 ">
">
引言
在目前学习的几种机器学习理论中,标准方程可以说是最直观,最易实现的一种机器学习方式,但是由于其算法过于简单,最终的结果也比较大,同时也不适合特征数据较大的情况。不过,对我这个机器学习的小白还是比较有意思的,于是我尝试用标准方程预测了波士顿房价。
内容
公式


目标

计算
提取数据
import numpy as npimport matplotlib.pyplot as plt# 训练数据dataTrain = np.loadtxt(open("train.csv","rb"),delimiter=",",skiprows=1)data_X = dataTrain[0:405,0:13]data_Y = dataTrain[0:405,13:14]# 测试数据test = np.loadtxt(open("test.csv","rb"),delimiter=",",skiprows=1)test = test[0:103,0:13]# 真实值price = np.loadtxt(open("submission.csv","rb"),delimiter=",",skiprows=1)price = price[0:103,0:1]
标准方程
def calc_weights(X_data, y_data):x_mat = np.mat(X_data)y_mat = np.mat(y_data)xT_x = x_mat.T * x_matif np.linalg.det(xT_x) == 0:print("x_mat为不可逆矩阵,不能使用标准方程法求解")returnweights = xT_x.I * x_mat.T * y_matreturn weights
预测
# 计算weights = calc_weights(data_X,data_Y)# 预测testPrice = test * weights# 打印print(testPrice.T)# 计算方差mse = 0for index in range(102):mse += (price[index] - testPrice[index])*(price[index] - testPrice[index])mse = mse / 102print(mse)
结果
[[19.87154627 12.74339681 11.25930362 20.11611177 21.82954216 19.7073790536.21952677 15.77135065 25.81183007 21.78250441 27.25072439 36.023709415.26689645 25.17598479 8.27260358 24.63741852 18.66512718 18.0486422331.33845725 23.45452335 12.2193436 18.45271625 16.62794516 18.1478380833.40137474 13.81036212 23.62470081 25.51070961 12.12006742 33.6932910316.21603983 27.45778447 4.24179304 16.95988225 29.30180957 34.2433364524.48626971 4.22911818 19.62051458 27.29868581 18.28141171 12.9728024831.07983641 14.03578931 28.71095795 22.12486456 21.39391063 16.4903296125.70217547 20.61918732 19.01664558 34.94595038 11.82504913 16.3372106924.38163508 14.88818189 26.50427758 11.04433601 23.66484002 22.8698112617.00514905 20.54492118 36.92735726 21.00451268 19.50612881 25.4925309827.37327027 -2.60912722 13.23106311 29.36430635 21.85888623 19.4472968113.04013028 25.60370043 18.11523322 44.64196252 21.16066692 0.3970078117.54093204 25.04123178 21.35947191 8.20954163 19.12299022 22.672036921.4882735 19.8568071 44.53544902 15.16798396 45.43652856 31.9732690531.4268688 21.21379429 9.25738545 13.48461408 15.11924347 32.1747508222.97028779 22.13800537 16.91068175 19.81034215 15.41315043 21.55994875]][[25.95242741]]
分析
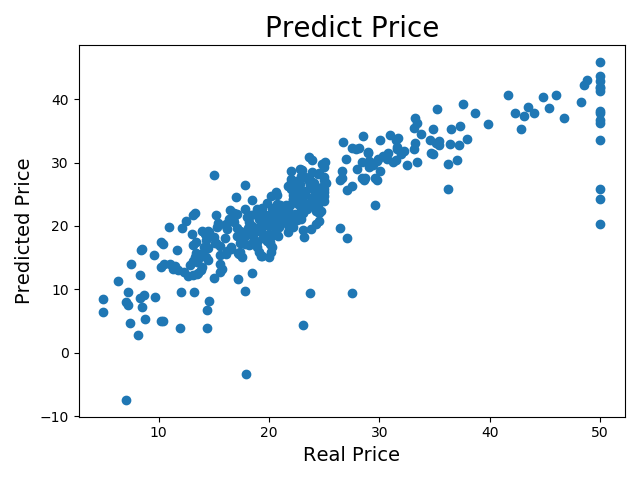
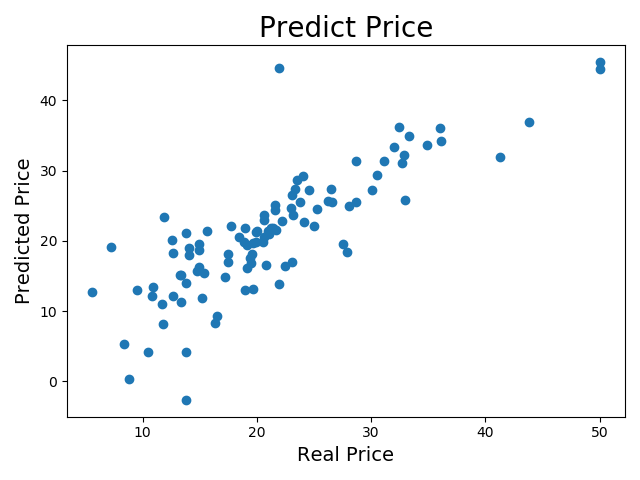
为了更加直观,我使用matplotlib作了一个简单的图形,同时为了验证θ的准确性,我用θ重新计算了训练集中的房价
代码
# 二维转一维def twoToOne(price2):price2 = price2.Tprice2 = np.array(price2)real = [i for j in price2 for i in j]return real# 打印预期结果def drawWish(draw_X,draw_Y):draw_X = twoToOne(draw_X)draw_Y = twoToOne(draw_Y)plt.scatter(draw_X,draw_Y)plt.show()printWish(price,testPrice)# 检验testPrice1 = data_X*weightsdrawWish(data_Y,testPrice1)
结果
总结
完美的情况应该是所有点在y=x这条直线上,然而事实并非如此。
从预测图中可以明显看出模型的拟合度,大部分与实际差不多,甚至从结果数据上看部分预测值甚至没有差距,但有的却差得不符实际了,特别是有价格尽然是负数,也是这些点直接导致了mse的增大。那么这是为什么呢?
其实从重新计算的训练集价格图可以看出,与正常的预测图一样,其中大部分都聚集在一条直线上,但也就是聚集,并不是完全拟合到直线上,其中依然有不少的点远离了实际值,甚至出现了负值,这直接说明计算出来的θ并不是完全正确的,其中存在误差,公式可能没有错,但是计算的精度存在问题,这导致重新再计算回来的时候与原来的结果不一样了。
综上,只是简单的标准方程是明显不够的,还需要其它的更加高明的模型来实现。所以后期就需要学习使用tensorflow来搭建高明的机器学习系统。

若有收获,就点个赞吧
0 人点赞
