机器学习
机器学习的核心是“使用算法解析数据,从中学习,然后对世界上的某件事情做出决定或预测”。这意味着,与其显式地编写程序来执行某些任务,不如教计算机如何开发一个算法来完成任务。有三种主要类型的机器学习:监督学习、非监督学习和强化学习,所有这些都有其特定的优点和缺点。
机器识别
步骤一:
创建function
Linear Model 线性模型
Deep Learning 深度学习 == 特别复杂的function == 能做特别复杂的事。
步骤二:
machine可以自动衡量function的好坏,这需要确定一个衡量标准,也就是我们通常说的损失函数(Loss Function),损失函数的确定也需要依据具体问题而定,如回归问题一般采用欧式距离,分类问题一般采用交叉熵代价函数。
步骤三:
machine有一个好的方法可以挑出最好的function,这一步是最大的难点,做到又快又准往往不是一件容易的事情。常用的方法有梯度下降算法,最小二乘法等和其他一些技巧(tricks)。
监督学习
监督学习涉及一组标记数据。计算机可以使用特定的模式来识别每种标记类型的新样本。监督学习的两种主要类型是分类和回归。
在分类中,机器被训练成将一个组划分为特定的类。分类的一个简单例子是电子邮件帐户上的垃圾邮件过滤器。过滤器分析你以前标记为垃圾邮件的电子邮件,并将它们与新邮件进行比较。如果它们匹配一定的百分比,这些新邮件将被标记为垃圾邮件并发送到适当的文件夹。那些比较不相似的电子邮件被归类为正常邮件并发送到你的邮箱。
第二种监督学习是回归。在回归中,机器使用先前的(标记的)数据来预测未来。天气应用是回归的好例子。使用气象事件的历史数据(即平均气温、湿度和降水量),你的手机天气应用程序可以查看当前天气,并在未来的时间内对天气进行预测。
回归模型
回归模型通过多项式插值的方式学习一个能够拟合采样数据的多项式数值函数。通过这个一般的多项式函数,预测未来数据在这个多项式函数中的走势。进而,达到预测的目的。
回归的主要任务是找出能够拟合训练数据集的数值函数,方差(计算数据与实际数据的差距)越小越好,从而去预测未知的数据,为该问题数据的一般化建立模型。上述步骤总结如下:1、假定多项式函数(这里可以用交叉验证技术,进行多项式回归阶数的选取) 2、定义训练集上的误差函数 3、用训练集不断优化多项式函数求得多项式系数。
m:训练样本数目
x:输入变量/特征量
y:输出变量/目标变量
(x(i),y(i)):第i个训练样本
x(i):第i个训练样本的特征量
y(i):第i个训练样本的目标变量
h:算法根据训练样本,经过训练,给出的结果函数,是一个x→y的映射
hypothesis: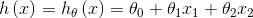
给出特征x,得到预测h(x)
代价函数,又被叫做平方误差函数、平均平方误差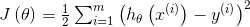
梯度下降法
在选定线性回归模型后,只需要确定参数 θ,就可以将模型用来预测。然而 θ 需要在 J(θ) 最小的情况下才能确定。因此问题归结为求极小值问题,使用梯度下降法。

若有收获,就点个赞吧
0 人点赞
