RabbitMQ有三种模式,但集群模式是2种,如下:
- 单一模式:即单机情况不做集群,就单独运行一个RabbitMQ而已,就是之前入门讲述的
- 普通模式:默认模式,以两个节点A、B为例
- 当消息进入A节点的Queue后,Consumer从B节点消费时,RabbitMQ会在A和B之间创建临时通道进行消息传输,把A中的消息实体取出并经过通过交给B发送给Consumer
- 当A故障后,B就无法取到A节点中未消费的消息实体
- 如果做了消息持久化,那么得等到A节点恢复,然后才可以被消费
- 如果没有持久化的话,就会产生消息丢失的现象
- 镜像模式:非常经典的mirror镜像模式,保证100%数据不会丢失
- 高可靠性解决方案,主要就是实现数据的同步,一般来讲是2-3个节点实现数据同步
- 对于100%数据可靠性解决方案,一般是采用3个节点。
- 实际工作中也是用的最多的方案,并且实现非常的简单,一般互联网大厂都会构建这种镜像集群的模式
-
集群搭建
前置条件:准备两台Linux虚拟机,并安装好RabbitMQ
集群搭建步骤:
- 修改
etc/hosts映射文件
1号服务器:给IP起个别名
127.0.0.1 A localhost localhost.localdomain localhost4 localhost4.localdomain4::1 A localhost localhost.localdomain localhost6 localhost6.localdomain6172.16.150.130 A172.16.150.131 B
2 号 服务器
127.0.0.1 B localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 B localhost localhost.localdomain localhost6 localhost6.localdomain6
172.16.150.130 A
172.16.150.131 B
修改完毕后,必须要重启服务器:reboot
重启之后1号服务器:[root@A ~]#
2号服务器:[root@B ~]#
- 相互通信,cookie必须保持一致,同步rabbitmq的cookie文件:跨服务器拷贝
.erlang.cookie隐藏文件需要使用ls -all显示
A 服务器:
[root@A ~]# cat /var/lib/rabbitmq/.erlang.cookie
MVSDETGAKZNEWVLPMWFU[root@A ~]#
B 服务器:
[root@B rabbitmq]# cat .erlang.cookie
UDOOMWLVQKDSNBEPYNYP[root@B rabbitmq]#
跨服务器拷贝到B服务器中,同步cookie文件:
[root@A ~]# scp /var/lib/rabbitmq/.erlang.cookie 172.16.150.131:/var/lib/rabbitmq/
The authenticity of host '172.16.150.131 (172.16.150.131)' can't be established.
ECDSA key fingerprint is cc:e7:f8:eb:5d:af:55:70:24:91:9a:f1:d0:43:cd:07.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '172.16.150.131' (ECDSA) to the list of known hosts.
root@172.16.150.131's password:
.erlang.cookie
然后重启A B服务器:reboot
停止防火墙,启动RabbitMQ服务
systemctl stop firewalld systemctl start rabbitmq-server加入集群节点
在服务器B操作:
rabbitmqctl stop_app # 停止节点管理
rabbitmqctl join_cluster rabbit@A # 加入A集群
rabbitmqctl start_app # 开启节点管理
查看节点状态
rabbitmqctl cluster_status查看管理端
注意:搭建集群后,之前创建的用户、交换机、队列等数据都会被隐藏起来,当脱离集群之后之前的用户、交换机、队列等数据又会重新回来。
所以搭建集群之后,需要重新创建用户。
在A服务器创建用户:
rabbitmqctl add_user prim 123456 # 添加账户信息
rabbitmqctl set_user_tags prim administrator # 设置账户标签为超级管理员
rabbitmqctl set_permissions -p "/" prim ".*" ".*" ".*" # 设置权限信息
# 查询用户列表
rabbitmqctl list_users
登录A服务器管理端查看节点信息:可以看到有两个节点A和B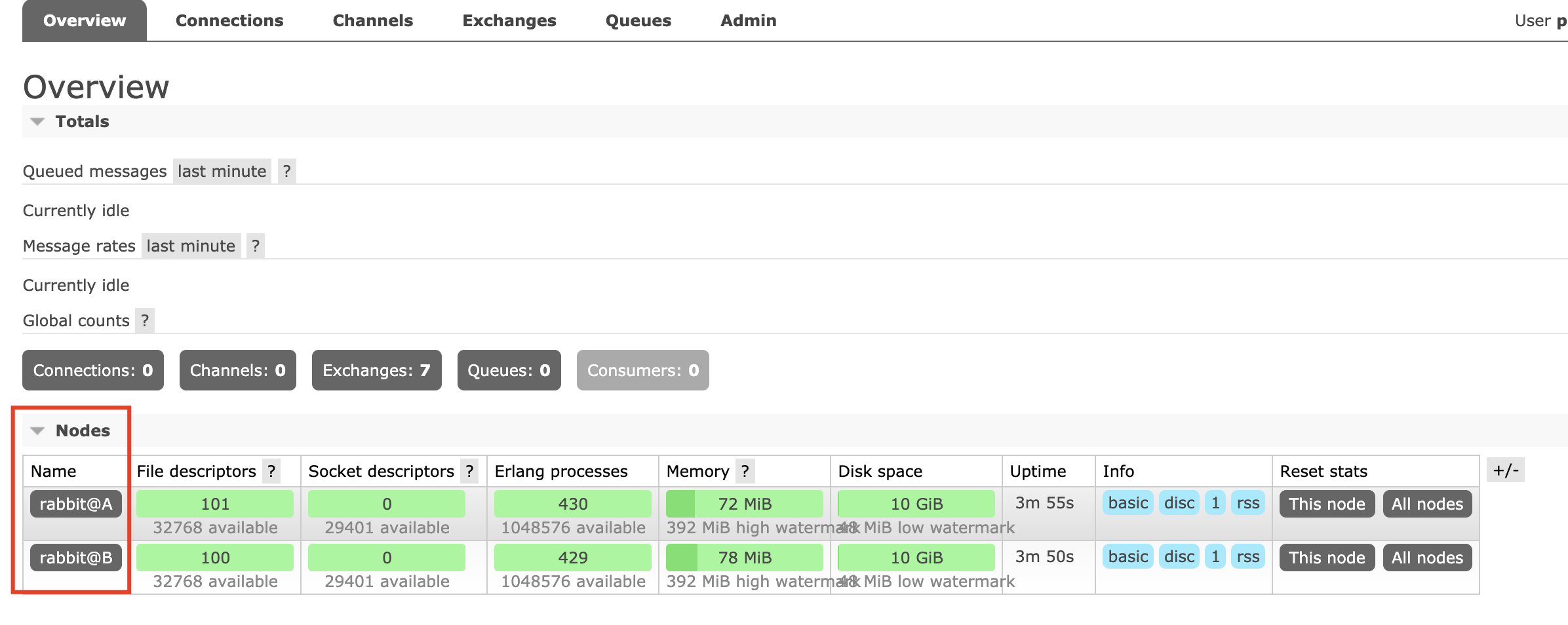
然后用相同的用户看看能否登录B服务器管理端,是可以登录的因为用户的信息同步过来了。
此时集群是普通模式,还不是镜像模式。
镜像模式
将所有队列设置为镜像队列,即队列会被复制到各个节点,各个节点状态一致。
语法:set_policy (name) {pattern}{definition}
name: 策略名,可自定义pattern:队列的匹配模式(正则表达式)^可以使用正则表达式,比如^queue_将队列名称以queue_开头的队列进行镜像,而^表示匹配所有队列definition: 镜像定义,包括三个部分:ha-modeha-paramsha-sync-modeha-modeHigh Avaliable 高可用模式,有效值为:all/exactly/nodesall: 表示集群中所有节点进行镜像exactly: 指定个数的节点上进行镜像,节点的个数由ha-params指定nodes: 指定的节点上镜像,节点名称通过ha-params指定
ha-params: ha-mode模式需要用的参数ha-sync-mode: 进行队列中消息的同步模式,有效值为:automatic和manual
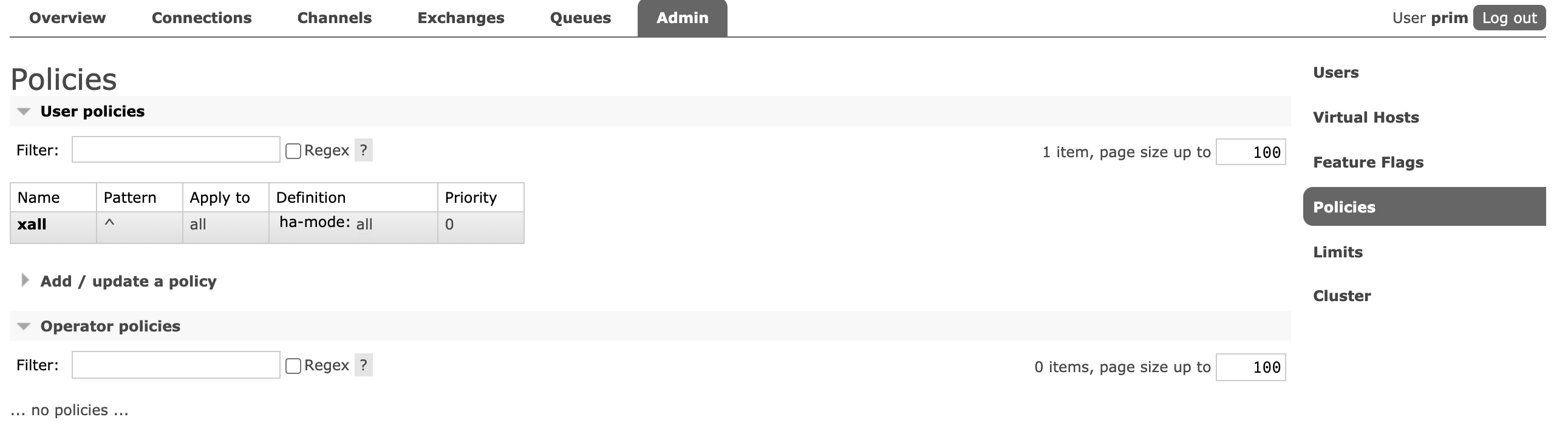
也可以通过管理端设置镜像策略:[root@A ~]# rabbitmqctl set_policy xall "^" '{"ha-mode":"all"}' Setting policy "xall" for pattern "^" to "{"ha-mode":"all"}" with priority "0" for vhost "/" ... [root@A ~]#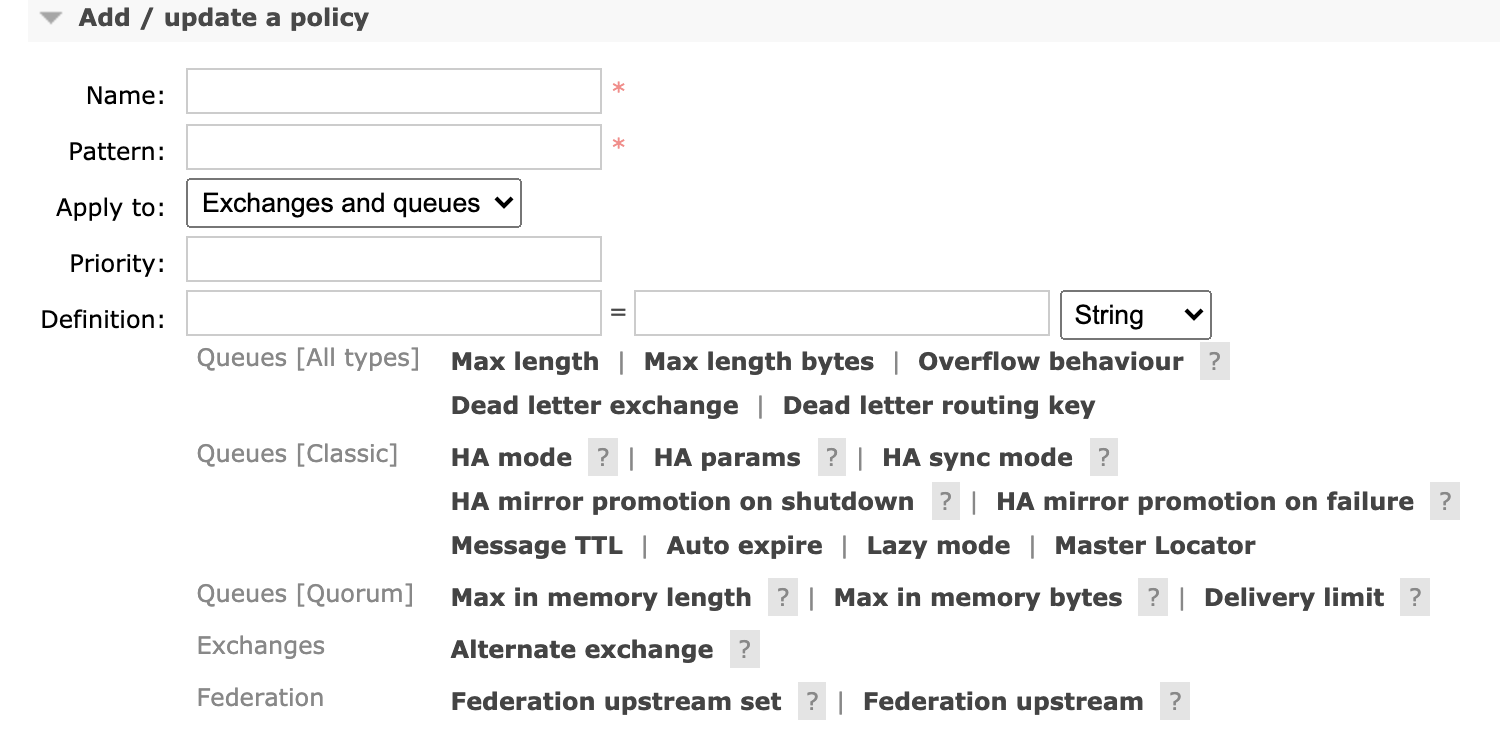
测试,使用上篇文章的代码进行测试:
RabbitMQ 入门实战
添加虚拟主机: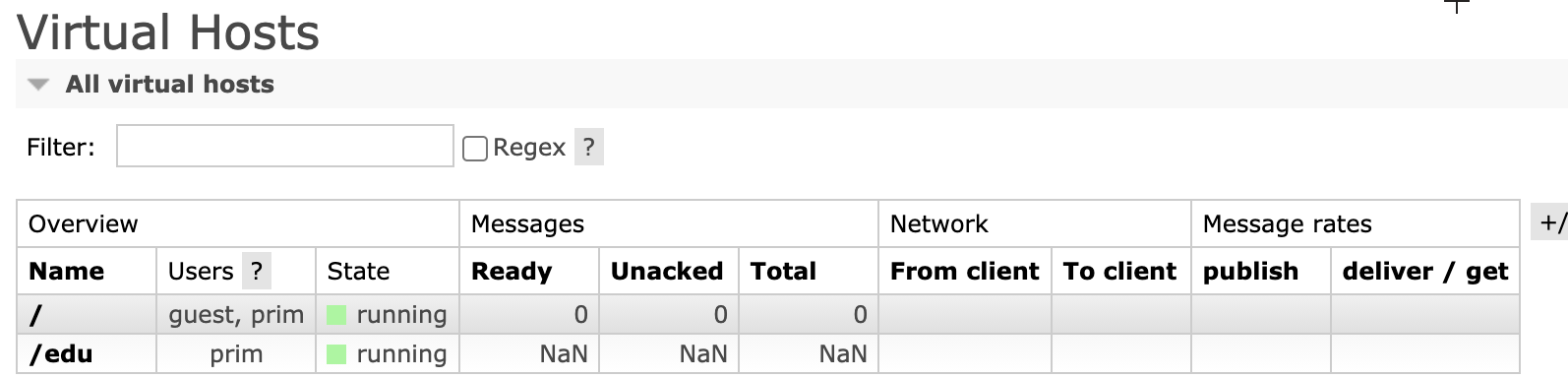
运行发送端:查看队列
下面我们来测试集群是否好使:将B服务从集群的节点停止
查看A服务器的管理端如下:显示B服务器节点没有运行[root@B ~]# rabbitmqctl stop_app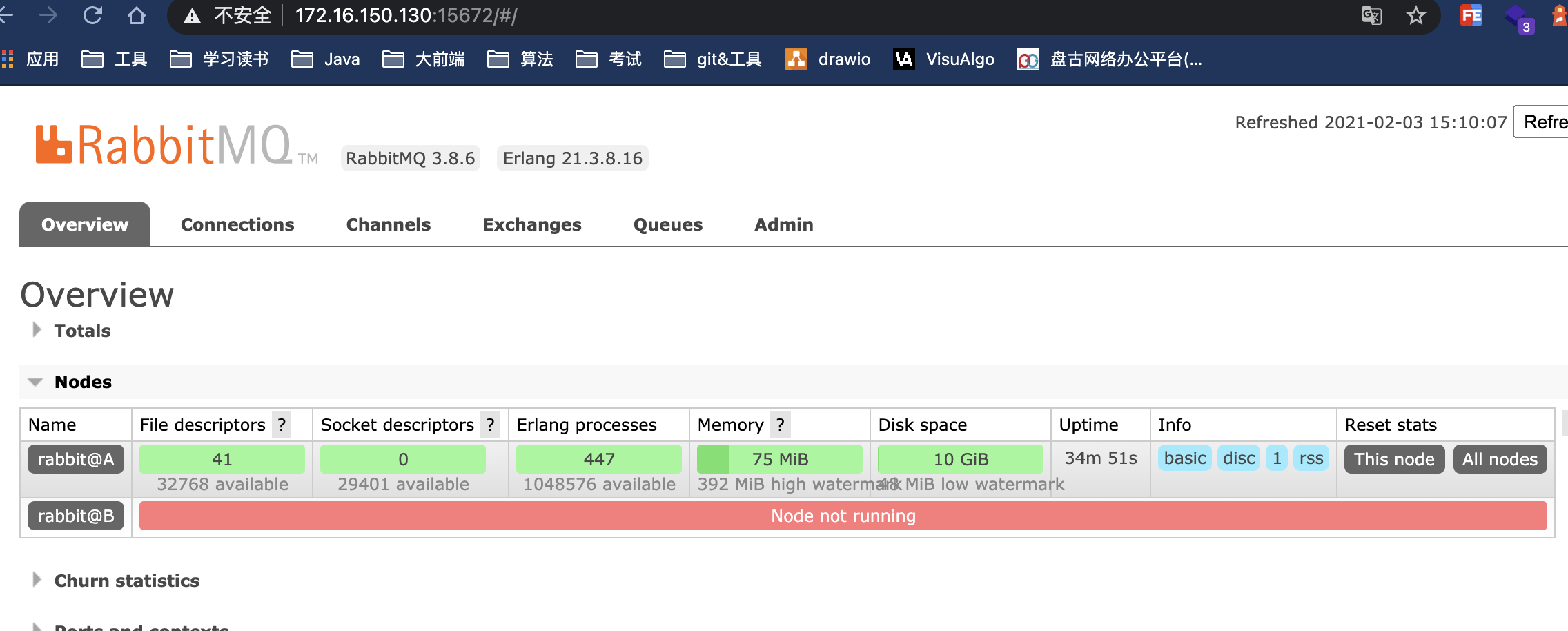
在访问B服务器的管理端,发现无法访问了。
此时我们在发送消息:A服务器死信队列有一条消息
然后我们在开启B服务器的节点,查看B服务队列是否同步:[root@B ~]# rabbitmqctl start_app
此时B服务器也同步过来了。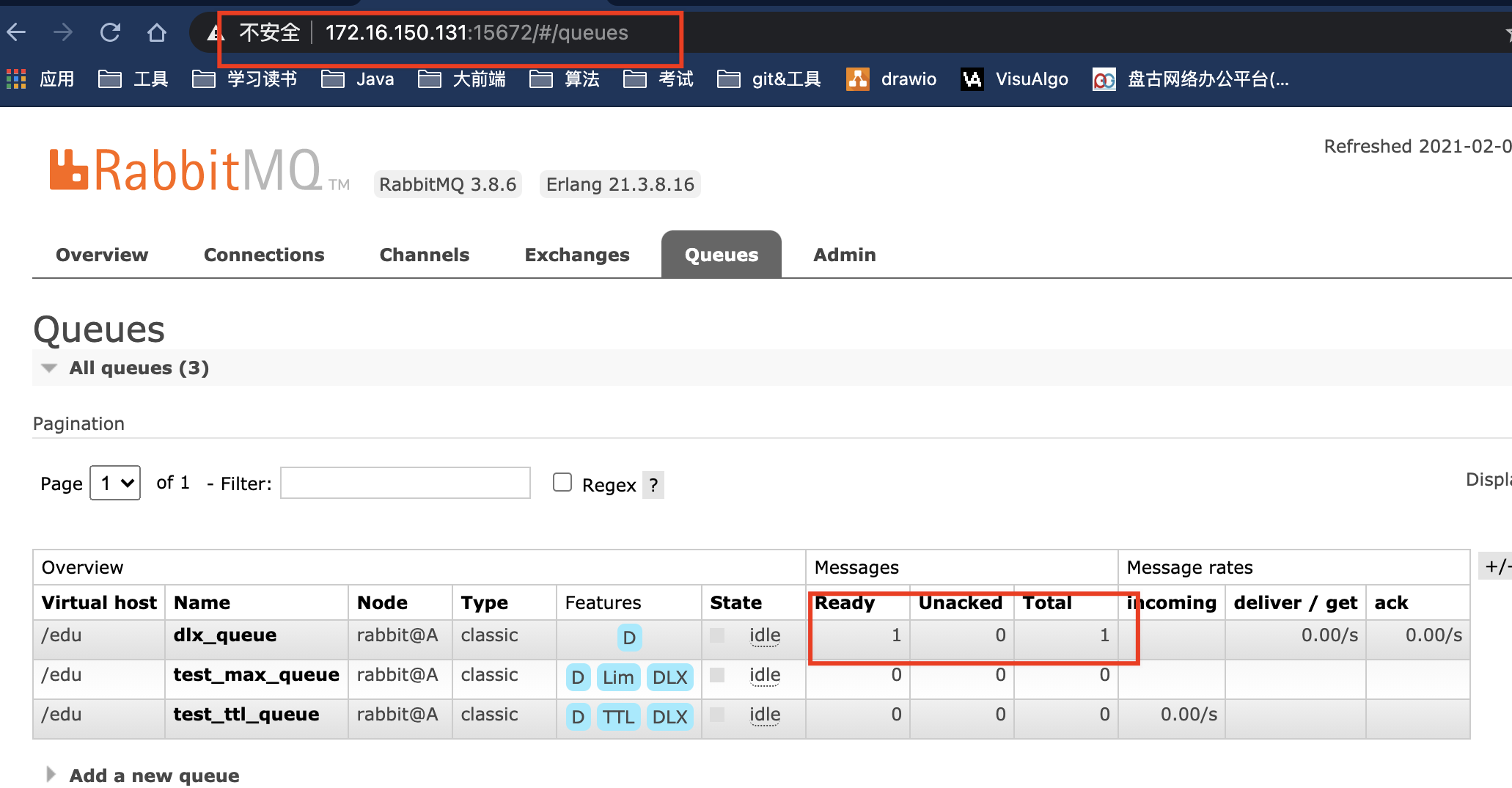
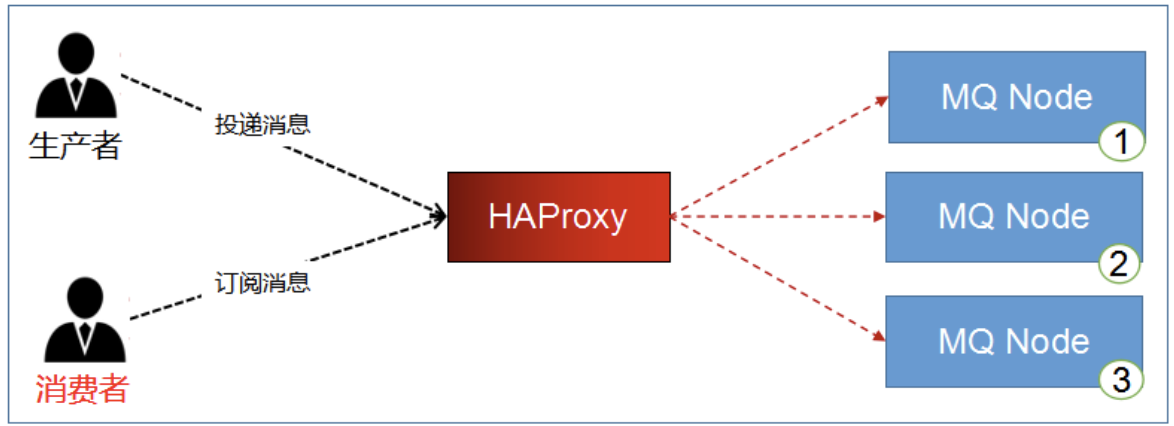
HAProxy实现镜像队列的负载均衡
在程序中访问A服务器,可以实现消息的同步,但是都是A服务器在接收消息,A太累而B太闲了。是否可以加入像Nginx一样,做负载均衡A和B轮流接收消息,再镜像同步。
HAProxy:
- HA(高可用),Proxy(代理)
- HAProxy 是一款提供高可用性、负载均衡,并且基于TCP和HTTP应用的代理软件
- HAProxy完全免费
- HAProxy可以支持数以万计的并发连接
- HAProxy 可以简单又安全的整合进架构中,同时还保护web服务器不被暴露到网络上
Nginx的优点:
- 工作在OSI第7层,可以针对http应用做一些分流的策略
- Nginx对网络的依赖非常小,理论上能ping通就就能进行负载功能,屹立至今的绝对优势
- Nginx安装和配置比较简单,测试起来比较方便;
- Nginx不仅仅是一款优秀的负载均衡器/反向代理软件,它同时也是功能强大的Web应用服务-
器
HAProxy的优点:
- 工作在网络4层和7层,支持TCP与Http协议,
- 它仅仅就只是一款负载均衡软件;单纯从效率上来讲HAProxy更会比Nginx有更出色的负载均
衡速度,在并发处理上也是优于Nginx的
- 支持8种负载均衡策略,支持心跳检测
- 性能上HA胜,功能性和便利性上Nginx胜
- 对于Http协议,Haproxy处理效率比Nginx高。所以,没有特殊要求的时候或者一般场景,建议使
- 用Haproxy来做Http协议负载
-
安装和配置
haproxy-1.8.12.tar.gz
准备第三台服务器,进行安装。 解压
tar -zvxf haproxy-1.8.12.tar.gzmake时需要使用TARGET版本指定内核及版本
[root@localhost opt]# uname -r 3.10.0-229.el7.x86_64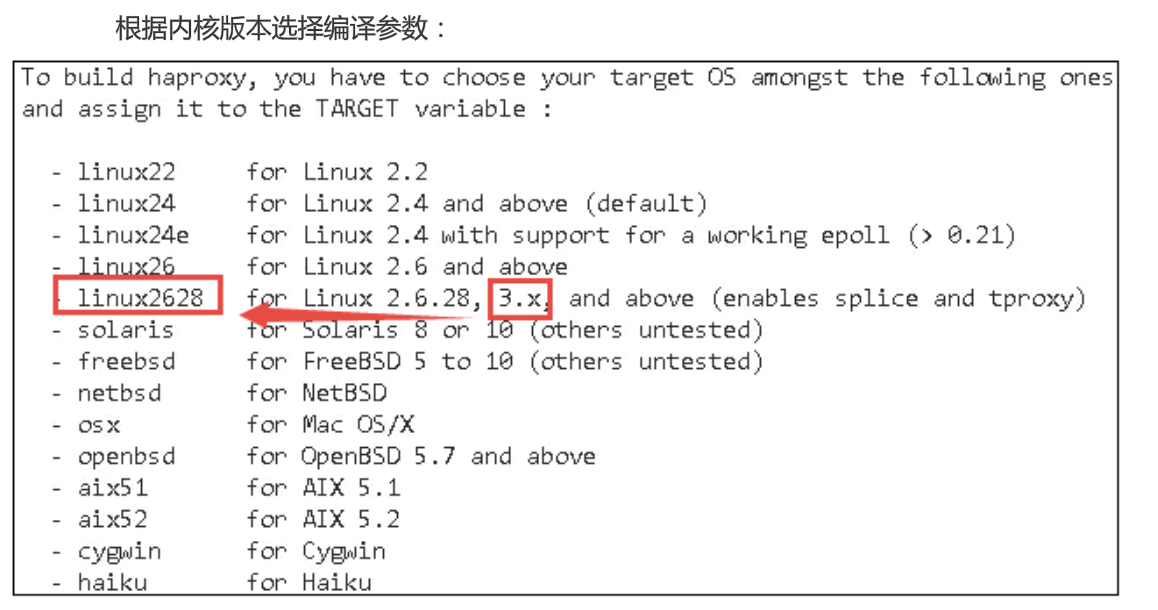
进入目录进行编译
cd haproxy-1.8.12/ make TARGET=linux2628 PREFIX=/usr/local/haproxy make install PREFIX=/usr/local/haproxy安装后,查看版本
[root@localhost haproxy-1.8.12]# /usr/local/haproxy/sbin/haproxy -v HA-Proxy version 1.8.12-8a200c7 2018/06/27 Copyright 2000-2018 Willy Tarreau <willy@haproxy.org>配置启动文件,复制haproxy文件到/usr/sbin 下,复制haproxy脚本,到
/etc/init.d下cp /usr/local/haproxy/sbin/haproxy /usr/sbin/ cp ./examples/haproxy.init /etc/init.d/haproxy chmod 755 /etc/init.d/haproxy创建系统账号
useradd -r haproxyhaproxy.cfg配置文件需要自行创建
mkdir /etc/haproxy vi /etc/haproxy/haproxy.cfg添加配置信息 ```shell
全局配置
global
设置日志
log 127.0.0.1 local0 info
当前工作目录
chroot /usr/local/haproxy
用户与用户组
user haproxy group haproxy
运行进程ID
uid 99
gid 99
守护进程启动
daemon
最大连接数
maxconn 4096
默认配置
defaults
全局配置
global
设置日志
log 127.0.0.1 local0 info
当前工作目录
chroot /usr/local/haproxy
用户与用户组
user haproxy group haproxy
运行进程ID
uid 99 gid 99
守护进程启动
daemon
最大连接数
maxconn 4096
默认配置
defaults
应用全局的日志配置
log global
默认的模式mode{tcp|http|health},TCP是4层,HTTP是7层,health只返回OK
mode tcp
日志类别tcplog
option tcplog
不记录健康检查日志信息
option dontlognull
3次失败则认为服务不可用
retries 3
每个进程可用的最大连接数
maxconn 2000
连接超时
timeout connect 5s
客户端超时30秒,ha就会发起重新连接
timeout client 30s
服务端超时15秒,ha就会发起重新连接
timeout server 15s
绑定配置
listen rabbitmq_cluster
# 本机ip端口5672,RabbitMQ直接host绑定的IP即可
bind 172.16.150.132:5672
#配置TCP模式
mode tcp
#简单的轮询
balance roundrobin
#RabbitMQ集群节点配置,每隔5秒对mq集群做检查,2次正确证明服务可用,3次失败证明服务不可用
server A 172.16.150.130:5672 check inter 5000 rise 2 fall 3
server B 172.16.150.131:5672 check inter 5000 rise 2 fall 3
haproxy监控页面地址
listen monitor bind 172.16.150.132:8100 mode http option httplog stats enable
#监控页面地址http://192.168.204.143:8100/monitor
stats uri /monitor
stats refresh 5s
- 启动代理
```shell
systemctl start haproxy
遇到的问题:如果你还遇到了其他问题可以操作文章最后的:启动警告和错误方案
:::tips
报错 Starting proxy rabbitmq: cannot bind socket :
# 开启允许绑定非本机的IP
[root@localhost sbin]# vi /etc/sysctl.conf
在配置中添加:net.ipv4.ip_nonlocal_bind = 1
[root@localhost sbin]# sysctl -p
[root@localhost sbin]# systemctl start haproxy
[root@localhost sbin]# netstat -lntup
:::
haproxy就启动成功了。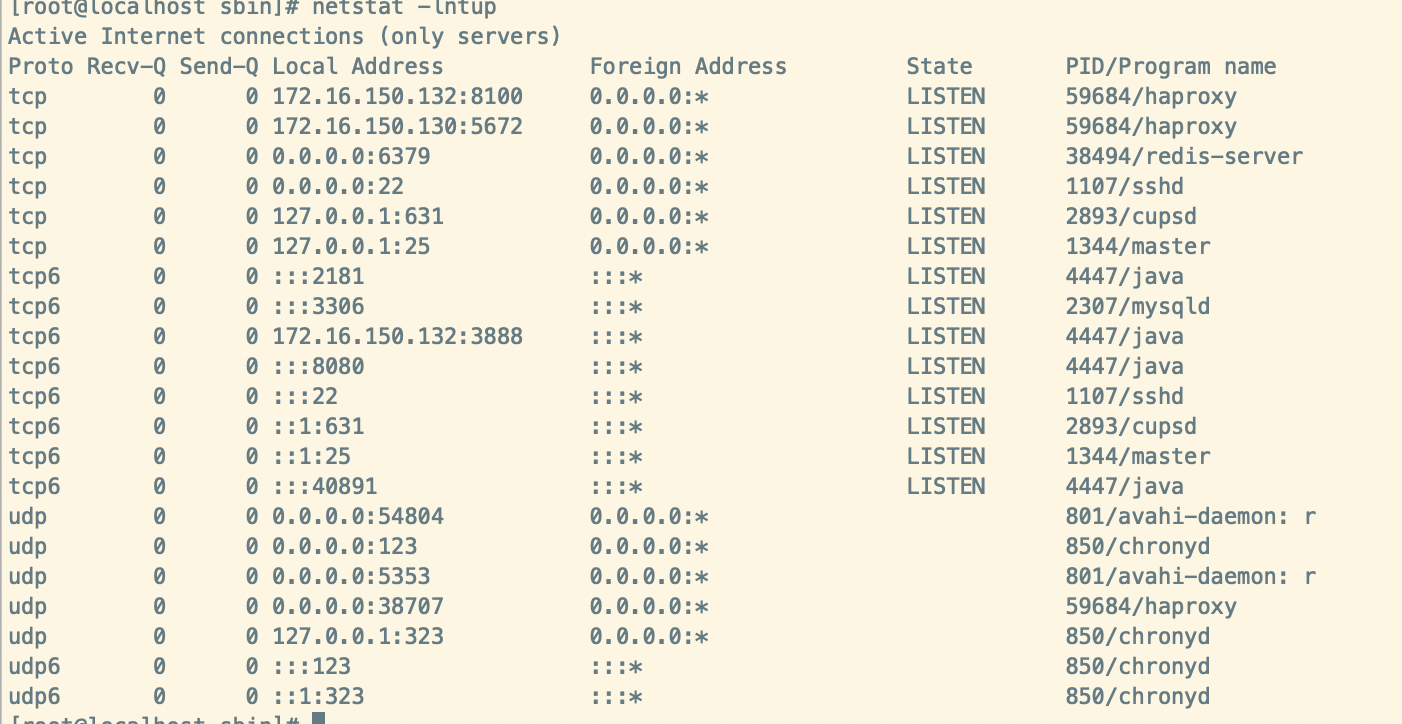
访问监控中心:
http://172.16.150.132:8100/monitor测试 将发送端项目中的host改为:
172.16.150.132即可<rabbit:connection-factory id="connectionFactory" host="172.16.150.132" port="5672" username="prim" password="123456" virtual-host="/edu"/>KeepAlived搭建高可用的HAProxy集群
现在的最后一个问题暴露出来了,如果HAProxy服务器宕机,rabbitmq服务器就不可用了。所以我们需要对HAProxy也要做高可用的集群。
Keepalived是Linux下一个轻量级别的高可用热备解决方案
- Keepalived的作用是检测服务器的状态,它根据TCP/IP参考模型的第三、第四层、第五层交换机

制检测每个服务节点的状态,如果有一台web服务器宕机,或工作出现故障,Keepalived将检测
到,并将有故障的服务器从系统中剔除,同时使用其他服务器代替该服务器的工作,当服务器工作
正常后Keepalived自动将服务器加入到服务器群中,这些工作全部自动完成,不需要人工干涉,
需要人工做的只是修复故障的服务器。
- keepalived基于vrrp(Virtual Router Redundancy Protocol,虚拟路由冗余协议)协议,vrrp它
是一种主备(主机和备用机)模式的协议,通过VRRP可以在网络发生故障时透明的进行设备切换
而不影响主机之间的数据通信
- 两台主机之间生成一个虚拟的ip,我们称漂移ip,漂移ip由主服务器承担,一但主服务器宕机,备
份服务器就会抢夺漂移ip,继续工作,有效的解决了群集中的单点故障
说白了,将多台路由器设备虚拟成一个设备,对外提供统一ip(VIP)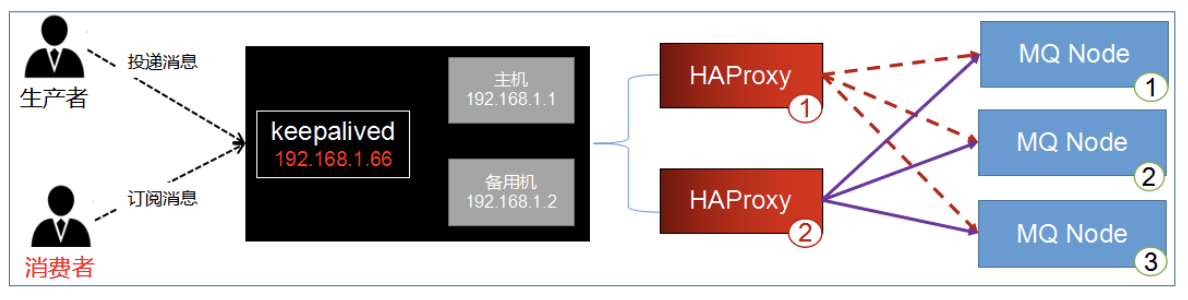
安装keepAlived
准备两个服务器132和133,修改hosts主机名C和D
为了省事目前只用一个132服务器,至于133服务器和132服务器搭建是类似的
127.0.0.1 C localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 C localhost localhost.localdomain localhost6 localhost6.localdomain6
172.16.150.130 A
172.16.150.131 B
172.16.150.132 C
172.16.150.133 D
安装:
yum install -y keepalived配置
[root@C~]#rm -rf /etc/keepalived/keepalived.conf [root@C~]#vim /etc/keepalived/keepalived.conf配置文件:
! Configuration File for keepalived global_defs { router_id C ## 非常重要,标识本机的hostname } vrrp_script chk_haproxy{ script "/etc/keepalived/haproxy_check.sh" ## 执行的脚本位置 interval 2 ## 检测时间间隔 weight -20 ## 如果条件成立则权重减20 } vrrp_instance VI_1 { state MASTER ## 非常重要,标识主机,备用机143改为 BACKUP interface ens33 ## 非常重要,网卡名(ifconfig查看) virtual_router_id 66 ## 非常重要,自定义,虚拟路由ID号(主备节点要相同) priority 100 ## 优先级(0-254),一般主机的大于备机 advert_int 1 ## 主备信息发送间隔,两个节点必须一致,默认1秒 authentication { ## 认证匹配,设置认证类型和密码,MASTER和BACKUP必须使用相同的密码才能正常通信 auth_type PASS auth_pass 1111 } track_script { chk_haproxy ## 检查haproxy健康状况的脚本 } virtual_ipaddress { ## 简称“VIP” 192.168.204.66/24 ## 非常重要,虚拟ip,可以指定多个,以后连接mq就用这个虚拟ip } } virtual_server 192.168.204.66 5672 { ## 虚拟ip的详细配置 delay_loop 6 # 健康检查间隔,单位为秒 lb_algo rr # lvs调度算法rr|wrr|lc|wlc|lblc|sh|dh lb_kind NAT # 负载均衡转发规则。一般包括DR,NAT,TUN 3种 protocol TCP # 转发协议,有TCP和UDP两种,一般用TCP real_server 192.168.204.143 5672 { ## 本机的真实ip weight 1 # 默认为1,0为失效 } }创建执行脚本
/etc/keepalived/haproxy_check.sh#!/bin/bash COUNT=`ps -C haproxy --no-header |wc -l` if [ $COUNT -eq 0 ];then /usr/local/haproxy/sbin/haproxy -f /etc/haproxy/haproxy.cfg sleep 2 if [ `ps -C haproxy --no-header |wc -l` -eq 0 ];then killall keepalived fi fi对脚本授权,否则不能执行
chmod +x haproxy_check.sh启动keepalived
service keepalived start输入
ip a可以看到在配置keepalived是添加的vvip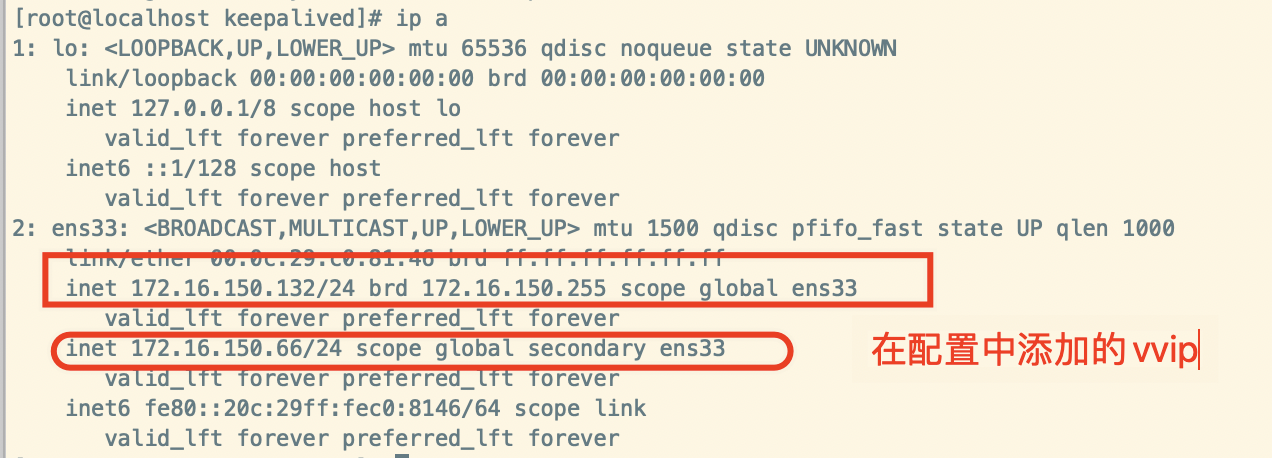
注意:如下图的圈住的部分一定要保持一致,否则会失败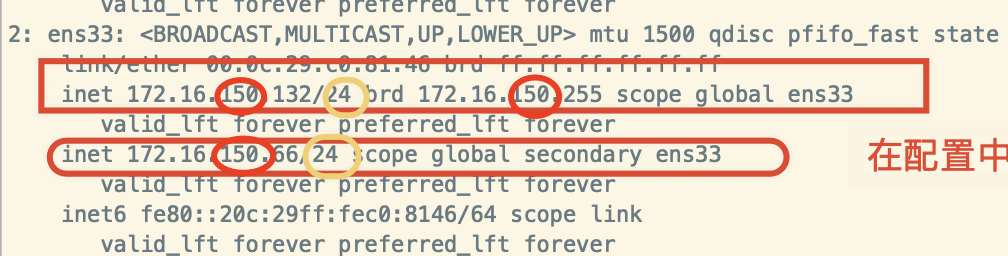
测试
本机IP和虚拟IP返回一致说明配置成功,可以使用了
[root@localhost keepalived]# curl 172.16.150.132:5672
AMQP
[root@localhost keepalived]# curl 172.16.150.66:5672
AMQP
- 在133服务器创建备用机keepalived,同样需要安装HAProxy以及Keepalived,直接克隆132虚拟机即可
配置host
127.0.0.1 D localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 D localhost localhost.localdomain localhost6 localhost6.localdomain6 172.16.150.130 A 172.16.150.131 B 172.16.150.132 C 172.16.150.133 D安装HAproxy和Keepalived这里就不再重复写了,忘了看上面的
- 修改keepalived配置文件
global_defs { router_id D ## 非常重要,标识本机的hostname } vrrp_instance VI_1 { state BACKUP ## 非常重要,标识主机,备用机143改为 BACKUP } virtual_server 192.168.204.66 5672 { ## 虚拟ip的详细配置 ..... real_server 192.168.204.144 5672 { ## 本机的真实ip ..... }
在代码中,直接访问虚拟IP即可172.16.150.66,HAProxy我们有两个服务器132(主机)和133(备机),当132宕机,那么133就会启用继续保证HAProxy可以正常访问到RabbitMQ服务器。
这样我们就避免了单个HAProxy负载均衡,当单个HAProxy宕机,导致RabbitMQ服务器无法访问。高可用性
<rabbit:connection-factory
id="connectionFactory"
host="172.16.150.66"
port="5672"
username="prim"
password="123456"
virtual-host="/edu"/>

消费端也配置:172.16.150.66,运行消费积压的消息

OK,到此我们搭建了一个高可用、高性能的RabbitMQ集群。
启动警告和错误方案
启动时报如下警告
[WARNING] 102/151915 (11151) : Proxy ‘http_gsres‘: in multi-process mode, stats will be limited to process assigned to the current request.
解决方案:
nbproc进程设置为1则不会提示,如果想去掉这个提示可以修改编译文件即可。 在源码配置src/cfgparse.c找到如下行
if (nbproc > 1) { if (curproxy->uri_auth) { - Warning(“Proxy ‘%s’: in multi-process mode, stats will be limited to process assigned to the current request.\n”, + Warning(“Proxy ‘%s’: in multi-process mode, stats will be limited to the process assigned to the current request.\n”,
调整nbproc > 1数值即可。
haproxy启动报错Starting proxy : cannot bind socket
解决方案
查看haproxy.conf配置文件
发现其监听80跟apache或nginx冲突,而apache或nginx没在使用,关闭或者卸载。
查看netstat -ntpl
如果有80端口,说明80被占用了,只需要找到程序关闭即可,一般是apache的进程
/usr/local/apache/bin/apachectl stop
再执行:
/usr/local/haproxy/sbin/haproxy -f /usr/local/haproxy/conf/haproxy.cfg
就可以了!
[/usr/local/haproxy/sbin/haproxy.main()] Cannot chroot1(/var/lib/haproxy).
解决方案:
将chroot指定文件改为/usr/local/haproxy 或者 注释掉
[/usr/local/haproxy/sbin/haproxy.main()] FD limit (16384) too low for maxconn=20000/maxsock=40022. Please raise ‘ulimit-n’ to 40022 or more to avoid any trouble.
暂时未找到,希望有人能在评论提供
[ALERT] 014/193706 (2346) : parsing [/usr/local/haproxy/conf/haproxy.cfg:11] : user/uid already specified. Continuing.
解决方案:
注释掉user haproxy

若有收获,就点个赞吧
0 人点赞
