机器学习与深度学习—日常学习笔记
影响因素:计算能力、数据、算法的发展
机器学习、深度学习能做些什么:
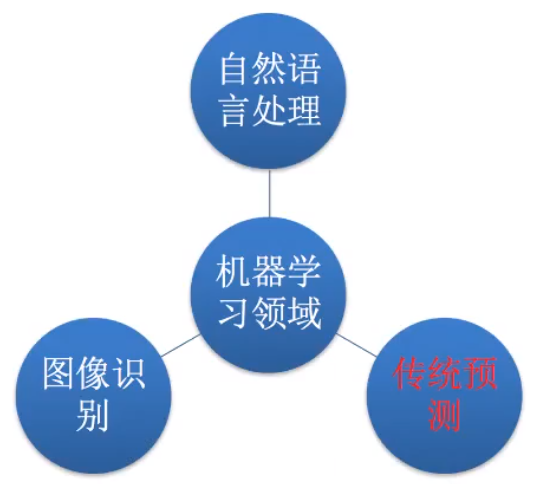
机器学习库和框架:


学习书籍推荐:

机器学习课程概要:

1、机器学习概述
1.1定义:
机器学习: 机器学习就是从**数据**中自动分析获得**规律(模型)**,并利用规律对**未知数据进行预测**
1.2为什么需要机器学习:
1、解放生产力;2、解决专业问题;3、提供社会便利;
1.3机器学习在各领域带来的价值:
让机器学习程序替代手动的步骤,减少企业的成本也提高企业的效率。<br />
2、数据集的结构
机器学习的数据:文件csv
注:mysql: 1、容易遭到性能瓶颈,读取速度不行,数据变大,速度就很慢;
2、格式不太符合机器学习要求数据的格式;
pandas: 读取工具 真正的多线程
numpy:动态语言、释放GIL
1、历史遗留问题
2.1可用的数据集:

2.2常用数据集数据的结构组成:
结构:特征值+目标值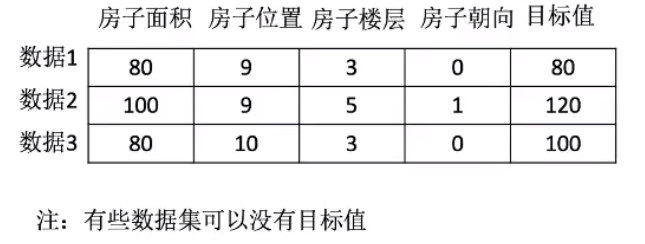
2.3数据中对于特征的处理:
pandas: 一个数据读取非常方便以及基本的处理格式的工具;
sklearn: 对于特征的处理提供了强大的接口;
注 :机器学习中数据有重复,不需要进行去重
3、数据的特征工程
3.1特征工程是什么:
特征工程是将**原始数据转换为更好地代表预测模型的潜在问题的特征**的过程,从而**提高了对未知数据的预测准确性。**(提高预测效果)
3.2特征工程的意义:
直接影响预测结果
特征抽取对文本等数据进行特征值化; 注: 特征值化是为了计算机更好的去理解数据。
**sklearn特征抽取API**1、sklearn.feature_extraction
3.3字典特征抽取
作用:对字典数据进行特征值化;
类: sklearn.feature_extration.DicVectorizer
DictVectorizer语法
流程
1、实例化类DictVectorizer
2、调用fit_transform方法输入数据并转换
注意返回格式
(sparse矩阵格式:节约内存,方便读取处理)
(ndarray: 二维数组)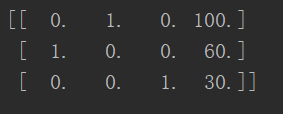
字典数据抽取:
把字典中一些类别数据,分别进行转换成特征;数组形式,有类别的这些特征:先要转换成字典数据One-hot编码
3.4文本特征抽取
作用: 对文本数据进行特征值化
类: sklearn.feature_extraction.text.CountVectorizer
流程:
1、实例化类CountVectorizer2、调用fit_transform方法输入数据并转换**注意:** 返回格式,利用toarray()进行sparse矩阵转换array数组
结果分析:1、统计所有文章当中所有的词,重复的只看做一次;
2、对每篇文章,在词的列表里面进行统计每个词出现的次数;3、单个字母不统计;(对于单个英文字母:没有分类依据)
如何对中午文本特征值化:(不支持单个中文字!)———需要对中文进行分词才能详细的进行特殊值化
案例:对三段话进行特征值化—-流程
1、准备句子,利用jieba.cut进行分词;2、实例化CountVectorizer;3、将分词结果变成字符串当作fit_transform的输入值;<br />
tf * idf 重要性程度
Tf: term frequency: 词的频率
idf: 逆文档频率inverse document frequency log(总文档数量/该词出现的文档数量)
**注:**log(数值):输入的数值越小,结果越小<br /><br />**为什么需要TfidfVectorizer:**分类机器学习算法的重要依据
3.5特征的预处理:对数据进行处理
三个特征同等重要的时候:进行归一化
目的:使得某一个特征对最终结果不会造成更大影响
介绍:特征预处理是通过特定的统计方法(数学方法)将数据转换成算法要求的数据
数值型数据:标准缩放:1、归一化; 2、标准化; 3、缺失值
类别型数据:one-hot编码
时间类型:时间的切分
1、特征预处理的方法
**2、sklearn特征预处理API: sklearn.preprocessing**<br /> <br /><br /> <br />  <br /> <br /> <br />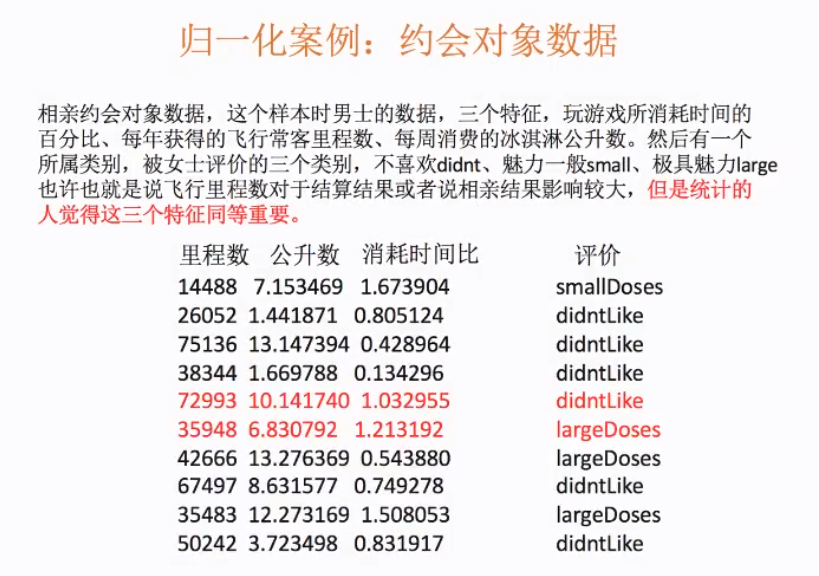<br />**问题:如果数据中异常点较多,会有什么影响???**
结果:异常点对最大值最小值影响太大


鲁棒性:反映产品的稳定性

1、特点:通过对原始数据进行交换把数据交换到均值为0,标准差为1范围内
标准化是使用最常见的!!!









如何处理数据中的缺失值???
缺失值处理方法:
1、**删除**----如果每列或者行数据缺失值达到一定的比例,建议放弃整行或者整列;2、**插补**----可以通过缺失值每行或者每列的平均值、中位数来填充;3、sklearn缺失值API: sklearn.preprocessing.Imputer;<br /><br /><br /> **数据当中的缺失值:**np.nam<br /><br /><br />
关于np.nan(np.NaN):
1、numpy的数组中可以使用np.nan/np.NaN来代替缺失值,属于float类型;
2、如果是文件中的一些缺失值,可以替换成nan,通过np.array转化成float型的数组即可;
3.6数据降维
降维:维度:特征的数量
降维方式:
1、特征选择:
原因:1、冗余:部分特征的相关度高,容易消耗计算性能;2、噪声:部分特征对预测结果有影响;特征选择就是单纯地从提取到的所有特征中选择部分特征作为训练集特征,特征在选择前和选择后可以 改变值,也不改变值,但是选择后的特征维数肯定比选择前小,毕竟我们只选择了其中的一部分特征;**主要方法:** **Filter(过滤式): VarianceThreshold****Embedded(嵌入式): 正则化、决策树**Wrapper(包裹式)<br /> <br /> <br /> <br />**2、主成分分析:**<br /><br />
PCA是什么???(特征数量达到上百的时候 考虑数据的简化 数据也会改变,特征数量也会减少)
本质:PCA是一种分析、简化数据集的技术;
目的:是数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量信息;
作用:可以削减回归分析或者聚类分析中特征的数量;

注: n_components:小数(095%))、整数—-一般不使用(减少到的特征数量)
4、数据的类型
5、机器学习算法基础
需明确几点问题:
(1)**算法**是核心,**数据**和**计算**是基础(2)**找准定位**大部分复杂模型的算法设计都是算法工程师在做,而我们:
- 分析很多的数据
- 分析具体的业务
- 应用常见的算法
- 特征工程、调参数、优化
数据类型:
- 离散型数据: 由记录不同类别个体的数目所得到的数据,又称计数数据,所有这些数据全部都是整数,而且不能再细分,也不鞥进一步提高它们的精确度;
- 连续性数据:变量可以在某个范围内去任一数,即变量的取值可以是连续的,如,长度、时间、质量值等,这类整数通常是非整数,含有小数部分;
注:只要记住一点,离散型是区间内不可分,连续性是区间内可分;
我们应该怎么做:
- 学会分析问题,使用机器学习算法的目的,想要算法完成何种任务;
- 掌握算法基本思想,学会对问题用相应的算法解决;
- 学会利用库或者框架解决问题;
5.1 机器学习开发流程
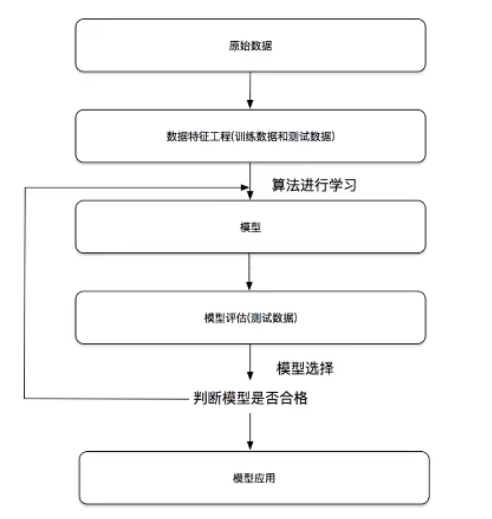
5.2 机器学习算法分类
- 监督学习(预测)特征值+目标值
- 分类—-(目标值离散型) k-近邻算法、 贝叶斯分类、决策树与随机森林、逻辑回归、神经网络
- 回归—-(目标值连续型) 线性回归 岭回归
- 标注 隐马尔可夫模型(不做要求)
- 无监督学习 特征值
- 聚类 k-means

监督学习:
监督学习(英语:Supervised learning),可以由输入数据中学到或建立一个模型,并依此模式推测新的结果。输入数据是由输入特征值和目标值所组成。函数的输出可以是一个连续的值(称为回归),或是输出是有限个离散值(称为分类)。
无监督学习:
无监督学习(英语:unSupervised learning),可以由输入数据中学到或建立一个模型,并依此模式推测新的结果。输入数据是由输入特征值所组成。
概念:
分类是监督学习的一个核心问题,在监督学习中,当输出变量取有限个离散值时,预测问题变成为分类问题。最基础的便是二分类问题,即判断是非,从两个类别中选择一个作为预测结果;
分类问题的应用:
概念:
回归是监督学习的另一个重要问题。回归用于预测输入变量和输出变量之间的关系,输出是连续型的值。
回归问题的应用:

5.3 机器学习模型是什么

若有收获,就点个赞吧
0 人点赞
