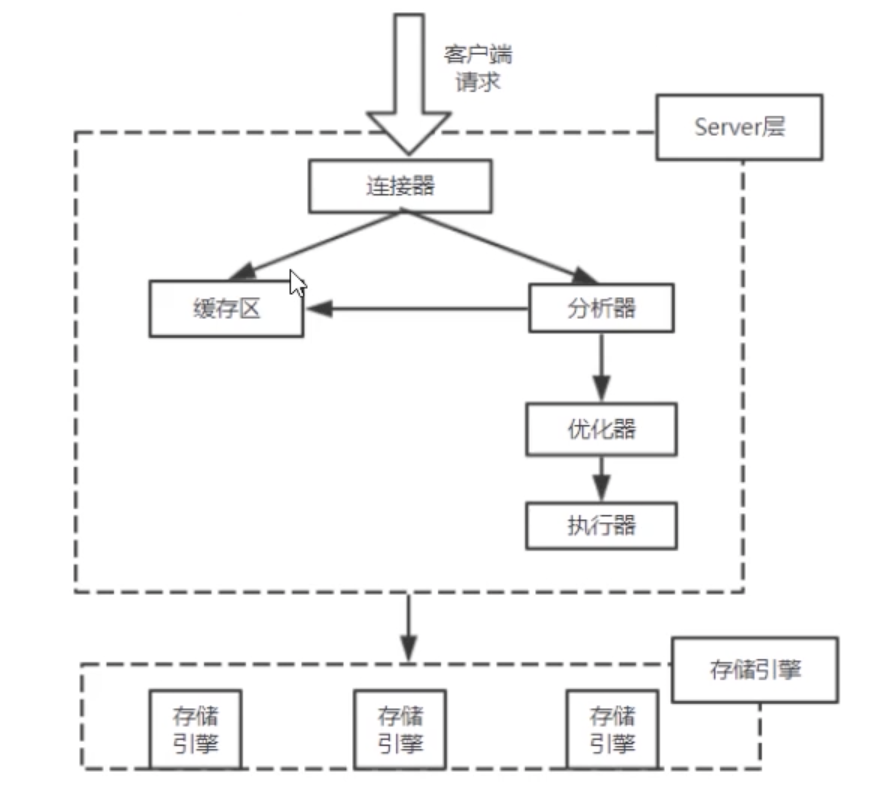
数据库底层的文件存储方式:
存储的物理方式:硬盘的块状存储,基本单位是1kb/块,磁头每次取数据,至少扫描一个块大小。
常见的关系型数据,常见的存储方式:
堆—随着文件的插入,不停地往其尾巴上堆,它的访问路径就是顺序扫描,扫完才能查到数据。
hash — 其文件的hash值,就是其存储地址
索引 + 堆 — 对堆文件的某一列,建立索引
- 非结构化数据查询
- 顺序扫描法: 所谓顺序扫描,比如要找内容包含某一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头看到为,如果此文档包含此字符串,则此文档为我们要找的文件,接着看一下个文件,直到扫描完所有的文件。搜索是相当的慢。
全文检索:全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方法,这个过程类似于通过字典的目录查字的过程。
将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定的结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的,这部分从非结构化数据中提取出来的然后重新组织的信息,我们称之为索引。
先建立索引,然后再对索引进行搜索的过程就叫全文检索。索然创建索引的过程是非常耗时的,但是索引一旦创建就可以多次使用,全文检索主要处理的是查询,索引耗时创建索引是值得的。
如何实现全文检索
Lucene实现全文检索。Lucene是Apache下的一个开放源代码的全文检索引擎工具包,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文和德文)Lucene目的是为软件开发人员提供一个简单易用的工具包,以方便在目标系统中实现全文检索的功能。
Lucene适用场景:
- 在应用中为数据库中的数据提供全文检索实现
- 开发独立的搜索引擎服务、系统
Lucene特点:
- 稳定、索引性高
- 高效、准确、高性能的搜索算法
- 跨平台
Lucene架构: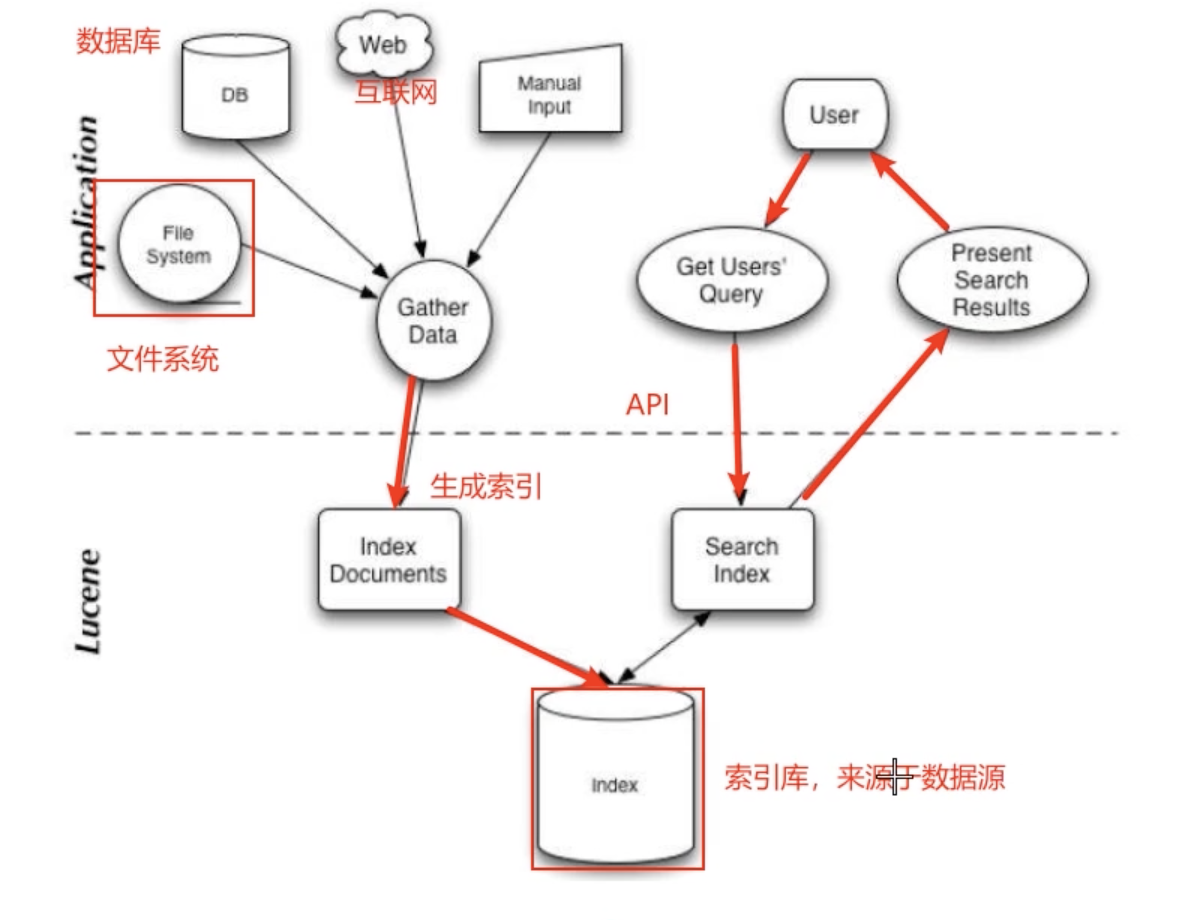
在传统的开发方式如下:例如搜索Java开发会从数据库中检索,但是一般使用like,而like是不支持索引的,加入有几百万条数据,很多用户访问那么会出现问题了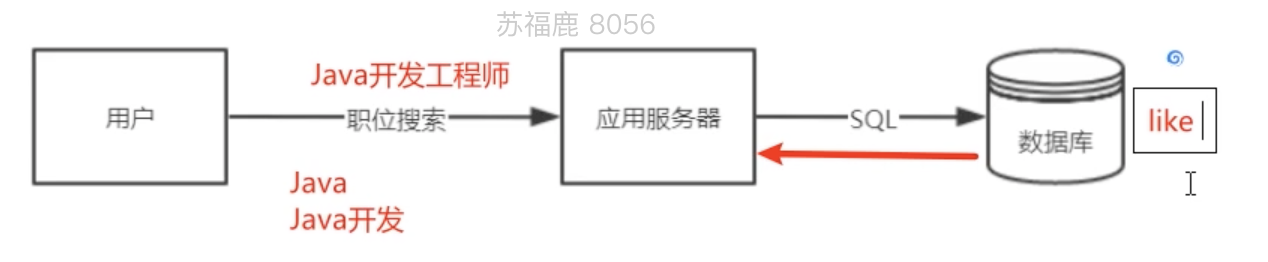
使用Lucene或者ES建立索引库,同事还可以进行分词例如会把Java开发工程师分为:Java、Java开发、工程师等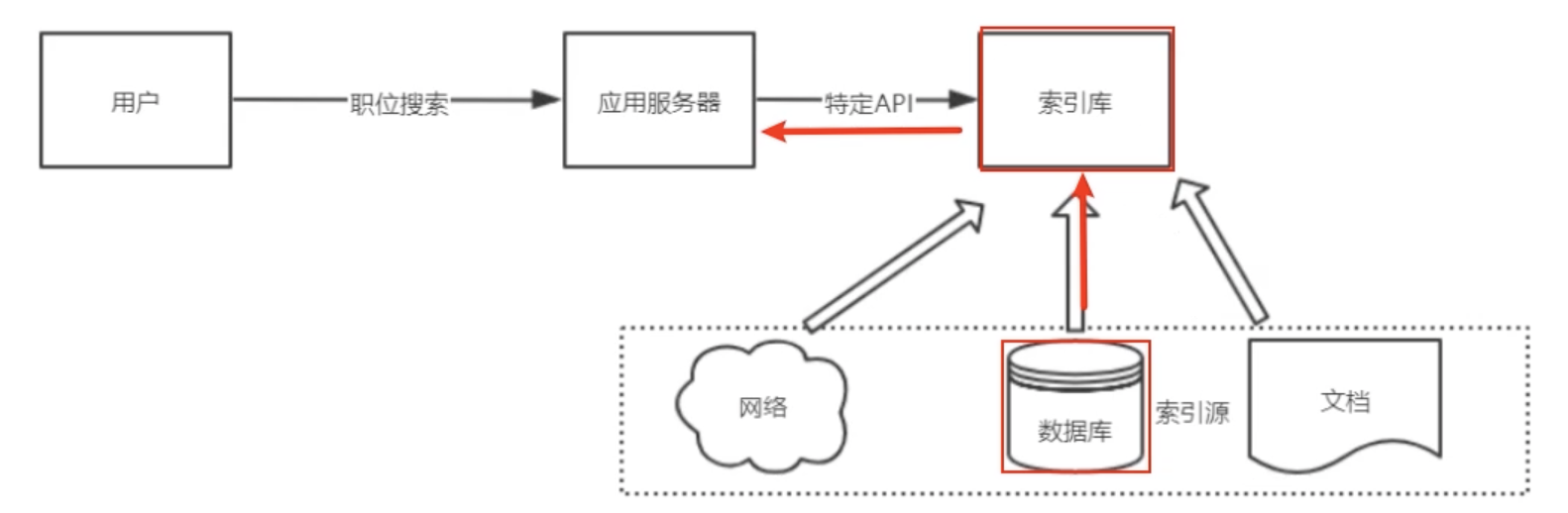
对于数据量大、数据结构不固定的数据可采用全文检索方式搜索。
Lucene 实战
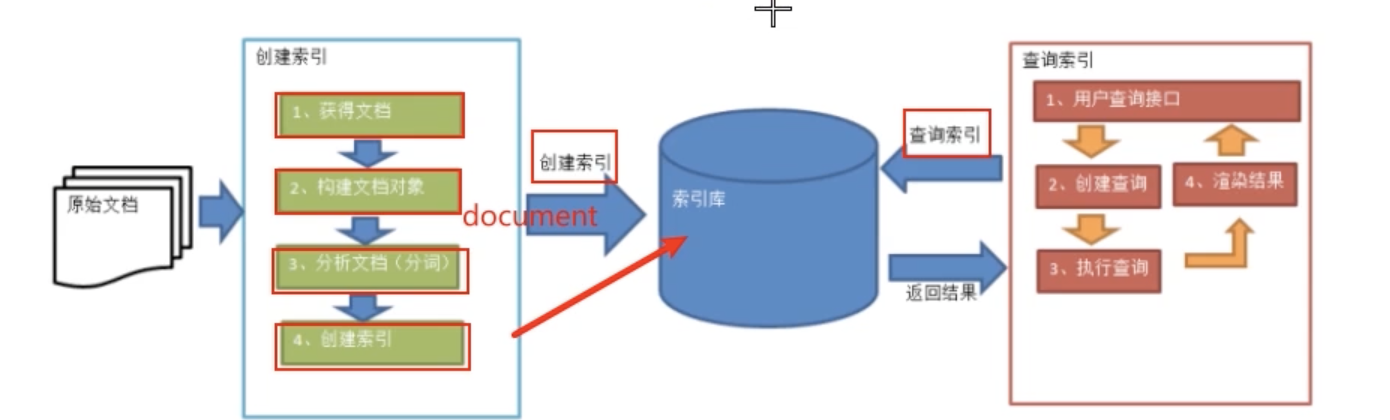
创建索引:
Lucene的核心概念:
- Document:用户提供的源是一条条记录。它们可以是文本文件、字符串或者数据库表的一条记录等等。一条记录经过索引之后,就是以一个Document的形式存储在索引文件中的。用户进行搜索也是以Document列表的形式返回。
- Field:一个Document可以包含多个Field信息域,例如表中的列,这些信息域都是通过Field在Document中存储。Field有两个属性可选:存储和索引

- Term:是搜索的最小单元,他表示文档的一个词语。 Term由两部分组成:表示的词语和这个词语锁出现的Field的名称。
倒排索引
查询索引
代码实现
- 创建索引
生成的文件如下:/*** 创建索引*/@Testpublic void create() throws IOException {//1. 指定索引文件的存储位置,索引具体的表现形式就是一组有规则的文件Directory directory = FSDirectory.open(new File("/Users/prim/java/class/index"));//2. 配置版本及其分词器Analyzer analyzer = new StandardAnalyzer();IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, analyzer);//3. 创建indexWriter对象,创建索引IndexWriter indexWriter = new IndexWriter(directory, config);//删除已经存在的索引库indexWriter.deleteAll();//4. 获得索引源 原始数据List<JobInfo> jobInfos = jobInfoService.selectAll();//5. 遍历JobInfoList 每次遍历创建一个Document对象for (JobInfo jobInfo : jobInfos) {//创建Document对象Document document = new Document();//创建Field对象,添加到Document中//职位的iddocument.add(new LongField("id", jobInfo.getId(), Field.Store.YES));//切分词、索引、存储//名称document.add(new TextField("companyName", jobInfo.getCompanyName(), Field.Store.YES));//地址document.add(new TextField("companyAddr", jobInfo.getCompanyAddr(), Field.Store.YES));//公司的信息document.add(new TextField("companyInfo", jobInfo.getCompanyInfo(), Field.Store.YES));//职位名称document.add(new TextField("jobName", jobInfo.getJobName(), Field.Store.YES));//职位的信息document.add(new TextField("jobInfo", jobInfo.getJobInfo(), Field.Store.YES));//最小工资document.add(new IntField("salaryMin", jobInfo.getSalaryMin(), Field.Store.YES));//最大工资document.add(new IntField("salaryMax", jobInfo.getSalaryMax(), Field.Store.YES));document.add(new StringField("url", jobInfo.getUrl(), Field.Store.YES));//将文档追加到索引库indexWriter.addDocument(document);}//关闭资源indexWriter.close();System.out.println("create index success");}
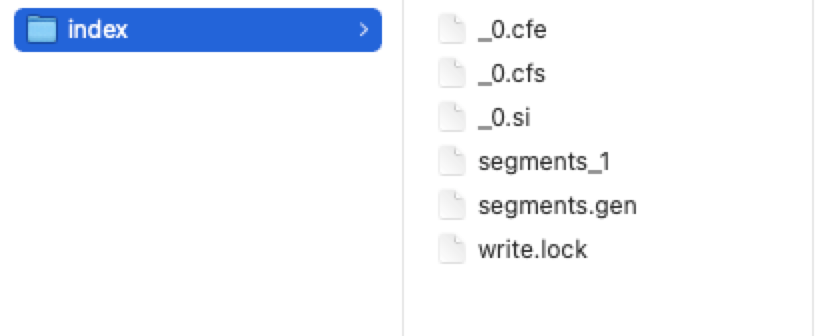
索引目录的描述:
- 查询索引
@Testpublic void query() throws IOException {//1. 指定索引文件的存储位置,索引具体的表现形式就是一组有规则的文件Directory directory = FSDirectory.open(new File("/Users/prim/java/class/index"));//2. IndexReader对象 读取索引IndexReader indexReader = DirectoryReader.open(directory);//3. 创建查询对象IndexSearcher indexSearcher = new IndexSearcher(indexReader);//4. 使用term查询 查询公司名称中包含"北京"的所有的文档对象 默认的分词器对中文不太友好Query query = new TermQuery(new Term("companyName", "北"));TopDocs search = indexSearcher.search(query, 100);//获得符合查询条件的文档数int totalHits = search.totalHits;System.out.println("totalHits:" + totalHits);//获得命中的文档 封装了文档的id信息ScoreDoc[] scoreDocs = search.scoreDocs;for (ScoreDoc scoreDoc : scoreDocs) {int id = scoreDoc.doc;//文档id//通过文档id获得文档对象Document document = indexSearcher.doc(id);System.out.println("id:" + document.get("id"));System.out.println("companyName:" + document.get("companyName"));System.out.println("companyAddr:" + document.get("companyAddr"));System.out.println("companyInfo:" + document.get("companyInfo"));System.out.println("jobName:" + document.get("jobName"));System.out.println("jobInfo:" + document.get("jobInfo"));System.out.println("url:" + document.get("url"));System.out.println("++++++++++++++++++++++++++++++++++++++++++++");}//释放资源indexReader.close();}
检索如下:当我们使用”北京”无法检索到,当改为一个字的时候”北”这是默认的分词器对中文不太友好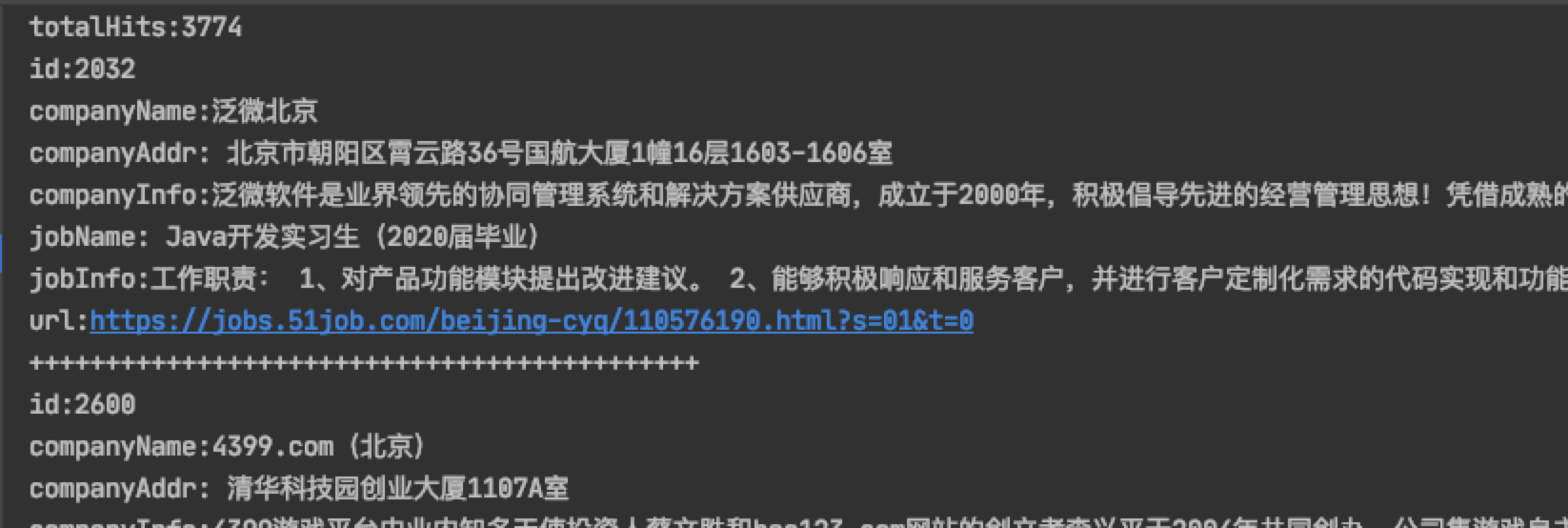
引入:IK 中文分词器
<!--IK中文分词器--><dependency><groupId>com.janeluo</groupId><artifactId>ikanalyzer</artifactId><version>2012_u6</version></dependency>
在上述的生成索引的代码中修改为IK分词器,重新生成索引。
Analyzer analyzer = new IKAnalyzer();
然后我们再根据”北京”去查询索引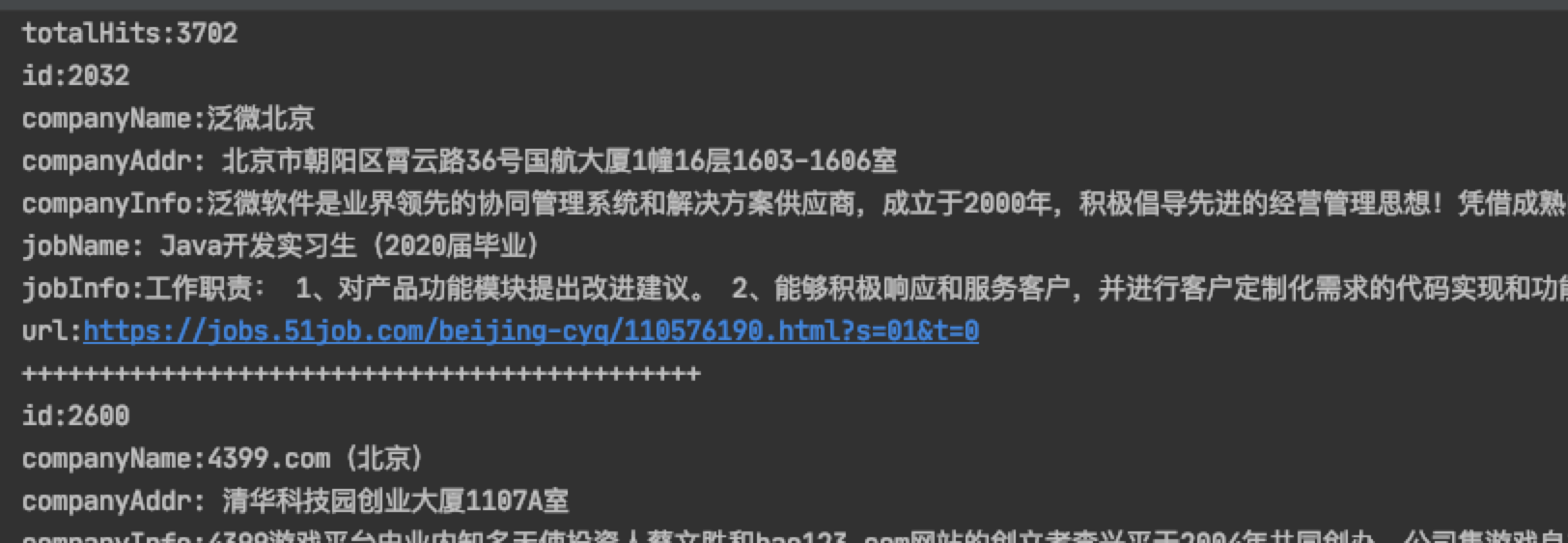
一个大型网站中的索引数据会很庞大,所以使用Lucene这种原生的写代码的方式就不合适了,所以需要借助一个成熟的项目或软件来实现,目前比较有名的是
solr和ElasticSearch。下面重点来学习ElasticSearch
ElasticSearch
ELK技术栈:
Elastic有一条完整的产品线:ElasticSearch、Logstash、Kibana等。这三个就是常说的ELK技术栈(开源实时日志分析平台)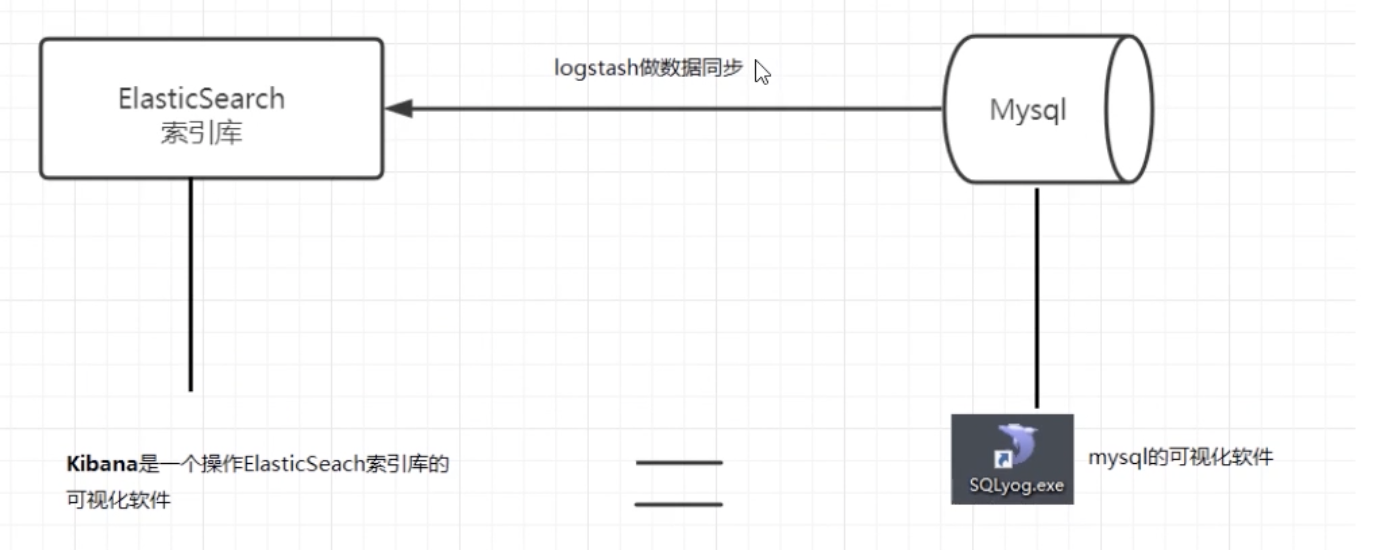
logstash的作用就是一个数据收集器,将各种格式各种渠道的数据通过它收集解析之后格式化输出到ES,最后再由Kibana提供的比较友好的Web界面进行汇总、分析、搜索 ELK内部实际就是个管道结构,数据从Logstash到ES再到Kibana做可视化展示。这三个组件各自也可以单独使用,比如Logstash不仅可以将数据输出到ES,也可以到数据库、缓存等。
Elasticsearch功能:
- 分布式搜索引擎
- 全文检索:提供模糊搜索等自动度很高的查询方式,并进行相关性排名、高亮等功能。
- 数据分析引擎(分组聚合) : 电商网站-一周内手机销量TOP10
- 对海量数据进行近乎实时处理:水平扩展,每秒钟可处理海量时间,同时能够自动管理索引和查询在集群中的分布式方式,以实现及其流畅的操作

- 安装Elasticsearch-6.2.4版本.
elasticsearch-6.2.4.zip 将压缩包解压到英文目录下,并且目录名称不要有空格。
启动es
~/elasticsearch-6.2.4/bin
sh elasticsearch
启动之后访问:http://localhost:9200/
看到如下信息就说明启动成功了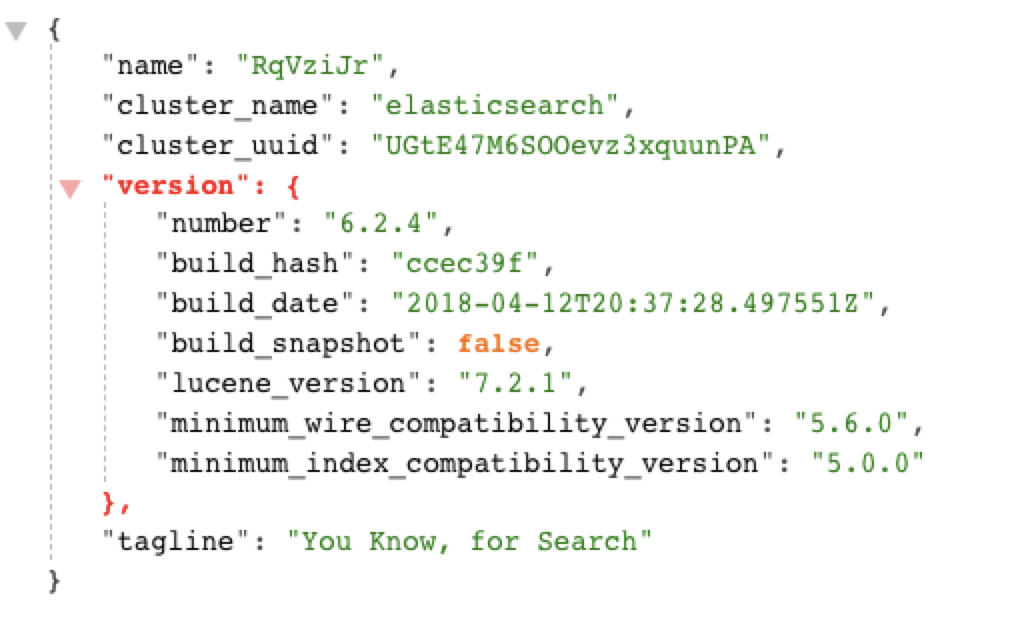
- 安装可视化工具 Kibana
kibana-6.2.4-darwin-x86_64.tar.gz
Kibana是基于node的环境,所以先安装node的环境。下载kibana的6.2.4的版本解压即可。
然后修改配置文件:config/kibana.yml 配置es的地址为:localhost:9200
然后进入bin目录运行sh kibana启动kibana
访问:http://localhost:5601
- 安装IK分词器
kibana-6.2.4-darwin-x86_64.tar.gz
IK分词器的版本要和ES的版本保持一致,进行解压,重命名为ik, 然后放到ES的plugin的目录下,然后重启ES和Kibana。
ik_max_word 最大的分词方式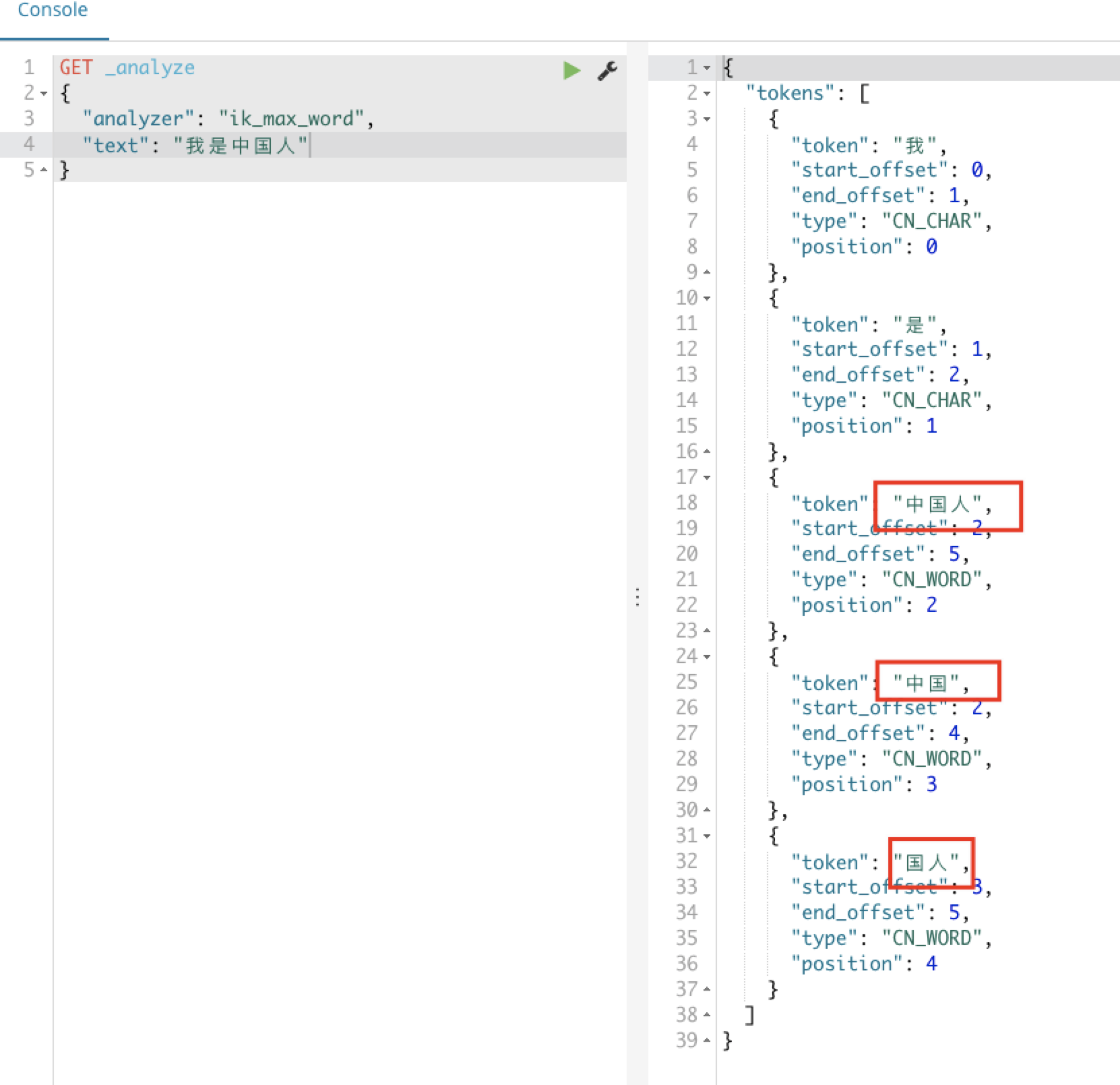
还有另一种分词的方式:ik_smart 智能的分词方式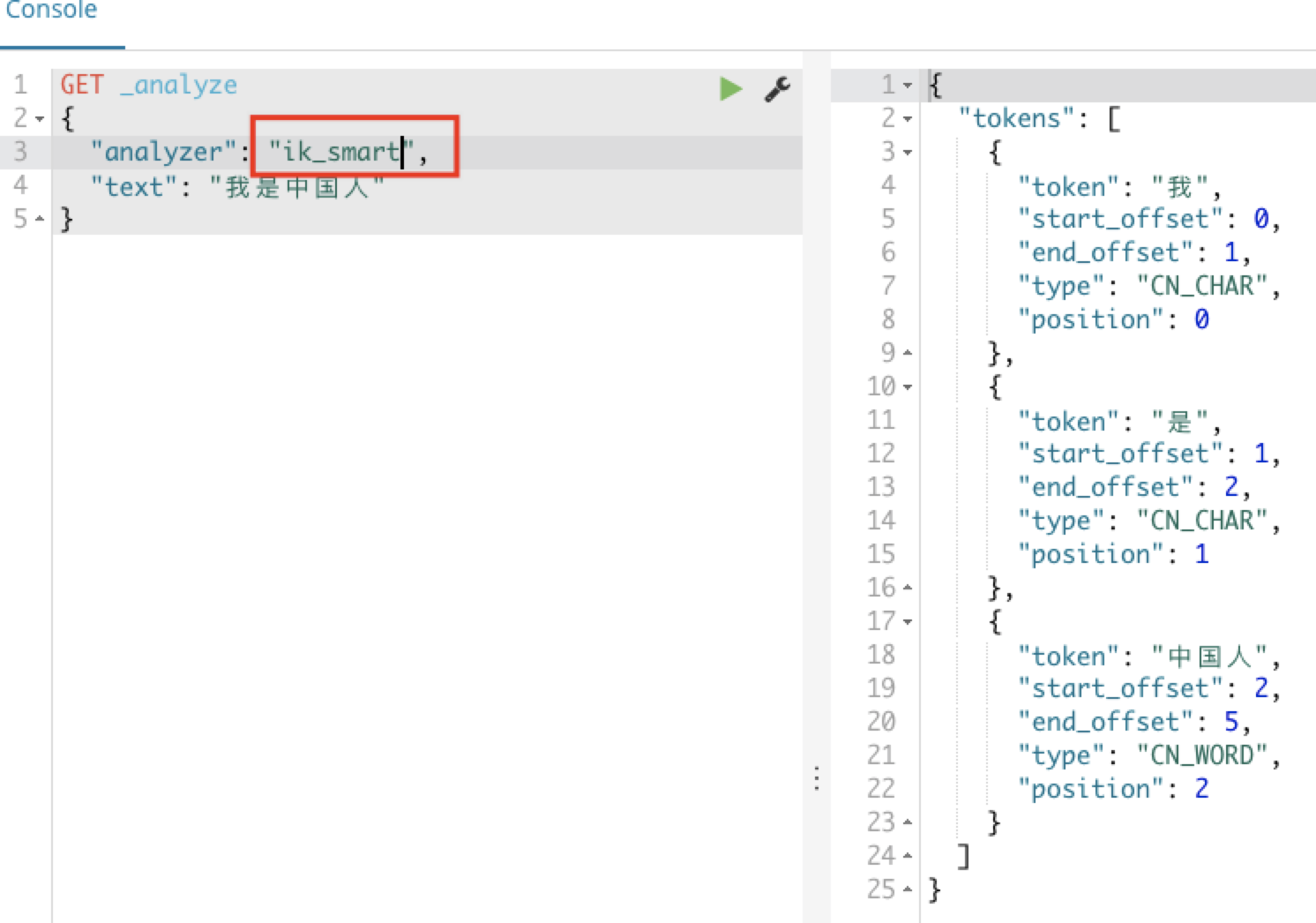
- elasticsearch-head安装
elasticsearch-head是一个界面化的集群操作和管理工具,可以对集群进行傻瓜式操作。
- 显示集群的拓扑,并且能够执行索引和节点级别操作
- 搜索接口能够查询集群中原始json或表格格式的检索数据
- 能够快速访问并显示集群的状态
官方的文档:
elasticsearch-head 是基于谷歌浏览器。elasticsearch-head.7z
解压压缩包,然后在谷歌浏览器中点击“加载已解压的压缩程序”,进行安装
启动之后的界面:
使用Kibana对索引库操作
基本概念
- 节点、集群、分片、副本
- 节点:一个节点就是一个ES的实例,在服务器上启动ES之后,就拥有了一个节点。如果在另一台服务器上启动ES就是另一个节点。设置可以通过启动多个ES进程,在同一台服务器上拥有多个节点。
- 集群(cluster):多个协同工作的ES节点的集合被称为集群。在多节点的集群上,同样的数据可以在多台服务器上传播。这有助于性能、稳定性。如果每个分片至少有一个副本分片,那么任何一个节点宕机后,ES依然可以进行服务,返回所有数据。但是它也有缺点:必须确定节点之间能够足够快速地通信,并且不会产生脑裂效应(集群的2个部分不能批次交流,都认为对方宕机了)。
- 分片(shard):索引可能会存储大量数据,这些数据可能超过单个节点的硬件限制。例如,十亿个文档的单个索引占用了1TB的磁盘空间,可能不适合单个节点的磁盘,或者可能太慢而无法单独满足来自单个节点的搜索请求。
ES允许将索引分片的一个或多个副本制作为所谓的副本分片(简称副本)
- 副本(replica):分片处理允许用户推送超过单机容量的数据至ES集群,副本则解决了访问压力过大时单机无法处理所有请求的问题。
- 文档、类型、索引及映射
- 文档(document):存入索引库原始的数据。比如每一条商品信息,就是一个文档
- 类型(type):类型是文档的逻辑容器,类似于表格是行的容器。在不同的类型中,最好放入不同结构的文档。例如:可以用一个类型定义聚会时的分组,而另一个类型定义人们参加的活动
- 索引(index): 索引是映射类型的容器,一个ES索引是独立的大量的文档集合。每个索引存储在磁盘上的同组文件中,索引存储了所有映射类型的字段,还有一些设置。
- 映射(mapping):所有的文档在写入索引前都将被分析,用户可以设置一些参数,决定如何将输入文本分割为词条,哪些词条应该被过来掉

创建/查询/删除索引库操作
在kibana的控制台,可以对HTTP请求进行简化:
如下新建索引:
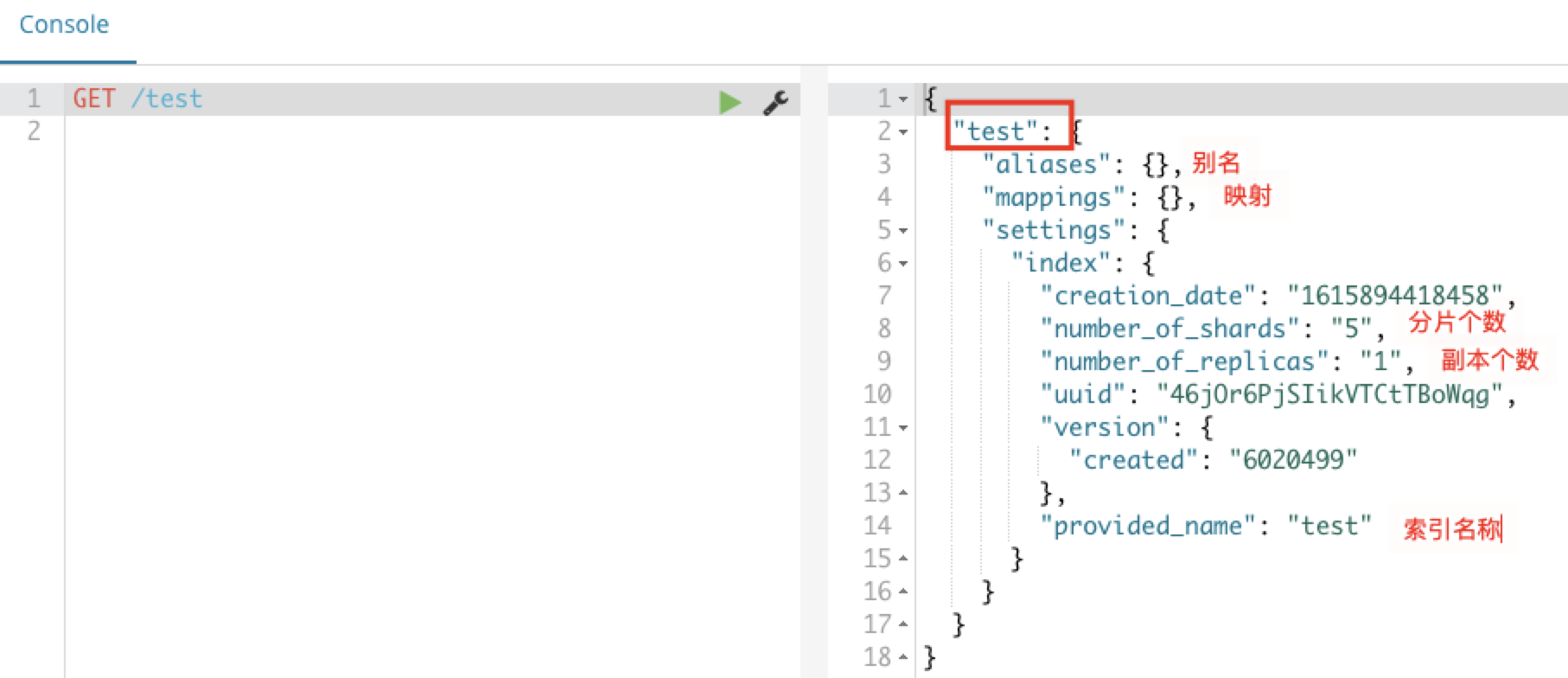

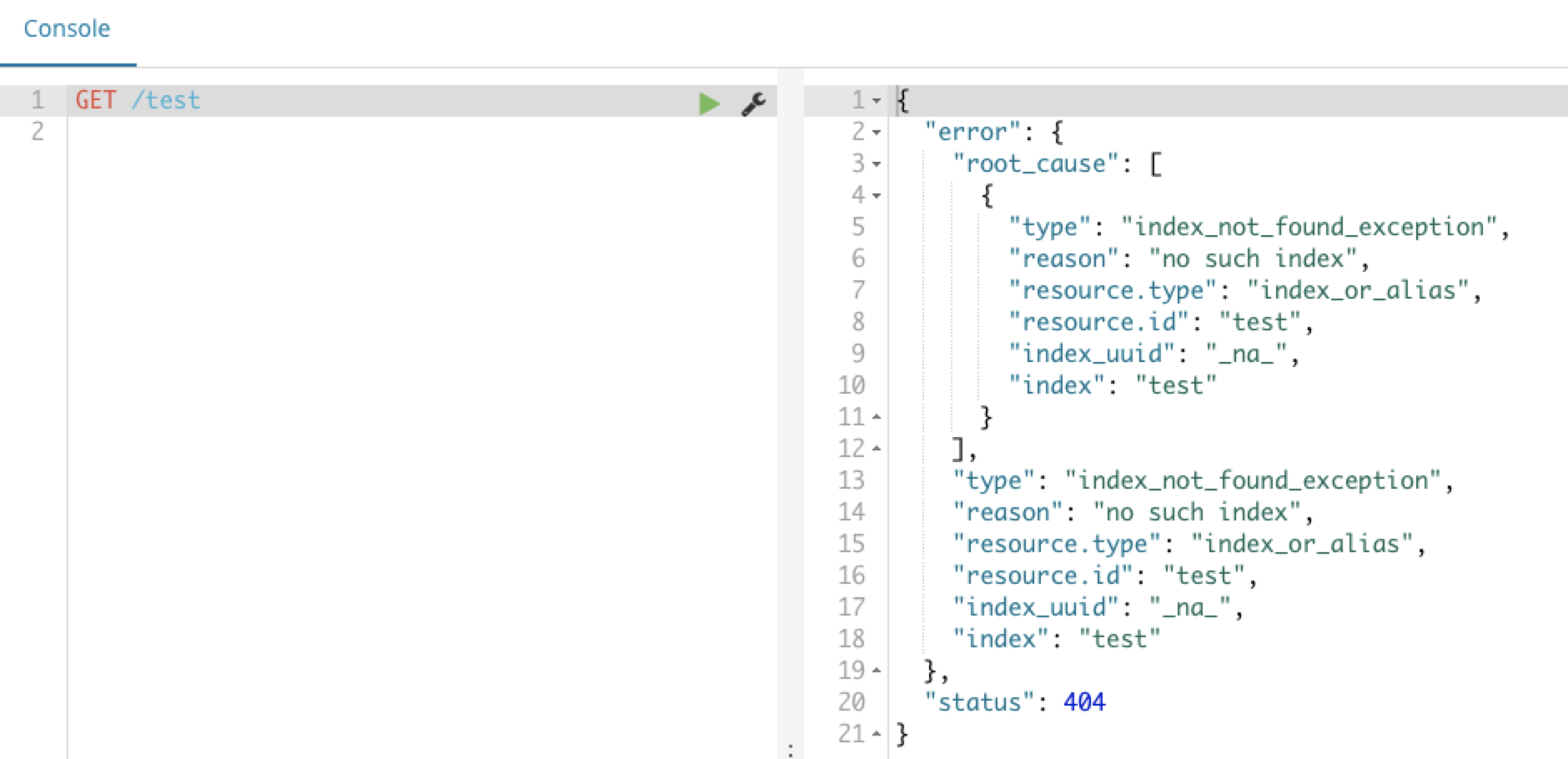
创建类型及映射操作
有了索引库,等于有了数据库中的database,接下来就需要索引库中的类型,也就是数据库中的表。我们在创建表需要设置字段约束,索引库也是一样的,在创建索引库的类型时,需要知道这个类型下有哪些字段,每个字段都有哪些约束信息,这就叫做字段映射。
字段的约束包括不限于:
- 字段的数据类型
- 是否要存储
- 是否要索引
- 是否分词
- 分词器是什么
PUT /索引库/_mapping/typeName(类似表名) mapper在逻辑上属于Type,所以要指定类型的名称
{
"properties": {
"字段名":{
"type":类型, // text keyword long short date integer object
"index":true, //是否索引,默认为true
"store":true, //是否存储,默认false
"analyzer":分词器 //指定分词器
}
}
}
例如如下:创建一个goods类型,设置三个字段:title price images
PUT /test/_mapping/goods
{
"properties":{
"title":{
"type":"text",
"store":true,
"analyzer":"ik_max_word"
},
"images":{
"type":"keyword",
"store":true,
"index":false
},
"price":{
"type":"float"
}
}
}
返回 表明类型和映射创建成功。
表明类型和映射创建成功。
- 查看映射关系
GET /索引库/_mapping 查看所有的映射关系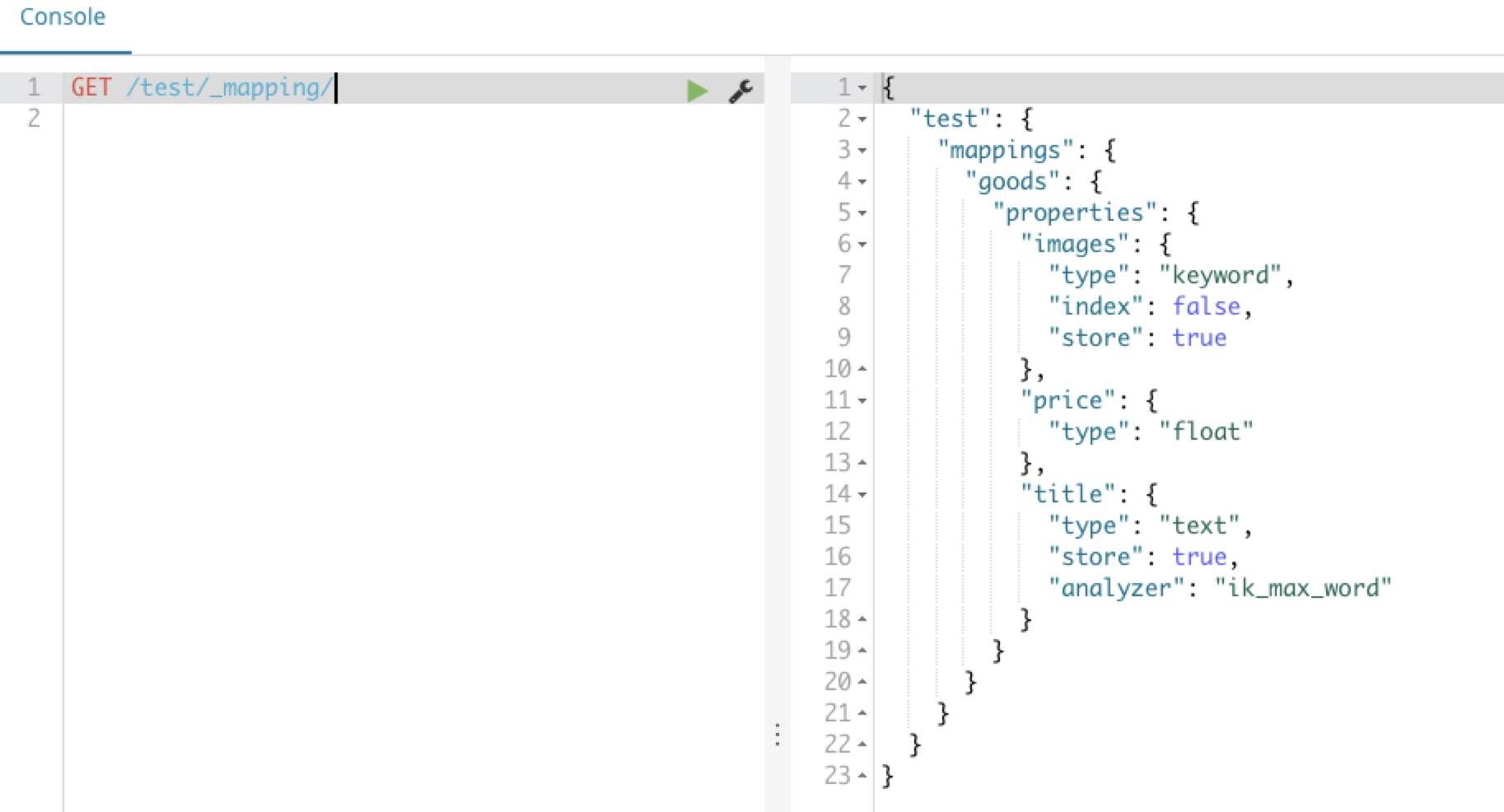
查看goods类型的映射关系:GET /test/_mapping/goods
映射的属性详解
- type
| 一级分类 | 二级分类 | 具体类型 | 使用 |
| —- | —- | —- | —- |
| 核心类型 | 字符串类型 | text(会被分词,通常不用于排序如文章标题、正文等)
keyword(用于索引结构化内容的字段,不会被分词,必须完整匹配的内容如:邮箱、身份证号、支持聚合) | 结构化搜索、全文本搜索、聚合、排序等 | | | 整数类型 | Integer,long,short,byte | 字段的长度越短,索引和搜索的效率越高 | | | 浮点类型 | double,float,half_float,scaled_float | | | | 逻辑类型 | boolean | | | | 日期类型 | date | 建议存储毫秒值,存储为long节省空间 | | | 范围类型 | range | | | | 二进制类型 | binary | | | 复合类型 | 数组类型 | array | |
| | 对象类型 | object | 用于单个JSON对象
|
| | 对象类型 | object | 用于单个JSON对象 |
| | 嵌套类型 | nested | 用于JSON对象数组 |
| 地理类型 | 地理坐标类型 | geo_point | 纬度 经度积分 |
| | 地理地图 | geo_shape | 用于多边形等复杂形状 |
| 特殊类型 | IP类型 | IP | 用于IPv4和IPv6地址 |
| | 范围类型 | completion | 提供自动完成建议 |
| | 令牌计数类型 | token_count | 计算字符串中令牌的数量 |
|
| | 嵌套类型 | nested | 用于JSON对象数组 |
| 地理类型 | 地理坐标类型 | geo_point | 纬度 经度积分 |
| | 地理地图 | geo_shape | 用于多边形等复杂形状 |
| 特殊类型 | IP类型 | IP | 用于IPv4和IPv6地址 |
| | 范围类型 | completion | 提供自动完成建议 |
| | 令牌计数类型 | token_count | 计算字符串中令牌的数量 |
- index
index影响字段的索引情况:
true:字段会被索引,默认值为true,只有当某一个字段的index值设置为true时,检索ES才可以作为条件检索
false:字段不会被索引,不能用来搜索。
- store
表示是否将数据进行额外存储。在ES中即便store设置为false,也可以搜索到结果。在ES创建文档索引时,会将文档中的原始数据备份,保存到一个叫做_source的属性中。如果store为true,就会在_source 以外额外存储一份数据,多余,因此一般我们都会将store设置为false。
Lucene时,我们知道如果一个字段的store设置为false,那么在文档列表中就不会有这个字段的值,用户的搜索结果中不会显示出来。
在某些情况下,这对 store 某个领域可能是有意义的。例如,如果您的文档包含一个 title ,一个date和一个非常大的content 字段,则可能只想检索thetitle和thedate而不必从一个大_source字段中提取这些字段。
- boost
boost权重,新增数据时,可以指定该数据的权重,权重越高得分越高,排名越靠前。
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"title": {
"type": "text",
"boost": 2 },
"content": {
"type": "text"
}
}
}
}
}
如上代码,title字段的匹配项的权重是字段匹配项的权重的两倍content boost默认值为1.0。仅适用于Term查询。
一次创建索引库和类型
PUT /test2
{
"settings": {},
"mappings": {
"goods":{
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word",
"store": true
},
"price": {
"type": "double",
"store": true
},
"images": {
"type": "keyword"
}
}
}
}
}
执行结果如下:
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "test2"
}
新增/修改/查询文档操作
新增文档就是相当于在数据表中新增数据。
POST /索引库/类型名
{
"key":"value"
}
如下例子:
POST /test/goods
{
"title":"华为",
"images":"https://www.baidu.com",
"price":9999.9
}
运行结果如下: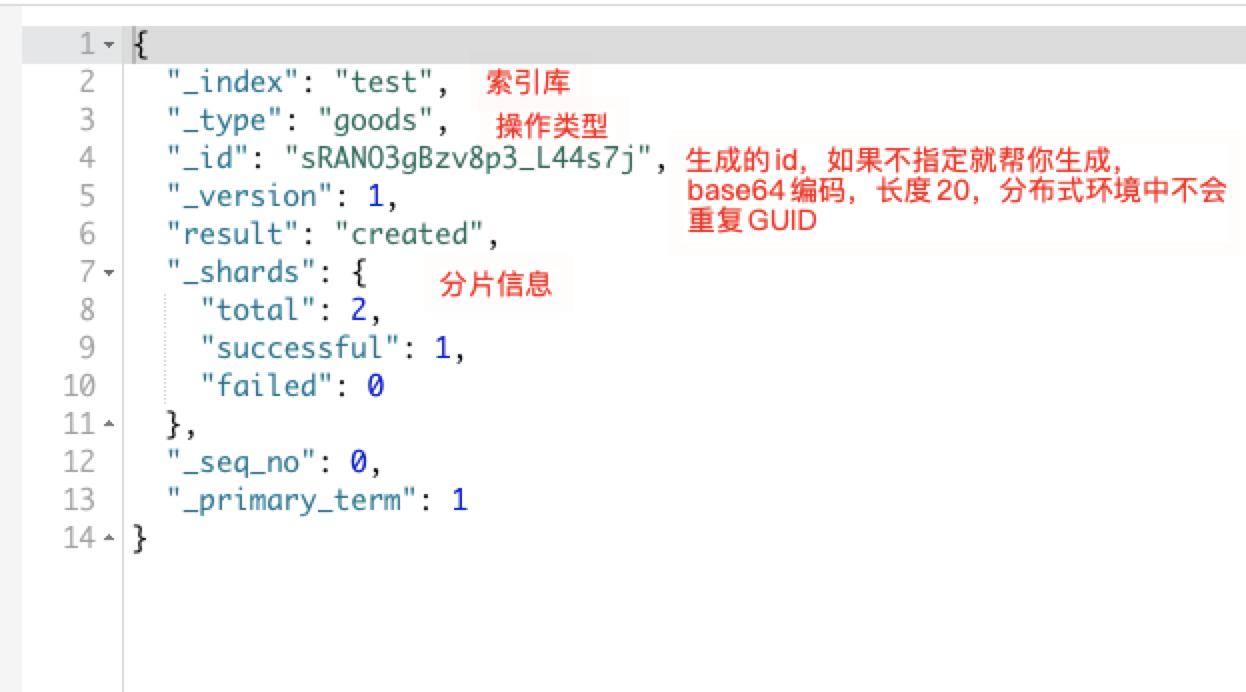
在实际开发中怒建议使用ES生成ID,太长且为字符串类型,检索时效率太低。建议:如果是数据表中的唯一id作为ES的文档ID
查看文档信息
GET /test/goods/sRANO3gBzv8p3_L44s7j/运行结果如下:
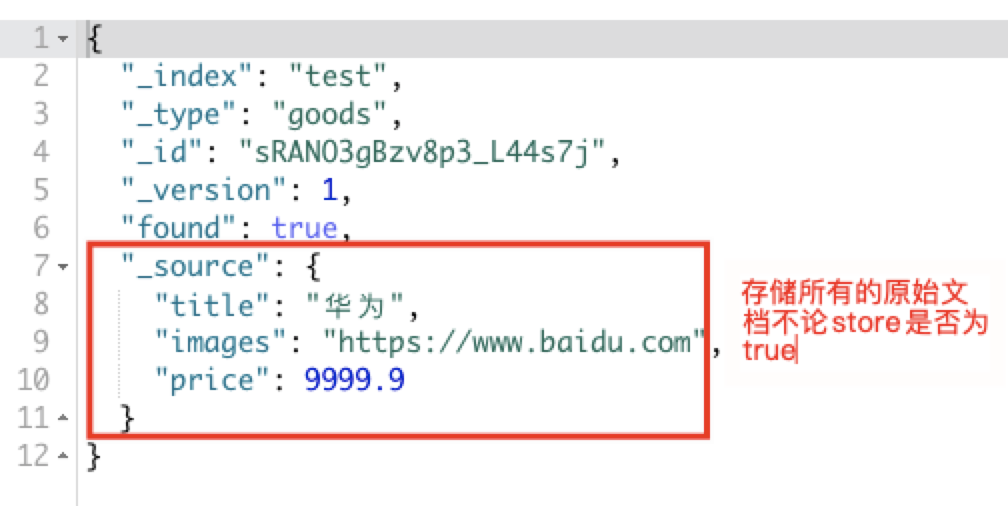
查询类型下的所有文档信息
GET /test/goods/_search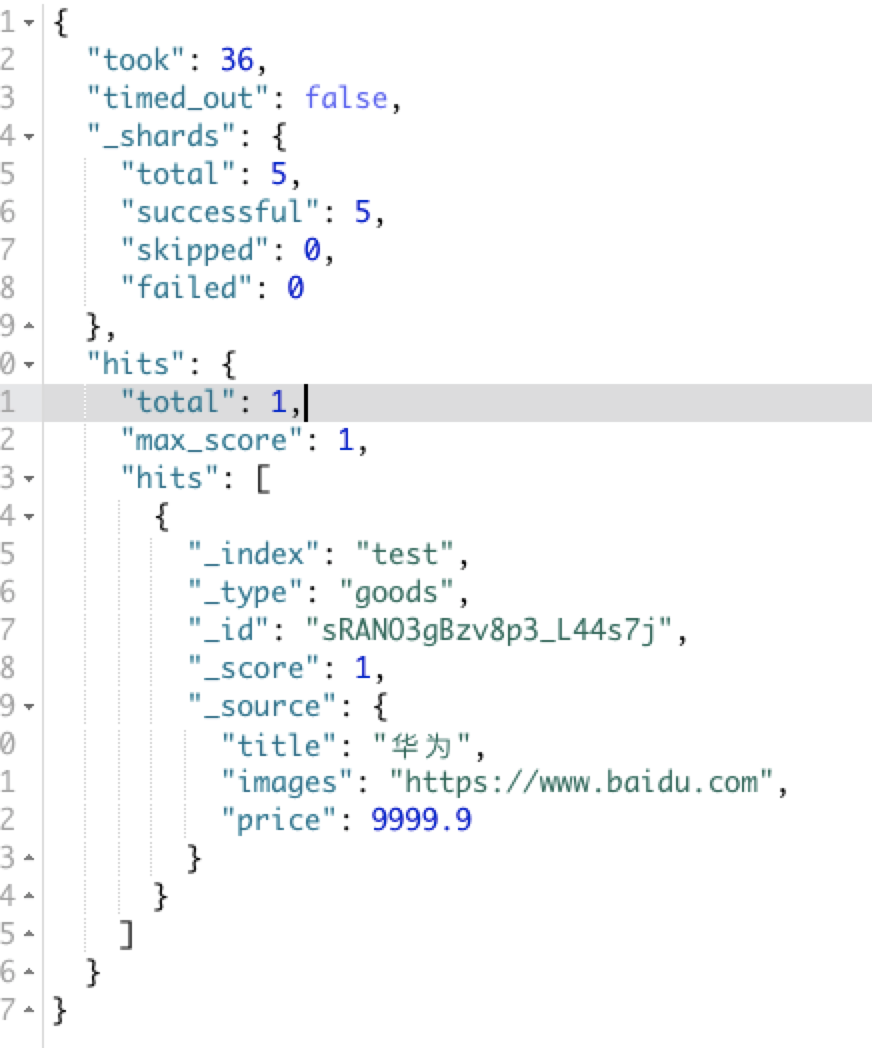
新增文档并自定义id
POST /test/goods/2 { "title":"xiaomi", "images":"xxx", "price":99.9 }修改数据
PUT:修改文档,必须指定id,如果id存在则修改,如果id不存在则为新增操作
PUT /test/goods/2
{
"title":"xiaomi2",
"images":"xxx",
"price":99.9
}
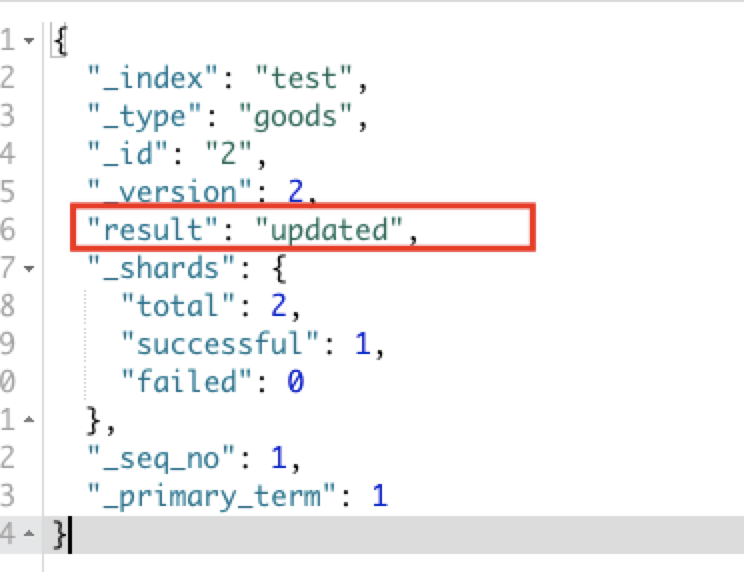
删除文档数据
DELETE /索引库/类型/id
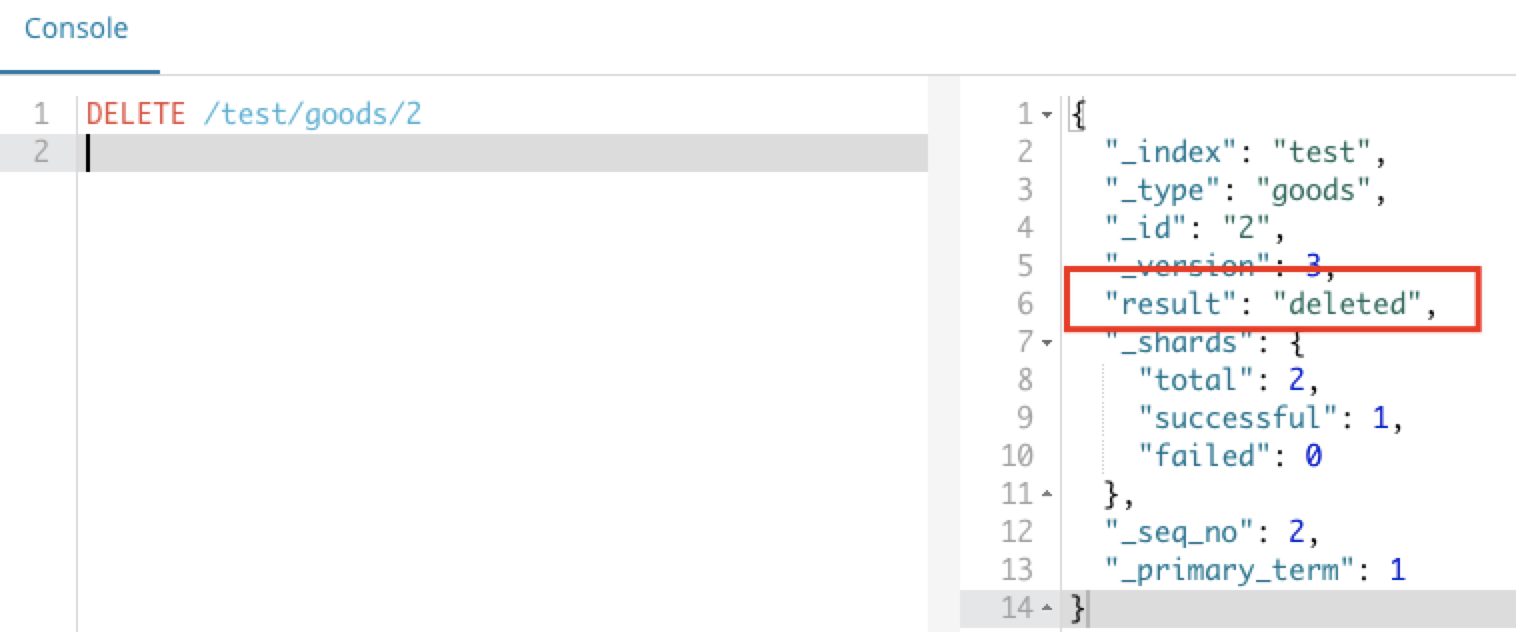
智能判断

若有收获,就点个赞吧
0 人点赞
