人工智能——深度学习
在当今大数据时代,人工智能掀起一股热潮。人工智能,是研究、开发用于模拟、延申和扩展人的智能的理论、方法、技术以及应用系统的一门新的技术科学。其中机器学习与深度学习尤为重要。
深度学习:
输入大量数据库,机器学习
计算机视觉相关:
图像存储:在计算中,一张图片被表示成三维数组的形式,数组中每个元素就是一个像素点。
相关套路:1.收集数据并给定标签。2.训练一个分类器。3。测试,评估
k近邻进行图像分类:
1. 计算已知类别数据集中的点与当前点的距离
2. 按照距离依次排序
3. 选取与当前点距离最小的k个点
4. 确当前k个点所在类别的出现概率
5. 返回前K个点出现频率最高的类别作为当前点预测分类。
如何计算:d1( I1-I2)=
超参数与交叉验证:
参数(parameters)/模型参数:由模型通过学习得到的变量,比如权重 和偏置
和偏置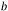 ;
;
超参数(hyperparameters)/算法参数: 根据经验进行设定,影响到权重 和偏置
和偏置 的大小,比如迭代次数、隐藏层的层数、每层神经元的个数、学习速率等
的大小,比如迭代次数、隐藏层的层数、每层神经元的个数、学习速率等
交叉验证其实就是为了检查模型的泛化行和稳定性,让模型的输出更加可靠。
因为当我们只将训练数据划分一次时,有可能划分的不好,所以模型的结果会有偏差,不可靠。所以,我们可以使用交叉验证。经常使用的是k-fold交叉验证,将数据划分k份,每次用一份做为验证集,其他的k-1份作为训练集来训练k个模型,然后对多个模型的结果取均值就是这个模型的输出。同时,我们还会看一下k的模型的具体输出值,看一下波动是否很大。在对分类任务进行交叉验证时,还要注意划分是样本类别的分布。python里面有sklearn.model_selection.StratifiedKFold可以处理分类任务的交叉验证。如果用k-fold划分,就有可能训练集和测试集的结果相差很大。因为有可能划分时,有一个块儿里面根本就没有某一类。
交叉验证划分训练集只是为了验证模型的稳定性,并没有说要选择里面的某一个模型。最后,还是要用全部的训练数据去训练模型,然后得出模型的参数。
线性分类:f(xi,w,b)=W xi+b;

若有收获,就点个赞吧
0 人点赞
