哈夫曼编码的概念
哈夫曼编码是基于哈夫曼树实现的一种文件压缩方式。哈夫曼树:一种带权路径最短的最优二叉树,每个叶子结点都有它的权值,离根节点越近,权值越(根节点权值为0,往下随深度增加依次加一),树的带权路径等于各个叶子结点的数值与其权值的乘积和。哈夫曼树如图: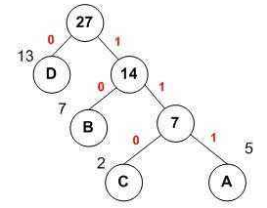
上图中的数据 A,B,C,D都是存放在叶节点里面。然后为每个节点进行编码,假设从根节点出发,到左子树获得编码0,到右子树获得编码1,这样我们可以得到D的编码是0,B的编码是10,C的编码是110,A的编码是111。离根越近的节点对应的编码越短,节点的数值越大。那么,如何把哈夫曼编码应用在文档的压缩上呢?我们记文件中字符出现的次数为节点的数值,出现次数最多的字符会分配到哈夫曼树的靠近根节点的地方,自然也就会获得较短的哈夫曼编码。于是我们通过这种方式,使得文档中的字符获得不同的哈夫曼编码,因为出现频次高的字符对应编码较短,所以从文档中获取的字节被哈夫曼编码替换之后,会获使得其占用的总存储空间变小,实现压缩的效果。
哈夫曼压缩与解压
(l)I:初始化 (Initialization):从终端读入字符集大小 n,及 n 个字符和 m 个权值,建立哈夫曼树,正规的是从文件获取数据,这里可以用一个足够大的数组来保存每个不同的字符,数组下标为字符所对应的ASCALL码值,这样一来数组存放的就是每一字符出现的次数(频率)以此作为每个数据的权值。
(2)为了更方便的建立哈夫曼树,可以把数组转化为链表。减少大量数据移动的时间复杂度。
(3)从链表中取出并删除最小的两个节点,创建一个他们的父节点,父节点不存字符,值为那两个节点的和,把那两个节点分别作为其左子节点和右子节点,最后把这个父节点存入链表。再次排序,取出并删除最小的两个节点,生成父节点,再存入…以此类推,最终生成一棵哈夫曼树.由此得到每个数据的编码。
(4)哈夫曼编码代替字符,进行压缩,压缩前首先要将文件头(文件标志,字符数量,最后一个字节有效位,密码)字符和其频率的那张表格写入文件,以便于解压缩。
(5)解压操作与压缩操作相似,从写入文件中的字符统计的表读出放入,用统计结果构建哈夫曼树(和压缩构建方式基本一致),用哈夫曼树生成哈夫曼编码(从根结点开始,路径左边记为0,右边记为1)(这里也和上面的压缩一样)。遍历文件每个字节,根据哈夫曼编码找到对应的字符,将字符写入新文件。
压缩结果:
上面的data1是源文件,data2是压缩后的文件,data3是data2解压后的文件,可见压缩后的文件站的内存比之前变少了,解压之后又和原文件一样,这里文件太小,所以压缩前后的差距不是很明显,当数据过大的时候,就更清晰了。

若有收获,就点个赞吧
0 人点赞
