损失函数(loss function)或代价函数(cost function)是将随机事件或其有关随机变量的取值映射为非负实数以表示该随机事件的“风险”或“损失”的函数。在应用中,损失函数通常作为学习准则与优化问题相联系,即通过最小化损失函数求解和评估模型。例如在统计学和机器学习中被用于模型的参数估计(parameteric estimation) ,在宏观经济学中被用于风险管理(risk mangement)和决策 ,在控制理论中被应用于最优控制理论(optimal control theory) 。
————《百度百科》
为什么使用损失函数:有了模型的假设空间后,统计学习接着需要考虑的是按照什么样的准则学习或选择最优的模型!统计学习的目标在于从假设空间中选取最优模型。损失函数就用于度量模型预测的好坏。
简单理解:损失函数衡量模型预测的好坏。损失函数就是用来表现预测与实际数据的差距程度。
比如你要做一个线性回归,你拟合出来的曲线不会和原始的数据分布是完全吻合(完全吻合的话,很可能会出现过拟合的情况),这个差距就是用损失函数来衡量。那么损失函数的值越小,模型的鲁棒性也就越好,对新数据的预测能力也就越强。
损失函数分类:
- 0-1损失函数:

当预测错误时,损失函数结果为1;当预测正确时,损失函数为0。该预测并不考虑具体的误差程度,直接进行二值化。
优点:稳定的分类面,不连续,所以不可导,但是次梯度可导
缺点:二阶不可导,有时候不存在唯一解
- 平方损失函数:

预测值与实际值的差的平方。一般用在线性回归中。
优点:容易优化(一阶导数连续)
缺点:对outlier点敏感,得不到最优的分类面
- 绝对值损失函数
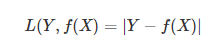
实际值与测试值的差值的绝对值。一般与平方损失函数相比较判断模型的优劣。
- 对数损失函数

对数损失函数用到了极大似然估计的思想。P(Y|X)表示在当前模型上,样本X的预测值为Y的概率,也就是说对于样本
X预测正确的概率。由于统计极大似然估计用到概率乘法,为了将其转为假发,对其取对数即可方便展开为加法;由于是损失函数,预测正确的概率应该与损失值成反比,
这里对概率取反得到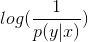 ,转化一下可以得到
,转化一下可以得到  。
。
优点:稳定的分类面,严格凸,且二阶导数连续。
缺点:(没能弄懂。。。静待有缘人的解惑)
损失函数值越小,模型就越好。
应用**:
首先我们假设要预测一个公司某商品的销售量:

X:门店数 Y:销量
我们会发现销量随着门店数上升而上升。于是我们就想要知道大概门店和销量的关系是怎么样的呢?
我们根据图上的点描述出一条直线:
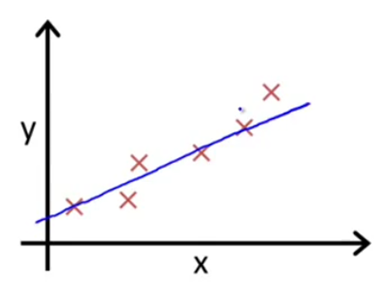
这个直线差不多能说明门店数X和Y得关系了:我们假设直线的方程为Y=a0+a1X(a为常数系数)。假设a0=10 a1=3 那么Y=10+3X(公式1)
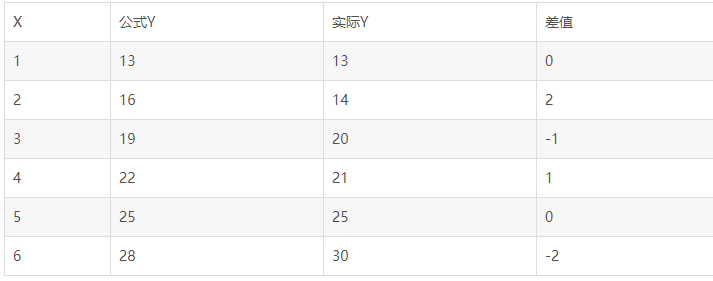
假设我们再模拟一条新的直线:a0=8,a1=4

公式2 Y=8+4X
绝对损失函数求和:11 平方损失函数求和:27
公式1 Y=10+3X
绝对损失函数求和:6 平方损失函数求和:10
从损失函数求和中,就能评估出公式1能够更好得预测门店销售。
参考资料:https://blog.csdn.net/qq_24753293/article/details/78788844
https://blog.csdn.net/haoji007/article/details/89015675
https://blog.csdn.net/chkay399/article/details/81878157
若有不足或错误,请联系我,虽然我也不会改。

若有收获,就点个赞吧
0 人点赞
